2022-01-28(금) 11주차 5일
깃헙에서 소스 받아와서 gradle build ← 이게 컴파일 하는 거
외부에서 컴파일 된 걸 갖고 오면 자바 버전이 다를 수 있음
EC2에 git 설치
깃헙에서 클론해옴
리눅스 서버에서 빌드하고 ServerApp을 실행시킴
ClientApp으로 8888번 포트로 서버에 접속해서 통신해봄
AWS - EC2 리눅스 서버 구축
91-미니프로젝트 / 19 페이지
옛날에는 개발자가 컴파일 한 걸 운영서버에 다 올렸었는데
추적할 길이 없음
개발이 끝난 건 형상관리 서버에 올리고
형상 관리 서버에서 가져와서 build
형상 관리 서버에 올린 건 공식적인 거
누가 언제 어느 부분을 만졌다는 게 기록이 다 남기 때문에
문제가 발생했을 때 누가 그랬는지 다 추적할 수 있음
형상 관리 서버에 올라간 걸 받아서 운영서버에서 빌드하는 방법
Gradle 빌드 도구 사용
리눅스 서버는 윈도우가 아님. 이클립스 못 띄움
그래서 컴파일, 테스트, 실행파일을 만들어주는 빌드 도구가 필요 (Ant, Maven, Gradle)
바깥쪽에 내보낼 때 어떤 문자집합으로 인코딩되었는지
바깥쪽에서 읽어들일 때 어떤 문자집합으로 인코딩되었는지 미리 알려준다.
-Dfile.encoding=UTF-8 ← 공백 없이 적어야 됨
문자집합을 UTF-8로 지정하게 되면
JVM(UTF-16)이 바깥쪽으로 데이터(UTF-16)를 내보낼 때 그대로 내보내지 않고 UTF-8로 바꿔서 내보낸다.
바깥쪽에 있는 문자 데이터를 읽을 때 UTF-8로 되어있다고 가정하고 읽는다.
-cp = -classpath 클래스 파일 또는 패키지가 있는 폴더
혹시 리눅스에서 안 되면
java -Dfile.encoding=UTF-8 -cp bin/main com.eomcs.app1.ServerApp
java -cp bin/main com.eomcs.app1.ServerApp
java -Dfile.encoding=UTF-8 -cp ./build
혹시 리눅스에서 안 되면 현재 폴더를 못 찾으면
./ 써서 현재 폴더를 정확하게 명시
git\bitcamp-study\project-app1\app-server>
java -Dfile.encoding=UTF-8 -cp build
윈도우에서는 이렇게만 적으면 됨
app-server 라는 현재 폴더에서 build 라는 폴더를 찾으라는 거
git\bitcamp-study\project-app1\app-server>
java -Dfile.encoding=UTF-8 -cp bin/main
이클립스에서 컴파일 할 때는
app-server 밑에 bin 밑에 main
거기에 컴파일 한 클래스 파일을 둔다
어제는 Gradle이 컴파일 함
윈도우에서도 gradle build 됨
에러남
두번째는 에러 안 뜸
// 자바 소스를 컴파일 할 때 적용할 옵션
tasks.withType(JavaCompile) {
// 프로젝트의 소스 파일 인코딩을 gradle에게 알려준다.
// $javac -encoding UTF-8 ..
options.encoding = 'UTF-8'
// 소스 파일을 작성할 때 사용할 자바 버전
sourceCompatibility = '1.8'
// 자바 클래스를 실행시킬 JVM의 최소 버전
targetCompatibility = '1.8'
}gradle java options.encoding 검색
compileJava.options.encoding = 'UTF-8'
$ gradle clean : build 폴더를 날림
$ gradle cleanEclipse : eclipse 설정 파일 날림
↑ build 폴더 사라짐
gradle project 폴더 구조
91-미니프로젝트 / 20 페이지
① 이전 방식 = 한 개의 주프로젝트를 다루는 방식
프로젝트폴더/
-settings.gradle
-build.gradle
-src/settings.gradle과 build.gradle 설정 파일이 함께 있다.
현업 가면 대부분 이렇게 되어 있을 거임
② 최근 방식 = 다중 하위 프로젝트를 다루는 방식
프로젝트폴더/
-settings.gradle ← 프로젝트 기본 빌드 정보
-app/ ← 하위 프로젝트
-/src
-/build.gradle
-app-client/ ← 하위 프로젝트
-src/
-build.gradle빌드를 하게 되면 하위 프로젝트도 따로 빌드함
얘네가 하위 프로젝트임을 settings.gradle에 설정을 해야 됨
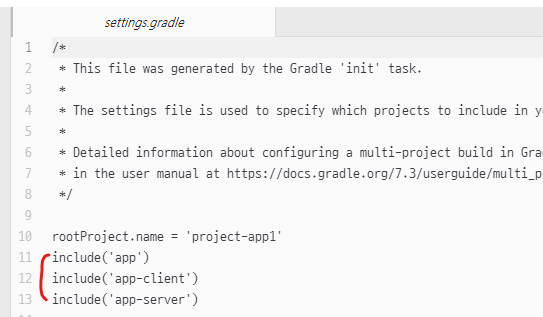
↑ 이걸 포함해서 build 하라고 적혀 있음
하위 프로젝트임을 설정
include('app-client')
include('app-server')
프로젝트 폴더 밑에 app 폴더가 있음
향후 하위 프로젝트가 더 만들어질 걸 대비해서 이런 구조로...
