
락이란 무엇인가
임계 영역을 마치 하나의 원자적 명령어인 것처럼 실행하게 한다.
쓰레드 사이의 상호 배제를 구현하기 위해 사용한다.- 락 객체는 락의 상태를 저장한다.
사용 가능(available), 해제(unlocked 또는 free) : 락을 획득한 쓰레드가 없다.
사용 중(acquired), 잠김(locked), 소유 중 : 어느 한 쓰레드가 락을 가지고 있고, 임계 영역을 실행 중이다.
락의 구현
- lock()의 의미 == mutex::lock()
락의 획득을 시도한다.
아무도 락을 갖고 있지 않으면, 락을 획득한다.
임계 영역에 진입한다.
-> 이 쓰레드가 락을 소유했다라고 한다. - 다른 쓰레드들은 이 쓰레드가 락을 갖고 있을 동안 임계 영역의 진입에 막혀 멈춰있게 된다.
락의 구현
- 효율적인 락은 Low Cost로 구현해야 한다.
- 이러한 락의 구현은 하드웨어나 OS의 도움이 필요하다
적은 개수의 명령어로 구현한다. => HW
Lock을 얻지 못했을 때 쓰레드를 대기 상태로 => OS
락의 평가
- 상호 배제
기본 사항으로 여러 개의 쓰레드가 임계 영역에 동시 진입하는 것을 막는다. - 공정성
락 획득의 기회가 공평하게 주어지는가? (기아 문제) - 성능
락 자체의 구현에 오버헤드가 적어야 한다.
구현 : 인터럽트 제어

-
싱글 CPU, 싱글 코어에서만 가능한 락의 구현 방법이다.
-
인터럽트를 금지 시킨다.
-
문제점
1- 응용 프로그램에게 너무 큰 권한을 주고 악용의 여지가 있으며 버그로 인한 오동작의 여파가 크다.
2- 멀티 CPU, 멀티 코어에서 동작하지 않는다.
3- 인터럽트의 중지는 I/O 오동작의 위험이 있다.
4- 현재 CPU에서 인터럽트 컨트롤은 느리게 실행된다.
하드웨어의 도움이 필요
첫 시도: flag를 사용해서 락의 획득 여부를 판단하자

- 문제점

1- 상호 배제 실패
2- 회전 대기(Spin-waiting) CPU시간을 소모해서 다른 쓰레드의 실행이 늦어진다.
다른 시도: SW적 시도
피터슨 알고리즘
- 2개의 쓰레드에서만 동작한다. (id가 0과 1)

#include <iostream>
#include <thread>
using namespace std;
int cnt;
bool flag[2] = { false, false };
int turn = 0;
void func0() {
for (int i = 0; i < 10000; i++) {
flag[0] = true;
turn = 1;
while (flag[1] == true && turn == 1) {}
cnt++;
printf("cnt1 :: %d\n", cnt);
flag[0] = false;
}
}
void func1() {
for (int i = 0; i < 10000; i++) {
flag[1] = true;
turn = 0;
while (flag[0] == true && turn == 0) {}
cnt++;
printf("cnt2 :: %d\n", cnt);
flag[1] = false;
}
}
int main() {
thread t1(func0);
thread t2(func1);
t1.join();
t2.join();
cout << "cnt : :" << cnt << endl;
return 0;
}
[링크텍스트](https://www.crocus.co.kr/1371)- 피터슨 알고리즘은 두개의 변수 flag와 victim or turn을 두고 양보하는 방식의 알고리즘이다.
빵집 알고리즘
- n개의 쓰레드에서만 동작 (id가 0과 1)

