뿌셔뿌셔
파이토치 한국 사용자 모임?에서 여기, 기본 익히기부터 시작한다. 1. 텐서(Tensor)는 한 번 쭉 써봤다. 버전은 아래와 같다.
import sys
import torch
print(sys.version)
print(torch.__version__)
#3.6.13 |Anaconda, Inc.| (default, Mar 16 2021, 11:37:27) [MSC v.1916 64 bit (AMD64)]
#1.10.2디버거도 안쓰고 vscode를 아주 대충 쓰고 있기에 여기서 볼 내용이 많았다.
2. Dataset과 DataLoader
2. Dataset과 DataLoader부터 봅시다.
캐글은 2010년 설립된 예측모델 및 분석 대회 플랫폼이다. 기업 및 단체에서 데이터와 해결과제를 등록하면, 데이터 과학자들이 이를 해결하는 모델을 개발하고 경쟁한다. 2017년 3월 구글에 인수되었다. - Wikipedia
보면 신기한 디스 이즈 컴피티션이 많다.
조만간 개랑 귀여운 고양이를 분류하고 놀고싶다.
매개변수는 download, root에 데이터가 없으면 다운합니다 까지 True로 해주면 아주 재미있게 다운로드를 해준다. 이 집구석에서는 40.0s가 걸린다.
train 밖에 없는건가 싶어서 data 날리고 밑에 똑같이 train=False로 해서 test_data도 받아와달라고 하니까 똑같았다. 그냥 지 알아서 잘 쓰나보다, 일단 따라해보자.
여기보면 막 데이터셋들이 있는데, 그렇게 친절하게도 어떤 종류의 데이터인지 (예를 들어, KITTI 데이터셋은 고양이인줄 알고 들어가봤는데 자동차들이 엄청 나왔다), 학습/데스트 데이더가 몇 개씩 제공되는지, 라벨이 무엇을 말하는지 모르기 때문에, 링크를 타고 들어가서 확인할 필요가 있다.
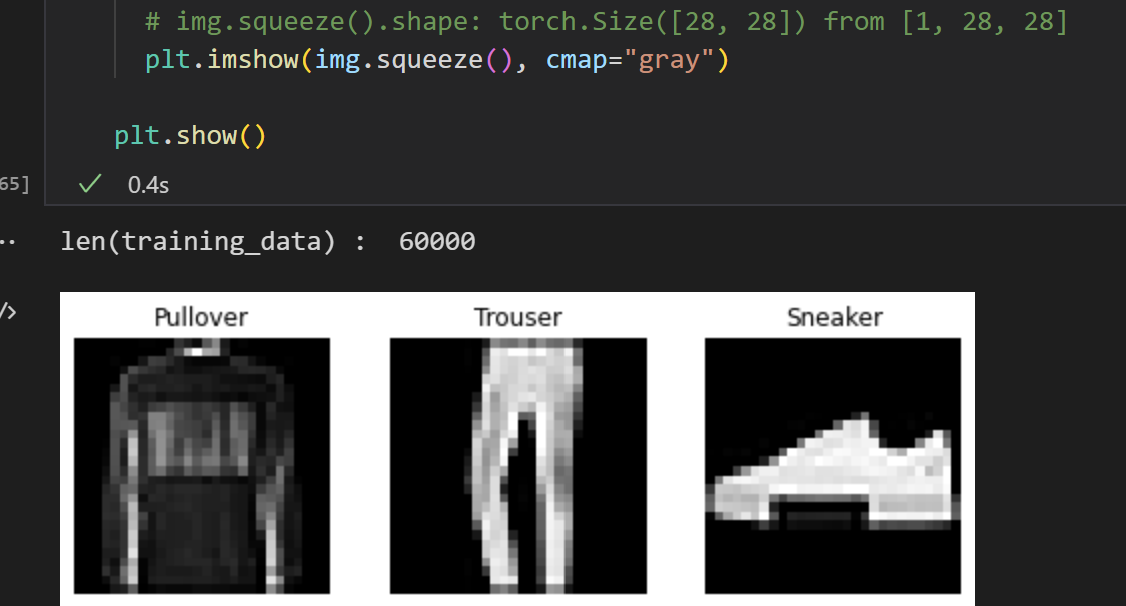
Fashion-MNIST는 Zalando의 기사 이미지 데이터셋으로 60,000개의 학습 예제와 10,000개의 테스트 예제로 이루어져 있습니다. 각 예제는 흑백(grayscale)의 28x28 이미지와 10개 분류(class) 중 하나인 정답(label)으로 구성됩니다. - 파이토치
여기를 보면 MNIST 칭구들은 6만/1만/28x28/흑백이 고정인 듯하다. 일단 튜토리얼이라서 설명이 되어있다. 하지만 가방이 8번이고, 코트가 4번인 것을 사진보면서 찾거나 저 맵핑을 머리 속에서 하면 아프기 때문에 labels_map을 만들어놓으면 좋겠다.