이전 방식은 settings.gradle, build.gradle이 같은 폴더에 있다. 메인 프로젝트 하나로 되어 있고 하위 프로젝트는 없다는 거.
최근 방식은 settings.gradle은 메인 프로젝트 밑에 있고
build.gradle은 서브 프로젝트 아래에 있는 거
bitcamp-study/project-app1 $ gradle build
소스파일 안에 한글 있으면 에러남
컴파일 할 때 소스파일이 utf-8로 되어 있다고 안 알려줘서 그럼
일단 다시 지우기
bitcamp-study/project-app1 $ gradle clean
compileJava.options.encoding = 'UTF-8'
project-app1 / app / build.gradle 파일에 추가
project-app1 / app-client / build.gradle 파일에 추가
project-app1 / app-server / build.gradle 파일에 추가
다시 gradle build 해보기
bitcamp-study/project-app1 $ gradle build
한글 관련해서 에러 안 뜸
↑ build 폴더 생김
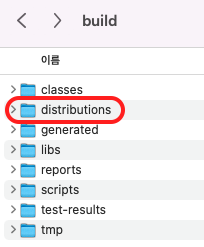
↑ distributions 친구한테 주는 실행 파일
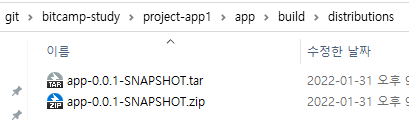
아예 압축해서 줌
tar 또는 zip
유닉스든 윈도우든 zip 다 됨
옛날에는 개발자가 자기 로컬 pc에서 빌드까지 다 끝낸 다음에
zip 파일을 운영서버에 올려서 실행했음
그런데 개발자가 zip 파일 안에 해킹 코드를 집어넣으면 안 되니까
깃헙에 올리면 누가 언제 올렸는지 기록이 다 남음
서버에서는 깃헙에 올라간 소스를 받아서 서버에서 빌드해서 실행하는 거
로컬에 있는 개발자 조작해도 기록이 다 남음
로컬에서 빌드하면 zip 파일까지 만들어줌
gradle build로 실행할 때는 각 프로젝트의 build 라는 폴더 밑에 classes라는 폴더 밑에 java 밑에 main에 클래스파일이 있다
이클립스로 개발할 때는 각 프로젝트의 bin이라는 폴더 밑에 main이라는 폴더 밑에 이클립스가 컴파일한 파일들이 있다
로컬에서 실행할 때는 어제처럼 안 하고 bin/main
git\bitcamp-study\project-app1>
java -Dfile.encoding=UTF-8 -cp bin/main com.eomcs.app1.ServerApp
패키지명 다 입력해야 됨
혹시 안 되면 bin/defualt
근데 보통 bin/main
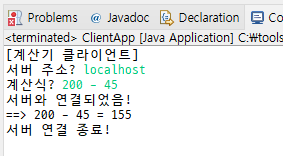
localhost
91-미니프로젝트 / 21 페이지
ClientApp <----------------> ServerAppIP 주소 = 127.0.0.1 = 진짜 IP 주소
집은 IP 주소가 또 바뀜
Socket socket = new Socket("localhost", 8888);서버와 연결될 때 클라이언트 소켓이 객체가 생성된다.
Socket socket = new Socket("localhost", 8888); // 서버와 연결될 때까지 객체를 생성하지 않는다.TCP/IP 통신
91-미니프로젝트 / 22 페이지
ClientApp
new Socket()
ClientApp
out.println("강사")
한 줄의 문자열을 보낸다. 줄바꿈 코드도 함께 보내진다.
out.println("강사\n") ← 줄바꿈 코드가 추가된다.
ServerApp은 줄바꿈 코드를 만날 때까지 읽어야 한다.
클라이언트는 데이터를 보내놓고 서버가 응답할 때까지 기다린다.
ServerApp
in.nextLine() ← 줄바꿈 코드를 만날 때까지 읽는다
줄바꿈 코드를 제거한 순수 텍스트만 리턴한다.
ServerApp
out.println(request + "님 반갑습니다.")
줄바꿈 코드도 함께 보내진다.
ClientApp
String response = in.nextLine();
줄바꿈 코드를 제거한 순수 텍스트만 리턴한다.
ClientApp
System.out.println("==> " + response);
ClientApp
socket.close();
서버와 연결을 끊는다.
SeverApp
socket.close();
클라이언트와 연결을 끊는다.
클라이언트와 연결이 끊어지면 그 다음 클라이언트와 연결하는 걸 반복해보자
연결 반복하는 거 해보자
ServerApp에 while (true) {} 넣기
package com.eomcs.app1;
import java.io.PrintStream;
import java.net.ServerSocket;
import java.net.Socket;
import java.util.Scanner;
public class ServerApp {
public static void main(String[] args) throws Exception {
System.out.println("[계산기 서버]");
// 1) 클라이언트 App의 연결을 준비한다.
ServerSocket serverSocket = new ServerSocket(8888);
while (true) {
// 클라이언트의 연결 요청을 승인한다.
