혼자 공부하는 머신러닝 - 2주차
핵심 포인트
(1) 회귀 : 임의의 수치를 예측하는 문제, 타깃값도 임의의 수치가 된다.
(2) k-최근접 이웃 회귀 : k-최근접 이웃 알고리즘을 사용하여 가장 가까운 이웃 샘플을 찾고 이 샘플들의 타깃값을 평균하여 예측으로 삼는다.
(3) 결정계수 : 1에 가까울 수록 좋고, 0에 가깝다면 성능이 나쁜 모델임
(4) 과대적합, 과소적합
과대적합 : 모델의 훈련 세트 성능이 테스트 세트 성능보다 훨씬 높을 때 일어난다. 데이텅네 내재된 거시적인 패턴을 감지하지 못한다
과소적합 : 훈련 세트와 테스트 세트 성능이 모두 동일하게 낮거나 테스트 세트 성능이 오히려 높을 때 일어난다. 이 경우에는 보통 더 복잡한 모델을 사용해 훈련 세트에 맞는 모델을 만들어야 한다.
연습 문제 실행 결과
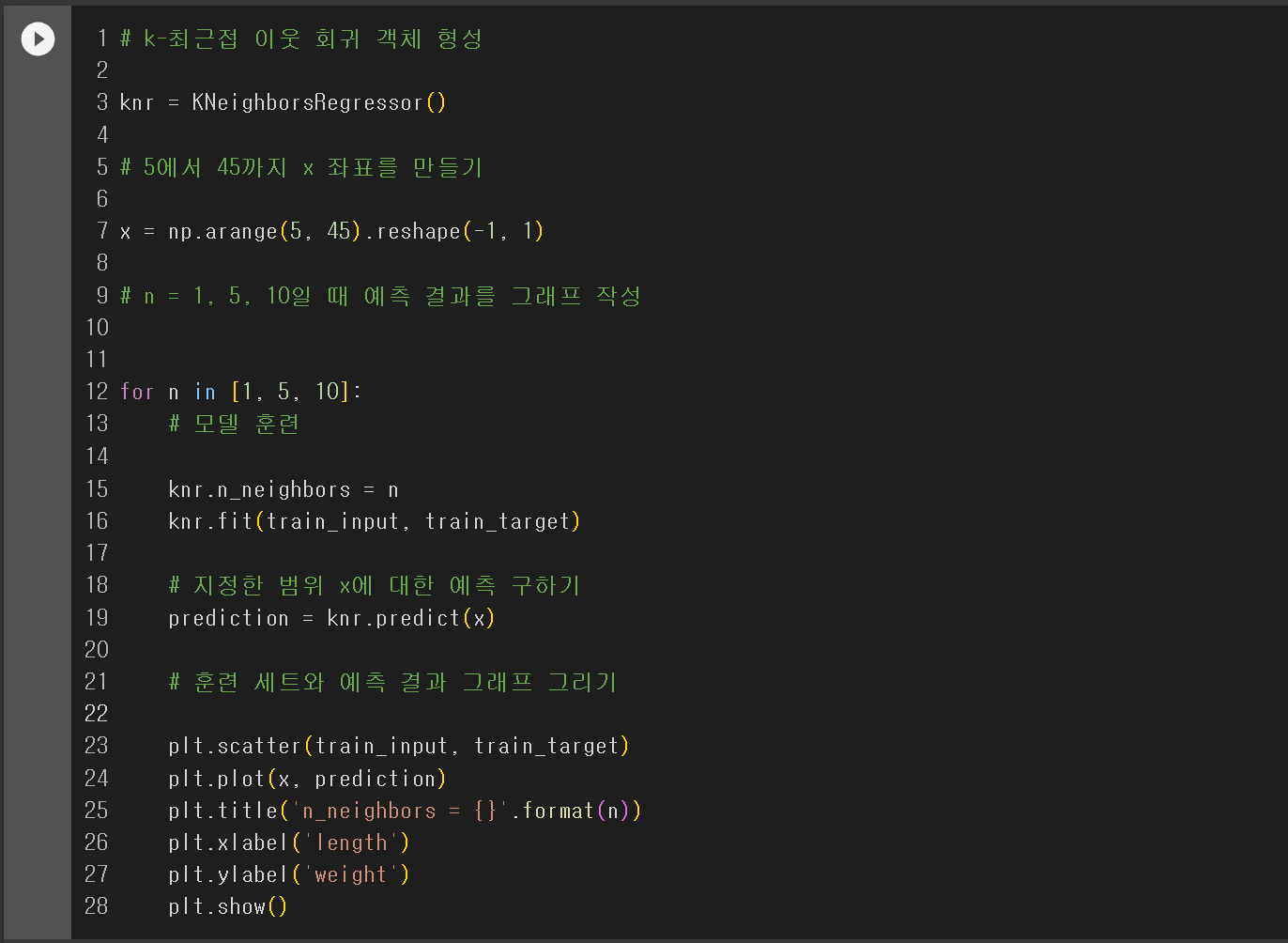
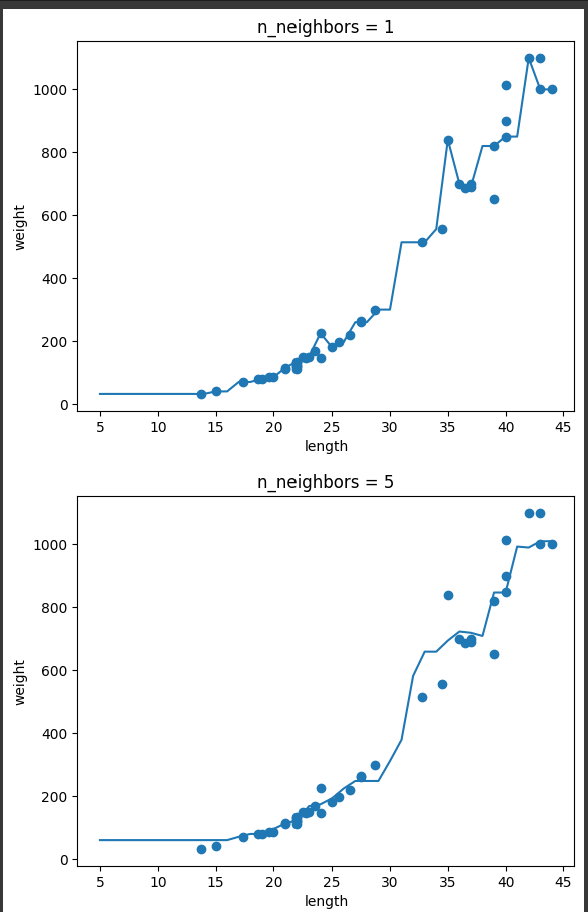
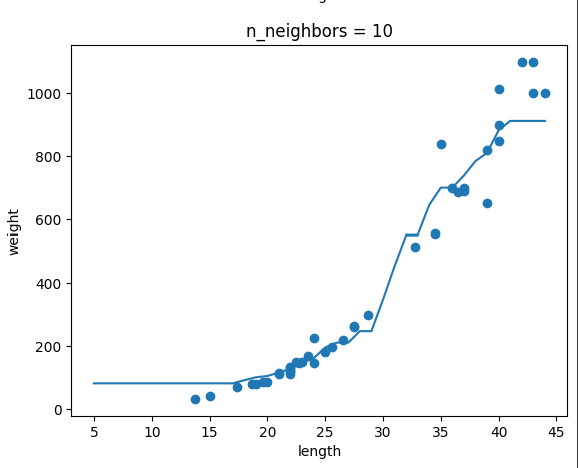

컴공 복전생의 하루 한 개 글 작성하기

잘봤습니다.