
C로 작성된 포스트입니다.
연결 리스트
연결 리스트(Linked List)는 선형 리스트와는(순차 자료구조) 다르게 자료의 순서가 존재하지 않는 자료구조 입니다. 순서가 없는 자료구조를 저장하는 방식은 노드(포인터)를 이용하는 방식입니다. 자료는 데이터 필드와 링크 필드 한 쌍으로 구성되어 있는데 데이터에는 실질적으로 사용될 데이터가 있고 링크 필드는 다음 데이터의 주소를 가리키는 정보가 담겨있습니다. 그래서 이것을 그림으로 풀어보면 다음과 같은 모양으로 구성되어있습니다.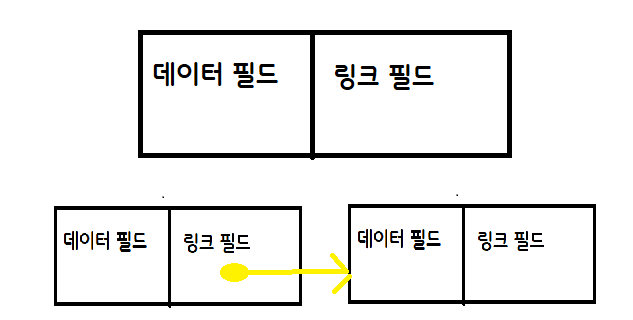 이런식으로 연결되있어서
이런식으로 연결되있어서 연결 리스트라고 불리우게 됩니다.
그러면 지금부터 노드 구현, 삽입, 삭제를 구현해보도록 하겠습니다.
노드 정의
노드를 구조체로 정의합니다. 노드는 데이터 필드와 링크 필드를 가지고 있습니다.
//노드 구현
typedef struct ListNode {
//데이터 필드
char data[10];
//링크 필드
struct ListNode* link;
}listNode;
//head, 리스트의 시작 노드
typedef struct {
listNode* head;
}linkedList_h;앞으로 연결 자료구조들은 이러한 노드 구조를 기본적으로 가지고 활용되니 잘 알아두세요.
노드 삽입
노드를 정의했으니 노드를 삽입할 차례입니다. 노드 삽입은 세가지 방법이 존재합니다. 리스트의 처음에 노드를 삽입하는 것, 리스트 중간에 노드를 삽입하는 것, 리스트의 마지막에 노드를 삽입하는법 세가지를 알아보겠습니다.
리스트의 처음에 노드 삽입
void insertFirst(linkedList_h* L, char* x) {
listNode* newNode;
//삽입할 새 노드 할당
newNode = (listNode*)malloc(sizeof(listNode));
//새 노드의 데이터 필드에 데이터인 x 저장
strcpy(newNode->data, x);
//새 노드를 맨 앞에 삽입했으므로 head 노드가 새 노드를 가리키게 함
newNode->link = L->head;
L->head = newNode;
}리스트의 중간에 노드 삽입
중간 삽입과정이 끝와 처음에 비해 고려해야할 조건이라던가 설정면에서 조금 더 복잡한 양상을 보입니다.
void insertMiddle(linkedList_h* L, listNode* pre, char* x) {
listNode* newNode;
newNode = (listNode*)malloc(sizeof(listNode));
strcpy(newNode->data, x);
//빈 리스트라면 삽입 노드를 맨앞이자 마지막 노드로 설정
//마지막 노드(=링크 필드가 아무것도 가리키지 않음)
if (L == NULL) {
newNode->link = NULL;
L->head = newNode;
}
//삽입위치 포인터 prer가 NULL이라는 것은 앞에 아무것도 없다는, 즉, 시작노드이므로
//삽입 노드를 첫 번째 노드로 설정합니다.
else if (pre == NULL) {
L->head = newNode;
}
//이전 노드가 존재하면 pre노드 뒤에 삽입합니다.
else {
//새 노드의 링크필드가 pre가 가리키고있던 링크 필드를 가리키게 됩니다.
newNode->link = pre->link;
//이전 노드 pre는 삽입한 새 노드를 가리키게 됩니다.