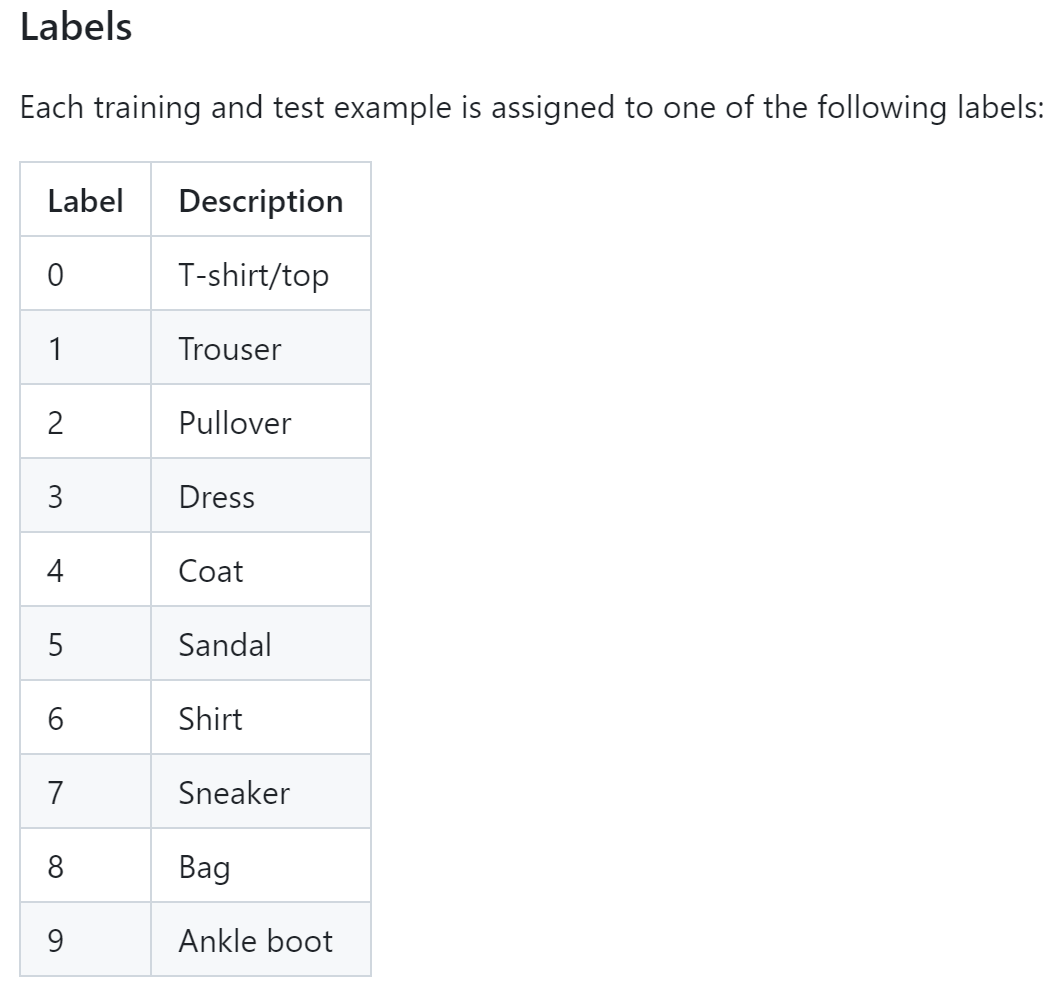
FashionMNIST 데이터셋에서 깃헙으로 타고 들어가면 각 라벨이 무엇을 의미하는지 알려준다.
