Datadog → AI 수정 → GitLab MR 자동화
들어가기전 내가 한 작업과 AI가 한 작업
내가 한 작업
- 5개 인터페이스 분해, 의존성 방향, 계층 구조, 워크 플로우
- 수집 → 분류 → 백로그 → 수정 → MR의 파이프라인 설계
- 2단계 분류 게이트, 캐싱 전략, 메서드 단위 추출 등 기능과 목적 정의
- "수정 정확도를 높여라", "토큰 비용을 줄여라" 같은 목적을 제시하고 최신 연구를 찾아 적용하도록 지시
- 테스트 결과 분석 및 개선점 도출
- 자동화 범위 설정
- 목적 정리 및 이유
AI가 한 작업
- 목적에 맞는 최신 연구/논문을 찾아서 설계에 반영 (Meta-Harness, 토큰 최적화 등)
- 설계 명세에 따라 인터페이스, 구현체, 비즈니스 로직, 테스트 코드 작성
- 스택트레이스를 보고 실제 운영 코드의 버그 수정
- 실패한 수정 시도를 분석해 다음 전략 제안 (Counterfactual Diagnosis)
설계 문서를 작성하고, 테스트 결과를 분석하고, 아키텍처 방향을 잡는 것은 사람의 몫이다. AI는 그 설계대로 구현하고, 정해진 범위 안에서 코드를 수정하는 도구다.
왜 만들었는가
이전에 Notion 백로그를 파싱해서 스펙과 프롬프트를 자동 생성하는 파이프라인을 만들어 봤다. 결과는 실패였다. 트레이드오프나 비즈니스 로직이 요구사항대로 반영이 잘 안 됐고, human review 단계에서 결국 매번 수정 요청을 다시 해야 했다.
그 경험에서 하나 배운 게 있다. AI 자동화가 통하려면 "정답이 하나인 영역"이어야 한다.
신규 기능 구현이나 비즈니스 로직 변경은 정답이 하나가 아니다. 왜 이 방향으로 만드는지, 어떤 트레이드오프가 있는지, 기획자와 개발자가 함께 고민해야 한다.
반면 서비스 운영 중 발생하는 오류(NullPointerException, NumberFormatException 등)와 N+1 쿼리 문제는 다르다. 문제가 명확하고, 테스트 케이스가 분명하다. 스택트레이스가 정확히 어디서 문제가 발생했는지 가리키고, 오류 메시지가 무엇이 잘못됐는지 알려준다. 수정 방향에 트레이드오프가 없다.
그런데 이 작업에도 개발자가 매번 같은 절차를 반복한다.
- Datadog 알림 확인 (슬랙 또는 이메일)
- Error Tracking 화면에서 스택트레이스 열기
- 해당 코드 찾기 — IDE에서 클래스명 검색, 메서드 위치 특정
- 원인 분석 — 왜 NPE가 났는지, 어떤 경로에서 null이 들어왔는지
- 코드 수정 — Optional 처리, null 체크, @EntityGraph 추가 등
- 테스트 작성 또는 기존 테스트 수정
- PR 작성 — 변경 사유, 스택트레이스, Datadog 링크 첨부
- 리뷰 요청 → 머지
Datadog, Sentry 같은 관측 도구는 오류를 발견해 준다. 하지만 수정까지 해 주지는 않는다.
반대로 GitHub Copilot, Cursor 같은 AI 코딩 도구는 코드를 수정해 준다. 하지만 "무엇을 수정해야 하는지"를 사람이 판단해서 알려줘야 한다.
발견과 수정 사이의 빈 공간을 메우는 파이프라인을 만들었다. 이전 시도에서 실패한 "기능 구현 자동화"가 아니라, 문제가 명확한 오류 수정 자동화다.
자동화 범위를 먼저 정했다
모든 오류를 자동으로 고칠 수 있다는 뜻이 아니다. 자동화가 통하는 영역은 다음 세 조건을 동시에 만족하는 경우로 한정했다.
- 증거가 있다 — 스택트레이스가 정확한 위치를 가리킨다
- 수정 패턴이 정형화되어 있다 —
Optional.get()→ifPresent(), N+1 →@EntityGraph등 - 비즈니스 판단이 필요 없다 — "이 로직을 어떻게 바꿀 것인가"가 아니라 "이 버그를 어떻게 고칠 것인가"의 문제다
이 조건을 벗어나는 작업 — 신규 기능, 비즈니스 로직 변경, DB 스키마 수정 — 은 처음부터 자동화 범위에서 제외했다. 이전 시도에서 배운 교훈이다.