// - 리턴 값은 클라이언트와 연결된 정보
System.out.println("클라이언트의 연결을 기다림!");
Socket socket = serverSocket.accept(); // 클라이언트가 연결될 때까지 리턴하지 않는다.
System.out.println("클라이언트와 연결됨!");
// 클라이언트와 데이터를 주고받을 입출력 도구를 준비한다.
Scanner in = new Scanner(socket.getInputStream());
PrintStream out = new PrintStream(socket.getOutputStream());
// 클라이언트와 주고받는 순서가 맞아야 한다.
String request = in.nextLine();
System.out.println("이름: " + request);
out.println(request + "님 반갑습니다.");
// 클라이언트와의 연결을 끊음
socket.close();
System.out.println("클라이언트 연결 종료!");
}
// 서버쪽 연결 도구 종료!
// serverSocket.close();
// System.out.println("서버 종료!");
}
}
↑ 종료되지 않고 그 다음 클라이언트 연결을 기다린다
서버를 종료하는 방법 : Ctrl + C
java -Dfile.encoding=UTF-8 -cp bin/main com.eomcs.app1.ClientApp [서버 주소][서버에 보낼 이름]
if (args.length != 2) {
System.out.println("프로그램 아규먼트가 누락되었습니다.");
System.out.println("사용법: ClientApp 서버주소 사용자이름");
return;
}

args[0], args[1]로 바꿔주기
Socket socket = new Socket(args[0], 8888); // 서버와 연결될 때까지 객체를 생성하지 않는다.// 서버에 데이터를 보낸다.
out.println(args[1]);이러면 유지보수할 때 직관성이 떨어짐
변수를 낭비하더라도
메모리를 더 쓰더라도
속도가 떨어지더라도
변수 메모리를 더 쓰더라도 유지보수에 소스코드를 이해하는 데 도움이 되고
메모리가 낭비되더라도 또는 실행속도가 떨어지더라도
이해하기 좋은 쪽으로 소스코드를 변경하자
더 직관적이다.
String serverAddress = args[0];
String userName = args[1];
Socket socket = new Socket(serverAddress, 8888);
out.println(userName);1시간 헤매면 5만원 날아가는 거
한 번 밖에 안 쓰는데 쓸데없이 왜 변수에 담았지? 이유는 가독성.
git\bitcamp-study\project-app1\app-client>
java -Dfile.encoding=UTF-8 -cp bin/main com.eomcs.app1.ClientApp localhost 오호라

노트북인데 연결됨
상위 네트워크에서 하위 네트워크로 안 감
하위에선 상위로 올라감
상위 공유기에 있는 걸 그대로 같이 쓰나봄
공유기 겸 와이파이면 서브넷을 따로 구성하지 않고 단일
명령어에 따라서 처리하는 걸로 바꾸자
args로 받지 말고 키보드 입력으로 받는 걸로 바꾸자
Scanner keyScan = new Scanner(System.in);
System.out.print("서버 주소? ");
String serverAddress = keyScan.nextLine();
System.out.print("이름? ");
String userName = keyScan.nextLine();
keyScan.close();키보드로 입력받으면 더이상 명령창으로 안 해도 됨
ClientApp은 이제 이클립스에서 실행
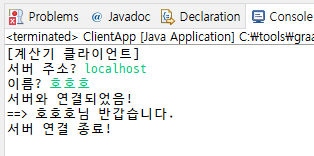
만들려고 하는 건 계산기니까 이름 대신 계산식을 받자
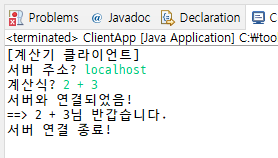
클라이언트는 끝남
이제 서버가 해야될 일은 계산식을 입력받으면
연산자와 피연산자를 쪼개서 실제 계산을 한 다음 결과를 리턴해야 됨
이제 ServerApp 보자
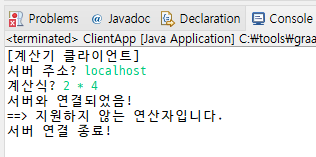
if (values.length != 3) {
out.println("계산식이 올바르지 않습니다.");
} else {
int a = Integer.parseInt(values[0]);
String op = values[1];
int b = Integer.parseInt(values[2]);
int result = 0;
switch (op) {
case "+":
result = a + b;
out.printf("%d %s %d = %d\n", a, op, b, result);
break;
case "-":
result = a - b;
out.printf("%d %s %d = %d\n", a, op, b, result);
break;
default:
out.println("지원하지 않는 연산자입니다.");
}
}
// 클라이언트와의 연결을 끊음
socket.close();socket.close();
응답 한 번 했으면 클라이언트와 연결 끊어야 됨
그게 상호간의 통신 규칙
데이터를 주고받는 규칙
프로토콜 : 규칙

순차적으로 요청을 처리할 때 문제점
91-미니프로젝트 / 23 페이지
앞에 있는 손님이 빠져야지 내가 주문함
이게 순차적으로 처리할 때 문제점
순차적으로 요청을 처리하기 때문에 이런 상황이 발생
🚨 순차적으로 요청을 처리할 때 문제점
만약 특정 요청을 처리하는데 시간이 오래 걸린다면
그 뒤의 요청은 계속 기다려야 한다.