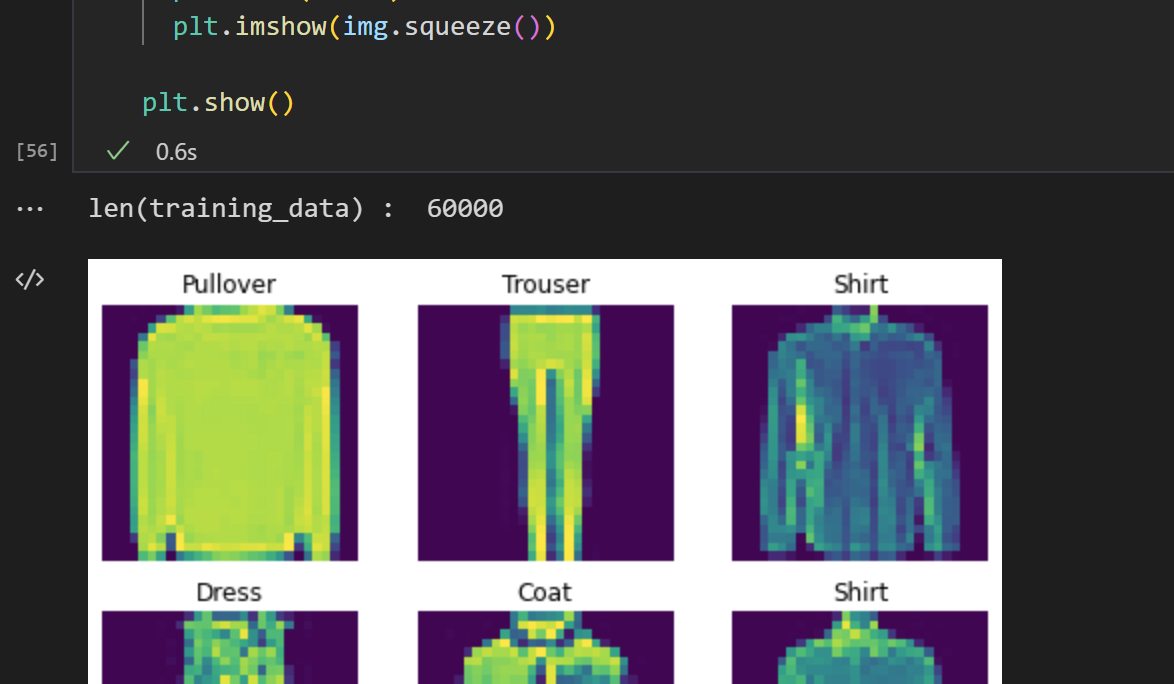
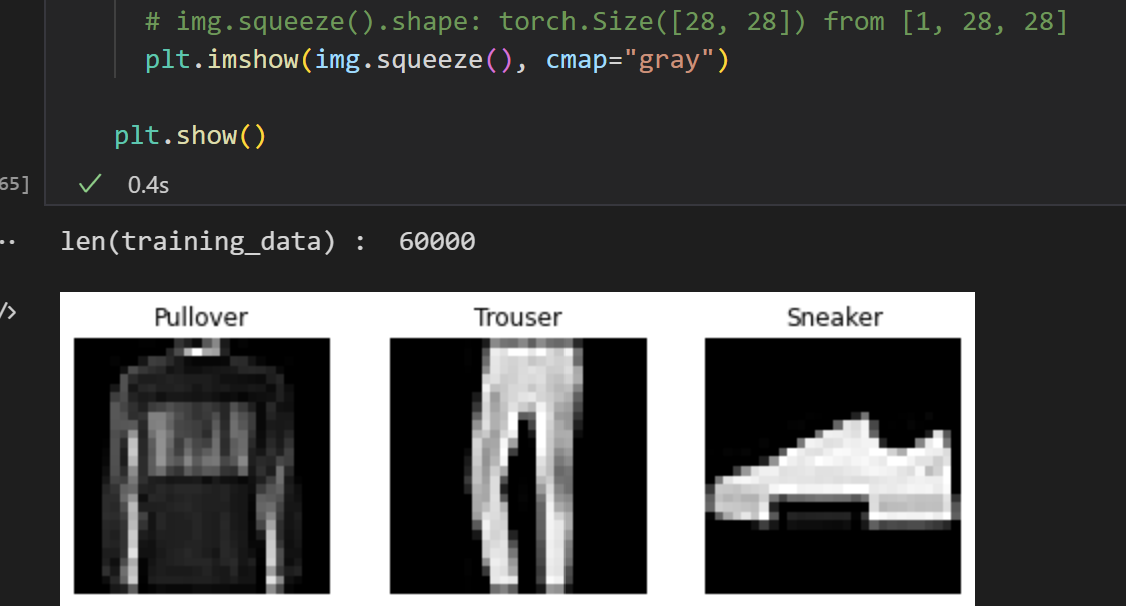
squeeze가 어떻게 동작하는지 잘 모르겠지만, img.shape를 뽑아보면 [1, 28, 28] 차원으로 나오는데, 1차원짜리 칭구들을 다 없애버리는 것이 필요한 모양이다. OpenCV에서 colorspace는 BGR로 되어있고, 맛?플로립은 colormap이 RGB로 되어있어서 변환이 필요했는데, 그건 색상 이미지를 써볼 때 다시 돌아오자. 어느 블로그님을 보면 손글씨 MNIST 가지고 무언가 하시는데 squeeze 관련해서 설명해놓으셨다.
