[SQL] PERCENT_RANK, CUME_DIST, RATIO_TO_REPORT, NTILE
- 예제1
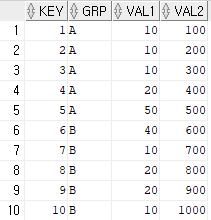
<테이블 TBL>
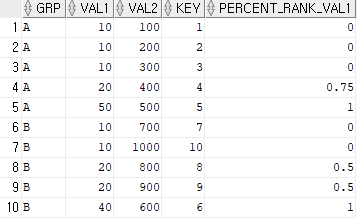
SELECT GRP, VAL1, VAL2, KEY
, PERCENT_RANK() OVER(PARTITION BY GRP ORDER BY VAL1) AS PERCENT_RANK_VAL1
FROM TBL ;PERCENT는 SQL 윈도우 함수 중 하나로, 데이터의 상대적 순위를 0과 1 사이의 소수 값으로 계산한다.
PERCENT_RANK =
첫 번째 순위는 0부터 시작한다. 마지막 값은 1이다. 값이 동일한 경우 동일한 순위를 가진다.
A 그룹에서 VAL1 값을 기준으로 데이터 정렬을 하면
10 10 10 20 50 이다.
GRP의 A 그룹에서 VAL1 = 10 인 경우
= 0
이므로 0이다. 또한 VAL1 = 10인 열이 3개이므로 똑같이 0을 갖는다.
VAL1 = 20인 경우
= 0.75
VAL1 = 50인 경우
= 1
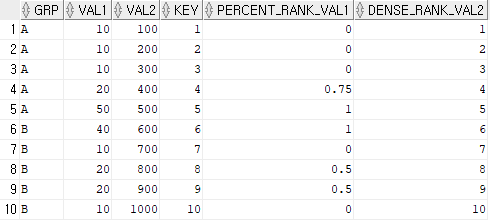
SELECT GRP, VAL1, VAL2, KEY
, PERCENT_RANK() OVER(PARTITION BY GRP ORDER BY VAL1) AS Percent_Rank_VAL1
, DENSE_RANK() OVER(ORDER BY VAL2) AS Dense_Rank_VAL2
FROM TBL;DENSE_RANK는 데이터 집합에서 순위를 매길 때 중복된 값에 대해 동일한 순위를 부여하고, 순위 간에 연속적인 숫자를 할당한다. 여기서는 VAL2에 대해 정렬 후 그 값에 순위를 부여한다.
- 예제2
<테이블 TBL>
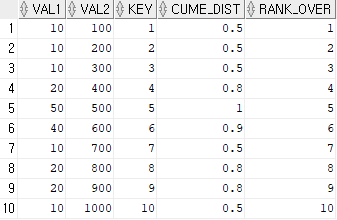
SELECT VAL1, VAL2, KEY
, CUME_DIST() OVER(ORDER BY VAL1) AS cume_dist
, RANK() OVER(ORDER BY VAL2) AS rank_over
FROM TBL
ORDER BY KEY;CUME_DIST()는 SQL의 윈도우 함수로, 데이터의 분포와 순위를 계산하는데 사용된다.
CUME_DIST(x) =
VAL1 = 10, 총 10개 데이터 10보다 작거나 같은 수 5개 -> 0.5
VAL1 = 20, 총 10개 데이터 20보다 작거나 같은 수 8개 -> 0.8
VAL1 = 40, 총 10개 데이터 30보다 작거나 같은 수 9개 -> 0.9
VAL1 = 50, 총 10개 데이터 50보다 작거나 같은 수 10개 -> 1.0
- 예제3
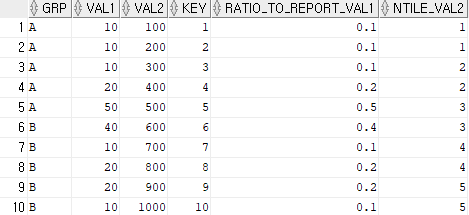
SELECT GRP, VAL1, VAL2, KEY
, RATIO_TO_REPORT(VAL1) OVER(PARTITION BY GRP) AS ratio_to_report_val1
, NTILE(5) OVER(ORDER BY VAL2) AS ntile_val2
FROM TBL
ORDER BY KEY;RATIO_TO_REPORT()는 윈도후 함수로 지정된 값이 파티션 내의 합계에서 차지하는 비율을 계산한다.
GRP로 파티션을 나누고 RATIO_TO_REPORT를 계산한다.
GRP = A인 경우
VAL1 = 10, =0.1
VAL1 = 20, =0.2
VAL1 = 50, =0.5
NTILE 함수는 데이터를 지정된 수의 수의 그룹으로 나누고, 각 행에 그룹 번호를 할당한다.
여기서는 VAL2 데이터를 기준으로 오름차순 정렬한 뒤 5개의 그룹으로 나는다