

노마드 코더 Python으로 웹 스크래퍼 만들기
https://nomadcoders.co/python-for-beginners
2.7 Extracting Companies
직무를 가지고 왔으니 이제 회사 이름을 가져와야 한다.
✍️ class명이 company인 span 가져오기
회사 이름을 가져오기 위해 class명이 company인 span을 가져오도록 한다.

company = result.find("span", {"class":"company"})
📕 find와 find_all의 차이점
soup.find_all('a')
매개변수로 tag 입력
해당되는 모든 tag들 리스트로 반환
soup.find('a')
매개변수로 tag 입력
해당되는 첫 번째 tag만 가져온다.
그 첫 번째 tag 안에 들어 있는 tag들도 다 가지고 옴.
리스트로 돌려주지 않는다.
import requests
from bs4 import BeautifulSoup
LIMIT = 50
URL = f"https://www.indeed.com/jobs?q=python&limit={LIMIT}"
def extract_indeed_pages():
result = requests.get(URL)
soup = BeautifulSoup(result.text, "html.parser")
pagination = soup.find("div", {"class": "pagination"})
links = pagination.find_all('a')
pages = []
for link in links[:-1]:
pages.append(int(link.string))
max_page = pages[-1]
return max_page
def extract_indeed_jobs(last_page):
jobs = []
#for page in range(last_page):
result = requests.get(f"{URL}&start={0*LIMIT}")
soup = BeautifulSoup(result.text, "html.parser")
results = soup.find_all("div", {"class": "jobsearch-SerpJobCard"})
for result in results:
title = result.find("h2", {"class": "title"}).find("a")["title"]
company = result.find("span", {"class": "company"}) # company 변수 생성
print(company) # company 변수 출력
return jobs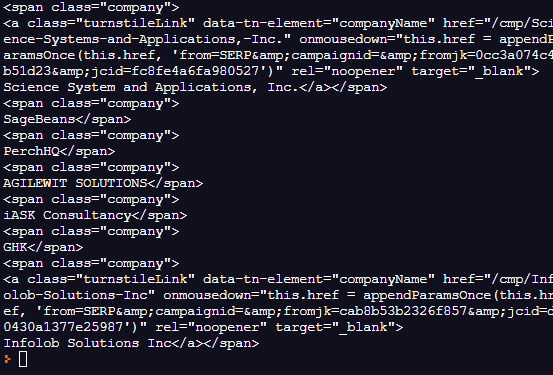
회사 목록이 출력되었다.
✍️ if문 사용하여 링크가 있는 회사 조건문 만들기
indeed 사이트로 가서 inspect 해보면 회사 이름에 링크가 있는 것과 없는 것이 있다.
🔹 company 링크 있는 거
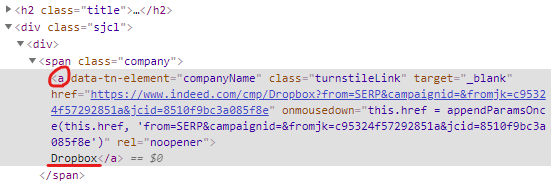
🔹 company 링크 없는 거
if문을 사용하여 링크가 있으면 ~, 링크가 없으면 ~ 조건문을 만든다.
if company.find("a") is not None: # 링크가 있으면
print(company.find("a").string) # anchor의 string 출력
else: # 없으면
print(company.string) # span의 string 출력
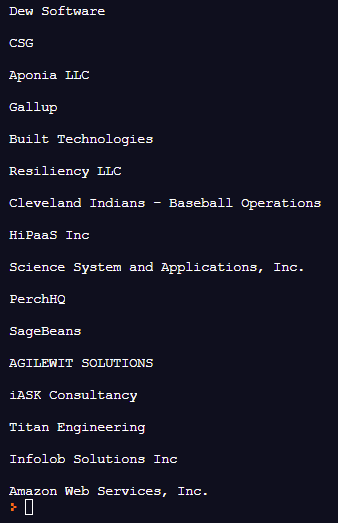
회사 이름을 가져왔다.