AI에게 최신 연구를 찾아서 적용하라고 했다
이 프로젝트는 AI(Claude Code)로 개발했다. 내가 한 것은 기능과 목적을 정의한 것이고, 구현은 AI가 했다.
구현을 시키면서 두 가지를 요구했다.
첫 번째는 하네스 엔지니어링 적용이다. 나는 하네스 엔지니어링의 기능과 목적 — AI 수정이 실패했을 때 같은 실수를 반복하지 않도록 매 시도마다 접근 방식을 개선하는 것 — 을 알고 있었고, 이걸 적용하라고 지시했다. AI가 Stanford IRIS Lab의 Meta-Harness 연구를 참고해서 실패-학습 루프를 구현했다.
두 번째는 AI 토큰 비용 절감이다. 이쪽은 구체적인 방법론을 지정하지 않고, "토큰 비용을 줄여라, 최신 연구와 논문을 찾아서 적용해라"라고 지시했다. AI가 토큰 효율에 관한 연구들을 참고해서 메서드 단위 소스코드 추출, 캐싱 전략 등을 구현했다.
논문을 내가 직접 읽고 이해해서 설계에 반영한 것이 아니다. 내 역할은 기능과 목적을 정의하고, AI가 구현한 결과가 그 목적에 맞는지 검증하는 것이었다.
전체 워크플로우
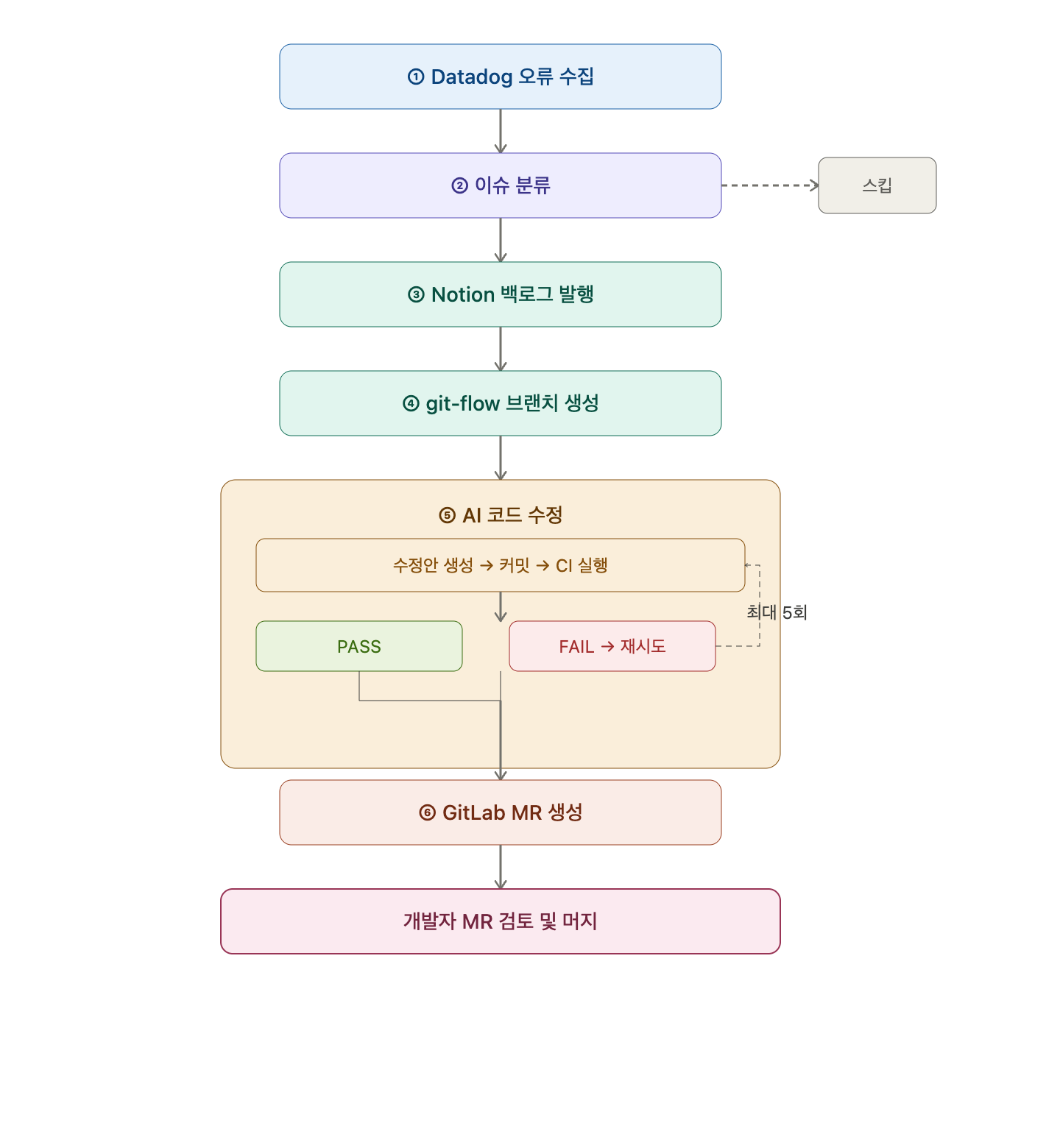
Datadog에서 오류를 읽는 것부터 GitLab MR을 여는 것까지 사람 손이 닿지 않는다. 개발자가 개입하는 시점은 MR 검토 한 번뿐이다.
