Aurora MySQL History Pipeline with AWS Lambda
🎯 프로젝트 개요
Aurora MySQL의 binlog를 실시간으로 캡처하여 S3에 구조화된 데이터로 저장하는 서버리스 CDC(Change Data Capture) 파이프라인
🏗️ 아키텍처 설계
1. 다양한 CDC 구현 방식 vs Lambda 기반 직접 파싱
고려했던 대안 방식들
🎯 방식 ①: Debezium → MSK(Serverless) → S3(Iceberg) → Athena
- 구성: Debezium 커넥터 → MSK Serverless → S3 Iceberg 테이블 → Athena
- 장점: 완전한 CDC 솔루션, 다중 싱크 지원
- 단점: 상시 비용 발생, 복잡한 운영
🎯 방식 ②: Aurora Native CDC → EventBridge Pipes → Lambda → S3(Iceberg)/Dynamo
- 구성: Aurora CDC → EventBridge Pipes → Lambda → S3/DynamoDB
- 장점: AWS 네이티브 서비스 활용
- 단점: 중간 서비스 의존성, 비용 증가
🎯 방식 ③: CDC(DMS/Debezium) → EventBridge Pipes → DynamoDB
- 구성: DMS/Debezium → EventBridge Pipes → DynamoDB
- 장점: 단건 조회 최적화
- 단점: 분석 기능 제한, DynamoDB 비용 폭증 위험
🎯 방식 ④: Debezium Server on Fargate(Spot) → S3(Iceberg) → Athena
- 구성: Debezium Server → Fargate Spot → S3 Iceberg → Athena
- 장점: MSK 없이 구현 가능
- 단점: Fargate 상시 실행 비용
왜 Lambda 기반 직접 binlog 파싱을 선택했는가?
🤖 GPT-5 기반 비용 분석: 이 비교 분석은 GPT-5를 활용하여 5가지 CDC 구현 방식의 상세한 비용 계산과 의사결정 과정을 수행했습니다.
월간 RDS CUD 이벤트 현황 (Datadog CSV 기반)
| 월 | 총 쿼리 수 | INSERT | UPDATE | DELETE | CUD 합계 |
|---|---|---|---|---|---|
| 2025-07 | 245,982,101 | 5,886,976 | 2,633,551 | 0 | 8,520,527 |
| 2025-08* | 54,751,948 | 1,277,932 | 545,330 | 0 | 1,823,262 |
*2025-08 데이터는 수집 중 일부 기간만 포함됨
🎯 비용 효율성 비교 (월간 비용):
현재 구현 (Lambda 직접 파싱): $30.58
방식 ④ (Fargate Spot): $90 (+196%)
방식 ① (MSK Serverless): $160 (+423%)
방식 ② (Aurora CDC + Pipes): $260 (+751%)
방식 ③ (DMS + Dynamo): $303 (+892%)
연간 절약 효과: $2,754-3,274 (70-90% 절약)🎯 기술적 우위:
- 완전한 제어: binlog 파싱부터 저장까지 모든 과정 제어
- 운영 단순성: 최소 서비스 구성 (Lambda, DynamoDB, S3)
- 에러 처리: 1236 에러 처리, S3 저장 실패 시 롤백 등 세밀한 제어
🎯 성능 최적화:
- 파티션 프루닝: 쿼리 비용 절약
- 체크포인트: 중간 체크포인트로 데이터 무결성 보장
🎯 확장성:
- 서버리스: Lambda 자동 스케일링
- 무제한 저장: S3 기반 무제한 확장
- 선형적 비용: 사용량에 비례한 비용 증가
2. 서버리스 우선 설계 (Serverless-First Architecture)
왜 서버리스로 설계했는가?
