
start()와 run()
지금까지 쓰레드를 다루면서 이상한 점이 보이지 않았나요?
분명히 우리가 오버라이딩한 메소드는 run()인데 실제로 쓰레드를 실행할 때는 start() 메소드를 사용합니다. 오늘은 이 의문을 해결하고자 두 메소드에 대해서 알아보려고 합니다.
run()의 실행
먼저, run()을 호출하게 되면 쓰레드를 실행하는 것이 아니라 어떤 클래스에 속한 run()이라는 메소드를 실행하게 됩니다. 따라서 호출 스택에서는 다음과 같은 동작이 발생합니다.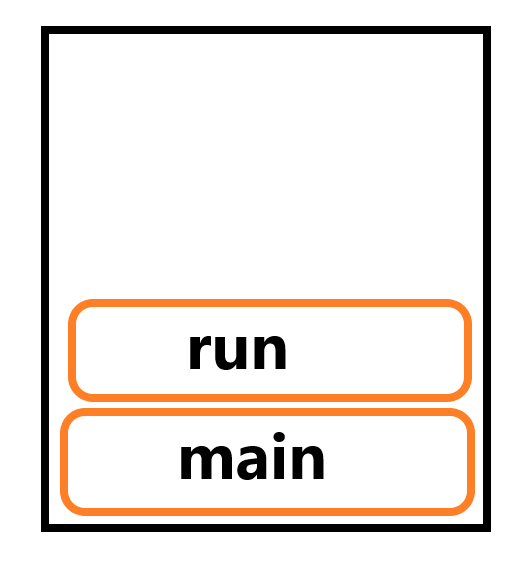 이렇게 실행된다는 것은 쓰레드를 생성하고 실행하는 것이 아니라 그냥 메소드 호출이 되게됩니다.
이렇게 실행된다는 것은 쓰레드를 생성하고 실행하는 것이 아니라 그냥 메소드 호출이 되게됩니다.
start()의 실행
반면 start()는 쓰레드가 작업을 하기 위한 새로운 호출 스택을 생성하고 해당 스택에 해당 쓰레드의 run()이 가장 먼저 담기게 됩니다.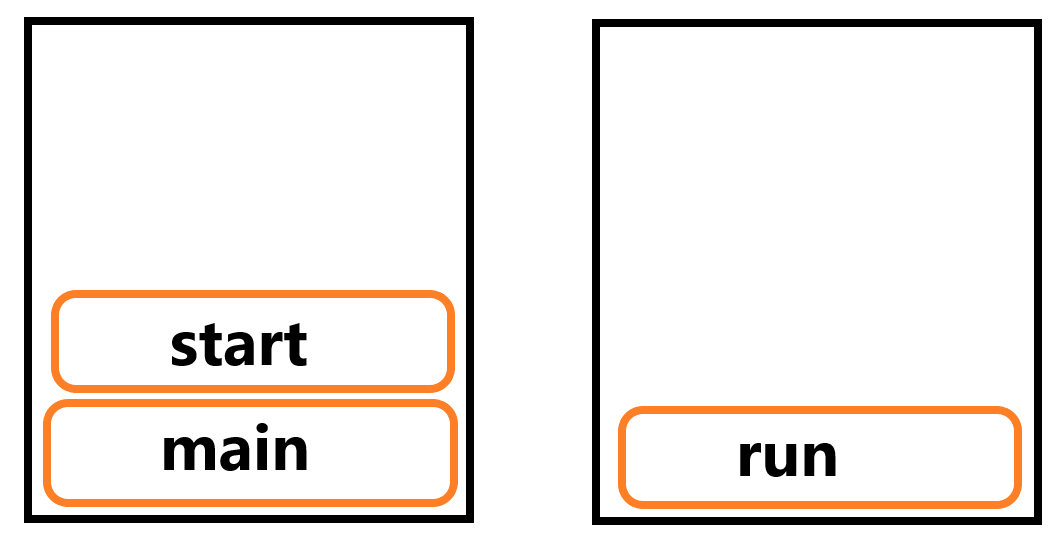 여기서 start()가 호출되어 새 호출 스택이 만들어지고 run이 새 호출 스택에 push되면 start는 pop이 됩니다.
