2021-12-01(수) 4주차 3일
CRLF
LF가 CRLF로 바뀔거라는 거
C:\Users\bitcamp\git\eomcs-java\eomcs-java-lang-boot\app>gradle cleanEclipse
gradle cleanEclipse
기존 이클립스 설정 파일 삭제
C:\Users\bitcamp\git\eomcs-java\eomcs-java-lang-boot\app>gradle eclipse
gradle eclipse
이클립스 설정 파일 생성
절차를 기억하기!!!
빌드 도구를 위한 설정 파일
‐ build.gradle (Gradle)
‐ pom.xml (Maven)
‐ build.xml (Ant)
영어로는 빌드 스크립트 파일로 검색하면 됨
build script file
settings.gradle 파일
스프링 부트를 안 띄우고 바로 실행하는 예제 모음
스프링 부트를 띄워서 실행하는 예제 모음
eomcs로 시작하는 건 강사님거
java로 시작하는 건 내거
물음표
서버에 안 올렸다는 거
가져와서 보는 용도
선생님이 수정한 파일은 여기에 올라옴
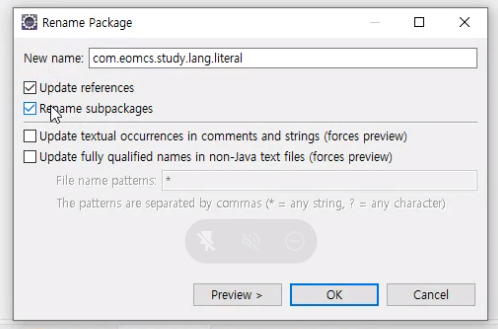
@GetMapping("/test2")
public String test2() {
double value = 987654321.1234567; // 8바이트 메모리 사용
return "부동소수점: " + value;
}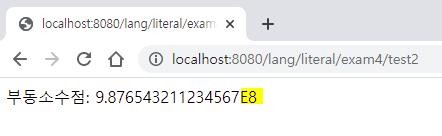
맨 끝에 E8은 10의 8제곱을 곱하라는 뜻
9.876543211234567 에서 10의 8제곱을 곱하면 소수점이 오른쪽으로 8칸 이동하여
→ 987654321.1234567 (소스파일에 있는 값이랑 똑같음)
4 바이트 부동 소수점 리터럴
8 바이트 부동 소수점 리터럴
16자리까지 유효하다. 값을 넣고 다시 꺼내더라도 거의 같은 값을 꺼내거나 근사한 값을 꺼낸다는 거
@GetMapping("/test3")
public String test3() {
float value = 987.654321f; // 4바이트 메모리 크기(유효자릿수 7자리)를 넘어서는 값은 잘린다. 유효자릿수를 넘어가는 값은 잘린다.
return "부동소수점: " + value;
}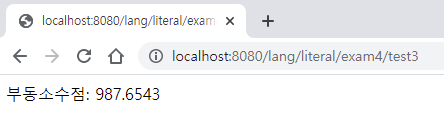
에러는 안 나고 값이 잘릴 뿐
@GetMapping("/test4")
public String test4() {
double value = 987654321.12345678987654; // 8바이트 메모리 크기(유효자릿수 15자리)를 넘어서는 값은 잘린다.
return "부동소수점: " + value;
}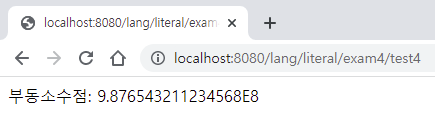
double value = 987654321.12345678987654;
9.876543211234568E8
987654321.123456 (15자리) 여기까지 유효함
15자리까지는 유효한데 15자리가 넘어가니까 반올림 처리함
원래 값은 7인데 반올림 해서 8로 나옴
16자리가 유효할지 15자리가 유효할지는 확실히 모른다.
문자 리터럴
'A'
'가'
최종적으로 하나의 문자열로 합쳐짐
// 리터럴 : 문자 리터럴
package com.eomcs.study.lang.literal;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/lang/literal/exam5")
public class Exam5 {
@GetMapping("/test1")
public String test1() {
return "문자1: " + 'A' + '가';
}
@GetMapping("/test2")
public String test2() {
return "문자2: " + '\u0041' + '\uac00'; // 문자에 대한 유니코드 값을 지정해도 된다.
}
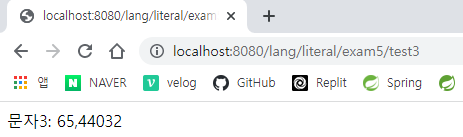
} @GetMapping("/test3")
public String test3() {
return "문자3: " + 0x41 + "," + 0xac00; // 문자 코드를 정수 값으로 지정한다. 대신 문자 코드임을 표시해야 한다.
}숫자로 나옴
char 입력
숫자가 아니라 문자다!! 라고 알려주는 거
@GetMapping("/test3")
public String test3() {
return "문자3: " + (char)0x41 + "," + (char)0xac00; // 문자 코드를 정수 값으로 지정한다. 대신 문자를 가리키는 코드임을 표시해야 한다.
}문자의 코드 값은 그냥 정수 값이다.
문자 코드 값은 반드시 16진수로 써야 되는 게 아님
근데 10진수로 표현하면 이게 몇 byte인지 알 수 없음
16진수는 알 수 있음. 숫자 한 개가 4 bit니까.
숫자 2개면 8 bit(=1 byte)
0x41 ← 2 byte
0xac00 ← 2 byte
@GetMapping("/test4")
public String test4() {
return "문자4: " + (char)65 + "," + (char)44032; // 문자 코드를 정수 값으로 지정한다. 대신 문자를 가리키는 코드임을 표시해야 한다.
}유니코드를 표현할 때는 반드시 4개의 숫자를 다 입력해야 된다.