✅ 해결책
주문 받는 사람을 늘린다
3000명으로 늘린다
손님이 들어오면 개별적으로 주문 받는 사람을 둔다
클라이언트 요청을 처리하는 작업을 별도로 수행하겠다
요청을 병행으로 처리
91-미니프로젝트 / 24 페이지
클라이언트가 서버에 접속을 하면 서버가 작업자를 생성
그리고 클라이언트는 생성된 작업자와 통신을 한다
또 다른 클라이언트가 서버에 접속
작업자를 스레드 라고 한다.
클라이언트1이 서버에 요청을 한다.
서버가 작업자를 생성해준다 new
클라이언트1은 작업자와 통신을 하면 된다.
클라이언트2 접속
서버가 작업자를 생성해준다
클라이언트2는 작업자랑 통신
이때 이 작업자를 "스레드(thread)"라고 한다.
스레드를 하면 순차적으로 처리하는 게 아니라
병행적으로 처리할 수 있다.
스레드는 어떻게 만드나
자바 프로그램이 스레드 만드는 게 굉장히 쉬움
스레드 만들기
91-미니프로젝트 / 25 페이지
Thread 라는 클래스가 있는데 얘를 상속받아서 MyTread를 만든다
Thread의 중요한 메서드
start() ← 스레드를 시작시키는 메서드
run()
Thread를 상속받아서 MyThread를 만들고 run() 메서드를 재정의한다.
병행으로 처리해야 하는 작업을 run() 메서드에 정의한다.
스레드를 스타트 시키고 싶을 때는 start() 메서드 사용하면 됨
start() 메서드가 내부적으로 run() 실행
직접 run()을 실행하면 안 됨
MyThread t = new MyThread()
t.run() ← X
t.start() ← O 내부적으로 run() 실행병행으로 처리해야 할 작업 : 클라이언트 계산을 처리하는 작업
project-app1-server에서 Worker 클래스 생성
package com.eomcs.app1;
public class Worker extends Thread {
}
Socket을 아예 받기
클라이언트와 연결된 socket을 아예 받기
package com.eomcs.app1;
import java.net.Socket;
public class Worker extends Thread {
Socket socket;
public Worker(Socket socket) {
this.socket = socket;
}
@Override
public void run() {
}
}ServerApp에서 입출력 도구 잘라내서 붙여넣기
서버가 하는 게 아니라 작업자가 하는 거
package com.eomcs.app1;
import java.io.PrintStream;
import java.net.Socket;
import java.util.Scanner;
public class Worker extends Thread {
Socket socket;
public Worker(Socket socket) {
this.socket = socket;
}
@Override
public void run() {
try {
Scanner in = new Scanner(socket.getInputStream());
PrintStream out = new PrintStream(socket.getOutputStream());
} catch (Exception e) {
e.printStackTrace();
}
}
}e.printStackTrace();
언제 어떤 메서드를 호출하다가 예외가 떴는지
마지막으로 어떤 메서드를 호출하다가 예외가 떴는지
순서대로 풀어서 출력
클라이언트가 보낸 계산식을 읽어야 됨
String request = in.nextLine();
읽은 걸 분해해야 됨
String[] values = request.split(" ");
서버가 하는 게 아니라 작업자가 하는 거
ServerApp에서 Worker로 복사해 온 부분은 지우기
스레드를 만들 때 socket을 주고
작업자는 클라이언트와 연결된 socket을 가지고
입출력 스트림을 얻고
클라이언트가 보내온 걸 읽어서
그걸 공백으로 잘라서 연산자와 피연산자로 쪼개고
쪼갰는데 3개가 아니야
정상적이야
// 클라이언트의 요청을 처리할 작업자를 만든다.
Worker worker = new Worker(socket);
worker.start(); // 작업자에게 일을 시킨 후 즉시 리턴한다.작업자에게 일을 시킨 후 즉시 리턴한다.
즉시 다음 클라이언트 연결을 기다린다.
작업자 일이 끝날 때까지 기다리는 게 아니라 즉시 다음 클라이언트 연결을 기다린다.
한 작업자가 시간이 오래 걸리더라도 다른 사람들은 전혀 상관 없음
병행하고 병렬은 다름!!
CPU 스케줄링 - ① 순차 처리 방식 - 옛날 DOS 시절
91-미니프로젝트 / 26 페이지
병행(concurrent)
CPU (Central Processing Unit) : 중앙 처리 장치
CPU 스케줄링
DOS ← 명령창
깜박이는 게 프롬프트
다음 프롬프트가 안 뜨기 때문에 기다려야 됨
무한루프에 빠지면 어떡합니까?
프로그램이 영원히 실행됨
컴퓨터 껐다 켜야됨
싱글태스킹 방식
🔹 순차 처리 방식
옛날 DOS 시절 + Windows 3.x 시절
① Single Tasking
② 비선점형 운영체제 ← CPU의 해제를 프로세스가 한다.
• CPU의 해제 → 사용을 마침
CPU가 해제되어야 다른 목수가 쓸 수 있음
• 프로세스 ← 실행 중인 프로그램
목수 : 프로그램
망치 : CPU
망치관리자 : OS
목수1이 망치를 놓을 때까지 대기
망치를 못 갖는다.