✍️ 코드 정리해주기
company_anchor 라는 변수를 추가해준다.
company_anchor = company.find("a")
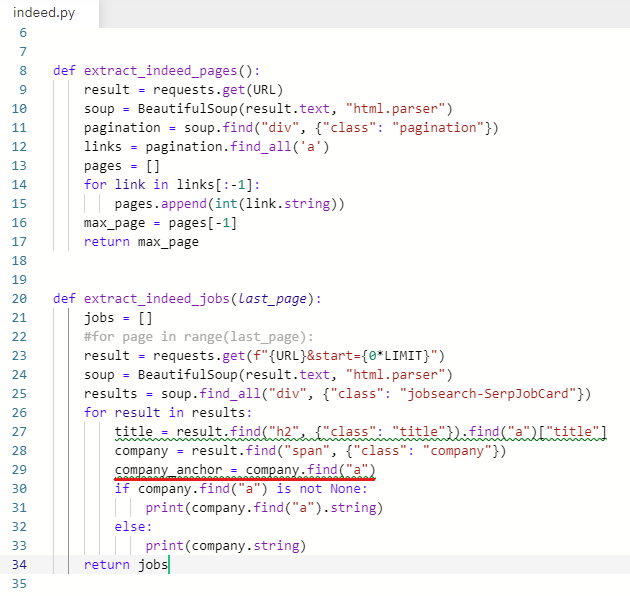
company.find("a")를 지우고 company_anchor 변수로 바꿔준다.
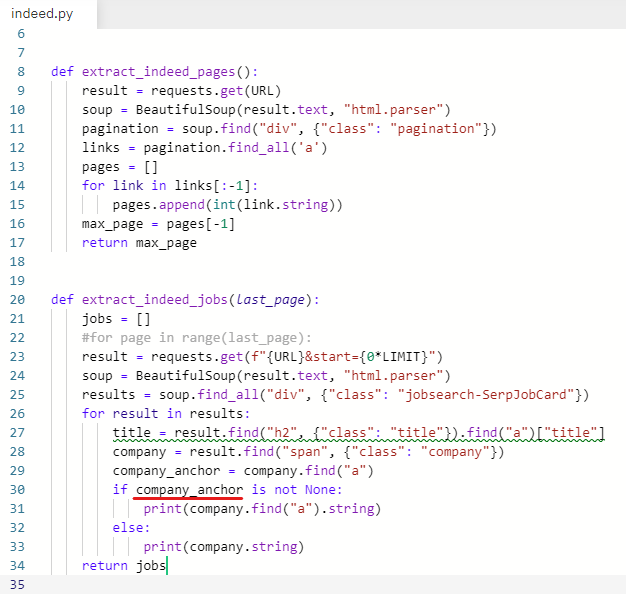
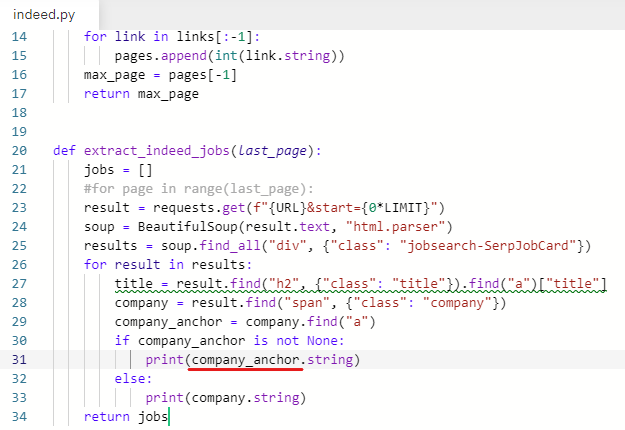
오류가 나진 않는지 한 번 실행해본다.

결과는 같게 나온다.
✍️ str 함수 사용하여 string으로 만들기
공백을 지우기 위해 str 함수를 사용하여 string으로 만든다.