양쪽에 싱글 쿼테이션으로 유니코드를 표현할 때는 반드시 4개의 숫자를 정확하게
'\u0041' ← 0041 4자리 다 입력해야 됨
0041
문자에 대해 지정된 번호 = 문자 코드
문자 코드 : 문자에 대해 지정된 번호
문자 리터럴
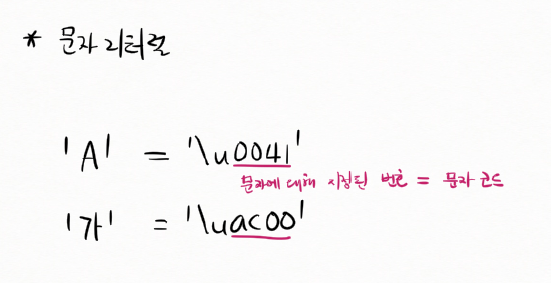
값을 메모리에 저장하기 위해 2진수화 시키는 규칙
① 정수
• Sign-Magnitude
• 1's complement
• 2's complement
• Excess-K
② 부동소수점
IEEE-754 규칙에 따라 바꿈
③ 문자
‐ Unicode(UTF-16BE = UCS2) 자바 기본 규칙 (국제표준)
‐ UTF-8 유니코드 변형 규칙 (국제표준)
‐ MS949(CP949) MS Windows에서 사용하는 규칙 (비표준)
‐ EUC-KR(KSC5601) 예전의 국가 표준 한글 규칙 (국제표준)
‐ 조합형 HWP 규칙 (비표준)
‐ ISO-8859-1 (영어권 표준 규칙)
‐ ASCII (미국 규칙)
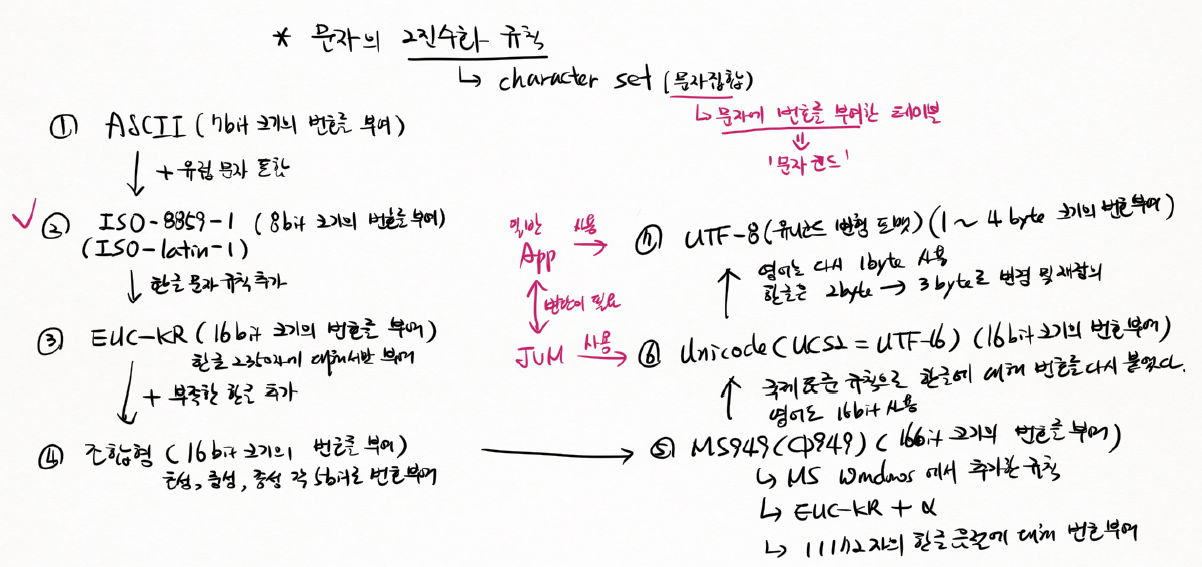
문자를 표현하는 2진수화 시키는 다양한 규칙을 알아야 됨
문자의 2진수화 규칙 (character set: 문자 집합)
문자에 부여된 번호 = 문자 코드
문자에 번호를 부여한 테이블
① ASCII (7bit 크기의 번호를 부여)
American Standard Code for Information Interchange
② ISO-8859-1 (8 bit 크기의 번호를 부여)
(ISO-latin-1)
ASCII + 유럽 문자 포함
8비트 크기의 번호를 부여함
③ EUC-KR (16 bit 크기의 번호를 부여)
ISO-8859-1 + 한글 문자 규칙 추가
16 비트 크기의 번호를 부여
한글 2350자에 대해서만 번호 부여
④ 조합형 (16 bit 크기의 번호를 부여)
EUC-KR + 부족한 한글 추가
초성, 중성(ㅏ, ㅑ, ㅓ, ㅕ), 종성(받침) 각 5 bit로 번호 부여
⑤ MS949(CP949) (16 bit 크기의 번호를 부여)
MS Windows에서 추가한 규칙
EUC-KR + α
11172자의 한글 음절에 대해 번호 부여
MS949는 리눅스나 유닉스에서 못 씀. 국제 표준이 아님
그래서 등장한 게 Unicode
⑥ Unicode(UCS2 = UTF-16) (16 bit 크기의 번호 부여)
국제 표준 규칙으로 한글에 대해 번호를 다시 붙였다.
영어도 16 bit 사용 (이게 ISO-8859랑 다른 점)
JVM은 유니코드 사용
UTF-8 등장
⑦ UTF-8 (유니코드 변형 포맷) (1~4 byte 크기의 번호 부여)
영어는 다시 1 byte 사용
한글은 2 byte → 3 byte로 변경 및 재정의
일반 에디터는 UTF-8 사용
현재 현업에서는 UTF-8 씀
영어는 ISO-8859-1 씀
JVM은 Unicode 사용
일반 프로그램은 UTF-8 사용
일반 프로그램에서 입력된 걸 JVM에서 처리하려면 Unicode로 바꿔야 됨
JVM이 처리한 문자열을 일반 프로그램이 읽게 하려면 UTF-8로 바꿔야 됨
변환이 필요
영어는 UTF-8의 영어나 ISO-8859의 영어나 같다.
git pull 했을 때
merge 에러 뜨면 로컬 건드린 거
다시 clone 받기
컴퓨터는 기본적으로 숫자를 4 byte 쓴다.
4 byte 정수 또는 8 byte 정수를 쓴다.
