
노마드 코더 Python으로 웹 스크래퍼 만들기
https://nomadcoders.co/python-for-beginners
2.11 StackOverflow extract job
✍️ 가져온 일자리 목록에서 직무 추출하기
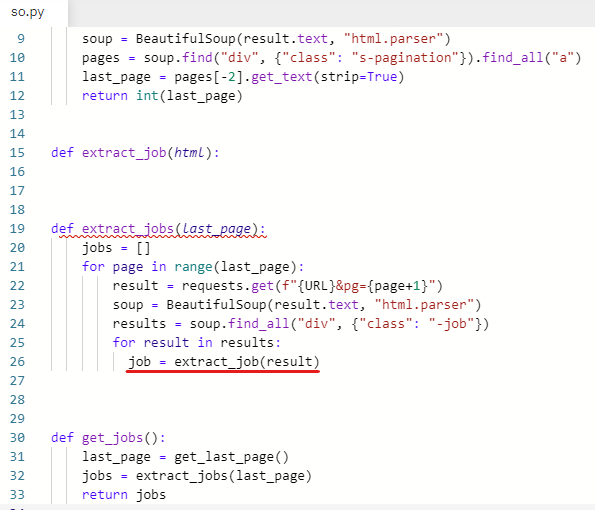
일자리를 가져오는 함수를 새로 만들어 준다.
인자로 html을 받는다.
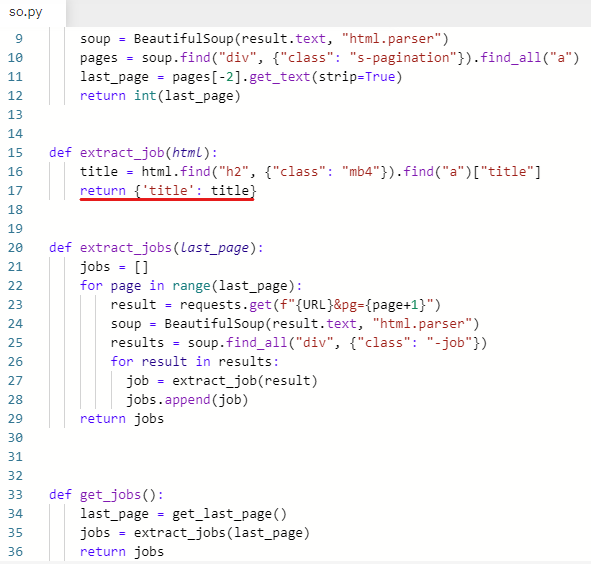
def extract_job(html):

extract_jobs 함수의 for문에 extract_job 함수를 호출한다.
job = extract_job(result)
인자로 들어간 result는 results 리스트의 요소이다.
result는 html이다.
extract_job 함수의 결괏값인 job을 jobs 리스트에 넣어준다.
jobs.append(job)


그리고 jobs 리스트를 반환해준다. 내어쓰기 해주기.
return jobs

이제 직무를 가져와야 한다.
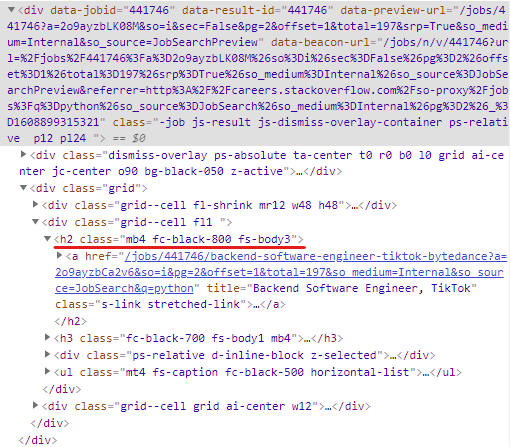
어떤 태그를 가져오면 되는지 확인하기 위해 stackoverflow에서 inspect 실행

class명이 mb4인 h2를 가져오기로 한다.
title = html.find("h2", {"class": "mb4"})
class명이 mb4인 h2를 가져온다.