① Datadog REST API로 오류와 N+1을 수집한다
- Error Tracking API로 NPE, SQL 예외 수집
- Spans Analytics API로 N+1 쿼리 탐지
- 수집된 오류를 서비스별, 유형별로 정리
② 수정할 가치가 있는 이슈만 분류한다
1차 — 규칙 필터
- FE 서비스, HTTP 4xx, Business/Validation 예외 → 스킵
- NPE/SQL → HIGH, N+1 → MEDIUM
2차 — AI 사전 검증
- 소스코드를 함께 보고 실제 코드 버그인지 판단
NEEDS_FIX→ 수정 진행 /NOT_CODE_ISSUE,BUSINESS_EXCEPTION→ 스킵
③ Notion 백로그를 발행한다
- 등록된 Notion DB 템플릿 속성을 읽어 포맷에 맞춰 title과 body만 채워서 생성
- 백로그 ID 발급
④ git-flow 브랜치를 생성한다
fix/{service}-{error_type}-{date}-{attempt}- 예:
fix/order-service-NPE-20260418-1
⑤ 로컬 프로젝트에서 AI가 코드를 수정한다
- 스택트레이스에서 메서드 단위 소스코드 추출
- CLAUDE.md에서 프로젝트 코딩 컨벤션 로딩
- Datadog MCP Server로 추가 트레이스/로그 탐색 (스택트레이스만으로 부족할 때)
- AI 수정안 생성 → 커밋 → CI 파이프라인 실행
- PASS → ⑥으로
- FAIL → 실패 원인 분석 → 전략 변경 → 재시도 (Meta-Harness 루프, 최대 5회)
⑥ MR을 올린다
- GitLab MR 자동 생성
- 개발자가 MR을 검토하고 머지한다 ← 유일한 사람 개입 지점
아키텍처
인터페이스로 분리한 이유
Datadog을 Sentry로, Notion을 Jira로, GitLab을 GitHub으로 바꿔도 비즈니스 로직은 안 바뀌어야 한다. 모든 외부 연동을 5개의 인터페이스(ABC)로 추상화했다.
| 인터페이스 | 역할 | 교체 가능 예시 |
|---|---|---|
| ErrorCollector | 오류 수집 | Datadog → Sentry, New Relic |
| AIAgent | AI 코드 수정 + 사전 검증 + 하네스 제안 | Claude → GPT, Gemini |
| VCSClient | 브랜치/커밋/MR/파이프라인 | GitLab → GitHub |
| IssueTracker | 백로그 등록/업데이트 | Notion → Jira, Linear |
| HarnessStore | 수정 시도 트레이스 저장 | 파일시스템 → DB |
예를 들어 AIAgent는 세 가지 메서드만 정의한다.
class AIAgent(ABC):
@abstractmethod
def fix_code(self, context: ErrorContext) -> FixResult: ...
@abstractmethod
def propose_harness(self, traces: List[ExecutionTrace]) -> Harness: ...
@abstractmethod
def validate_issue(self, context: ErrorContext) -> ValidationResult: ...비즈니스 로직(MetaHarnessLoop, Classifier 등)은 이 인터페이스들에만 의존한다. 구체 구현체는 CLI 조립 시점에서 주입한다. 드라이런 모드에서는 LocalVCSClient를, 실전에서는 GitLabClient를 넣는데, 비즈니스 로직 쪽은 어떤 구현체가 들어왔는지 모른다.