4 바이트 메모리에 담을 때도 있고
8 바이트 메모리에 담을 때도 있음
4 바이트 쓸 때는 맨 앞에 비트가 0이면 양수고 1이면 음수
일반 양수인지 2의 보수인지 맨 앞의 비트로 판단
일반 양수는 무조건 0
1로 시작하면 무조건 음수
맨 앞이 부호 비트
0이 양수
1이 음수
32 bit 다 적을 수 없어서 4 bit 라고 가정하고 한 거임
ASCII character set (7 bit)
American Standard Code for Information Interchange
문자를 메모리에 저장할 수 있도록 2진수로 바꾸는 규칙
처음에는 7비트였음
문자에 대해 번호를 부여한 테이블
65 대문자 'A'
2진수로 만들면 되는 거
문자를 메모리에 저장할 수 있도록 2진수로 바꾸는 규칙
문자 → 2진수 ( 7 bit )
'0' → 011 0000 (0x30) 48
'1' → 011 0001 (0x31) 49
'2' → 011 0010 (0x32) 50
⋮
'A' → 100 0001 (0x41) 65
'B' → 100 0010 (0x42) 66
⋮
'a' → 110 0001 (0x61) 97
'b' → 110 0010 (0x62) 98
'c' → 110 0011 (0x63) 99
⋮
⟹ 총 95자
2진수를 보통 16진수로 표현
뒤에서부터 4비트씩 자른다
3비트 4비트로 자른다
10진수로 오해할까봐 앞에다가 16진수인걸 표현하기 위해서 0x를 붙인다.
결국 문자에 숫자를 지정한 거임
문자 '0'은 10진수로 48이라는 문자임. 48번째에 해당하는 문자임.
이렇게 약속(규칙)을 정한 거임.
대문자 'A' -- 저장 --> 100 0001 -- 출력 --> 65번째 문자 (0x41번째 문자)상호 간에 규칙이 같아야 되는 거임.
저장할 때 저장하는 사람이 사용하던 규칙과 저장된 값을 읽어서 출력하는 그 사람이 사용하는 규칙이 같아야 되는 거.
한 사람은 대문자 'A'에 대해 65라고 저장했는데 읽어들이는 쪽에서는 65가 대문자 'Z'로 정해져 있어서 Z가 출력되면 말이 안 되는 거. 그래서 규칙이 필요한 거. 그래서 그 규칙을 누가 만들었다? 미국 표준 위원회에서 만듦.
규칙을 미국 표준 위원회에서 만듦
우리는 이제 대문자 'A'를 65라는 숫자로 저장하겠습니다!
따라서 문자를 읽어서 출력하는 프로그램을 짜시는 분들은
그 값이 65면 '대문자 A구나'라고 판단을 하시고 화면에 출력할 때 A를 출력하세요
ASCII 따르지 않으면 납품하지마
규칙에 따라 저장하고 규칙에 따르는 거
상호 간에 규칙을 지켜야 됨
근데 안타깝게도
7 bit로 지정할 수 있는 숫자는 0 ~ 127
0 → 문자
≀
127 → 문자
최대 128자에 대해서 지정
이 중에서 영어 대·소문자(52개), 아라비아 숫자(10개), 특수문자(32개), 공백(1개) => 95개의 출력 가능한 문자 + 33개의 제어문자
https://ko.wikipedia.org/wiki/ASCII
아스키는 7비트 인코딩으로, 33개의 출력 불가능한 제어 문자들과 공백을 비롯한 95개의 출력 가능한 문자들로 총 128개로 이루어진다.
출력 가능한 문자들은 52개의 영문 알파벳 대소문자와, 10개의 숫자, 32개의 특수 문자, 그리고 하나의 공백 문자로 이루어진다.
ASCII에는 유럽 문자가 없음
프랑스어, 이탈리아어, 독일어...
영어 밖에 안 됨
그래서 등장한 게 ISO-8859
ISO-8859 검색
https://ko.wikipedia.org/wiki/ISO/IEC_8859
컴퓨터에서 8비트로 문자를 나타내기 위한 ISO와 IEC의 공동 표준이다.
우리 나라는 기본적으로 ISO/IEC 8859-1를 사용하고 있다.

8 bit면 256자인데 모든 나라 문자가 들어가는 게 아니라
이 비트가 1이면 얘는 네덜란드어
이 비트가 2면 노르웨이어
우리가 쓰는 건 영어이기 때문에 ISO-8859-1을 기본으로 쓴다.
ISO-8859-1 (영어, 프랑스어, 이탈리아어 등) (8 bit)
ASCII + 프랑스어 등
128자 + 128자 = 256자
ASCII를 포함한다는 거
ASCII 포함이어서 앞에는 ASCII랑 똑같음
앞에 1비트가 추가된다.
1비트 늘어나서 앞에 비트 추가
문자 → 2진수 ( 8 bit )
'0' → 0011 0000 (0x30) 48
'1' → 0011 0001 (0x31) 49
'2' → 0011 0010 (0x32) 50
⋮
'A' → 0100 0001 (0x41) 65
'B' → 0100 0010 (0x42) 66
⋮
'a' → 0110 0001 (0x61) 97
'b' → 0110 0010 (0x62) 98
'c' → 0110 0011 (0x63) 99
현재 영어는 ISO-8859-1을 사용
기본이 1 byte이고 1 byte는 8 bit로 이루어져 있음
메모리가 7 bit로 이루어져 있지 않음. 8 bit로 이루어져 있음.
그래서 기본이 ISO-8859-1
앞으로 영어는 무조건 ISO-8859-1
컴퓨터에 character set 1개가 있는 게 아니라
영어를 저장할 때는 ISO-8859-1로 저장하고
한글을 저장할 때는 EUC-KR 규칙에 따라 저장한다.
EUC-KR이 내부적으로 ISO-8859-1을 사용하는 거
그런데 ISO-8859-1에는 한글이 없다.
한글 음절에 대한 규칙이 없다.
한글 음절 자체가 이미 8 bit로 표현 불가
한글 음절이 11172자인데 안 됨
그래서 우리나라에서는 컴퓨터 초창기에 EUC-KR 등장
일본은 EUC-JP
https://ko.wikipedia.org/wiki/EUC-KR
EUC-KR은 KS X 1001와 KS X 1003을 사용하는 8비트 문자 인코딩, EUC의 일종이며 대표적인 한글 완성형 인코딩이기 때문에 보통 완성형이라고 불린다.
128보다 작은 바이트에 KS X 1003을 배당한다.
128보다 크거나 같은 바이트에 KS X 1001을 배당한다.
