
노마드 코더 Python으로 웹 스크래퍼 만들기
https://nomadcoders.co/python-for-beginners
✍️ 해야할 것
-
사이트 접근
-
페이지 몇 개인지 알아내기
-
페이지 하나씩 들어가기
indeed와 stackoverflow에서 scraping 해 오기
마지막에 모든 결과를 엑셀 시트에 보여준다
파이썬에서는 라이브러리 또는 패키지를 import 할 수 있다
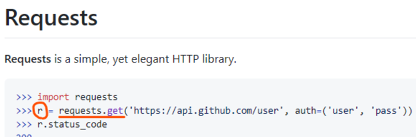
📕 requests 라이브러리
Python HTTP 라이브러리. 웹 페이지의 HTML을 가져오는 모듈
r = requests.get(url) 해당 url 사이트에 get 요청을 보내는 것
요청이 성공하면 200을 응답한다.
package로 가서 requests 찾아서 설치하기
설치가 완료되면
✍️ import requests
requests를 import 해준다
request를 만들고 그 결과를 변수에 넣는다.
indeed_result 라는 변수를 만들고

.get 괄호 안에 indeed 주소 복사해서 붙여넣기
import requests
indeed_result = requests.get("https://www.indeed.com/jobs?q=python&limit=50")실행해본다
오류가 안 났다
이제 출력을 해본다
import requests
indeed_result = requests.get("https://www.indeed.com/jobs?q=python&limit=50")
print(indeed_result) ⬅️ 추가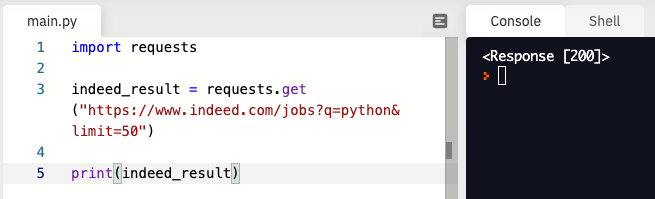
200이라고 응답이 왔는데 okay라는 뜻이다.
Indeed의 html을 살펴본다.
requests로 이것 저것 가지고 올 수 있는데
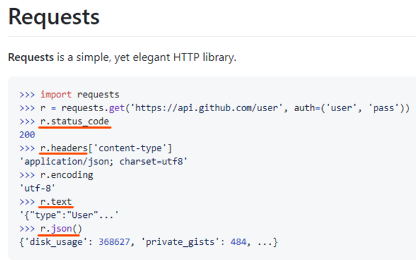
✍️ indeed_result.text
우리가 가져올 것은 text이다.
indeed_result.text 라고 입력한다.
출력해본다.
import requests
indeed_result = requests.get("https://www.indeed.com/jobs?q=python&limit=50")
print(indeed_result.text) ⬅️ indeed_result.text로 변경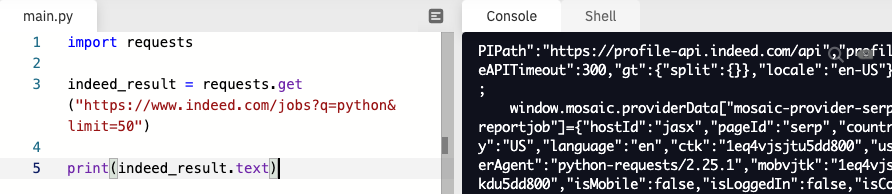
뭐가 엄청 많이 출력된다.
html 전부를 가지고 온 것이다.
✍️ import BeautifulSoup
이제 가지고 온 html에서 원하는 정보를 추출해야 한다.
페이지 숫자를 가져와야 한다.
수동으로 하려면 시간이 오래 걸리므로
구글에 beautifulsoup 검색
html에서 정보를 추출할 때 유용한 package이다.
repl.it packages에 가서 beautifulsoup4 설치
beautifulsoup4 Screen-scraping library 설치
📕 Beautiful Soup Documentation
https://www.crummy.com/software/BeautifulSoup/bs4/doc/
import requests
from bs4 import BeautifulSoup ⬅️ 추가
indeed_result = requests.get("https://www.indeed.com/jobs?q=python&limit=50")
print(indeed_result.text)실행해본다.