- 빵집 알고리즘은 빵집을 비유로 고객들에게 번호표를 부여하여 번호표를 기준으로 먼저 처리해야할 일들의 우선순위를 부여
- 모든 고객은 맨처음 번호표를 부여 받고 자기 순서가 올때까지 대기한다. 이를 통해 다수가 공유자원에 접근을 불허한다.
하드웨어의 도움이 필요한 이유
- SW 문제점
1- 오버헤드가 크다.
2- 제한된 프로세스의 개수
3- 너무 복잡한 연산으로 인한 delay
4- 현대 CPU에서는 제대로 작동하지 않으며 추가적인 CPU 제어가 필요하다
-> test-and-set 명령어 == atomic exchange(원자적 교환) 등의 추가적인 하드웨어 도움이 필요하다
Test-and-set(Atomic Exchange)
- 원자적 교체
- 락을 간단하게 구현하기 위한 명령어

- 1- ptr가 가리키는 이전 값을 리턴한다(TEST).
2- 동시에 그 값을 new로 바꾼다(SET).
3- 이동작은 원자적으로 수행된다
4- SW만으로는 구현할 수 없다.
5- CPU가 메모리 버스를 잠가서 다른 CPU나 코어의 메모리 관련 명령어의 실행을 원천 봉쇄한다.
Test-and-set을 사용한 스핀 락

- 스핀 락 평가
1- 정확성: 그렇다.
오직 한 쓰레드 만이 임계영역에 진입할 수 있다.
2- 공정성: 아니다.
스핀 락은 어떠한 공정성도 제공하지 않는다.
사실상 영원히 스핀하는 쓰레드가 생길 수 있다.
3- 성능: 끔찍
단일 CPU에서의 성능은 끔찍할 수 있다. Context Switch가 발생할 때까지 계속 스핀한다.
쓰레드의 개수가 CPU의 개수보다 작거나 같을 경우 스핀락의 성능은 적절하다.
Compare-and-swap
-
주소(ptr)에 있는 값이 기대 값(expected)과 같은지 본다.
같다면, 주소(ptr)의 값을 새 값(new)으로 수정한다.
주소(ptr)의 원래 메모리 값을 리턴한다.
Compare-and-swap C+11 구현

- atomic_bool: bool 클래스인데 원자적이다.
읽고 쓰는 것이 원자적으로 수행되는 변수 - atomic_compare_exchange_strong
성공하면 true, 실패하면 false를 리턴한다.
expected에 addr에 있던 원래 값을 넣어서 리턴한다.
Load-Linked와 Store-Conditional

- Load-Linked로 주소의 값을 읽었을 경우 Store-Conditional은 아무도 그 주소에 쓰지 않았을 경우에만 저장한다
성공: ptr주소의 값을 value로 수정하고 1을 리턴한다.
실패: ptr주소의 값은 수정되지 않고 0을 리턴한다.
장점: Compare&Swap보다 강력하다
단점: 코드가 복잡하고 성능이 떨어지며 성공해야 하는데 실패할 수 있다.
성공해야 하는데 실패하는 경우도 있어서 ace에 strong, weak가 존재한다.
Fetch-and-add
- 원래 값을 리턴하면서 값을 증가시키는 동작을 원자적으로 수행한다.