EUC-KR (2 byte) - 한글 음절 2350자 (국제표준) (영어 1 byte, 한글 2 byte)
영어 : 1 byte
한글 : 2 byte
국제표준이라는 것은 Unix든 Mac이든 Windows든 똑같이 지원한다는 거
80년대에 만듦
핵심은 2 byte를 쓴다는 거
문자 → 2진수 ( 2 byte )
0 → 0011 0000 (0x30) 48
1 → 0011 0001 (0x31) 49
2 → 0011 0010 (0x32) 50
⋮
A → 0100 0001 (0x41) 65
B → 0100 0010 (0x42) 66
⋮
a → 0110 0001 (0x61) 97
b → 0110 0010 (0x62) 98
c → 0110 0011 (0x63) 99
⟹ 여기까지는 1 byte 사용
ISO-8859-1 (1 byte) 사용
2350자 (2 byte 사용)
가 → 0xB0A1
각 → 0xB0A2
간 → 0xB0A3
⋮
⟹ 2 byte 사용
11172자
EUC-KR을 만들 당시만 해도 우리가 2350자 이상을 쓸 줄을 몰랐음
그래서 2350자만 정리함
시간이 지나니까 2350자로는 다 못 쓰는 상황이 발생
그래서 등장한 게 조합형
한글을 저장할 땐 2 byte 사용
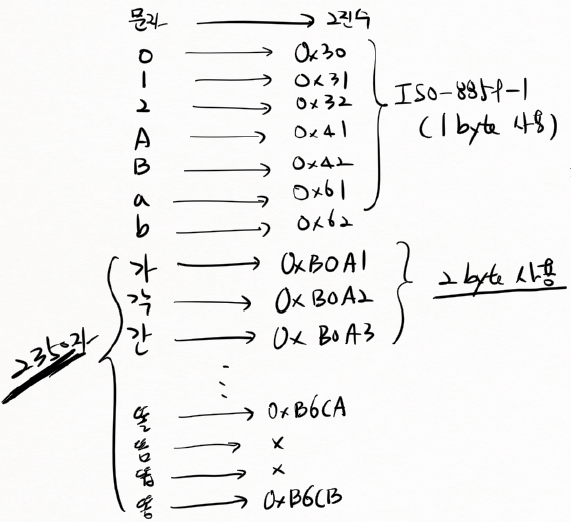
가 → 0xB0A1
B0A1
B = 11 (1011)
0 = 0 (0000)
A = 10 (1010)
1 = 1 (0001)
⟹ 1011 0000 1010 0001 // 메모리상에 이렇게 2 byte(16 bit)로 저장됨0000 0000 0000 0000
⋮
1111 1111 1111 1111
⟹ 65536자에 대해 정의할 수 있다. (ASCII 256자를 포함하고 있다.)
65536자를 저장할 수 있는데 2350자 밖에 정의를 안 했는지?
한글 11172자 + α
옛한글, 한국만의 한자 등...
조합형 등장하기 전까지 2350자 밖에 못 썼었음
65536자에는 한글만 있는 게 아니라 중국어도 있고 일본어도 표현해야 됨
중국 10만자
2 byte로도 정의가 안 됨
간자체
이 당시에는
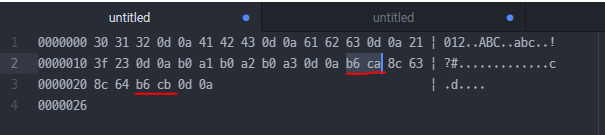
2350자가 EUC-KR로 등록이 된 거
똘 → 0xB6CA
똠 → X (숫자 정의 안 함)
똡 → X (숫자 정의 안 함)
똥 → 0xB6CB
'똠'자에 대해 숫자가 지정되지 않아서 입출력이 안 됐다.
초창기 EUC-KR을 사용하는 에디터는 안타깝게도 똠방각하를 입력할 때 ㅁ 받침이 뒤에 또ㅁ방각하 이렇게 쓸 수 밖에 없었음 '똠'이라는 문자에 대해서 숫자가 지정되지 않음. 정의되지 않은 문자이기 때문에 컴퓨터상에서 입력이 안 됨.
또ㅁ방각하
'똠'자에 대해 숫자가 지정되지 않아서 입출력이 안 됐다.
그 다음에 조합형이 등장
초창기 편집기
조합형 (2 byte)
* 조합형 (2 byte) - 초성(5비트)+중성(5비트)+종성(5비트) = 16 bit
MS-DOS → Windows 3.0 -- + 동영상 플레이 --> Windows 3.1 ---> Windows 95 → Windows 7 → Windows 10/11
초성 중성 종성
5 bit
00000 = 0
⋮
11111 = 2^5 - 1
11 ← 3
+ 1
----
100 ← 411 = 100 - 1
11 = +
100 - 1 =
11 ← 비트가 2개니까 = 최댓값
5비트니까 한 값이 최댓값
32 - 1 = 31 ( 0 ~ 31 )
초성 31개
31개의 초성에 대해서 숫자를 정의할 수 있는데 그 초성이 31개일 이유는 없음

중성
ㅏ
ㅐ
ㅑ
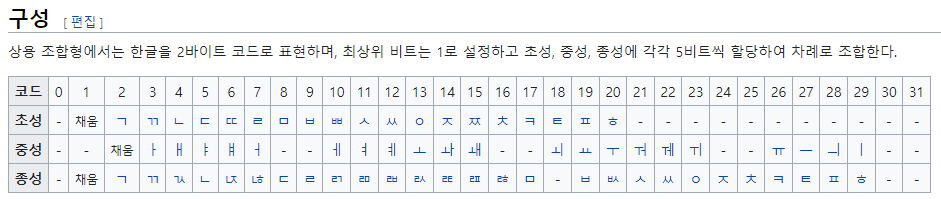
넬
초성 ㄴ = 4 (10진수) = 00100 (2진수, 5비트)
중성 ㅔ = 10 (10진수) = 01010 (2진수, 5비트)
종성 ㄹ = 9 (10진수) = 01001 (2진수, 5비트)
한글인 경우 첫번째 비트가 1로 시작하므로 앞에 1을 추가로 붙여준다.
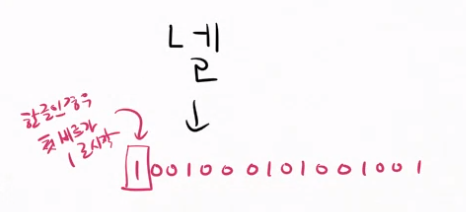
앞에 1을 추가하고 4비트씩 자른다.
