
노마드 코더 Python으로 웹 스크래퍼 만들기
https://nomadcoders.co/python-for-beginners
2.9 StackOverflow Pages
✍️ main.py 간단하게 해주기
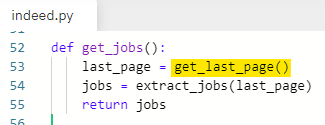
indeed.py로 가서 get_jobs라는 새로운 함수를 만들어 준다.
딱히 인자는 필요 없다.
def get_jobs():
수행할 문장은 main.py에서 가져온다.
아래 두 줄 복사
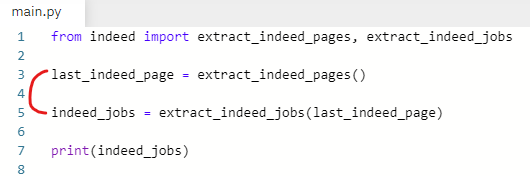
get_jobs 함수에 붙여넣기

indeed_jobs 변수이름을 jobs로 수정

그리고 jobs를 반환하는 걸로 한다.
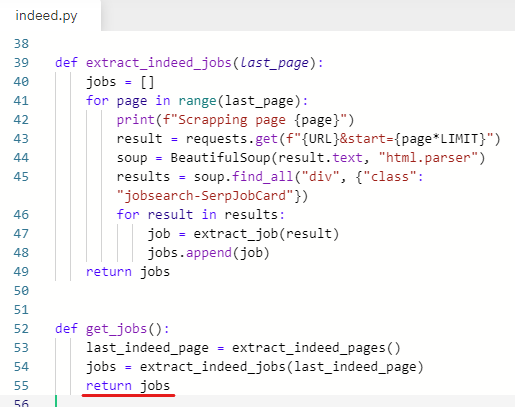
변수와 함수 이름에 들어있는 indeed를 다 지워준다.
indeed.py에 있으니까 굳이 이름에 indeed가 들어가지 않아도 된다.
extract_indeed_pages → get_last_page
get_jobs 함수에서만 수정하지 말고 모두 수정해주기

extract_indeed_jobs → get_jobs
get_jobs 함수에서만 수정하지 말고 모두 수정해주기
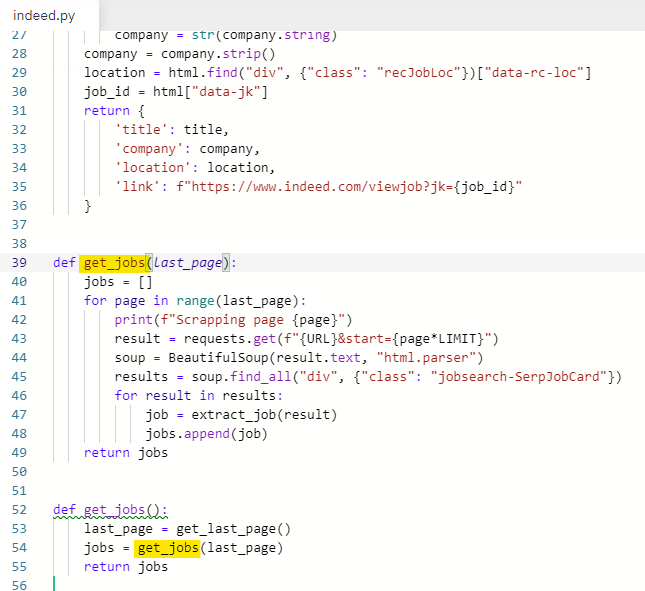
last_indeed_page → last_page
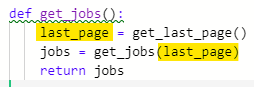
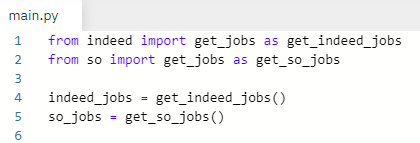
main.py로 가서 새로 만든 get_jobs 함수를 import 해 준다.
두 개를 합친 게 get_jobs 함수니까 지우고

get_jobs 함수를 입력한다.
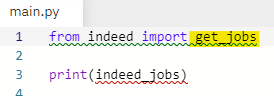
as를 써서 함수 이름을 get_indeed_jobs로 바꿔서 import 해 준다.
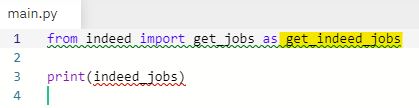
indeed_jobs = get_indeed_jobs() 입력

잘 동작하는지 확인하기 위해 실행해본다.