의존성 방향
- CLI / Hook → FullRunner / StepRunner → 비즈니스 로직 → 인터페이스 ← 구현체
상위 계층은 하위 인터페이스에만 의존한다. 구현체가 인터페이스를 구현할 뿐, 비즈니스 로직이 구현체를 직접 참조하는 경우는 없다.
도메인 모델
시스템을 흐르는 데이터는 16개의 dataclass와 6개의 enum으로 정의했다. 흐름은 다음과 같다.
- Datadog API 응답 → ErrorEvent (서비스, 예외 클래스, 스택트레이스, 발생 횟수)
- Classifier → Issue (ErrorEvent + 계층, 심각도, 레포 정보)
- MetaHarnessLoop → ErrorContext (Issue + 메서드 단위 소스코드 + 이전 실패 전략 + 프로젝트 컨벤션)
- AIAgent → FixResult (수정 성공 여부, 변경 파일, diff)
각 단계에서 필요한 데이터만 담아서 넘긴다.
Datadog 연동
오류 수집 — Error Tracking API
Datadog Error Tracking은 운영 중 발생한 예외를 그룹화해 관리한다. Error Tracking API로 최근 7일 오류를 수집한다. 스택트레이스, 예외 클래스명, 발생 횟수, 최초 발생 시각이 함께 반환된다.
N+1 수집 — Spans Analytics API
Datadog APM Recommendations에서 N+1 패턴을 UI로 확인할 수 있지만, 해당 데이터는 공개 REST API로 직접 접근이 불가능하다.
Spans API로 동일한 데이터를 구성했다.
N+1 스코어 = count(DB 스팬) / cardinality(@trace_id)
트레이스당 평균 동일 쿼리 호출 횟수. 5 이상이면 N+1로 판정.
2단계 분류 — AI에게 다 넘기지 않는다
AI에게 모든 오류를 넘기면 비용과 시간 모두 낭비된다. 수정할 가치가 있는 이슈만 골라내는 게 먼저다.
1단계: 규칙 필터
class Classifier:
def _classify_error(self, event: ErrorEvent) -> Optional[Issue]:
if service_info.get("layer") == "FE":
return None # FE → BE 코드 수정 불가
if event.http_status in {400, 401, 403, 404, 422}:
return None # 4xx → 클라이언트 문제
if any(kw in event.exception_class for kw in ("Business", "Validation", "Domain")):
return None # 의도된 예외
# NPE → HIGH, SQL → HIGH, N+1 → MEDIUM2단계: AI 사전 검증
규칙을 통과한 이슈에 대해 AI가 소스코드를 함께 보고 최종 판단한다.
| 판정 | 의미 | 동작 |
|---|---|---|
NEEDS_FIX | 실제 코드 버그 | 수정 진행 |
ALREADY_FIXED | 이미 고쳐진 코드 | 스킵 |
BUSINESS_EXCEPTION | 의도된 예외 흐름 | 스킵 |
NOT_CODE_ISSUE | 인프라/DB/설정 문제 | 스킵 |
NEEDS_REVIEW | AI 판단 불가 | 개발자에게 위임 |
결과는 캐시에 저장된다. 스킵 판정은 7일, 수정 판정은 24시간 TTL로 분리했다. 수정 판정의 TTL이 짧은 이유는 코드가 바뀌면 판단도 바뀌어야 하기 때문이다.
Meta-Harness — 실패할 때마다 접근을 바꾼다
AI 코드 수정의 가장 큰 과제는 정확도다.
단순 재시도(Naive Retry)는 동일한 실패를 반복한다. 사람이 프롬프트를 수정하면 새로운 실패 유형에 다시 사람이 개입해야 한다. Meta-Harness는 이 문제를 풀기 위해 AI에게 무엇을 줄 것인가(하네스)를 매 시도마다 개선한다.
메서드 단위 추출
파일 전체를 AI에게 주면 비용이 폭증하고, 관련 없는 메서드를 "개선" 대상으로 오인하는 문제가 있었다. 스택트레이스에서 클래스와 메서드명을 파싱하고, 메서드 경계를 특정한 뒤, 해당 블록만 잘라서 AI에게 넘긴다. 수정 결과가 돌아오면 원본의 해당 영역만 교체한다. 500줄짜리 파일에서 46줄만 뽑아서 넘기는 식이다.