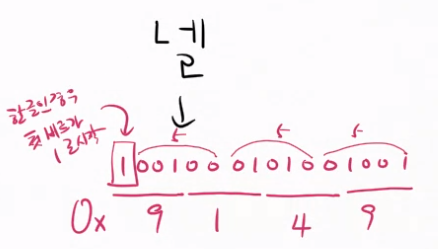
16진수로는 0x9149가 '넬'이다.
초성, 중성, 종성에 부여된 숫자를 합쳐서 문자 코드를 정한다.
⟹ 가장 한글답다.
⟹ 16 bit 중에서 1로 시작하는 절반의 값을 한글이 모두 사용한다.
⟹ 다른 나라(중국, 일본 등) 문자는?
절반이나 우리가 독차지..?
중국은 2 바이트를 다 써도 다 못 쓰는 판인데
우리가 다 쓰겠다고?
⟹ 그래서 국제 표준이 안 되는 거임
Windows 3.1까지 사용
Windows 3.1까지 EUC-KR 사용 → "똠"자 입출력 불가!
그래서 아래한글에서 조합형을 따로 만들어서 썼음
아래한글에서는 '똠' 입력 가능
단, 아래한글로 입출력을 해야 함.
MS Word 이런 것들은 안 됨.
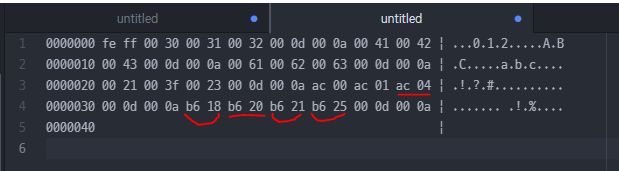
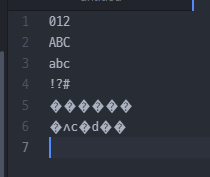
012
ABC
abc
!?#
가각간
똘똠똡똥
UTF-16 LE(리틀 엔디언), UTF-16 BE(빅 엔디언)
작은 수가 끝에 놓이냐 큰 수가 끝에 놓이냐 차이
30 31 32
문자가 정렬되는 순서대로
MS949(CP949)(2 byte) = EUC-KR + α
EUC-KR + α
2350자 + α = 11172자
Windows 95부터
기존에 정한 걸 뒤로 밀 수도 없음
기존에 작성한 문서들 어떡함
기존 EUC-KR 문서들이 깨져버리니까 번호가 밀려버리니까
안 쓰는 번호를 부여하겠습니다
똘 → 0xB6CA
똠 → 0x8C63
똡 → 0x8C64
똥 → 0xB6CB
MS949에서 새로 추가한 문자에 대해 사용되고 있지 않은 번호를 부여했다.
그래서 번호가 순서대로 부여되지 않았다.
대신 기존 EUC-KR 규칙과 호환된다.
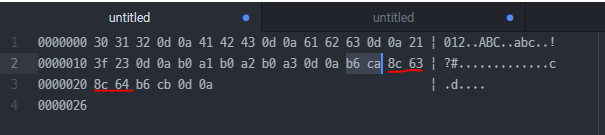
일련번호가 부여되지 않았다.
MS949로 저장한다고 하더라도 EUC-KR 문자는 그대로 쓴다.
즉 MS949 규칙에 따라 문자를 저장하더라도 EUC-KR에 정의된 문자로 기존과 같은 번호를 사용한다.
단점 : 문자 정렬할 때 숫자 일련번호로 정렬하면 섞이게 됨
조합형은 한국만의 표준
Unicode (UTF-16) (영어, 한글 2 byte)
국제 표준
UTF-16 : 영어든 한글이든 2 byte
Java에서 문자를 저장할 때 사용하는 규칙
UTF-8 아님
Unicode (UTF-16) = UCS2
★ 2 byte 사용 ★
영어도 2 byte
2 byte = 16 bit
기존의 ISO-8859-1 문자도 2 byte 숫자를 사용한다.
11172자의 한글 음절에 대해 새로 번호를 부여했다.
EUC-KR과 호환되지 않는다. ★
Unicode (UTF-8) (영어 1 byte, 한글 3 byte)
UTF-8
8 bit 숫자로 정의 가능한 것은 그대로 8 bit 사용
ISO-8859-1 문자는 예전처럼 1 byte 사용
영어권에서 Unicode를 처리하기 위해 따로 작업할 필요가 없다.
ISO-8859-1과 호환
총 4 byte 사용


한글은 UTF-8 변환규칙에 따라 유니코드를 변환한다.
⟹ 2 byte → 3 byte (메모리 증가!)
⟹ 요즘은 테라바이트여서 이건 아무것도 아님
https://ko.wikipedia.org/wiki/UTF-8
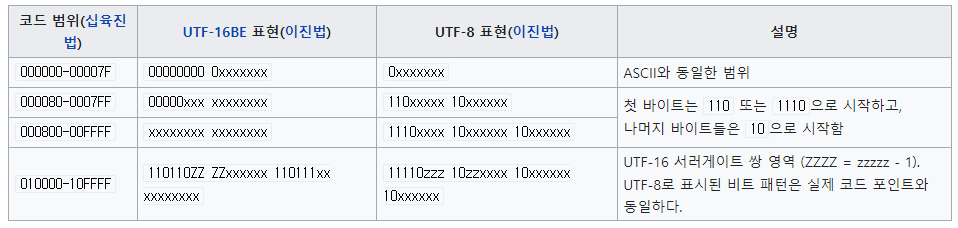
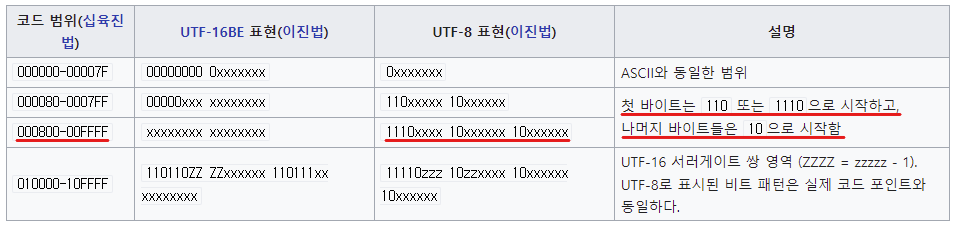
↑ 코드 범위 참고
AC00은 800 ~ FFFF 사이의 수
'가'
유니코드 : 0xAC00 (16진수)
1010(A) 1100(C) 0000(0) 0000(0) (2진수)
1010 1100 0000 0000 (4개 4개 4개 4개) ← 2 byte (UTF-16)
1010 110000 000000 (4개 6개 6개)
1110xxxx 10xxxxxx 10xxxxxx ← 여기에 집어 넣는다.