그리고 나서 h2 안에 있는 anchor를 가져오고
anchor 안에 있는 title이라는 attribute를 가져오도록 한다.

title = html.find("h2", {"class": "mb4"}).find("a")["title"]
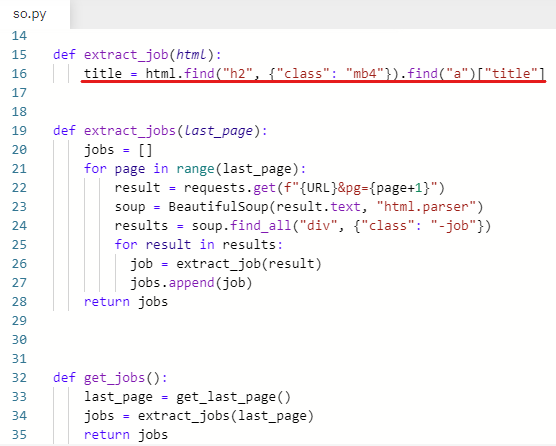
잘 가져왔는지 확인하기 위해 title을 출력해본다.
print(title)
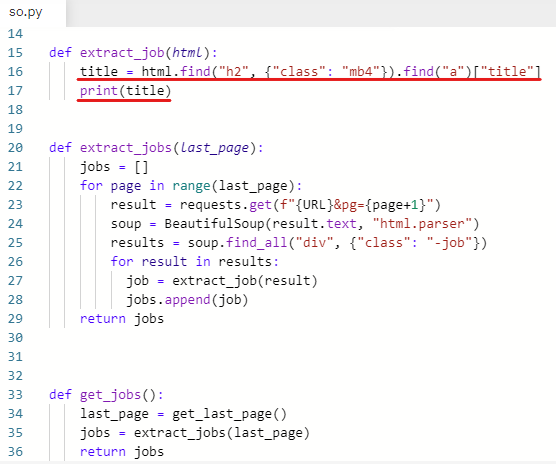

잘 출력됐다. 직무 가져오는 것을 성공했다.
추출한 값을 딕셔너리 형태로 반환해준다.
return {'title': title}
import requests
from bs4 import BeautifulSoup
URL = f"https://stackoverflow.com/jobs?q=python"
def get_last_page():
result = requests.get(URL)
soup = BeautifulSoup(result.text, "html.parser")
pages = soup.find("div", {"class": "s-pagination"}).find_all("a")
last_page = pages[-2].get_text(strip=True)
return int(last_page)
def extract_job(html):
title = html.find("h2", {"class": "mb4"}).find("a")["title"]
return {'title': title}
def extract_jobs(last_page):
jobs = []
for page in range(last_page):
result = requests.get(f"{URL}&pg={page+1}")
soup = BeautifulSoup(result.text, "html.parser")
results = soup.find_all("div", {"class": "-job"})
for result in results:
job = extract_job(result)
jobs.append(job)
return jobs
def get_jobs():
last_page = get_last_page()
jobs = extract_jobs(last_page)
return jobs✍️ 가져온 일자리 목록에서 회사명, 위치 추출하기
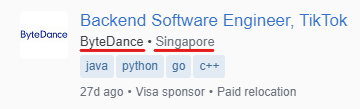
stackoverflow를 보면 회사 이름과 위치가 나란히 나와 있다.
inspect를 실행하여 어떤 태그를 가져오면 되는지 확인한다.
h3 안을 보면 span이 두 개가 있는 것을 볼 수 있는데
하나는 company(회사이름)고 다른 하나는 location(위치)이다.
class명이 mb4인 h3을 가져오기로 한다.

변수를 생성한다.
회사 이름만 있는 게 아니니까 company_row라고 해준다.
company_row = html.find("h3", {"class": "mb4"})
class명이 mb4인 h3을 가져온다.
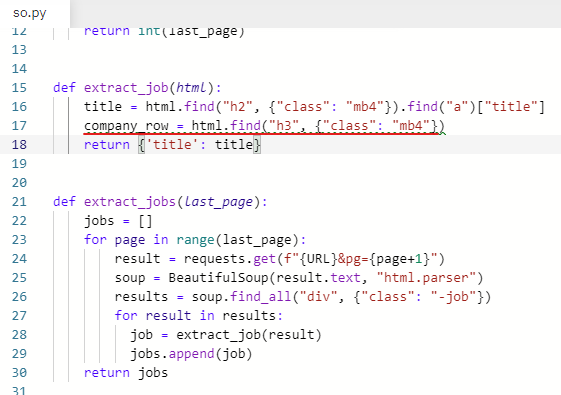
company_row 안에 있는 span 2개를 가져온다.
company_row = html.find("h3", {"class": "mb4"}).find_all(“span”)
잘 가져왔는지 확인하기 위해 출력해본다.
print(company_row)
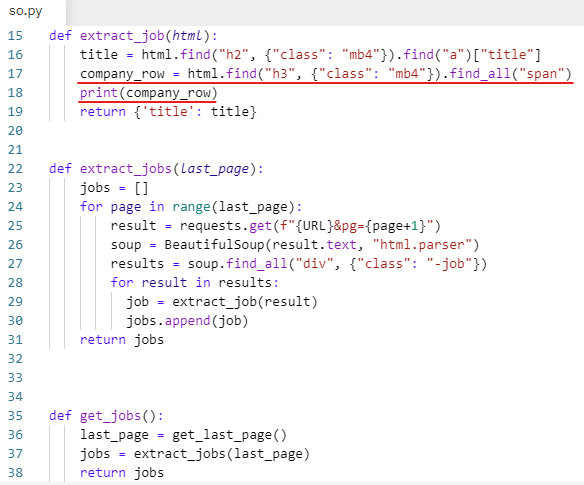