Fetch-and-add C+11 구현

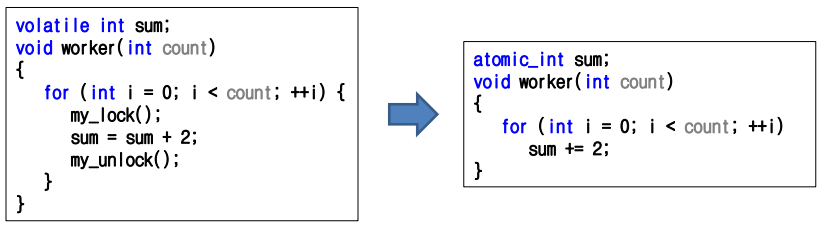
C++ 11의 Atomic 자료구조
- 기본 자료 구조의 일부를 원자적으로 구현
char, int, short, bool - #include <"atomic">으로 사용
- 읽기, 쓰기, +=, -=, ++, -- 연산을 원자적으로 수행한다.
매우 간단,,,
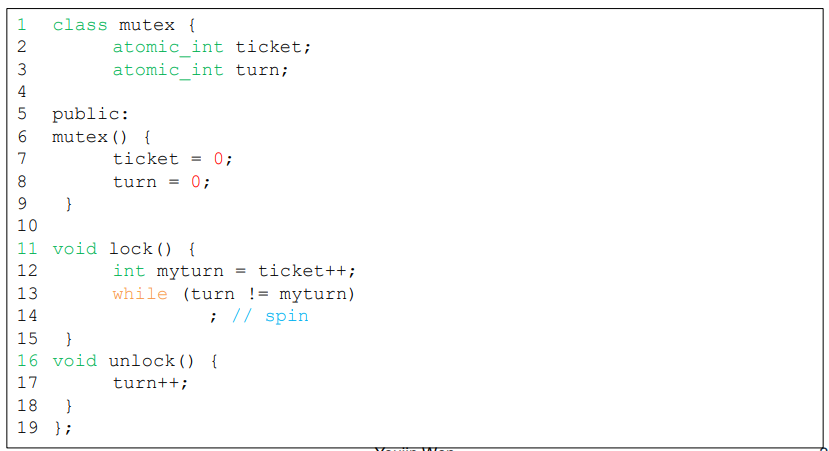
Ticket lock
- 티켓 락은 fetch-and-add로 구현할 수 있다.
- 락을 신청한 순서대로 락을 얻는다 : 공정성
과도한 스핀
- HW 기반의 스핀 락은 간단하고 확실히 동작한다.
- 하지만 많은 경우, 이러한 방법은 비효율적이다.
락을 가진 쓰레드가 준비상태가 되면, 기다리는 쓰레드들은 전체 타임 슬라이스를 락의 상태를 검사하는데 낭비
호위 현상이라고도 한다. 락을 가진 쓰레드가 스케줄링이 되지 않았을 때 다른 쓰레드들이 계속 기다리는 현상
간단한 해결: 양보
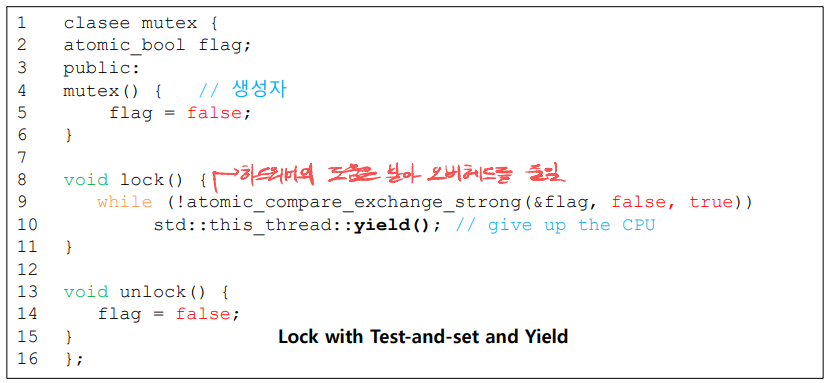
간단한 해결 : 양보 -> 스핀하게 되면, CPU를 다른 쓰레드에 양보한다.
- OS호출을 통해 실행 상태에서 준비 상태로 변환한다.
- 문맥 교환 비용이 상당하며, 기아 문제가 계속 존재한다.
큐의 사용 : 스핀대신 잠자기
- Yield()의 아쉬움
양보를 했는데 양보한 코어를 실행할 쓰레드가 없으면 다시 Yield()
Unlock이 되지 않았음에도, 깨어나서 다시 yield()를 실행할 경우가 많음 - 해결 방법
프로그래밍으로 해결
OS의 도움이 필요
yield()대신 대기상태로 하는 park()
대기상태의 쓰레드를 깨우는 unpark() - 대기 상태의 쓰레드가 여러개면?
park()할 때 큐에 thread_id를 넣자
unpark()를 unpark(thread_id)로 하자