11101010 10110000 10000000 ← 3 byte (UTF-8)
4비트씩 잘라서 16진수로 만든다.
1110 1010 1011 0000 1000 0000
14 10 11 0 8 0
E A B 0 8 0
3 byte로 만든다.
EA B0 80
기존 유니코드(UTF-16)를 UTF-8로 바꿨다. 3 byte로 바꿨다.
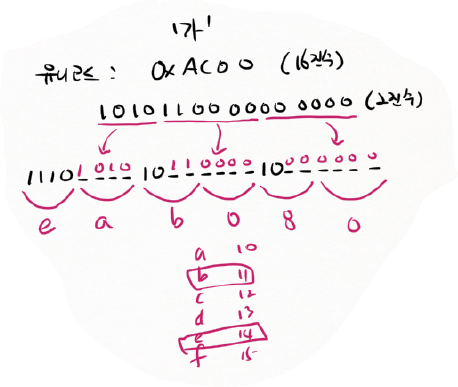
문자는 양수만 있음
약 42억개의 문자에 숫자를 부여할 수 있음
UTF-8은 영어는 1 byte, 한글은 3 byte
영어는 1 byte 줄어들었고 한글은 1 byte 늘어났다.
이렇게 해야지 중국의 10만자도 저장할 수 있음
UTF-16
UTF-8
선택권이 두 개가 있는데 Unicode(UTF-16)으로 저장하거나 UTF-8로 저장
영어권 나라는 UTF-16을 사용할 이유가 없음
굳이 영어를 저장하는 데 2 byte를 사용할 이유가 없음
그래서 UTF-8을 씀. UTF-8은 1 byte니까.
여기서 바로 문제가 발생하는 거!!
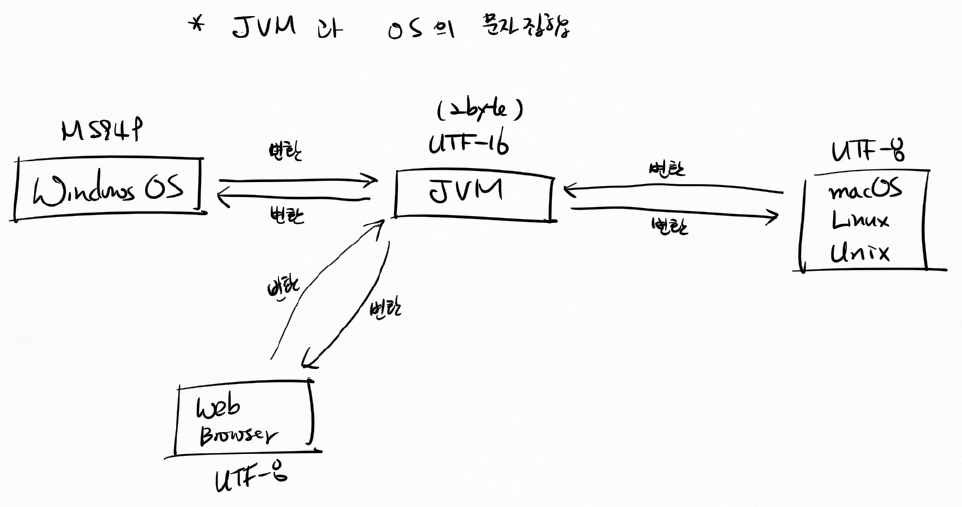
JVM과 OS의 문자 집합
JVM은 무조건 UTF-16 (2 byte)
UTF-16 : 영어든 한글이든 2 byte
윈도우 운영체제는 MS949
⟹ 변환이 필요
macOS, Linux, Unix는 UTF-8 사용
JVM에서 읽어들일 때 변환이 필요
JVM에서 출력할 때도 변환이 필요
한글이 깨졌으면 변환을 안 한 거
Web Browser : UTF-8 사용
웹 브라우저에서 JVM 쪽으로 값을 보내는데 UTF-8로 보냄
JVM은 UTF-8을 인식 못 함
UTF-16으로 바꿔줘야 됨 (변환이 필요)
서버에서 Web Browser에 데이터를 줄 때도 UTF-16을 UTF-8로 변환해서 줘야 됨
이 과정에서 변환을 안 하면 한글 깨짐
운영체제나 웹 브라우저나 자바 프로그램이나 다 같은 문자집합을 사용하면 문제가 없는데 자바는 유니코드 중에서 UTF-16을 사용. 브라우저는 대부분 UTF-8 사용.
Atom, vscode, Eclipse UTF-8로 설정했었음
저장되는 모든 자바 소스는 UTF-8
그래서 항상 변환을 해야 됨
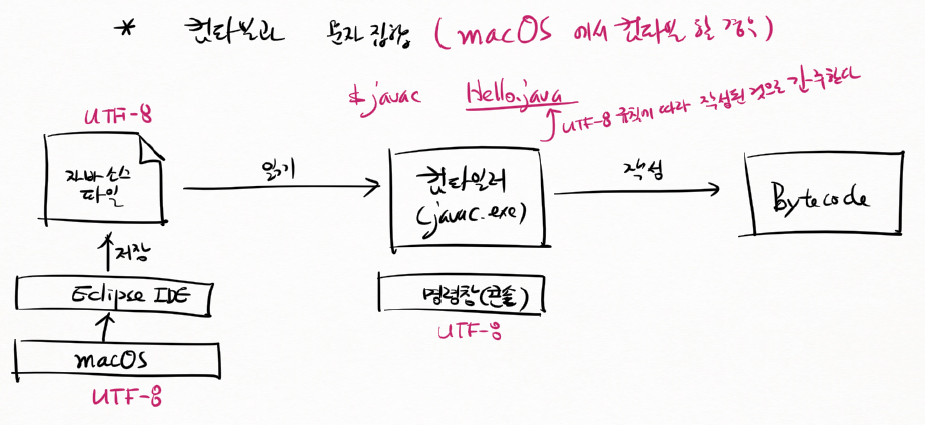
컴파일과 문자집합 (macOS에서 컴파일 할 경우)
macOS(UTF-8)에서 이클립스(UTF-8)를 통해서 자바 소스 파일 작성
컴파일러(javac.exe)가 자바 소스 파일을 읽어서 바이트코드를 만든다.