span 두 개가 나온 것을 볼 수 있다.
첫 번째 span이 company(회사명)
두 번째 span이 location(위치)
company, location 변수 생성
company_row 리스트 인덱싱 사용해서 생성한 변수에 값 넣어주기
company = company_row[0]
company = company_row 리스트 첫 번째에 있는 요소(첫 번째 span)
location = company_row[1]
location = company_row 리스트 두 번째에 있는 요소(두 번째 span)
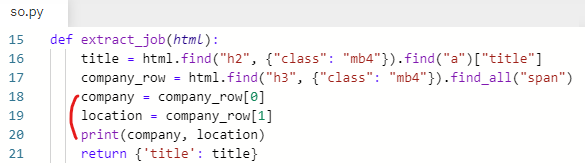
print(company, location)
값이 잘 들어갔나 확인하기 위해 출력해본다.

잘 출력됐다.
이제 span에서 .string을 사용해서 텍스트만 가져온다.
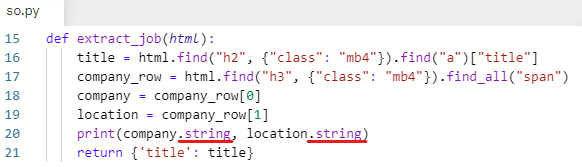

잘 출력됐다.
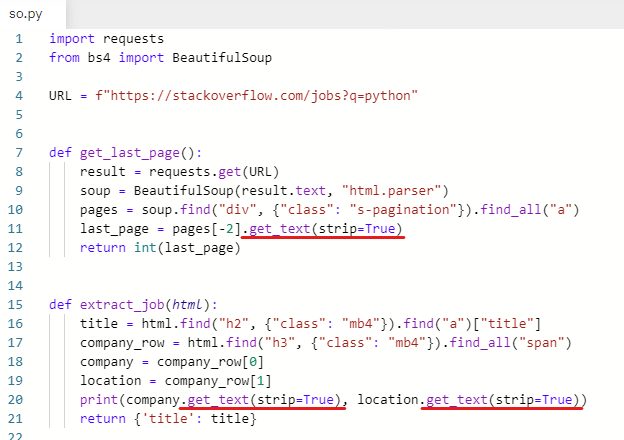
앞에서 사용했던 .get_text(strip=True)를 사용하여 똑같이 공백을 지워준다.
import requests
from bs4 import BeautifulSoup
URL = f"https://stackoverflow.com/jobs?q=python"
def get_last_page():
result = requests.get(URL)
soup = BeautifulSoup(result.text, "html.parser")
pages = soup.find("div", {"class": "s-pagination"}).find_all("a")
last_page = pages[-2].get_text(strip=True)
return int(last_page)
def extract_job(html):
title = html.find("h2", {"class": "mb4"}).find("a")["title"]
company_row = html.find("h3", {"class": "mb4"}).find_all("span")
company = company_row[0]
location = company_row[1]
print(company.get_text(strip=True), location.get_text(strip=True))
return {'title': title}
def extract_jobs(last_page):
jobs = []
for page in range(last_page):
result = requests.get(f"{URL}&pg={page+1}")
soup = BeautifulSoup(result.text, "html.parser")
results = soup.find_all("div", {"class": "-job"})
for result in results:
job = extract_job(result)
jobs.append(job)
return jobs
def get_jobs():
last_page = get_last_page()
jobs = extract_jobs(last_page)
return jobs
공백이 지워졌다.
📖 (recursive=False)
The recursive argument
https://www.crummy.com/software/BeautifulSoup/bs4/doc/#the-recursive-argument
find_all만 사용하면 다 가져오는데
recursive=False를 써주면 바로 밑 자식만 가져옴. 직계 자식.