🎯 비용 효율성
- 사용량 기반 과금: 실제 데이터 변경이 있을 때만 비용 발생
- 인프라 관리 불필요: 서버 프로비저닝, 패치, 모니터링 오버헤드 제거
- 자동 스케일링: 데이터 볼륨에 따라 자동으로 리소스 조정
🎯 운영 단순화
- 이벤트 기반 실행: CloudWatch Events로 주기적 실행 (1분마다)
- 무상태 처리: 각 실행이 독립적이며 재시작 가능
- 장애 격리: 개별 실행 실패가 전체 시스템에 영향 없음
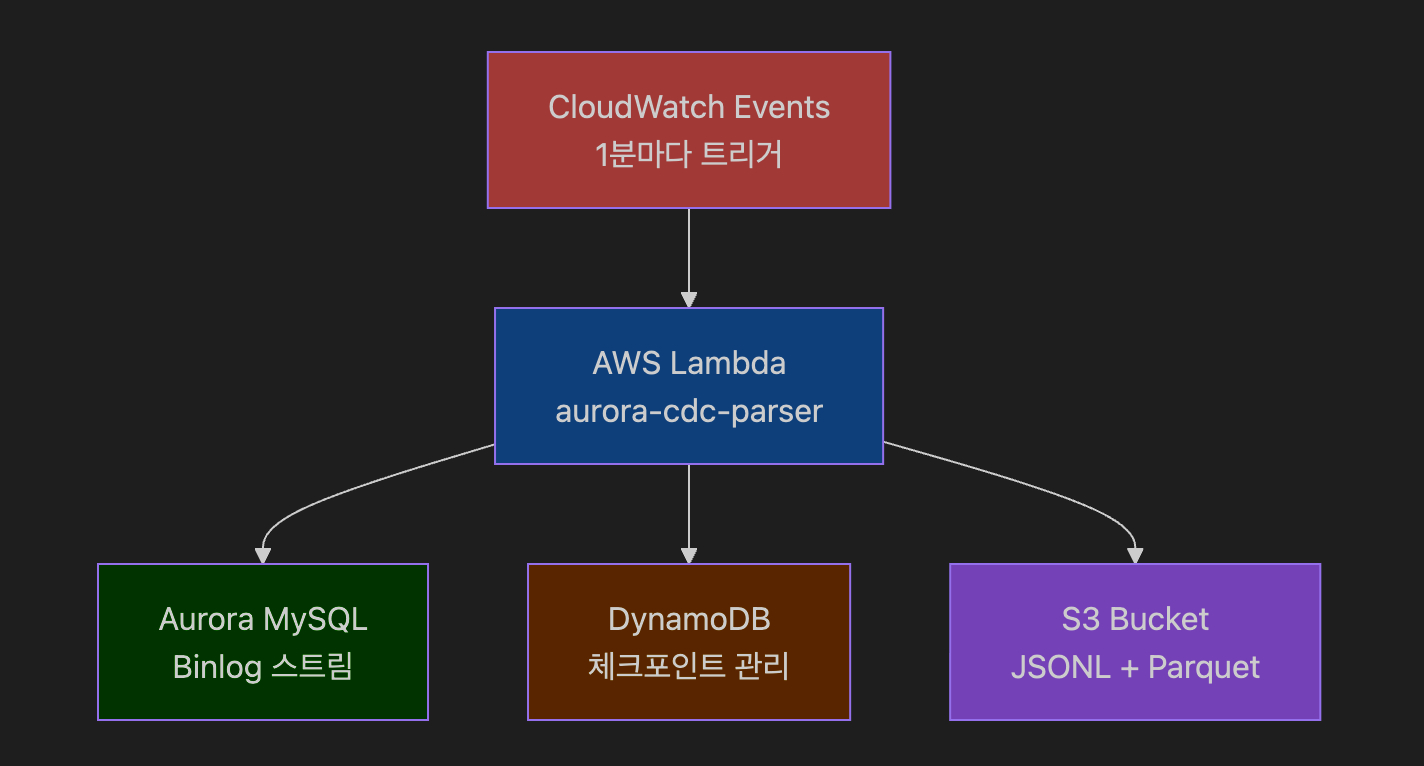
graph TB
A[CloudWatch Events<br/>1분마다 트리거] --> B[AWS Lambda<br/>aurora-cdc-parser]
B --> C[Aurora MySQL<br/>Binlog 스트림]
B --> D[DynamoDB<br/>체크포인트 관리]
B --> E[S3 Bucket<br/>JSONL + Parquet]
style A fill:#ff9999
style B fill:#99ccff
style C fill:#99ff99
style D fill:#ffcc99
style E fill:#cc99ff3. 체크포인트 기반 재시작 메커니즘
왜 체크포인트 패턴을 선택했는가?