실패-학습 루프
- AI가 코드를 수정한다
- CI 파이프라인을 돌린다
- 실패하면 — 어떤 컨텍스트로 접근했는지, 왜 실패했는지 트레이스를 저장한다
- Counterfactual Diagnosis — 이전 시도의 어떤 결정이 실패를 유발했는지 AI가 분석한다
- 다음 시도의 전략을 갱신하고, 개선된 하네스로 재시도한다 (최대 5회)
단순 재시도와 다른 점은 접근 방식 자체가 바뀐다는 것이다.
def _improve_context(self, issue, related_code) -> ErrorContext:
"""이전 실패를 분석해 개선된 컨텍스트를 만든다."""
previous_runs = self._store.load_runs()
failed_traces = [r.execution_trace for r in previous_runs
if r.test_result == TestResult.FAIL]
if failed_traces:
improved = self._agent.propose_harness(failed_traces)
# Counterfactual Diagnosis 결과를 다음 시도의 컨텍스트에 주입
additional = "\n\n".join([
"## Counterfactual Diagnosis — 이전 실패 분석",
improved.description,
"## 다음 시도 구체적 전략\n" + improved.code,
])
return ErrorContext(issue=issue, related_code=related_code,
additional_context=additional)처음엔 메서드 단위로 수정하다가, 실패하면 호출부까지 범위를 넓히고, 그래도 안 되면 해당 패턴의 다른 사례를 참고해 전략을 바꾸는 것이 실제로 관찰됐다.
Rate Limit 페일오버
Claude가 rate limit에 걸리면 자동으로 다음 에이전트(Cursor 계정 1 → 2 → 3)로 전환하는 라우터를 만들었다. 모든 에이전트가 소진되면 작업을 중단한다. 무한히 재시도하지 않는다.
실제 드라이런 결과
로컬 git 브랜치에만 커밋하는 드라이런 모드로 실제 운영 코드를 대상으로 검증했다.
N+1 수정
- 입력 —
N+1 query detected: ExhibitionRepository.findAllByStatusCodeAndOperationTypeAndAutoType(트레이스당 평균 8회 반복) - AI 판단 — Spring Data JPA 연관 엔티티를 lazy로 가져오면서 N+1 발생
- 수정 — 리포지토리 메서드에
@EntityGraph(attributePaths = {...})추가. 수정 diff 2줄.
NPE 수정
- 입력 —
java.util.NoSuchElementException: No value present at Optional.get(...) - 수정 —
optional.get()→optional.ifPresent(::method)리팩터링
"수정 안 할 것"도 정확히 걸러낸다
PriceCacheService.expire:22 스택트레이스를 넣어보았다. @AllArgsConstructor로 의존성 주입을 받는 Spring Bean이라 코드 자체에 null 가능성이 없다. AI는 NOT_CODE_ISSUE로 판정하고, "Spring 컨텍스트 초기화 실패나 빈 등록 누락 등 DI 설정 문제로 판단됩니다"라고 사유를 남겼다.
수정하지 않아야 할 것을 수정하지 않는 능력이 이 시스템의 신뢰성을 결정한다.
테스트
618개 테스트, Phase별 검증
인터페이스 → 도메인 모델 → 구현체 → 비즈니스 로직 순서로 개발했고, 테스트도 같은 순서로 쌓았다. 각 Phase 테스트가 100% 통과해야 다음 Phase로 넘어갔다.
Phase 1 — 인터페이스 계약 (45개)
5개 인터페이스에 대해 추상 클래스 직접 인스턴스화 불가, 불완전 구현 불가, 완전 구현 시 올바른 타입 반환을 검증한다.
Phase 2 — 도메인 모델 (33개)
6개 enum 전수 검사, dataclass 필드 검증, 경계값(score 범위, occurrence_count 임계값) 검증.
Phase 3 — 구현체 (137개)
외부 API를 Mock으로 교체하고 각 구현체의 입출력을 검증한다. 가장 많은 테스트가 집중된 Phase다.