망치관리자 : OS
빌려줄 때 한 번. 완전하게 망치를 통제 안 함.
목수1이 사용을 끝낼 때까지 강제로 망치를 못 뺏음 (비선점형 운영체제)
운영체제가 통제 권한이 없음
목수 : 프로그램
설치된 프로그램인지 실행중인 프로그램인지 알 수 없음
실행 중인 프로그램 ⟹ '프로세스'
설치된 프로그램 ⟹ '프로그램' 또는 '어플리케이션'
'프로그램' 추가/제거
'프로세스' 추가/제거 아님
작업관리자에서 실행 중인 프로그램을 '프로세스'라고 한다
운영체제가 통제 권한이 없음
CPU
• 16 bit
MS-DOS
Windows 3.x ← OS 아님. 윈도우 관리자.
MS-DOS
• 32 bit
운영체제가 통합돼서 나온 게 Windows 95 ← OS
망치를 놓을 때까지 절대 다른 프로그램이 망치를 사용할 수 없음
CPU 스케줄링 - ② 병행 처리 방식 - Windows 95부터
91-미니프로젝트 / 27 페이지
🔹 병행 처리 방식
Windows 95부터
1. Multi-Tasking
2. 선점형 운영체제 ← CPU의 해제를 OS가 한다.
망치(CPU)
망치관리자가 강제로 사용 중지
목수2가 사용할 수 있도록 사용을 허락
목수2가 실행 상태가 되고 목수3이 대기 상태가 된다.
목수가 망치를 놓을 때까지 기다리는 게 아니라
OS가 CPU를 줄 때까지 기다린다. → CPU 해제를 OS가 한다. (선점형 운영체제)
CPU를 어느 프로세스에게 어느 정도 맡길 건지
그 시간을 관리하는 걸 CPU 스케줄링이라고 한다.
Multi-Tasking에서 가장 중요한 건
CPU를 어떤 식으로 맡길 건지
CPU의 사용시간을 어떻게 관리할 건지 그 정책에 따라서 실행하는 게 다름
Priority 스케줄링 방법 : 우선순위 중심의 스케줄링 방법
우선순위가 높은 프로그래밍에게
우선순위가 낮은 프로그래밍에게
✅ 스케줄링 방식
① Priority + Aging : Unix / Linux
우선순위가 높은 프로세스에게 더 자주 CPU를 배정
② Round-Robin (RR) : Windows
모든 프로세스에게 CPU 배정을 균등하게 배분
하나의 CPU를 여러 프로세스가 나눠서 쓰는 방법
클라이언트 요청을 병행으로 처리
91-미니프로젝트 / 28 페이지
CPU
Worker Worker Worker Worker
↑ ↑ ↑ ↑
| | | |
↓ ↓ ↓ ↓
Client Client Client ClientWorker 라는 스레드가 여러 개 있다
클라이언트와 연결되어 내부적으로 작업
클라이언트와 통신하는 게 Worker 라는 스레드
그런데 CPU가 1개
CPU 코어가 여러 개
코어가 많을 수록 병행적으로 처리하기 쉬워짐
현대의 대부분의 어플리케이션은 동시에 여러 기능을 실행해야 되는 경우가 많음
CPU 속도가 빠른 게 중요한 게 아니라 CPU 코어가 많은 게 중요
CPU가 많이 있는 게 실행속도를 빠르게 한다.
CPU 스케줄링 방식에 따라 스레드에게 배정
마치 동시에 진행되는 것처럼 보이지만
스레드를 통해서 멀티 태스킹
스레드에 관련된 내용은 나중에 또 배운다
concurrent
com.eomcs.concurrent
동기화 처리 방법
통신하는 이유?
프로그램의 기능을 서버쪽으로 옮겨 놓으면 클라이언트의 기능이 추가되더라도 클라이언트는 변경할 필요 없다
Calculator App.을 C/S 구조로 전환하기
91-미니프로젝트 / 16 페이지
91-미니프로젝트 / 11 페이지
Calculator App이 원래 standalone 프로그램이었는데
실제 작업을 하는 서버 프로그램과 사용자와 소통하는 클라이언트 프로그램으로 쪼갰다
Calculator App을 Client/Server 구조로 바꾸게 되면
사용자는 ClientApp을 사용한다
실제 작업은 서버가 한다
ClientApp은 사용자에게 UI 제공
ServerApp은 작업을 처리. 계산 작업을 수행.
ServerApp에서 계산 작업을 수행하고
ClientApp은 사용자가 계산식을 입력한다거나 계산식의 실행 결과를 출력한다거나 UI 제공
이 방식으로 바꾸게 되면 기능이 바뀌더라도 서버쪽만 바꾸면 된다
원래 목적을 잊지 말기
열심히 네트워킹을 적용했는데 왜 적용했는지 잊어버리면 의미가 없다
잘 쓰고 있었는데 왜 쪼갰을까?