오류가 났다.
함수 이름이 중복되어 있었다.
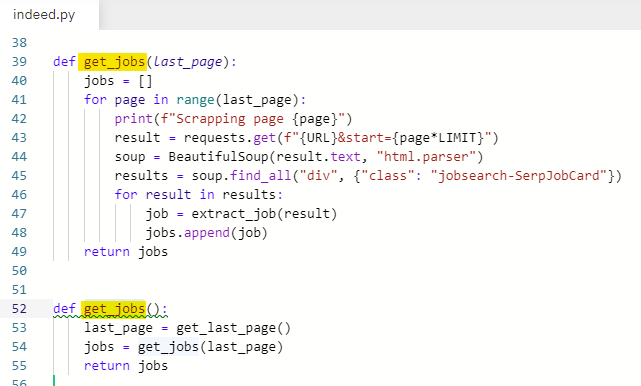
하나를 extract_jobs로 바꿔준다.

함수이름을 바꿔주고 다시 실행해보니 오류가 안 난다.
이렇게 함수를 여러 개로 쪼개서 indeed.py 안에 모아두면
main.py에 코드를 길게 써주지 않아도 된다.
✍️ stackoverflow 시작
이제 stackoverflow 페이지에서 정보를 추출할 차례이다.
https://stackoverflow.com/jobs?q=python
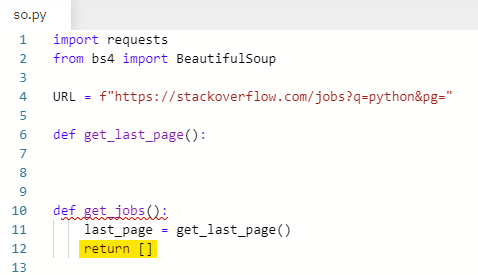
so.py 라는 새로운 파일을 만든다.

so.py에 처음 작성했던 코드를 복붙한다.
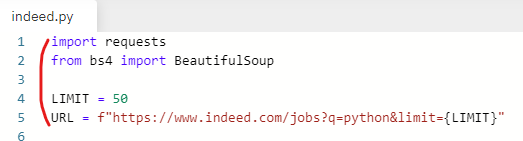
URL을 stackoverflow 페이지로 바꿔준다.
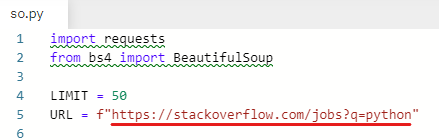
stackoverflow 사이트로 가서
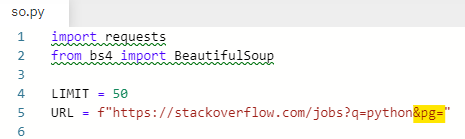
페이지를 이동할 때 주소창이 어떻게 바뀌는지 확인한다.
2페이지로 이동해본다. 주소창을 보면 &pg=2 라고 바뀐다.

URL에 입력해준다.
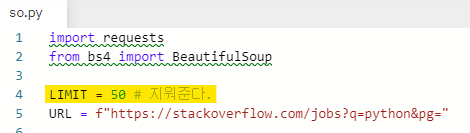
LIMIT은 사용하지 않으므로 지워준다.
get jobs 라는 함수를 새로 만든다.
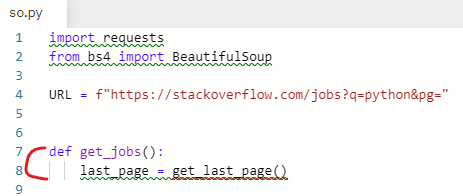
indeed.py에서 했던 것을 그대로 참고한다.
임시로 리스트 하나를 반환해주도록 한다.
main.py로 가서 so.py에서 만든 get jobs 함수를 import 해 준다.