오류 안 남
✍️ BeautifulSoup(html_doc, 'html.parser')
이제 변수를 만들어준다.

BeautifulSoup(html_doc, 'html.parser')
import requests
from bs4 import BeautifulSoup
indeed_result = requests.get("https://www.indeed.com/jobs?q=python&limit=50")
indeed_soup = BeautifulSoup(indeed_result.text, "html.parser") ⬅️
print(indeed_result.text)실행해보기
오류 안 남
✍️ indeed 페이지 가져오기
아래와 같이 beautifulsoup으로 데이터 구조를 탐색할 수 있다.

📕 find와 find_all의 차이점
soup.find_all('a')
매개변수로 tag 입력
해당되는 모든 tag들 리스트로 반환
soup.find('a')
매개변수로 tag 입력
해당되는 첫 번째 tag만 가져온다.
그 첫 번째 tag 안에 들어 있는 tag들도 다 가지고 옴.
리스트로 돌려주지 않는다.


class명이 pagination인 div를 찾는다.

import requests
from bs4 import BeautifulSoup
indeed_result = requests.get("https://www.indeed.com/jobs?q=python&limit=50")
indeed_soup = BeautifulSoup(indeed_result.text, "html.parser")
pagination = indeed_soup.find("div", {"class": "pagination"})
print(pagination)✍️ pagination.find_all('a')
이제 pagination에서 a를 찾는다

출력해준다
import requests
from bs4 import BeautifulSoup
indeed_result = requests.get("https://www.indeed.com/jobs?q=python&limit=50")
indeed_soup = BeautifulSoup(indeed_result.text, "html.parser")
pagination = indeed_soup.find("div", {"class": "pagination"})
pages = pagination.find_all('a')
print(pages)✍️ page.find("span")
indeed html을 보면
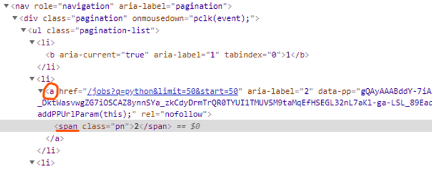
a 안에 span이 들어있다
각 a 안에 들어있는 span을 찾는다
import requests
from bs4 import BeautifulSoup
indeed_result = requests.get("https://www.indeed.com/jobs?q=python&limit=50")
indeed_soup = BeautifulSoup(indeed_result.text, "html.parser")
pagination = indeed_soup.find("div", {"class": "pagination"})
pages = pagination.find_all('a')
for page in pages:
print(page.find("span"))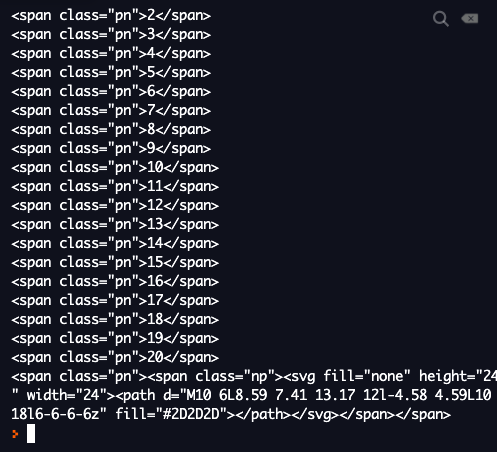
✍️ spans.append(page.find("span"))
마지막에 출력된 np(next page)를 없애줘야 한다.
빈 리스트를 만든다.
import requests
from bs4 import BeautifulSoup
indeed_result = requests.get("https://www.indeed.com/jobs?q=python&limit=50")
indeed_soup = BeautifulSoup(indeed_result.text, "html.parser")
pagination = indeed_soup.find("div", {"class": "pagination"})
pages = pagination.find_all('a')
spans = [] ⬅️ 빈 리스트를 만들어준다.
for page in pages:
print(page.find("span"))import requests
from bs4 import BeautifulSoup
indeed_result = requests.get("https://www.indeed.com/jobs?q=python&limit=50")
indeed_soup = BeautifulSoup(indeed_result.text, "html.parser")
pagination = indeed_soup.find("div", {"class": "pagination"})
pages = pagination.find_all('a')
spans = []
for page in pages:
spans.append(page.find("span")) ⬅️ .append 사용
print(spans)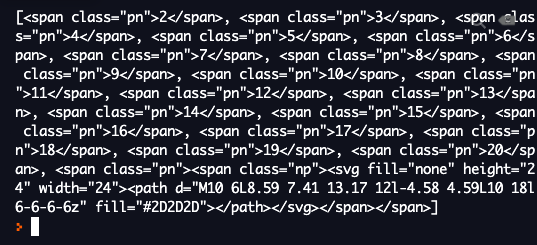
리스트에 span이 모두 들어가 있다.