여기서 start()가 호출되어 새 호출 스택이 만들어지고 run이 새 호출 스택에 push되면 start는 pop이 됩니다.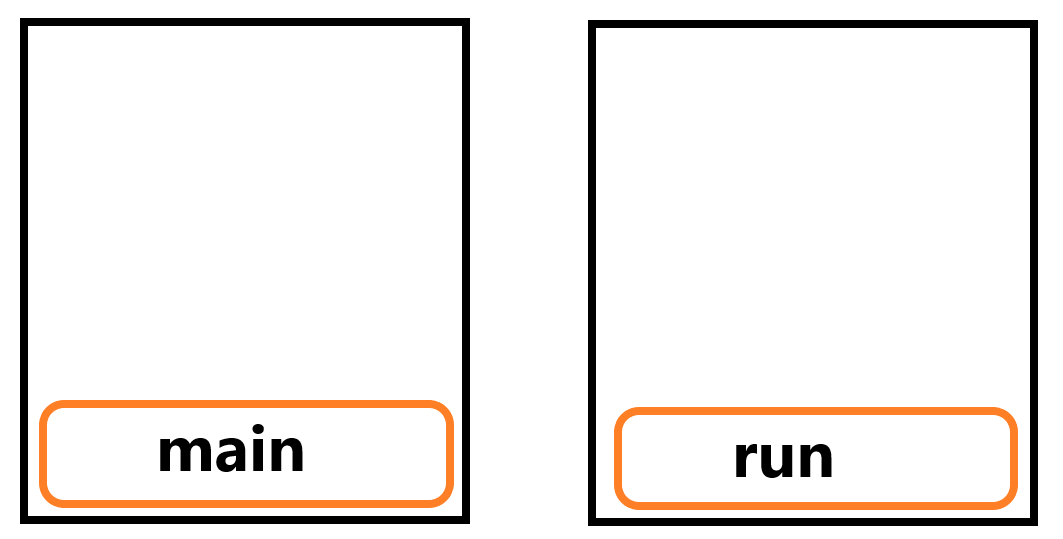
start()의 동작을 정리하면 다음과 같습니다.
- main에서 쓰레드의 start() 호출
- start는 쓰레드의 작업을 위한 새로운 호출 스택을 하나 생성
- 생성된 호출 스택에 쓰레드의 run() 메소드를 호출해서 작업을 수행
- 두 호출 스택은 CPU 스케쥴링에 따라 작업
이에 따라서 run()이 종료된 호출 스택은 사라지게 되고, 모든 호출 스택이 사라지면 프로그램이 종료되었다라고 할 수 있습니다.
쓰레드 우선순위
모든 쓰레드는 우선순위(priorty)라는 이름의 멤버 변수를 가지고 있습니다. 우선순위의 값에 따라서 CPU에서 할당되는 실행시간이 달라집니다. 당연히 높은 우선순위를 가진 쓰레드가 더 많은 실행시간을 할당받을 수 있게됩니다.
쓰레드의 우선순위와 관련된 멤버 변수, 메소드는 다음과 같습니다.
| 멤버 | 설명 |
|---|---|
| MAX_PRIORITY, MIN_PRIORTY | 최대, 최소 우선순위 (public static final) |
| NORM_PRIORITY | 보통 우선순위 (public static final) |
| void setPriorty(int p) | 우선순위를 지정한 값 p로 변경 |
| int getPriorty() | 쓰레드 우선순위 반환 |
각 쓰레드가 가질 수 있는 우선순위의 범위는 정수 1 ~ 10사이의 값 입니다. 숫자가 커질수록 우선순위가 높은 것으로 취급됩니다. 이때 우선순위는 절댓값이 아니라 상대값으로 적용되는 것에 주의해야합니다.
참고로 main 쓰레드의 우선순위는
5로 설정되어 있습니다.