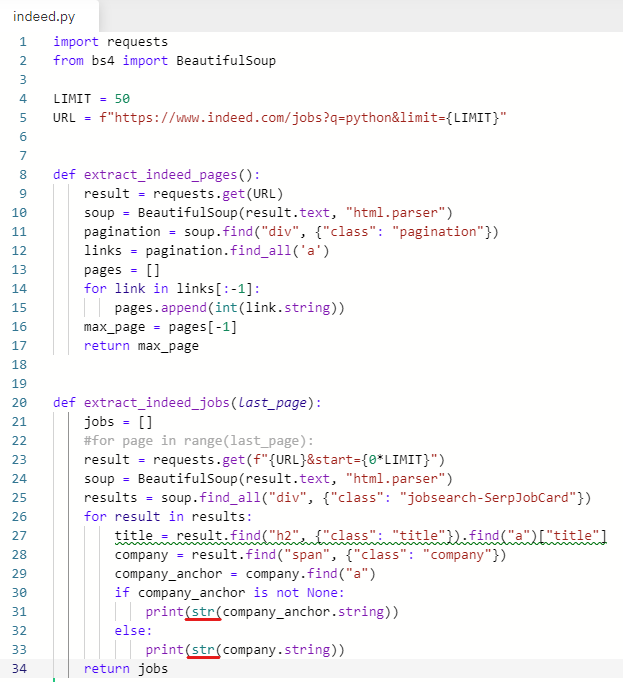
import requests
from bs4 import BeautifulSoup
LIMIT = 50
URL = f"https://www.indeed.com/jobs?q=python&limit={LIMIT}"
def extract_indeed_pages():
result = requests.get(URL)
soup = BeautifulSoup(result.text, "html.parser")
pagination = soup.find("div", {"class": "pagination"})
links = pagination.find_all('a')
pages = []
for link in links[:-1]:
pages.append(int(link.string))
max_page = pages[-1]
return max_page
def extract_indeed_jobs(last_page):
jobs = []
#for page in range(last_page):
result = requests.get(f"{URL}&start={0*LIMIT}")
soup = BeautifulSoup(result.text, "html.parser")
results = soup.find_all("div", {"class": "jobsearch-SerpJobCard"})
for result in results:
title = result.find("h2", {"class": "title"}).find("a")["title"]
company = result.find("span", {"class": "company"})
company_anchor = company.find("a")
if company_anchor is not None:
print(str(company_anchor.string)) # str 함수 추가
else:
print(str(company.string)) # str 함수 추가
return jobs✍️ 변수에는 새로운 값을 넣을 수 있다.
기존의 company 변수를 사용해서 새로운 값을 넣어준다.
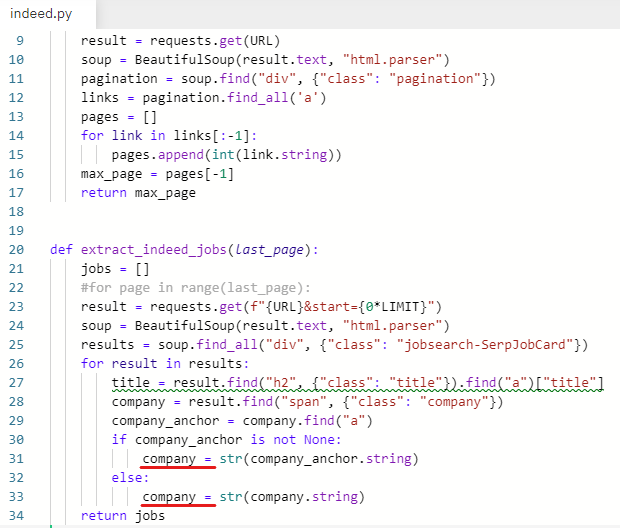
import requests
from bs4 import BeautifulSoup
LIMIT = 50
URL = f"https://www.indeed.com/jobs?q=python&limit={LIMIT}"
def extract_indeed_pages():
result = requests.get(URL)
soup = BeautifulSoup(result.text, "html.parser")
pagination = soup.find("div", {"class": "pagination"})
links = pagination.find_all('a')
pages = []
for link in links[:-1]:
pages.append(int(link.string))
max_page = pages[-1]
return max_page
def extract_indeed_jobs(last_page):
jobs = []
#for page in range(last_page):
result = requests.get(f"{URL}&start={0*LIMIT}")
soup = BeautifulSoup(result.text, "html.parser")
results = soup.find_all("div", {"class": "jobsearch-SerpJobCard"})
for result in results:
title = result.find("h2", {"class": "title"}).find("a")["title"]
company = result.find("span", {"class": "company"})
company_anchor = company.find("a")
if company_anchor is not None:
company = str(company_anchor.string) # company 변수 입력
else:
company = str(company.string) # company 변수 입력
return jobs✍️ 공백 지우기(strip)
strip은 빈 칸이 포함된 string 다음에 쓸 수 있다.
company = company.strip()
괄호 안이 비어있으면 빈 칸을 지워준다.