✍️ 마지막에 있는 next 빼기 👉 spans[:-1]

마지막 거 빼주기
a[-1] ⬅️ 리스트 a의 마지막 요솟값
리스트의 슬라이싱
a[시작 번호:끝 번호] ⬅️ 끝 번호에 해당하는 것은 포함하지 않는다
시작 번호 생략시 처음부터 시작
a[:-1] ⬅️ 시작 번호가 생략되어 있으므로 처음부터 시작. 끝 번호는 -1. -1은 마지막 요솟값. 끝 번호에 해당하는 것은 포함하지 않으므로 마지막 요솟값은 포함하지 않는다.
import requests
from bs4 import BeautifulSoup
indeed_result = requests.get("https://www.indeed.com/jobs?q=python&limit=50")
indeed_soup = BeautifulSoup(indeed_result.text, "html.parser")
pagination = indeed_soup.find("div", {"class": "pagination"})
pages = pagination.find_all('a')
spans = []
for page in pages:
spans.append(page.find("span"))
print(spans[:-1]) ⬅️ 마지막 요소 포함하지 않는다.
마지막 값 제외됨
spans = spans[:-1] 로 바꿔준다.
import requests
from bs4 import BeautifulSoup
indeed_result = requests.get("https://www.indeed.com/jobs?q=python&limit=50")
indeed_soup = BeautifulSoup(indeed_result.text, "html.parser")
pagination = indeed_soup.find("div", {"class": "pagination"})
pages = pagination.find_all('a')
spans = []
for page in pages:
spans.append(page.find("span"))
spans = spans[:-1] ⬅️ 미리 만들어둔 빈 리스트에 넣음indeed 페이지 추출 완료
pages ➡️ links
page ➡️ link
spans ➡️ pages
수정하기
import requests
from bs4 import BeautifulSoup
indeed_result = requests.get("https://www.indeed.com/jobs?q=python&limit=50")
indeed_soup = BeautifulSoup(indeed_result.text, "html.parser")
pagination = indeed_soup.find("div", {"class": "pagination"})
links = pagination.find_all('a')
pages = []
for link in links:
pages.append(link.find("span"))
pages = pages[:-1]✍️ 페이지 숫자만 가져오기 👉 link.find("span").string
텍스트만 가져온다.

span을 찾은 다음 그 안에 있는 string만 가져온다.
import requests
from bs4 import BeautifulSoup
indeed_result = requests.get("https://www.indeed.com/jobs?q=python&limit=50")
indeed_soup = BeautifulSoup(indeed_result.text, "html.parser")
pagination = indeed_soup.find("div", {"class": "pagination"})
links = pagination.find_all('a')
pages = []
for link in links:
pages.append(link.find("span").string)
pages = pages[:-1]
print(pages)
👉
['2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20']텍스트만 추출되었다.
span 말고 link에서 .string 실행해도 동일한 결과를 얻는다.
import requests
from bs4 import BeautifulSoup
indeed_result = requests.get("https://www.indeed.com/jobs?q=python&limit=50")
indeed_soup = BeautifulSoup(indeed_result.text, "html.parser")
pagination = indeed_soup.find("div", {"class": "pagination"})
links = pagination.find_all('a')
pages = []
for link in links:
pages.append(link.string) ⬅️ link에서 string 가져오기
pages = pages[:-1]
print(pages)
👉
['2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20']
결과는 동일하다.예를 들어 anchor가 있고 이 요소 안에 다른 요소가 있고 그 요소에 srting이 오직 하나 있다면 그냥 anchor에서 string method를 실행하면 된다.