- Park / Unpark 문제
무한대기: 쓰레드B가 park()를 호출하기 바로 전 쓰레드A가 락을 반납하면 쓰레드 B는 영원히 대기상태
-> setpark()를 사용해 해결
호출하는 쓰레드는 곧 park할 것임을 미리 알려준다.
공교롭게도 인터럽트가 발생하여 다른 쓰레드가 그 사이에 unpark를 호출했다면, park호출은 쓰레드를 대기시키지 않고 즉시 복귀한다.
Futex
리눅스는 futex를 제공한다.
- futex_wait
호출하는 쓰레드를 대기상태로 전환한다.
만약 address에 저장되어 있는 값이 기대값과 다르다면 즉시 리턴한다. - futex_wake
큐에서 대기하고 있는 쓰레드 중 하나를 깨운다.
그러나 역시 C+11 표준이 아니다.
C++11 해결 방식
대기와 재시작을 포함한 효율적인 mutex구현은 사용자에게 맡기면 안되고 mutex가 기본적으로 가져야할 특성
2단계 락
락이 금방 해제된다면 스피닝이 더 좋다는 현실을 구현한 것이 2단계 락
- 첫 단계
락을 금방 얻을 수 있을 때를 위해 잠시 동안 스핀한다.
스핀으로 락을 얻지 못할 경우 두번째 단계로 이행한다. - 두번째 단계
호출하는 쓰레드를 대기상태로 변환한다.
락이 해제되었을 경우 대기상태에서 깨운다.
락 기반 병행 자료 구조
자료 구조에 락을 추가하면 쓰레드 안전 자료구조가 된다
락을 어떻게 추가했느냐에 따라 그 자료구조의 정확성과 성능이 결정된다.
락이 없는 병행 카운터

간단하지만 멀티 쓰레드에서 사용이 불가능하다.
락을 사용한 병행 카운터

락을 획득한 이후에만 내부 자료구조를 변경한다.