컴파일러를 명령창(콘솔)에서 실행
macOS : UTF-8
eclipse : UTF-8
$ javac Hello.java
명령창(콘솔) : UTF-8
자바 컴파일러는 UTF-8 규칙에 따라 작성된 것으로 간주한다.
자바 소스 파일이 UTF-8이므로 아무런 문제가 없다.
맥은 에러 안 남
아 그래서 저번에 400번인가 명령창에서 컴파일했을 때 에러 안 남
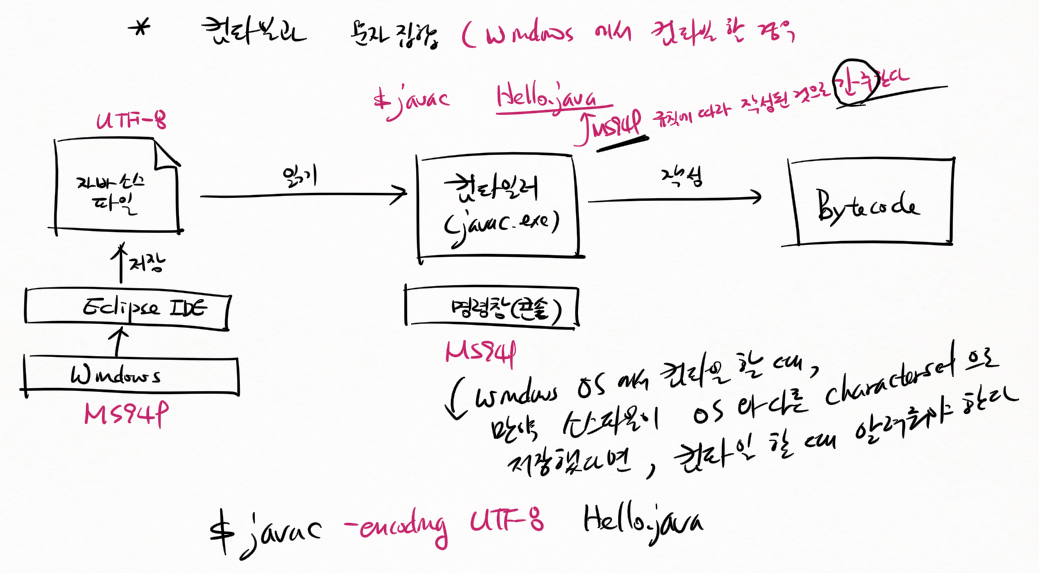
문제는 Windows
컴파일과 문자집합 (Windows에서 컴파일 할 경우)
Windows : MS949
eclipse : UTF-8
자바 소스 파일 : UTF-8
명령창(콘솔) : MS949
컴파일러는 따로 옵션을 지정하지 않으면 운영체제와 같은 MS949 규칙에 따라 작성된 것으로 간주된다.
컴파일러는 자바 소스 파일이 MS949 규칙에 따라 작성된 것으로 아니까 컴파일이 제대로 안 된다. 그래서 Windows에서 에러 뜨는 거
mac에서 컴파일 할 때는 상관 없지만 Windows에서 컴파일 할 때는 알려줘야 됨
Windows OS에서 컴파일할 때, 소스파일을 OS와 다른 character set으로 저장했다면 컴파일 할 때 알려줘야 한다.
$ javac -encoding UTF-8 Hello.java
-encoding UTF-8
팀에 mac을 쓰는 사람도 있고 Windows를 쓰는 사람도 있을 거임
근데 MS949 Windows 운영체제에서만 유효한 문자 집합이다.
UTF-8은 국제 표준이다.
그럼 당연히 소스 파일을 저장할 때 국제 표준인 UTF-8로 저장해야 됨
물론 소스 파일 안에 한글을 안 썼으면 아무런 문제가 안 됨
eclipse는 컴파일할 때 자기가 실행할 때 인코딩 옵션 자동으로 붙임
제어 코드
제어를 나타내는 코드
제어 명령
줄바꿈 명령
Windows 운영체제에서는 2개 byte 사용
0D : CR(Carriage Return)
0A : LF(Line Feed)
Unix/Linux 계열 운영체제에서는
0A : LF(Line Feed)
줄바꿈 → 0D0A(Windows) → 0A(Unix/Linux)
Carriage Return : 캐리지를 맨 앞으로 되돌리는 명령
Line Feed : 다음 라인으로 가는 명령
⟹ 타자기의 행동을 모방
윈도우에서 엔터를 칠 때마다 맨 끝에 2 byte 붙음
유닉스나 리눅스는 엔터를 치면 맨 끝에 1 byte 붙음
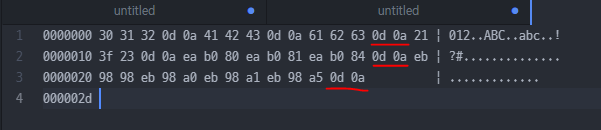
↑ Enter를 의미하는 제어 문자가 들어간 걸 볼 수 있다.
0D 0A 라는 숫자를 만나면 다음 줄로 이동한 다음에 그 다음에 나오는 번호에 해당하는 문자를 뿌린다.
Atom 에디터는 첫 비트가 0으로 시작하는 게 아니라 1로 시작하면 한글로 받아들이고
읽어들일 때도 영어가 아니면 3 byte UTF-8 문자라고 간주한다.
영어가 아닌 거는 UTF-8이라고 생각
UTF-8이 아닌 거를 UTF-8로 출력하려고 하니까 이상하게 나오는 거
로렘 입숨
탭
백스페이스
윈도우에서 엔터를 칠 때마다 맨 끝에 0D 0A (2 byte) 붙음
유닉스나 리눅스는 엔터를 치면 맨 끝에 0A (1 byte) 붙음
값 → 2진수화 → 메모리 저장
4 byte
정수, 부동소수점, 2개의 문자
어떤 값을 저장하든지 상관없이 같은 메모리 사용
그렇다면 저 메모리에 저장된 값은 정수로 간주하고 읽어야 하는가, 부동소수점으로 간주하고 읽어야 하는가, 문자코드로 간주하고 읽어야 하는가?