✍️ 페이지 숫자 str에서 정수로 바꿔주기 👉 int(link.string)
페이지 숫자가 str로 되어 있으므로 int로 바꿔준다.
int는 문자열로 되어 있는 숫자를 정수형으로 바꿔주는데
np(next page)는 숫자가 아니기 때문에 오류 남
import requests
from bs4 import BeautifulSoup
indeed_result = requests.get("https://www.indeed.com/jobs?q=python&limit=50")
indeed_soup = BeautifulSoup(indeed_result.text, "html.parser")
pagination = indeed_soup.find("div", {"class": "pagination"})
links = pagination.find_all('a')
pages = []
for link in links[:-1]: ⬅️ 처음부터 [:-1] 써줌
pages.append(int(link.string))
# pages = pages[:-1] ⬅️ 지움
print(pages)
👉
[2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20]✍️ 마지막 페이지 숫자 가져오기 👉 max_page = pages[-1]
마지막 페이지를 찾는다.
import requests
from bs4 import BeautifulSoup
indeed_result = requests.get("https://www.indeed.com/jobs?q=python&limit=50")
indeed_soup = BeautifulSoup(indeed_result.text, "html.parser")
pagination = indeed_soup.find("div", {"class": "pagination"})
links = pagination.find_all('a')
pages = []
for link in links[:-1]:
pages.append(int(link.string))
print(pages[-1]) ⬅️ [-1] 입력. 뒤에서 첫 번째 요소.
👉 20indeed의 마지막 페이지를 변수에 넣는다.
import requests
from bs4 import BeautifulSoup
indeed_result = requests.get("https://www.indeed.com/jobs?q=python&limit=50")
indeed_soup = BeautifulSoup(indeed_result.text, "html.parser")
pagination = indeed_soup.find("div", {"class": "pagination"})
links = pagination.find_all('a')
pages = []
for link in links[:-1]:
pages.append(int(link.string))
max_page = pages[-1] ⬅️ 변수를 만들어서 넣어준다.✍️ range(max_page)
최대 페이지 수 만큼 request를 보내야 함
range 함수를 사용한다.
import requests
from bs4 import BeautifulSoup
indeed_result = requests.get("https://www.indeed.com/jobs?q=python&limit=50")
indeed_soup = BeautifulSoup(indeed_result.text, "html.parser")
pagination = indeed_soup.find("div", {"class": "pagination"})
links = pagination.find_all('a')
pages = []
for link in links[:-1]:
pages.append(int(link.string))
max_page = pages[-1] ⬅️ 20
print(range(max_page)) ⬅️ range(20)
👉
range(0, 20) ⬅️ 0 이상 20 미만 (0 ~ 19)range(시작 숫자, 끝 숫자) ⬅️ 끝 숫자는 포함되지 않는다.
import requests
from bs4 import BeautifulSoup
indeed_result = requests.get("https://www.indeed.com/jobs?q=python&limit=50")
indeed_soup = BeautifulSoup(indeed_result.text, "html.parser")
pagination = indeed_soup.find("div", {"class": "pagination"})
links = pagination.find_all('a')
pages = []
for link in links[:-1]:
pages.append(int(link.string))
max_page = pages[-1] ⬅️ 20
for n in range(max_page): ⬅️ range(20) 0부터 20 미만의 숫자
print(n)
👉
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19✍️ f"start={n*50}"
페이지 숫자에 50을 곱해준다
0부터 19까지 페이지 넘버가 하나씩 차례로 대입되면서
페이지 넘버 * 50 문장을 반복적으로 수행한다.
n 변수에 50을 곱해준다.
import requests
from bs4 import BeautifulSoup
indeed_result = requests.get("https://www.indeed.com/jobs?q=python&limit=50")
indeed_soup = BeautifulSoup(indeed_result.text, "html.parser")
pagination = indeed_soup.find("div", {"class": "pagination"})
links = pagination.find_all('a')
pages = []
for link in links[:-1]:
pages.append(int(link.string))
max_page = pages[-1]
for n in range(max_page):
print(f"start={n*50}") ⬅️ n(0~19)*50
👉
start=0
start=50
start=100
start=150
start=200
start=250
start=300
start=350
start=400
start=450
start=500
start=550
start=600
start=650
start=700
start=750
start=800
start=850
start=900
start=9501 페이지 ⬅️ start=0
https://www.indeed.com/jobs?q=python&limit=50&start=0
20 페이지 ⬅️ start=950
https://www.indeed.com/jobs?q=python&limit=50&start=950
✍️ def extract_indeed_pages():
여태까지 작성한 걸 새로운 파일을 만들어서 따로 넣어준다.
