fine-tuning 해보기
1. jsonl 형식의 데이터 준비
다음과 같은 형식으로 데이터를 준비한다.
- prompt: GPT에게 줄 입력값
- completion: GPT에게 기대하는 대답 (정답)
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
...2. 데이터 reformat
openai에서는 fine-tuning을 더 잘 할 수 있도록 데이터를 reformat하는 기능을 지원해준다고 한다.
openai tools fine_tunes.prepare_data -f <LOCAL_FILE>위 명령어로 reformat을 수행하면 다음과 같이 문장 끝에 ' END'를 추가하는 등 데이터 형식 등을 조금 수정해준다.
Analyzing...
- Your file contains 2 prompt-completion pairs. In general, we recommend having at least a few hundred examples. We've found that performance tends to linearly increase for every doubling of the number of examples
- All prompts end with suffix `다.`
WARNING: Some of your prompts contain the suffix `다.` more than once. We strongly suggest that you review your prompts and add a unique suffix
- All completions start with prefix `1. 회의 안건: `. Most of the time you should only add the output data into the completion, without any prefix
- Your data does not contain a common ending at the end of your completions. Having a common ending string appended to the end of the completion makes it clearer to the fine-tuned model where the completion should end. See https://platform.openai.com/docs/guides/fine-tuning/preparing-your-dataset for more detail and examples.
- The completion should start with a whitespace character (` `). This tends to produce better results due to the tokenization we use. See https://platform.openai.com/docs/guides/fine-tuning/preparing-your-dataset for more details
Based on the analysis we will perform the following actions:
- [Recommended] Remove prefix `1. 회의 안건: ` from all completions [Y/n]: y
- [Recommended] Add a suffix ending ` END` to all completions [Y/n]: y
- [Recommended] Add a whitespace character to the beginning of the completion [Y/n]: y
Your data will be written to a new JSONL file. Proceed [Y/n]: y
Wrote modified file to `data/example_data_prepared.jsonl`
Feel free to take a look!
Now use that file when fine-tuning:
> openai api fine_tunes.create -t "data/example_data_prepared.jsonl"
After you’ve fine-tuned a model, remember that your prompt has to end with the indicator string `다.` for the model to start generating completions, rather than continuing with the prompt. Make sure to include `stop=[" END"]` so that the generated texts ends at the expected place.
Once your model starts training, it'll approximately take 2.47 minutes to train a `curie` model, and less for `ada` and `babbage`. Queue will approximately take half an hour per job ahead of you.3. fine-tuning 수행
openai --api-key API_KEY api fine_tunes.create -t <TRAIN_FILE_ID_OR_PATH> -m <BASE_MODEL>
친절하게 cost를 미리 알려준다.
- 진행 상황 확인
openai --api-key API_KEY api fine_tunes.get -i <YOUR_FINE_TUNE_JOB_ID>{
"object": "fine-tune",
"id": YOUR_FINE_TUNE_JOB_ID,
"hyperparams": {
"n_epochs": 4,
"batch_size": 1,
"prompt_loss_weight": 0.01,
"learning_rate_multiplier": 0.1
},
"organization_id": ORGANIZATION_ID,
"model": "davinci",
"training_files": [
{
"object": "file",
"id": "file-u5",
"purpose": "fine-tune",
"filename": "./data/example_data_prepared.jsonl",
"bytes": 1265,
"created_at": 1694,
"status": "processed",
"status_details": null
}
],
"validation_files": [],
"result_files": [
{
"object": "file",
"id": "file-5k",
"purpose": "fine-tune-results",
"filename": "compiled_results.csv",
"bytes": 510,
"created_at": 1694,
"status": "processed",
"status_details": null
}
],
"created_at": 16943,
"updated_at": 16943,
"status": "succeeded",
"fine_tuned_model": "davinci:ft-personal-2023-09-10-12-04-24",
"events":
...
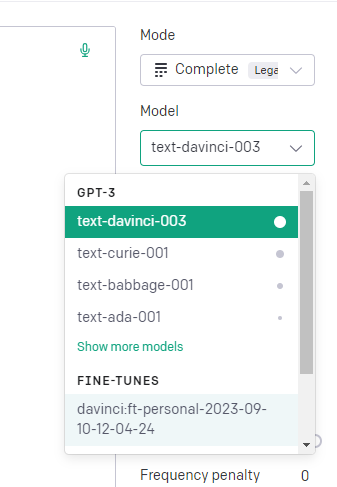
4. 결과 확인
다음과 같이 fine-tune한 모델의 이름을 받아서 이용할 수 있다.
result = openai.FineTune.list()
fine_tuned_model = result['data'][0]["fine_tuned_model"] #fine_tune한 모델의 이름
new_prompt = "Which part is the smallest bone in the entire human body?"
answer = openai.Completion.create(
model=fine_tuned_model,
prompt=new_prompt
)
answer['choices'][0]['text'] #결과 텍스트또한, 다음과 같이 playground에서 사용해볼 수도 있다.
참고문헌

꾸준히!