Client / Server Application Architecture의 이점
91-미니프로젝트 / 29 페이지
사용자 <----> Client
사용자 <----> Client
사용자 <----> Client <<server>> Application
사용자 <----> Client
사용자 <----> Client ① 기능 추가
기능을 추가/변경/삭제할 때 서버쪽만 바꾸면 된다
각 PC에 프로그램을 재설치할 필요가 없다
Thin Client
클라이언트는 UI 처리만 담당하기 때문에 H/W 성능이 높을 필요가 없다
⟹ H/W 유지 비용 절감
예) Chrome book
크롬북
크롬 OS
하드디스크도 없음
요즘 다 클라우드로 저장
Worker에서 곱하기 기능 추가하기
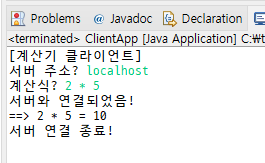
새 기능이 추가돼도 서버쪽만 바꾸면 됨
각 PC에 프로그램을 재설치할 필요가 없다
ClientApp에서 서버 주소랑 계산식을 합쳐버리자
String substring(int begin, int end)
문자열에서 해당 범위에 있는 문자열을 반환한다.
주어진 시작 위치부터 끝 위치 범위의 문자열을 얻는다.
이때, 시작 위치는 문자의 범위에 포함되지만, 끝 위치의 문자는 포함되지 않는다.
String substring(int begin)
시작 위치만 주는 경우 문자열 끝까지 포함
// ClientApp
System.out.print("요청(형식: 서버주소/연산자/값1/값2): ");
String input = keyScan.nextLine();
int slashPos = input.indexOf("/");
String serverAddress = input.substring(0, slashPos);
String queryString = input.substring(slashPos + 1);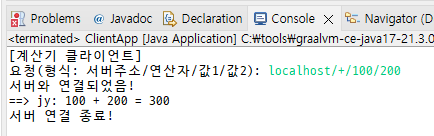
URL이 이런 형식임
https://en.dict.naver.com/search?query=hello
앞부분이 서버, 뒷부분이 명령
웹 브라우저 주소창에 서버 URL과 경로를 주면 웹 브라우저는 주소를 잘라서
서버 주소로 접속한 다음에 나머지 문자열을 서버에 전달한다
그럼 그쪽 서버에서 받은 문자열을 잘라서 처리를 하는 거
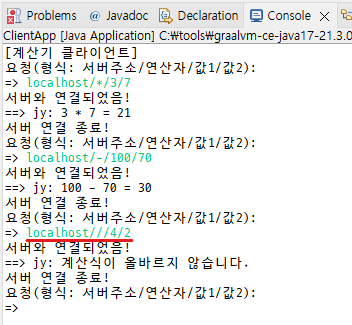
나누기 처리가 안 됨...
나누기 기호를 그대로 보내면 안 됨
다른 형식으로 바꿔서 보내야 됨
보내는 데이터의 인코딩/디코딩 필요성
91-미니프로젝트 / 30 페이지
보내는 데이터 형식 : 연산자/값1/값2
/ : 연산자와 피연산자를 구분하는 문자
연산자: +, -, *, /
🚨 / 문자의 경우 연산자와 피연산자를 구분할 때 사용하는 문자와 같기 때문에 그냥 사용할 수 없다. 다른 문자로 바꿔야 한다.
원래 문자 : /
바꾼 문자 : %2F (아스키코드)
encoding : 원래 형식을 다른 형식으로 바꾸는 것
decoding : 원래 형식으로 되돌리는 것
첫 번째 문자가 /일 경우 %2f로 교체한다.
boolean startsWith(String prefix)
주어진 문자열(prefix)로 시작하는지 검사한다.
String replaceFirst(String 지정된 문자열, String 새로운 문자열)
문자열 중에서 지정된 문자열과 일치하는 첫 번째 문자열만 새로운 문자열로 변경한다. 바꾼 문자열을 반환한다.
queryString = queryString.replaceFirst("/", "%2f")
String은 이뮤터블
리턴한 값을 다시 변수에 담는다
String 객체는 이뮤터블 객체
한 번 값이 설정되면 안 바뀜
새로운 String을 만들어서 리턴하는 거
// ClientApp
// 만약 연산자가 / 일 경우 %2f 문자로 교체한다.
if (queryString.startsWith("/")) {
queryString = queryString.replaceFirst("/", "%2f"); // 서버에 보내는 데이터 형식에 어긋나지 않도록 인코딩한다
}// ServerApp
String op = values[0];
if (op.equals("%2f")) {
op = "/"; // %2f 문자열을 원래의 문자인 / 로 디코딩한다.
}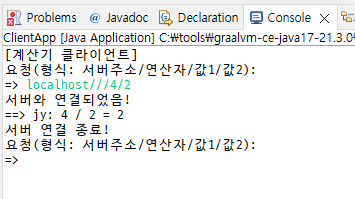
나누기 잘 된다
기존에 이미 사용되고 있는 문자인 경우에
그냥 보내지 말고 다른 형식으로 바꿔서 보내자
받는 쪽에서는 디코딩해서 쓴다
보내는 데이터의 인코딩/디코딩 필요성 예
91-미니프로젝트 / 31 페이지
입력값 ---> 보내는 데이터 ---> 받은 데이터 ---> 원래 값
//12/4 %2f/12/4 %2f/12/4 //12/4
인코딩 디코딩
Client Server🚨 나누기 연산자와 구분 문자 사이에 충돌이 발생
⟹ 클라이언트에서 / 문자를 %2f 문자열로 특별히 변환한다. 인코딩(encoding)
⟹ 서버에서 %2f → / 디코딩(decoding)
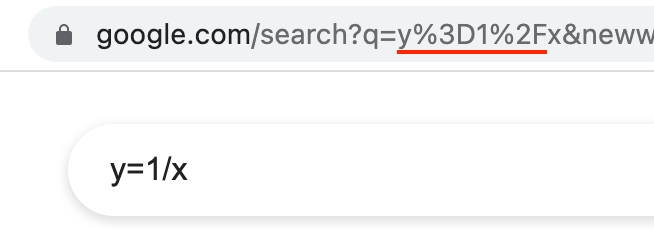
원래 ? = / 는 URL에서 사용되는 문자이다.