락의 문제점: 성능
하나의 카운터를 여러개의 쓰레드에서 증가 시킨다.
- 쓰레드마다 백만번씩
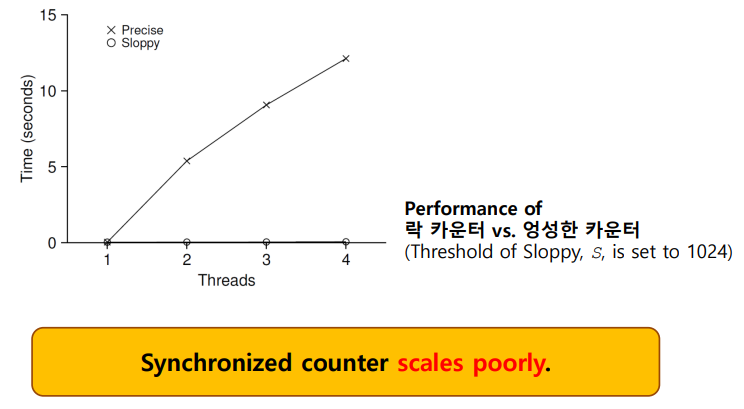
- 락을 사용하지 않았을 경우 성능
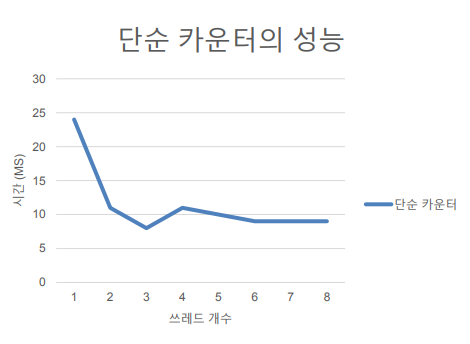
- 락을 사용하였을 경우 성능
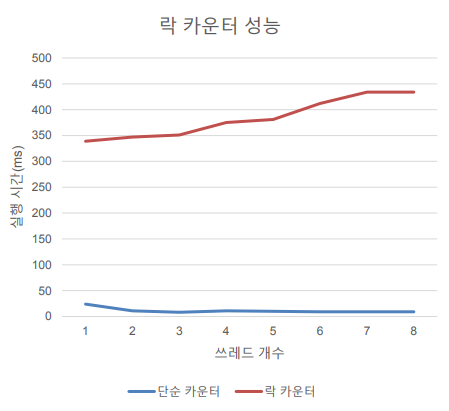
정확한 결과값이 나오기는 하지만 시간이 훨씬 걸린다.
락 카운터
- 모니터와 유사한 구현
모니터는 모든 메소드들이 실행을 자동적으로 상호배제 하는 자료구조이다. 올바른 결과 그러나 성능이 떨어짐 - 단점: 성능이 너무 떨어진다.
-더 느려진다.
-적어도 느려지면 안되고 쓰레드와 CPU 개수가 늘어날수록 성능이 향상되어야 한다.
엉성한 카운터
- 락 카운터의 성능을 개선
-전역 변수의 사용 회수를 줄이자
-대신 쓰레드 지역변수를 사용하자 - 쓰레드 지역 변수(TLS)
-같은 전역 변수인데 쓰레드 마다 다른 장소에 접근하는 변수
-초간단 구현 -> 배열로 구현하고 쓰레드마다 자신의 ID로 인덱싱 한다.
-C+11의 구현 thread_local 확장자 사용
쓰레드당 하나의 지역 카운터가 존재한다.
하나의 전역 카운터가 존재한다.
여러 개의 락: 지역 카운터당 한 개, 전역 카운터를 위한 한 개
ex) 4개의 CPU를 갖는 컴퓨터 -> 같은 개수의 쓰레드 실행, 4개의 지역 카운터, 1개의 전역 카운터
엉성한 카운터의 구현
- 각 쓰레드는지역 카운터를 하나씩 갖는다.
- 각 CPU는 자신의 지역 카운터를 갖는다.
쓰레드의 개수와 CPU의 개수가 같아서 각 CPU가 한 개씩의 쓰레드를 실행하므로
자신의 지역 카운터의 수정은 아무런 충돌이 없다.
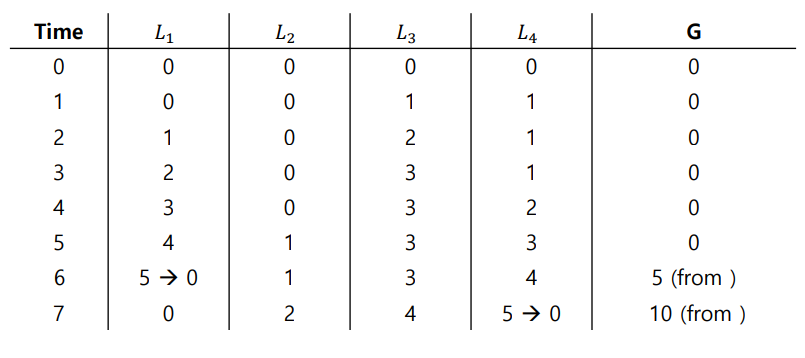
따라서 카운터 수정은 확장성이 있다. - 지역 카운터 값은 주기적으로 전역 카운터에 더해진다.
전역 락을 얻는다.
지역 카운터의 값만큼 증가시킨다.
이때 지역 카운터의 값은 다시 0으로 초기화 한다. - 얼마나 자주 지역에서 전역으로의 전송이 필요한 가는 한계치 s(엉성수치)로 결정
-s가 작아질수록: 일반 락 카운터와 비슷해진다.
-s가 커질수록: 확장성이 커지며 전역 카운터 값과 실제 값과의 차이가 커진다.
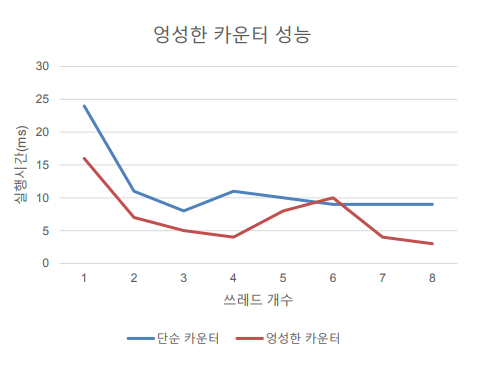
왜 성능이 더 좋을까
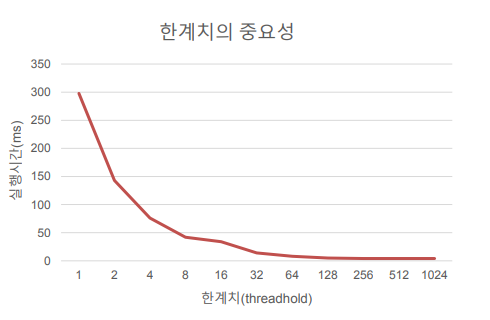
한계치의 중요성
4개의 쓰레드가 각각 카운터를 백만번 증가 시킨다.
-작은 s -> 낮은 성능, 전역 카운터는 비교적 정확
-높은 s -> 훌륭한 성능, 뒤처진 전역 카운터
병렬 연결 리스트
-
포인터로 연결된 리스트
-
삽입 연산만 구현
-
new를 사용한 메모리 할당 시 오류 처리
-> 락의 해제를 빼놓지 않도록 신경 써야 한다. -
삽입 함수 시작 시 락을 획득한다.
-
복귀 하기 바로 전에 그 락을 반납한다.
new가 실패할 경우 삽입 함수에서 복귀하기 전 락을 반납해야 한다.
임계 영역의 크기가 필요 이상으로 커서 병행성이 떨어진다.
이러한 예외 처리는 오류를 포함하기 쉽다.
-> 해결책: 락의 획득과 반납은 실제 임계영역만을 둘러싸야 한다.