🎯 데이터 무결성 보장
- 중간 체크포인트: 10건마다 진행 상황 저장으로 부분 실패 시에도 데이터 손실 방지
- 최종 체크포인트: Lambda 실행 완료 시 최종 위치 저장
- 자동 재시작: 장애 발생 시 마지막 체크포인트에서 자동 재개
🎯 처리 효율성
- 증분 처리: 이미 처리된 데이터 재처리 방지
- 병렬 실행 안전성: 동일한 binlog 위치에서 중복 처리 방지
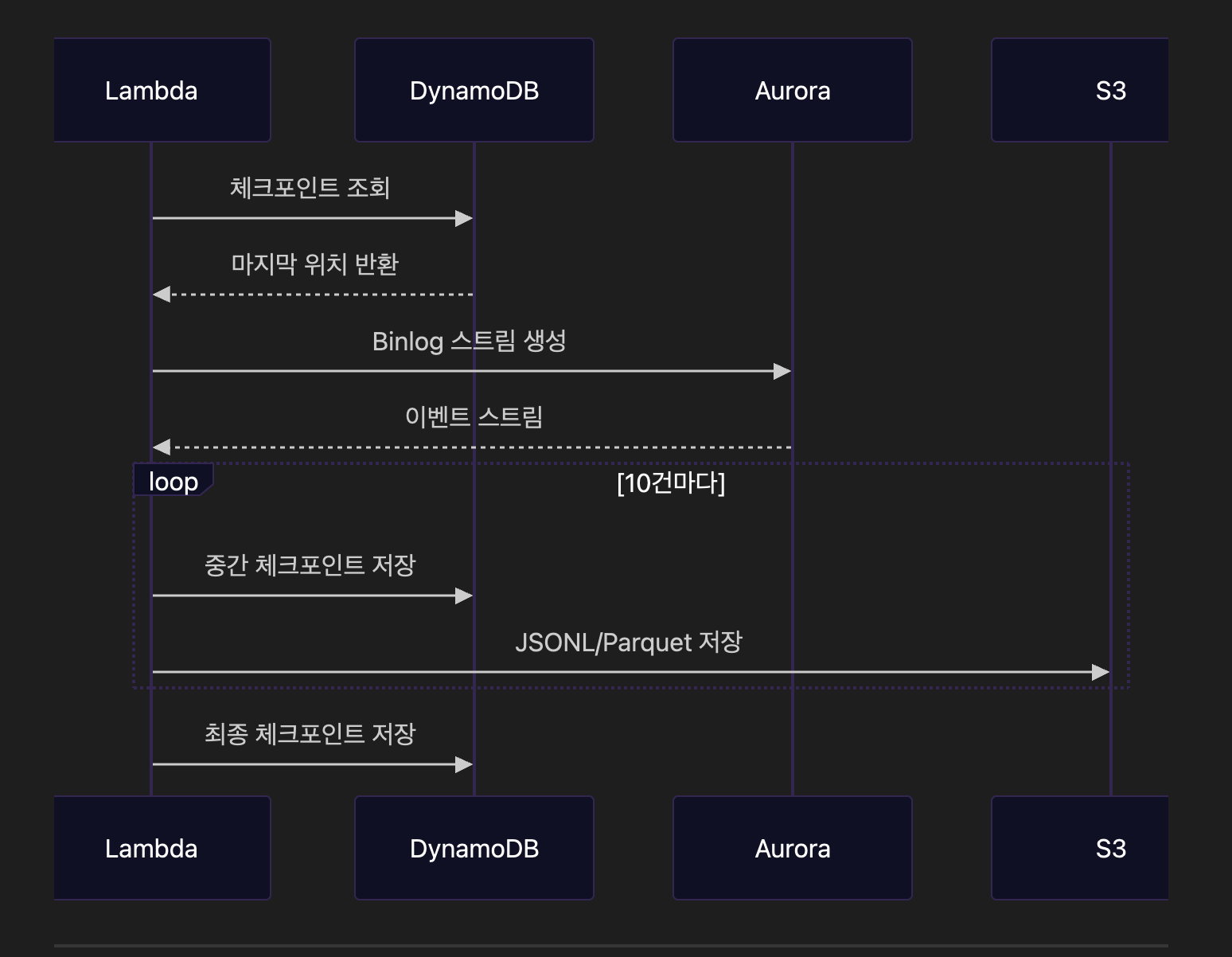
sequenceDiagram
participant L as Lambda
participant D as DynamoDB
participant A as Aurora
participant S as S3
L->>D: 체크포인트 조회
D-->>L: 마지막 위치 반환
L->>A: Binlog 스트림 생성
A-->>L: 이벤트 스트림
loop 10건마다
L->>D: 중간 체크포인트 저장
L->>S: JSONL/Parquet 저장
end
L->>D: 최종 체크포인트 저장🔄 핵심 처리 플로우
1. Binlog 스트림 처리 플로우
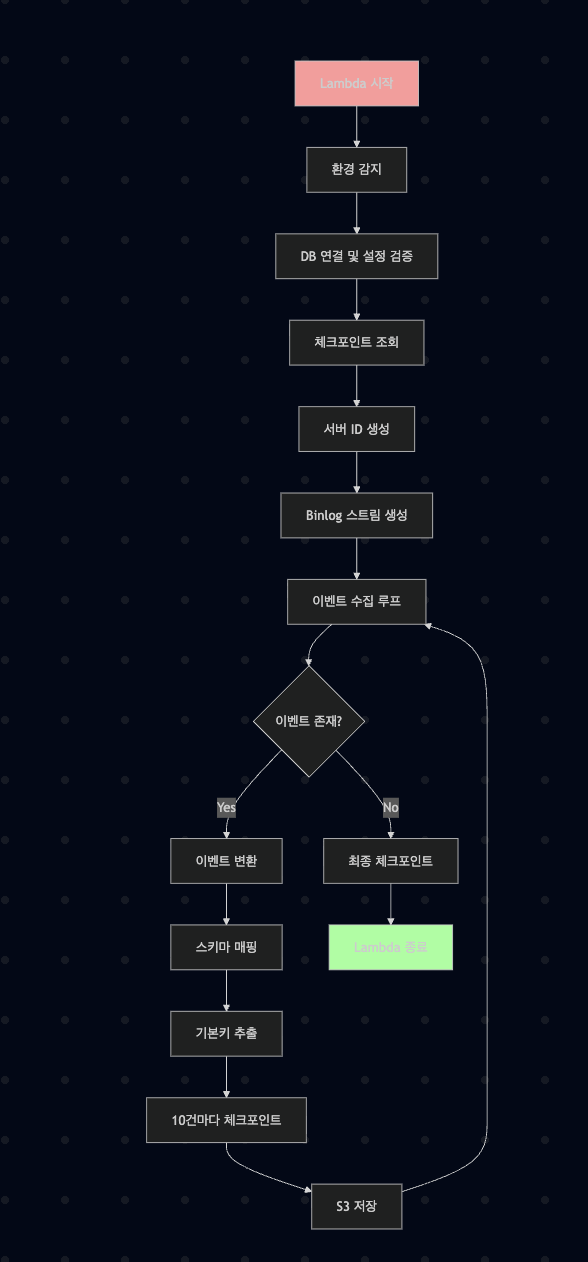
flowchart TD
A[Lambda 시작] --> B[환경 감지]
B --> C[DB 연결 및 설정 검증]
C --> D[체크포인트 조회]
D --> E[서버 ID 생성]
E --> F[Binlog 스트림 생성]
F --> G[이벤트 수집 루프]
G --> H{이벤트 존재?}
H -->|Yes| I[이벤트 변환]
I --> J[스키마 매핑]
J --> K[기본키 추출]
K --> L[10건마다 체크포인트]
L --> M[S3 저장]
M --> G
H -->|No| N[최종 체크포인트]
N --> O[Lambda 종료]