함수 이름을 extract_indeed_pages 라고 정의해준다.
import requests
from bs4 import BeautifulSoup
def extract_indeed_pages(): ⬅️ 함수이름 새로 만들어줌
indeed_result = requests.get(
"https://www.indeed.com/jobs?q=python&limit=50")
indeed_soup = BeautifulSoup(indeed_result.text, "html.parser")
pagination = indeed_soup.find("div", {"class": "pagination"})
links = pagination.find_all('a')
pages = []
for link in links[:-1]:
pages.append(int(link.string))
max_page = pages[-1]✍️ URL 변수로 만들기
.get 안에 있는 링크를 꺼내서 변수로 만들어 준다.
URL = "https://www.indeed.com/jobs?q=python&limit=50"
나중에 계속 불러와서 쓸 수 있도록 변수로 만들어 준다.
.get 안에는 링크주소 대신 변수이름을 적어준다.
import requests
from bs4 import BeautifulSoup
URL = "https://www.indeed.com/jobs?q=python&limit=50"
def extract_indeed_pages():
indeed_result = requests.get(URL) ⬅️ 변수로 적어줌
indeed_soup = BeautifulSoup(indeed_result.text, "html.parser")
pagination = indeed_soup.find("div", {"class": "pagination"})
links = pagination.find_all('a')
pages = []
for link in links[:-1]:
pages.append(int(link.string))
max_page = pages[-1]새로 만든 파일 이름이 indeed.py이므로 변수명에 indeed를 굳이 안 넣어도 되므로 빼준다.
import requests
from bs4 import BeautifulSoup
URL = "https://www.indeed.com/jobs?q=python&limit=50"
def extract_indeed_pages():
result = requests.get(URL)
soup = BeautifulSoup(result.text, "html.parser")
pagination = soup.find("div", {"class": "pagination"})
links = pagination.find_all('a')
pages = []
for link in links[:-1]:
pages.append(int(link.string))
max_page = pages[-1]✍️ return max_page
마지막에 return max_page 추가
import requests
from bs4 import BeautifulSoup
URL = "https://www.indeed.com/jobs?q=python&limit=50"
def extract_indeed_pages():
result = requests.get(URL)
soup = BeautifulSoup(result.text, "html.parser")
pagination = soup.find("div", {"class": "pagination"})
links = pagination.find_all('a')
pages = []
for link in links[:-1]:
pages.append(int(link.string))
max_page = pages[-1]
return max_page✍️ main.py에 import 해주기
main.py로 돌아와서 새로 만든 함수를 import 해 준다.
indeed.py에 있는 extract_indeed_pages 함수를 import 해 준다.
from indeed import extract_indeed_pages
indeed 마지막 페이지 변수를 만들고
extract_indeed_pages 함수를 호출한 결괏값을 넣어준다.
max_indeed_pages = extract_indeed_pages()
from indeed import extract_indeed_pages
max_indeed_pages = extract_indeed_pages()
print(max_indeed_pages)
👉 20✍️ def extract_indeed_jobs(last_page):
indeed.py에 또 다른 함수를 만든다.
indeed page를 입력 받아서 페이지 수 만큼 request를 만드는 함수
함수이름은 extract_indeed_jobs로 한다.
def extract_indeed_jobs(last_page):
마지막 페이지를 매개변수로 받는다.
import requests
from bs4 import BeautifulSoup
URL = "https://www.indeed.com/jobs?q=python&limit=50"
def extract_indeed_pages():
result = requests.get(URL)
soup = BeautifulSoup(result.text, "html.parser")
pagination = soup.find("div", {"class": "pagination"})
links = pagination.find_all('a')
pages = []
for link in links[:-1]:
pages.append(int(link.string))
max_page = pages[-1]
return max_page
def extract_indeed_jobs(last_page): ⬅️ 매개변수로 마지막 페이지 받음
for page in range(last_page):
print(f"&start={page*50}")✍️ LIMIT 변수 생성
URL변수에서 맨 끝에 있는 50을 따로 변수로 만들어 준다.
나중에 20개씩 보기, 30개씩 보기로 바꿔줄 수도 있기 때문.
