
스트림 요소 병렬 처리
스트림을 처음 소개할 때 Iterator에 비해 병렬 처리에 효율적인 구조라고 언급했었죠. 자바에서는 스트림의 병렬 처리를 편리하게 하기 위해 병렬 스트림을 제공하고 있습니다.
자바 병렬 스트림
동시성, 병렬성
멀티 쓰레드에서는 동시성과 병렬성 중 하나의 방식을 선택해서 동작합니다.
동시성(concurrency)은 멀티 쓰레드가 하나의 코어에서 번갈아가면서 작업하는 것을 의미합니다. 그렇기 때문에 한 시점에 하나의 작업만을 수행합니다.
병렬성(parallelism)은 멀티 코어를 각각 사용하는 병렬 처리 작업을 의미합니다. 그래서 병렬성은 한 시점에 여러 개의 작업을 할 수도 있습니다. 병렬성은 다시 데이터 병렬성과 작업 병렬성으로 구분지을 수 있습니다.
- 데이터 병렬성: 전체 데이터를 분할하고 분할한 데이터를 병렬 처리. 자바 병렬 스트림이 데이터 병렬성을 기반으로 구현.
- 작업 병렬성: 서로 다른 작업을 병렬 처리.
fork/join framework
자바 병렬 스트림에서는 병렬 처리를 위해 fork/join framework를 Java 7부터 지원하고 있습니다. fork는 나누다라는 의미이고, join은 합치다라는 의미기에 나누고 합치는 도구모음이라고 볼 수 있습니다.
fork/join framework은 fork 단계에서 데이터를 분할해 서브 요소셋으로 만듦니다. 그리고 각각의 서브 요소셋을 병렬로 처리합니다. 그 후 join 단계에서 처리된 서브 요소셋을 다시 하나로 합쳐 반환합니다.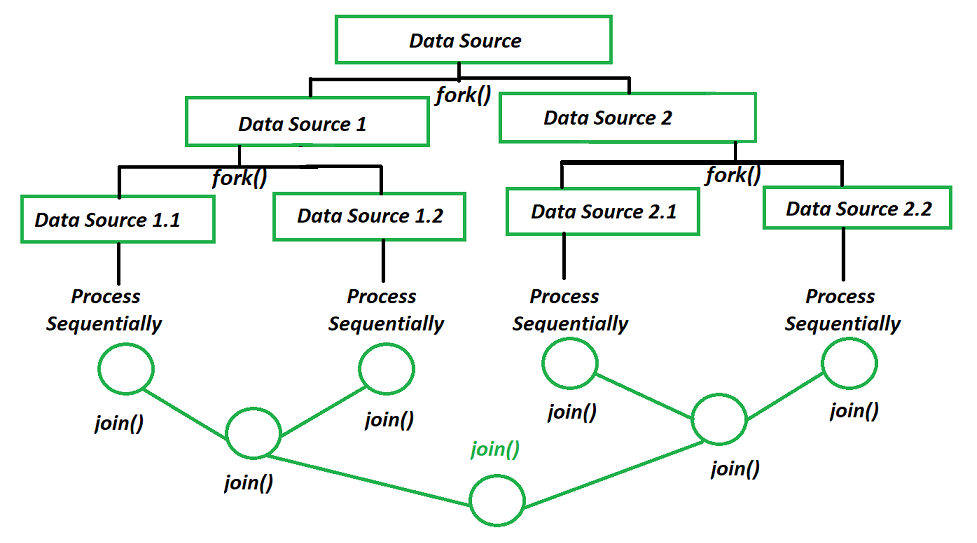 이미지 출처
이미지 출처
fork/join framework의 작업 관리를 위해서 쓰레드풀을 사용합니다. 이때 ExecutorService의 구현 객체인 ForkJoinPool을 이용해서 쓰레드를 관리합니다.
자바 병렬 스트림 사용
fork/join framework은 백그라운드에서 알아서 돌아가기 때문에 개념만 알고 있으면 실제 사용에서는 따로 구현할 필요없이 간단하게 병렬 스트림을 취득해서 사용할 수 있습니다.
병렬 스트림을 취득하는 메소드는 다음과 같습니다.
| 메소드 | 제공해야하는 것 |
|---|---|
parallelStream() | List, Set 컬렉션 |
parallel() | Stream, IntStream, LongStream, DoubleStream |
parallelStream()은 List, Set 컬렉션을 제공하면 해당 컬렉션의 병렬 스트림을 제공합니다. parallel()은 기존의 스트림을 병렬 처리 스트림으로 바꿔줍니다.
다음 코드는 일반 스트림과 병렬 처리 스트림의 작업 시간을 확인하는 예제코드입니다. 1000개의 랜덤 Integer를 삽입한 List의 평균을 구하는 작업 시간을 측정합니다.
public class Main {
public static void main(String[] args) {
List<Integer> list = new ArrayList<Integer>();
for (int i = 0; i < 1000; i++) { //List 요소 삽입
list.add((int) (Math.random() * 100) + 1);
}
double avg = 0.0;
long startTime, endTime, totalTime;
Stream<Integer> generalStream = list.stream();
startTime = System.nanoTime();
avg = generalStream.mapToInt(elem -> elem).average().getAsDouble();
endTime = System.nanoTime();
totalTime = endTime - startTime;
System.out.println("일반 스트림 작업 처리 시간: " + totalTime);
Stream<Integer> parallelStream = list.parallelStream();
startTime = System.nanoTime();
avg = parallelStream.mapToInt(elem -> elem).average().getAsDouble();
endTime = System.nanoTime();
totalTime = endTime - startTime;
System.out.println("병렬 스트림 작업 처리 시간: " + totalTime);
}
} 병렬 스트림이 일반 스트림보다 훨씬 빠르게 작업을 수행한 것을 확인할 수 있습니다.
병렬 스트림이 일반 스트림보다 훨씬 빠르게 작업을 수행한 것을 확인할 수 있습니다.
병렬 처리 스트림 사용할 때 고려할 점
사실 위 코드와 결과만을 본다면 병렬 처리 스트림을 사용하는 것이 무조건적으로 좋아보입니다. 그러나 실제로 병렬 처리 스트림을 사용할 땐 여러가지를 고려해야합니다. 왜냐하면 상황에 따라서 일반 스트림의 효율이 훨씬 좋은 경우가 발생할 수도 있기 때문입니다.
병렬 처리 스트림을 사용하고자할 때는 아래 세 가지 사항을 고려해보고 적용해야합니다.
-
요소 개수, 요소당 처리 시간
컬렉션이나 스트림의 요소 개수가 적고 요소당 처리 시간이 짧은 코드에서는 일반 스트림이 병렬 스트림보다 빠를 수도 있습니다. 그 이유는 병렬 처리는 fork/join framework의 동작 시간, 쓰레드 풀 생성 등의 추가 동작이 있기 때문입니다. -
스트림 소스 종류
ArrayList, Array는 인덱스로 요소를 관리해서 요소에 접근하기 쉽기 때문에 fork 단계에서 빠르게 분할을 할 수 있습니다. 하지만 인덱스가 없는 Set, 링크를 사용하는 LinkedList와 같은 컬렉션은 요소 분리에서 시간이 더 오래 소요됩니다. -
CPU 코어 개수
CPU 코어 개수가 늘어나면 병렬 처리할 수 있는 양도 늘어나기 때문에 병렬 처리가 빨라집니다. 만약 CPU 코어 개수가 적은 환경에서는 병렬성 뿐만아니라 동시성도 늘어나기 때문이에 오히려 병렬 처리가 늦어질 수도 있습니다.