style A fill:#ff9999
style O fill:#99ff992. 데이터 변환 파이프라인
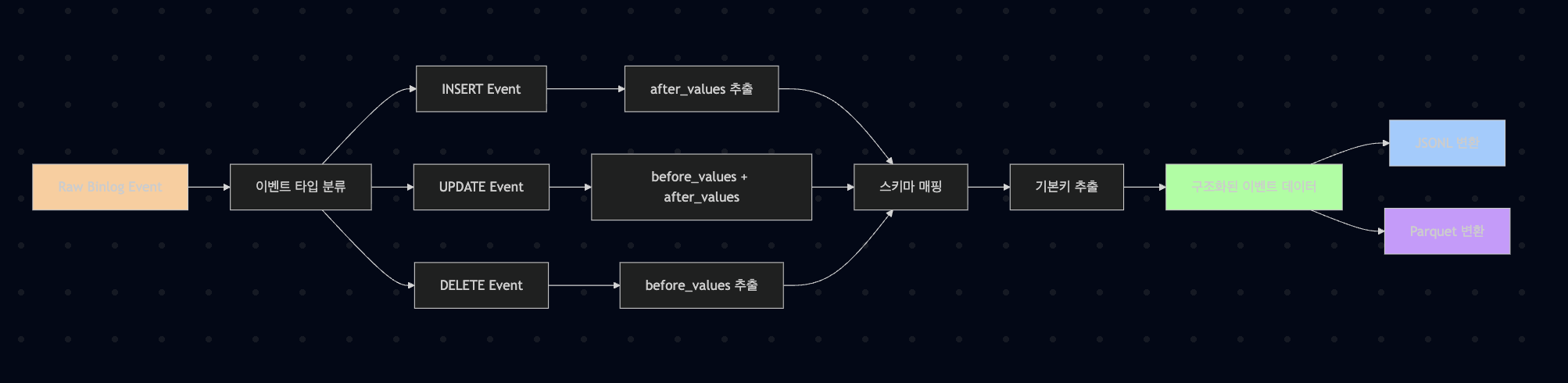
graph LR
A[Raw Binlog Event] --> B[이벤트 타입 분류]
B --> C[INSERT Event]
B --> D[UPDATE Event]
B --> E[DELETE Event]
C --> F[after_values 추출]
D --> G[before_values + after_values]
E --> H[before_values 추출]
F --> I[스키마 매핑]
G --> I
H --> I
I --> J[기본키 추출]
J --> K[구조화된 이벤트 데이터]
K --> L[JSONL 변환]
K --> M[Parquet 변환]
style A fill:#ffcc99
style K fill:#99ff99
style L fill:#99ccff
style M fill:#cc99ff🛠️ 기술적 설계 결정사항
1. S3 저장 경로 설계 및 비용 최적화
Parquet 경로 구조 (Athena 파티션 최적화)
s3://aurora-history-binlog/
└── env=dev/db=db-name/schema=schema-name/date=2025-01-15/
└── PUSH_LOG_20250115_143022.parquet왜 이렇게 설계했는가?
🎯 Parquet 경로: Athena 파티션 최적화
- 쿼리 성능: 파티션 프루닝으로 쿼리 성능 향상
- 비용 절약: 필요한 파티션만 스캔하여 비용 절약```
파티션 키 구조:
1. env = 'prod' # 환경별 분리 (dev/stage/prod)
2. db = 'database_name' # 데이터베이스별 분리
3. schema = 'schema_name' # 스키마별 분리