괄호 안에 문자를 입력하면
string에 있는 해당 문자를 다 지워준다.
import requests
from bs4 import BeautifulSoup
LIMIT = 50
URL = f"https://www.indeed.com/jobs?q=python&limit={LIMIT}"
def extract_indeed_pages():
result = requests.get(URL)
soup = BeautifulSoup(result.text, "html.parser")
pagination = soup.find("div", {"class": "pagination"})
links = pagination.find_all('a')
pages = []
for link in links[:-1]:
pages.append(int(link.string))
max_page = pages[-1]
return max_page
def extract_indeed_jobs(last_page):
jobs = []
#for page in range(last_page):
result = requests.get(f"{URL}&start={0*LIMIT}")
soup = BeautifulSoup(result.text, "html.parser")
results = soup.find_all("div", {"class": "jobsearch-SerpJobCard"})
for result in results:
title = result.find("h2", {"class": "title"}).find("a")["title"]
company = result.find("span", {"class": "company"})
company_anchor = company.find("a")
if company_anchor is not None:
company = str(company_anchor.string)
else:
company = str(company.string)
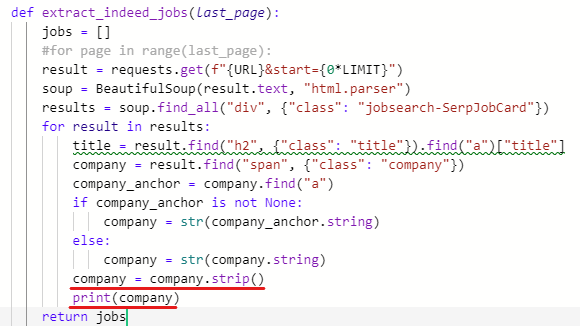
company = company.strip() # strip 함수로 공백 지우기
print(company) # 공백을 지운 뒤 출력해준다.
return jobs
공백이 지워진 것을 볼 수 있다.
✍️ 직무와 회사명 출력해보기
title과 company를 출력해본다.
import requests
from bs4 import BeautifulSoup
LIMIT = 50
URL = f"https://www.indeed.com/jobs?q=python&limit={LIMIT}"
def extract_indeed_pages():
result = requests.get(URL)
soup = BeautifulSoup(result.text, "html.parser")
pagination = soup.find("div", {"class": "pagination"})
links = pagination.find_all('a')
pages = []
for link in links[:-1]:
pages.append(int(link.string))
max_page = pages[-1]
return max_page
def extract_indeed_jobs(last_page):
jobs = []
#for page in range(last_page):
result = requests.get(f"{URL}&start={0*LIMIT}")
soup = BeautifulSoup(result.text, "html.parser")
results = soup.find_all("div", {"class": "jobsearch-SerpJobCard"})
for result in results:
title = result.find("h2", {"class": "title"}).find("a")["title"]
company = result.find("span", {"class": "company"})
company_anchor = company.find("a")
if company_anchor is not None:
company = str(company_anchor.string)
else:
company = str(company.string)
company = company.strip()
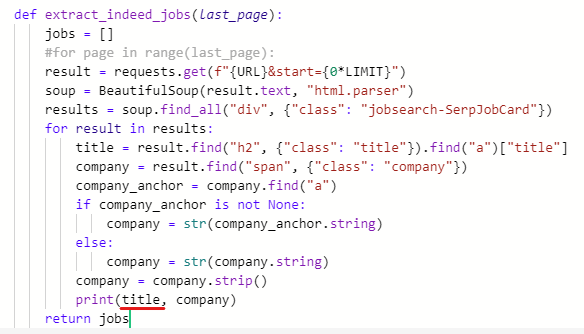
print(title, company) # title과 company 출력해주기
return jobs
둘 다 잘 출력 되었다.