병행 연결 리스트를 재작성한다.
연결 리스트의 병행성 개선
- Hand-over-hand locking(lock coupling)
전체 리스트를 하나의 락으로 관리하지 않고, 노드마다 락을 갖는다.
리스트를 순회할 때, 다음 노드의 락을 획득하고 현재 노드의 락을 반납한다.
-> 높은 병행성으로 리스트를 관리할 수 있지만 실제로는 락 획득과 반납 오버헤드 때문에 기본 성능이 매우 낮다.
Michael과 Scott의 병행 큐
- 두 개의 락이 있다.
하나는 head용, 하나는 tail용
이 두개의 락으로 enqueue와 dequeue의 병렬성을 얻는다. - 더미 노드의 추가(또는 보초 노드)
큐가 초기화 될 때 할당
head와 tail연산을 서로 분리한다.


병행 해쉬 테이블
- 간단한 해쉬 테이블
크기 고정(size가 변경되지 않음)
병행 연결 리스트로 구현
해시 버켓마다 락이 있다. -> 전역 락이 없다.
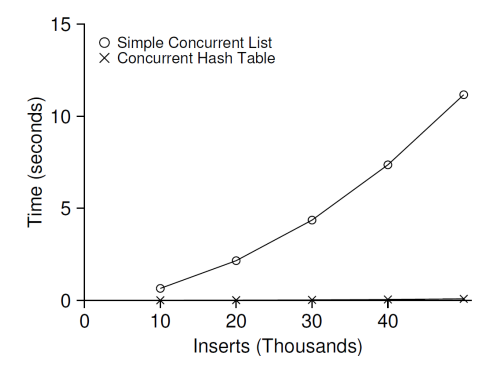
병행 해시 테이블의 성능
병행 자료 구조
- 락 획득과 해제 시 코드의 흐름에 주의를 기울여야 한다.
-> unique_lock과 lock_guard를 사용해야 하는 이유 - 임계 영역의 크기를 최소화해야 한다.
-> unique_lock과 lock_guard사용 시 주의 - 병행성 개선이 반드시 성능 개선으로 이어지지 않는다.
-> 추가 오버헤드에 주의 - 미숙한 최적화 주의
-> 전체 성능에 미치는 영향을 계속 살펴봐야 한다. - 논 블럭킹 자료 구조
-> 성능을 위한 최선의 선택