| 구현체 | 테스트 수 | 핵심 검증 |
|---|---|---|
| DatadogErrorCollector | 17 | API 응답 파싱, N+1 임계값, YAML 설정 주입 |
| NotionIssueTracker | 33 | 템플릿 복사, 속성 타입별 정규화(11개), 캐시 히트 |
| ClaudeCodeAgent | 19 | JSON 파싱 성공/실패 fallback, 프로젝트 스킬 포함 |
| GitLabClient | 11 | 브랜치/MR/파이프라인 CRUD |
| LocalVCSClient | 27 | 실제 git 명령어, 언어별 확장자 필터링 |
| FilesystemHarnessStore | 17 | round-trip 보존, 최고 점수 선택, 손상 파일 스킵 |
| AIAgentRouter | 10 | 전체 소진 에러, fallback 전환 |
Phase 4 — 비즈니스 로직 (58개)
| 모듈 | 테스트 수 | 핵심 검증 |
|---|---|---|
| Classifier | 16 | NPE→HIGH, FE→스킵, 4xx→스킵, Business 키워드→스킵 |
| MetaHarnessLoop | 45 | 1차 성공, 재시도 후 성공, 최대 재시도 실패, Counterfactual |
| ValidationCache | 14 | 핑거프린트 결정성, TTL 분기(7일/24시간), 만료 삭제 |
Phase 5 — 유틸리티 + 스킬 + Runner (345개)
| 모듈 | 테스트 수 | 핵심 검증 |
|---|---|---|
| StackTraceParser | 19 | Java/Python/JS/Kotlin 형식 파싱, 메서드 추출, merge |
| Language Detector | 38 | 9개 언어 감지, APM→project 우선순위 |
| Service Mapping | 36 | YAML 로딩, Datadog 쿼리 생성 |
| Runner + CLI | 141 | 파이프라인 상태 관리, 단계별 실행, 스케줄러, 캐시 신선도 |
| Caches | 21 | 수집 캐시 + 검증 캐시 TTL |
통합 테스트 — Mock 없이 실제 API 호출
환경변수 미설정 시 자동 스킵. 실제 Datadog API, Notion API, Claude Code CLI를 호출한다.
| 테스트 | 검증 |
|---|---|
test_collect_errors_real | Datadog Error Tracking API 실제 호출 |
test_collect_n1_issues_real | Datadog Spans Analytics API 실제 호출 |
test_create_and_update_backlog_real | Notion 페이지 생성 + 업데이트 |
test_fixes_npe | 실제 NPE → Claude 호출 → 로컬 코드 수정 + git 커밋 |
test_fixes_n1 | 실제 N+1 → Claude 호출 → @EntityGraph 추가 |
설계 결정
왜 파일시스템에 트레이스를 쌓는가
대안은 DB 또는 벡터 저장소였다. 파일시스템을 선택한 이유는 세 가지다.
- 투명성 — 어떤 시도가 왜 실패했는지 바로 볼 수 있다
- Meta-Harness 원 논문이 증명한 패턴 — filesystem 자체가 AI 컨텍스트로 들어가는 설계
- 교체 가능 — HarnessStore 인터페이스 뒤에 있으므로 DB로 바꿔도 비즈니스 로직은 안 바뀐다
상태 관리 — 중간에 죽어도 처음부터 다시 하지 않는다
각 단계 완료 시 결과를 파일로 저장한다. 네트워크 끊김이나 rate limit이 발생해도 직전 완료 지점부터 재개할 수 있다. CLI가 단계별 실행을 지원하는 것도 이 구조의 연장선이다.
Claude Code CLI — 왜 API가 아닌 subprocess인가
- 사용자 계정 기반 인증 — API 키를 별도 관리하지 않는다
- 스킬 시스템 접근 — CLI는 Claude Code의 스킬/도구 생태계와 연동된다
- 프로세스 격리 — AI의 상태가 메인 프로세스를 오염시키지 않는다
토큰 사용량 측정이 세밀하지 않고, API 대비 호출 오버헤드가 크다. 하지만 운영 관점의 단순성이 훨씬 컸다.
MCP 연동 — AI가 외부 데이터에 직접 접근한다
Datadog MCP Server를 Claude Code에 연결하면, AI가 코드를 수정하는 시점에 트레이스, 로그, 메트릭을 직접 조회할 수 있다. 파이프라인이 가져온 스택트레이스만으로 부족할 때, AI가 추가 맥락을 스스로 탐색하는 것이 가능해진다.
수집은 REST API로, 수정 시 탐색은 MCP로 — 역할이 분리되어 있다.
기술 스택
| 구분 | 기술 |
|---|---|
| 오류 수집 | Datadog Error Tracking API |
| N+1 탐지 | Datadog Spans Analytics API |
| MCP 연동 | Datadog MCP Server |
| 백로그 관리 | Notion API |
| AI 에이전트 | Claude Code (claude -p CLI) |
| 형상 관리 | GitLab API / LocalVCSClient |
| 언어 | Python 3.11+ |
| 하네스 방식 | Meta-Harness (Stanford) |