pre->link = newNode;
}
}중간 삽입 과정을 그림으로 표현하면 다음과 같습니다.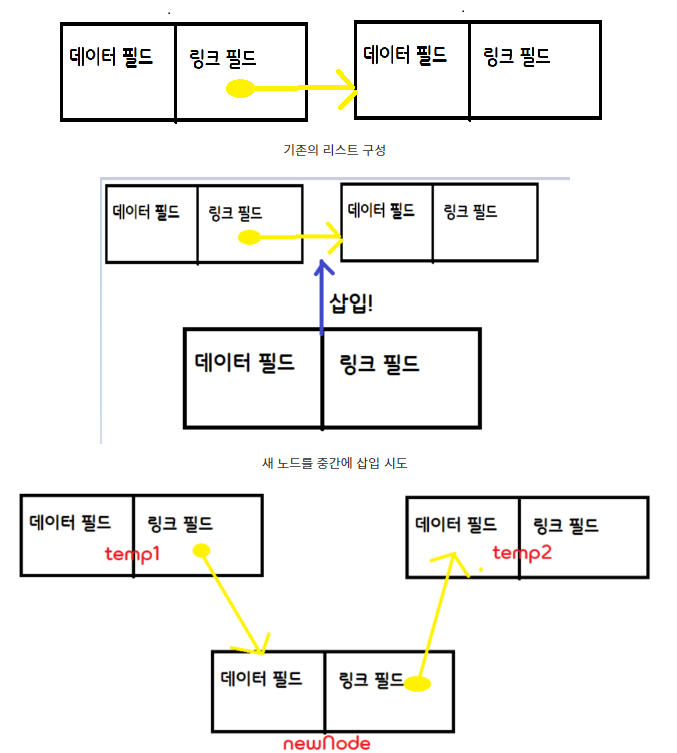
리스트 마지막에 노드 삽입
void insertLast(linkedList_h* L, char* x) {
listNode* newNode;
listNode* temp;
newNode = (listNode*)malloc(sizeof(listNode));
strcpy(newNode->data, x);
newNode->link = NULL;
//공백 리스트이면 삽입한 새 노드를 시작 노드로 설정
if (L->head == NULL) {
L->head = newNode;
return;
}
//빈 리스트가 아닐때만 실행되는 코드들
temp = L->head;
//히스트의 마지막 노드를 찾아서 임시 변수 temp에 저장
while (temp->link != NULL) {
temp = temp->link;
}
//삽입한 새 노드를 이전 마지막노드인 temp의 위에 연결
temp->link = newNode;
}노드 삭제
노드 삭제에도 다양한 방법이 있습니다. 여기서는 삭제할 노드의 이전 노드의 링크 필드가 가리키는 노드(말이 거창하지만 결국 삭제할 노드를 의미)를 삭제하는 방식을 구현하겠습니다.
void deleteNode(linkedList_h* L, listNode* p) {
listNode* pre;
//공백 리스트라면 삭제할 것이 없으므로 실행 종료
if (L->head == NULL) {
return;
}
//리스트에 노드가 하나뿐이라면 노드를 삭제하고 리스트 head의 포인터를 비웁니다.
if (L->head->link == NULL) {
free(L->head);
L->head = NULL;
return;
}
//삭제할 노드가 존재하지 않는다면 실행을 종료
else if (p == NULL) {
return;
}
//삭제연산. 삭제할 노드인 p의 앞 노드 pre를 통해서 p를 찾습니다.
else {
pre = L->head;
while (pre->link != p) {
pre = pre->link;
}
//삭제 노드의 앞 노드와 다음 노드를 서로 연결해줍니다.
pre->link = p->link;
free(p); //메모리 해제
}
}이 부분에서 중요한 것은 결국 삭제한 노드의 앞 노드와 그 다음 필드를 서로 연결해주는 과정이 꼭 들어가야 합니다. 빠지면 당연히 연결되어있지 않게 되어서 데이터가 유실되겠죠?
리스트 검색
마지막으로 구현해볼 기능은 리스트 내에서 검색을 실시하는 연산입니다. 탐색이라고도 하는데 이 탐색방법이 꽤 여러가지가 존재합니다. 그러나 지금은 첫 공부기 때문에 처음부터 끝까지 순서대로 탐색하는 순차 탐색을 이용해서 리스트에서 검색하는 기능을 구현해보려고 합니다.
listNode* search(linkedList_h* L, char* x) {
//탐색을 시행할 포인터 변수 temp
listNode* temp;
temp = L->head;
//temp가 NULL이라면 전부 순환한 것임
while (temp != NULL) {
//temp.data 즉 temp의 데이터 값과 일치하는 것을 찾으면 temp가 위한 주소를 return
if (strcmp(temp->data, x) == 0) {
return temp;
}
//일치하지 않으면 다음 노드로 이동
else {
temp = temp->link;
}
}
//반환할 때 결과를 찾지 못하면(=탐색 실패) NULL을 반환
return temp;
}전체 코드는 GitHub에서 볼 수 있습니다.