맨 밑에 있는 print도 지워줬다.
stackoverflow만 테스트 해 보기 위해 indeed_jobs를 임시로 주석 처리 해 준다.
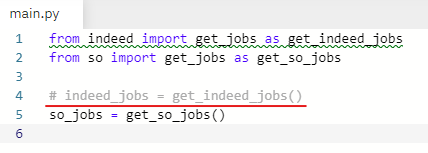
get_jobs 함수에 빨간줄이 떠 있다.
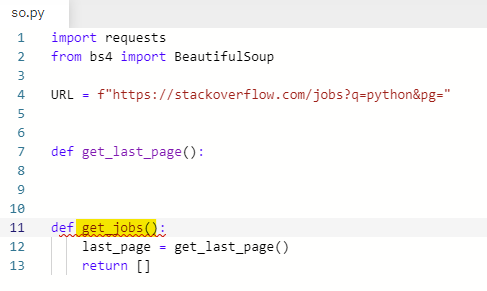
✍️ stackoverflow 페이지 가져오기
첫 번째, 페이지를 가져온다.
두 번째, request를 만든다.
세 번째, job을 추출한다.
stackoverflow 웹사이트 하단에 있는 페이지 넘버를 클릭해서 inspect 실행
s-pagination

indeed와 마찬가지로 페이지 넘버 마지막에 next가 있다

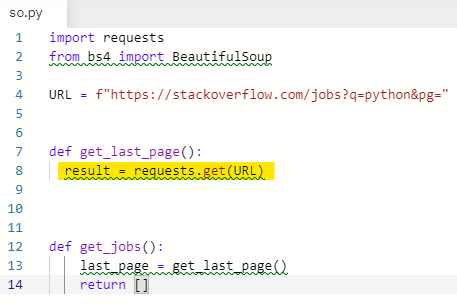
get_last_page 함수에 request를 만들어 준다.
result = requests.get(URL)
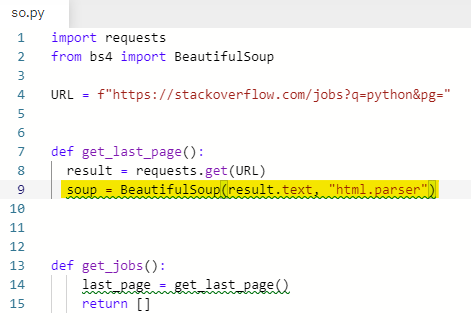
그리고 soup을 만들어 준다.
soup = BeautifulSoup(result.text, "html.parser")
잘 동작하는지 확인하기 위해 soup를 출력해 본다.

잘 동작한다.
이제 s-pagination을 가지고 온다.
pagination = soup.find("div", {"class": "s-pagination"})
출력해 본다.
print(pagination)
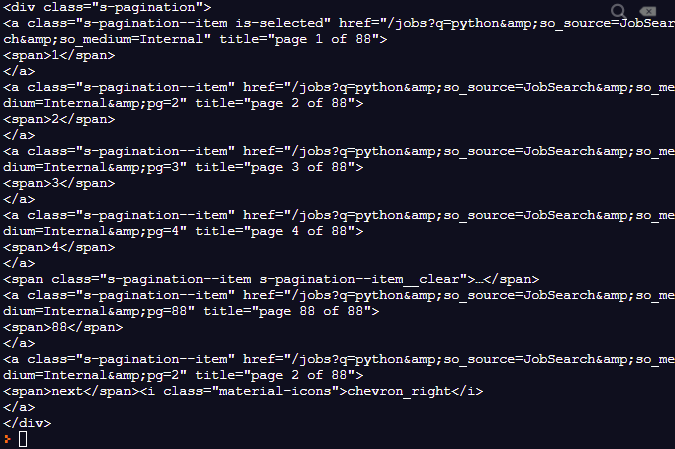
잘 동작한다.
이제 s-pagination 안에 있는 모든 anchor를 가져온다.

변수 이름을 pagination에서 pages로 바꿔준다.
s-pagination 안에 있는 모든 anchor 가져오기

실행해본다.
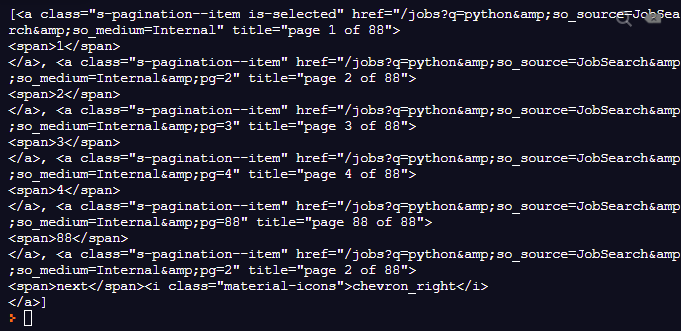
잘 동작한다.