숫자는 2의 보수에 따라 저장
부동소수점은 IEEE-754 규칙에 따라 저장
문자를 저장할 때는 자바의 경우는 유니코드 UTF-16 규칙에 따라 저장
그러나 같은 메모리를 씀
이 메모리에 들어 있는 값을 읽을 때는?
메모리에 저장된 값을 읽을 때 정수로 간주하고 읽어야 하는가, 부동소수점으로 간주하고 읽어야 하는가, 문자코드로 간주하고 읽어야 하는가?
이 메모리에 대해서 정보가 주어지지 않으면 모름!!!
메모리에 저장된 값에 대해 정보가 주어지지 않으면 모른다!!
확장자 없앴는데도 웹 브라우저가 알아서 보여줌
이 파일 데이터 안에 어떤 데이터인지 정보가 다 들어 있음

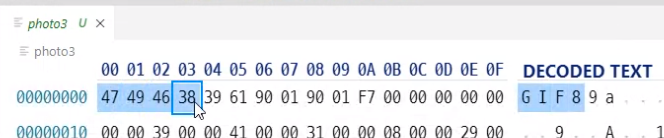

파일에 저장될 때 이게 무슨 데이터인지 정보가 들어 있거나
또는 정보가 안 들어있으면 파일 확장자명으로 알려주거나
또는 그렇게도 안 알려주면 더 이상 읽어들이는 쪽에서는 텍스트인지 이미지 파일인지 pdf 파일인지 알 길이 없음
JVM 메모리에 때로는 정수를 저장할거고, 때로는 부동소수점도 저장할 거고, 때로는 문자를 저장할 거임
이때 메모리에 저장된 값이 정수인지 부동소수점인지 문자에 부여된 번호인지 true, false를 나타내는 숫자인지 그거는 따로 정보가 기록되어 있다
그 기록을 보고 읽어들인다
만약에 그 정보가 없으면 그 메모리에 들어 있는 값이 어떤 값인지 알 길이 없다
정보를 따로 저장한다고!
그 메모리가 어떤 데이터를 저장하는 메모리인지 정보를 따로 저장함.
소스 코드는..?
이미 리터럴 자체로 알 수 있다!!
양쪽에 싱글 쿼테이션은 문자에 부여된 숫자를 가리키는 거고
뒤에 f로 끝나거나 중간에 점.이 있으면 부동소수점
근데 문제는 메모리!!
변수 - 값을 담는 메모리
값을 담는 메모리인데 여기에 어떤 값이 담기는지 표시를 해야 됨
int v;
4 byte 메모리에 정수를 담는다
long v;
8 byte 메모리에 정수를 담는다
float v;
4 byte 메모리에 부동소수점. IEEE 754 규칙에 따라서 지수부, 가수부를 나눠서 담겠다
double v;
8 byte, 부동소수점.
char v;
2 byte, UTF-16 코드값
boolean v;
4 byte, true(1)/false(0)를 가리키는 숫자를 저장
byte v;
1 byte
short v;
2 byte
데이터를 저장하기 위해서 메모리를 만들 때 그 메모리를 어떤 용도로 쓸 건지 설정해야 한다.
똑같이 메모리에 저장하는데
똑같은 2진수인데
정수를 2의 보수로 표현한 2진수인지
부동소수점을 지수부와 가수부와 나눠서 표현한 2진수인지
문자를 정수로 표현한 2진수인지
그걸 따로 설정하지 않으면 모름
정수 : 2의 보수
부동소수점 : IEEE 754
문자 : Unicode UTF-16
메모리에 저장할 때 무조건 2진수로 바꾼 다음에 저장
결국 메모리상에서는 각각의 비트에 전기를 채우고 안 채우고로 표현하는 거
자바스크립트 변수
var, let, const
그 안에 들어있는 게 숫자인지 문자인지 어떻게 알지?
자바스크립트는 어떤 값인지 정보도 함께 들어있음
이 변수에 들어있는 숫자는 정수값이다
이 변수에 들어 있는 숫자는 부동소수점을 표현한 숫자다.
이 변수에 들어 있는 숫자는 객체라고 불리는 다른 메모리의 주소를 가리키는 숫자다.
메모리에 들어 있는 그 숫자가 어떤 숫자인지 다 정보가 함께 기록이 된다.
다만 숫자를 저장하는 순간 그 정보가 계속 바뀜
변수에 문자열을 저장하면 그 순간
어 여기 들어간 숫자는 문자 숫자인데~~
그 변수에 정수 값을 집어 넣으면 그 순간
어 이 변수에 저장된 숫자는 정수인데~~
계속 바뀜
변수에 들어간 값의 종류가 고정된 게 아니라 끊임없이 움직인다.
⟹ Dynamic Type Binding 이라는 용어가 등장
https://docs.oracle.com/javase/specs/jvms/se17/html/jvms-2.html#jvms-2.3


▣ 어떤 값을 메모리에 저장하려면 2진수화 시켜야 한다는 의미를 설명할 수 있는가?
2진수로 바꿀 수 있으면 메모리에 저장할 수 있으니까
▣ 문자 집합의 종류와 탄생 배경을 설명할 수 있는가?
어떤 이유로 등장했는지
UTF-16이 있었는데 UTF-8이 나온 이유는 영어를 1 byte로 쓰기 위해서
UTF-16은 영어도 2 byte
영어를 예전처럼 1 byte로 쓰기 위해서
국제 표준은 1 byte
▣ 각 문자 집합에 대해서 설명할 수 있는가?
ASCII : 7 bit
▣ JVM과 OS 사이에서 문자를 다루는 상황을 설명할 수 있는가?
리눅스나 유닉스의 경우에는 UTF-8
윈도우는 MS949(CP949)
▣ 컴파일할 때 문자 집합을 지정하는 이유를 설명할 수 있는가?
JVM : UTF-16
Windows : MS949(CP949)
컴파일할 때 문자집합을 지정하는 이유
굳이 지정할 필요 없으면 지정 안 하면 되는 거고
윈도우는 지정해줘야 됨
소스코드는 UTF-8 콘솔창은 MS949
이 상태에서 그냥 컴파일하면 소스파일이 운영체제와 똑같은 문자집합으로 저장되어 있을 거라고 간주
▣ 줄바꿈 제어 코드(CR, LF)에 대해 설명할 수 있는가?
CR : Carriage Return
LF : Line Feed
영어로 못 바꾸는 건 물음표로 내보냄