LIMIT = 50
URL = f"https://www.indeed.com/jobs?q=python&limit={LIMIT}"
import requests
from bs4 import BeautifulSoup
LIMIT = 50 ⬅️ 나중에 바꿀 수도 있어서 따로 빼주었다.
URL = f"https://www.indeed.com/jobs?q=python&limit={LIMIT}"
def extract_indeed_pages():
result = requests.get(URL)
soup = BeautifulSoup(result.text, "html.parser")
pagination = soup.find("div", {"class": "pagination"})
links = pagination.find_all('a')
pages = []
for link in links[:-1]:
pages.append(int(link.string))
max_page = pages[-1]
return max_page
def extract_indeed_jobs(last_page):
for page in range(last_page):
print(f"&start={page*LIMIT}") ⬅️ 50 대신 LIMIT변수 사용✍️ main.py에 import extract_indeed_jobs
main.py로 가서 extract_indeed_jobs 함수를 추가로 import 해준다.
from indeed import extract_indeed_pages, extract_indeed_jobs
콤마 사용해서 추가하면 됨
변수 이름 수정
max_indeed_pages ➡️ last_indeed_page
from indeed import extract_indeed_pages, extract_indeed_jobs
last_indeed_page = extract_indeed_pages()
extract_indeed_jobs(last_indeed_page)
👉
&start=0
&start=50
&start=100
&start=150
&start=200
&start=250
&start=300
&start=350
&start=400
&start=450
&start=500
&start=550
&start=600
&start=650
&start=700
&start=750
&start=800
&start=850
&start=900
&start=950✍️ requests.get(f"{URL}&start={page*LIMIT}")
이제 URL 변수랑 위에 나온 결괏값이랑 합쳐준다.
result 라는 변수 만들고
result = requests.get(f"{URL}&start={page*LIMIT}")
.status_code 출력
print(result.status_code)
import requests
from bs4 import BeautifulSoup
LIMIT = 50
URL = f"https://www.indeed.com/jobs?q=python&limit={LIMIT}"
def extract_indeed_pages():
result = requests.get(URL)
soup = BeautifulSoup(result.text, "html.parser")
pagination = soup.find("div", {"class": "pagination"})
links = pagination.find_all('a')
pages = []
for link in links[:-1]:
pages.append(int(link.string))
max_page = pages[-1]
return max_page
def extract_indeed_jobs(last_page):
for page in range(last_page):
result = requests.get(f"{URL}&start={page*LIMIT}")
print(result.status_code)
👉
200
200
200
200
200
200
200
200
200
200
200
200
200
200
200
200
200
200
200
200
# 200이 20개 출력됨✍️ jobs = [ ]
indeed.py에 추출한 일자리 정보를 담을 빈 리스트를 만든다.
# indeed.py
import requests
from bs4 import BeautifulSoup
LIMIT = 50
URL = f"https://www.indeed.com/jobs?q=python&limit={LIMIT}"
def extract_indeed_pages():
result = requests.get(URL)
soup = BeautifulSoup(result.text, "html.parser")
pagination = soup.find("div", {"class": "pagination"})
links = pagination.find_all('a')
pages = []
for link in links[:-1]:
pages.append(int(link.string))
max_page = pages[-1]
return max_page
def extract_indeed_jobs(last_page):
jobs = [] ⬅️ # 추출한 일자리를 담을 빈 리스트 생성
for page in range(last_page):
result = requests.get(f"{URL}&start={page*LIMIT}")
print(result.status_code)
return jobs ⬅️ # 최종적으로 일자리 담은 리스트 반환
질문드려도 될까요? 제가 main.py에서 코드를 복사한다음에 indeed.py 파일 만들어서 그대로 복사 붙여 넣기해서 def extract_indeed_pages(): 함수를 만들었습니다 그리고 다시 main.py에 있던 원래 코드는 지우고 indeed.py를 실행하면 아무런 반응이 없습니다.. 그래서 main.py에 있던 원래 코드를 남겨두면 실행이 됩니다.. 왜 그럴까요 ㅠㅠㅠ 여기서 이틀째 진도를 못나가고 있어요
확인해보니까 indeed.py에서 run을 해도 main.py가 실행이 되네요 왜그럴까요