그래서 = 대신 특별한 문자로 바꾸고
/ 대신 특별한 문자로 바꾼다
URL에서 사용되는 문자는 그대로 쓸 수 없으니까
URL 인코딩이라고 하는 특별한 규칙에 따라서 바꿔서 서버에 보내고
서버쪽에서는 거꾸로 URL 인코딩된 문자를 URL 디코딩을 해서 쓴다
이것이 URL 인코딩을 하는 이유
URL에서 이미 어떤 목적으로 사용되는 문자는 그대로 보낼 수 없음
그래서 특별한 문자열로 바꾼다
"%2f"으로 인코딩 했으면 디코딩할 때 "%2F"로 하면 안 됨
대소문자를 구분함
URLEncoding 과 URLdecoding
91-미니프로젝트 / 32 페이지
Web Browser --------> Web Server
https://google.com/search?g=y=1/x
URL을 규칙에 따라 자를 때 문제 발생!
✓ URL 형식에서 특정 목적으로 사용하는 문자와 충돌이 발생할 경우
지정된 규칙에 따라 변환한다.
지정된 규칙에 따라 변환 ⟹ URLEncoding
https://google.com/search?g=y=1/x
URL의 / 문자, = 문자와 충돌 발생!
충돌? ⟹ URL을 규칙에 따라 자를 때 문제 발생!
https://google.com/search?g=y=1/x 입력
↓
Web Browser
↓
https://www.google.com/search?q=y%3D1%2Fx로 변환해서 보냄
↓
Web Server
↓
https://google.com/search?g=y=1/x로 다시 변환해서 리턴
ASCII 코드
URLEncoding과 URLDecoding은 우리가 하는 거 아님
URLEncoding은 웹 브라우저가 하고
URLDecoding은 웹 서버가 한다
자바스크립트에서 AJAX로 데이터를 보낼 때는 브라우저가 처리하는 게 아니라서
encodeURIComponent() 메서드로 직접 인코딩 해야 됨
주소창이 왜 저렇게 바뀌는지 이유는 알기
Socket을 이용한 통신 프로그래밍
Multi-Threading
데이터 encoding/decoding
클라이언트를 웹 브라우저로 대체하고
서버를 웹 서버로 대체하면
더 이상 Socket 프로그램 필요 없고
인코딩 디코딩 프로그램을 짤 필요 없음
개발자는 어떤 프로그램을 짤 것인지 기능에만 집중하면 됨
C/S → Web App.
웹 브라우저로 대체하려면 웹 브라우저가 원하는 형식대로 HTTP 형식대로 만들어야 됨
서버는 Spring Boot를 도입
스프링부트 계산기로 최종 완료된다
이게 스프링부트가 존재하는 이유
스프링부트를 사용하는 이유
이게 웹 기술을 사용하는 이유
아 이래서 웹 프로그래밍을 하는구나
왜 그 기술을 사용하느냐
com.eomcs.basic.ex02.Exam0160.java
String - mutable vs immutable 객체
String 클래스의 메서드는 원본 인스턴스의 데이터를 변경하지 않는다.
다만 새로 String 객체를 만들 뿐이다.
mutable 객체 : StringBuffer, StringBuilder
immutable 객체 : String
우리 서버를 웹 서버로 만들자
ServerApp을 HTTP 서버로 변경한다.
10단계: 웹 기술 도입 - 웹 브라우저 사용하기
91-미니프로젝트 / 33 페이지
ClientAppb ------ ServerApp
나름의 규칙에 따라 데이터를 주고 받는다.
규칙 : 통신 규칙 ⟹ 프로토콜(protocol)
ClientApp을 Web Browser로 교체할 거
Web Browser는 지금의 ServerApp과 통신할 수 없다. 규칙이 다르다.
ServerApp을 변경해야 된다.