4. date = '2025-09-15' # 날짜별 분리 (가장 세밀한 파티션)Athena 쿼리 비용 최적화
파티션 프루닝 효과:
-- 비효율적인 쿼리 (전체 테이블 스캔)
SELECT * FROM binlog_event
WHERE table_name = 'table_name' AND pk_value = '32811'
-- 최적화된 쿼리 (파티션 프루닝)
SELECT * FROM binlog_event
WHERE env = 'prod' -- 파티션 1: 환경
AND database_name = 'database_name' -- 파티션 2: 데이터베이스
AND schema_name = 'schema_name' -- 파티션 3: 스키마
AND event_date BETWEEN '2025-09-01' AND '2025-09-30' -- 파티션 4: 날짜
AND table_name = 'table_name'
AND pk_value = '32811'env=prod/db=database_name/schema=table_name/date=2025-09-01/ ← 스캔됨
env=prod/db=database_name/schema=table_name/date=2025-09-02/ ← 스캔됨
...
env=prod/db=database_name/schema=schema_name/date=2025-09-30/ ← 스캔됨
env=prod/db=database_name/schema=schema_name/date=2025-10-01/ ← 스캔 안됨 (범위 밖)
env=dev/db=database_name/schema=schema_name/date=2025-09-15/ ← 스캔 안됨 (환경 다름)
Java/Kotlin Spring 개발자 황재명입니다.