웹 브라우저가 HTTP 규칙에 따라서 요청
HTTP 규칙에 따라서 응답
🔹 HTTP (HyperText Transfer Protocol)
Hyper : 고수준의
웹 브라우저와 웹 서버 사이에 데이터를 주고 받는 통신 규칙
🔹 URI (Uniform Resource Identifier)
① URL (Uniform Resource Locator)
자원의 위치를 기술하는 방법을 통일한 것
② URN (Uniform Resource Name)
HTTP 요청 프로토콜
91-미니프로젝트 / 34 페이지
Request
요청 라인 (request line)
헤더 (공통/요청/엔티티) ← 0개 이상
빈 줄
엔티티 (entity; 서버에 보내는 데이터) ← 선택 사항메서드 URI HTTP/버전
헤더명: 값 ← 0개 이상
빈 줄GET /plus/100/200 HTTP/1.1
Host: localhost
빈 줄HTTP 메서드 : GET
요청 대상 : /plus/100/200
HTTP Version : 1.1
Worker 수정하기
웹 브라우저에서 보내는 첫 번째 줄은 request-line(start-line)
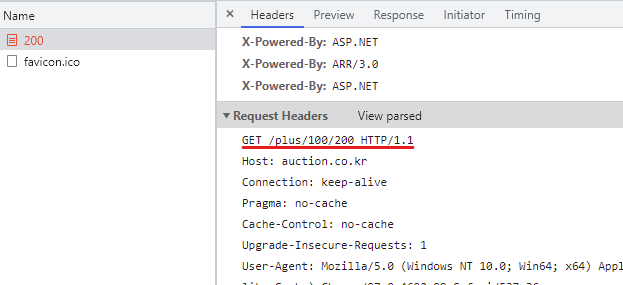
GET /plus/100/200 HTTP/1.1
나머지 데이터는 버린다
더 이상 읽을 게 없어서 빈 줄을 보내면 break
// 나머지 데이터는 버린다.
while (true) {
String str = in.nextLine();
if (str.length() == 0) {
break;
}
}HTTP 응답 프로토콜
91-미니프로젝트 / 34 페이지
Response
상태줄 (status line)
헤더 (공통/요청/엔티티) ← 0개 이상HTTP/버전 상태_코드 간단한_설명
헤더명: 값
⋮
빈줄
응답 결과(entity)HTTP/1.1 200 OK
Content-Type: text/plain;charset=UTF-8
Content-Length: 3 ← 응답 결과의 길이
빈 줄
abc String response = "Hello!";
// 2) HTTP 응답 데이터 보내기
out.println("HTTP/1.1 200 OK");
out.println("Content-Type: text/plain; charset=UTF-8");
out.printf("Content-Length: %d\n", response.length());
out.println();
out.println(response);
out.flush();http specification 검색
https://datatracker.ietf.org/doc/html/rfc2616
설명이 다 나와 있음
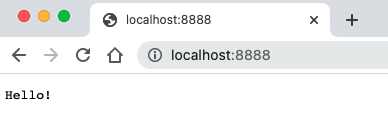
웹 브라우저와 서버가 대화가 통하기 시작
stateless 방식
com.eomcs.net 배울 때 할 거임
지금은 감 잡기
request-line을 분석해서 뭐가 플러스 마이너스인지 알아야 됨
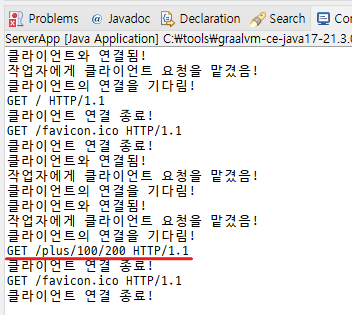
공백으로 잘라서 0번째거 버리고 2번째거 버리고 1번째거만 가져온다
String requestUri = requestLine.split(" ")[1];
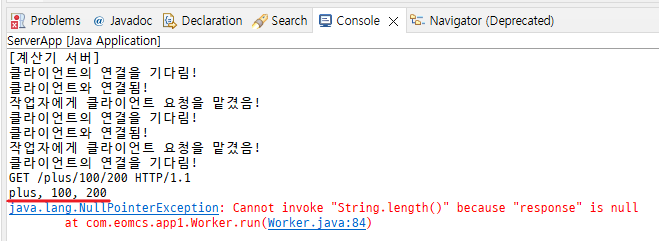
연산자랑 피연산자 잘 가져옴
Content-Length 부분 삭제하기
이 방법의 가장 큰 단점?
계산기 기능에 집중해야 되는데
어떻게 읽어야 하고 그 읽은 데이터를 어떻게 분리해야 되며
어떤 규칙에 따라서 응답을 해야 되는지 네트워크 통신에 신경써야 됨
ServerApp
• HTTP 프로토콜로 통신을 처리
• Multi-threading
이런 것들을 계속 개발자가 코딩해야 됨
String op = values[1]; // "+"
if (op.equalsIgnoreCase("%2f")) {
op = "/";
}+도 %2b로 보내야 됨
String op = URLDecoder.decode(values[1], "UTF-8"); // "%2b" -> "+", "-", "*", "%2f" -> "/"charset 반드시 지정하라고 나옴
웹 브라우저가 보낼 땐 UTF-8로 보냄
11단계: 웹 기술 도입 - 스프링 부트 사용하기
91-미니프로젝트 / 35 페이지
다음주 내용
클라이언트를 웹 브라우저로 교체함
서버를 스프링 부트로 바꿀 거
HTTP 프로토콜에 따라서 요청
HTTP 프로토콜에 따라서 스프링부트가 응답
다음주에 CalculatorController 만들 거
스프링 부트가 CalculatorController를 call 할 거
이제 개발자는 아래 것들을 신경 쓸 필요 없음
통신 프로그래밍 X
HTTP 프로토콜 X
멀티스레딩 X
✅ 업무 관련 작업에 대한 코딩만 신경쓰면 된다.
