
📌세그멘테이션이란
베이스와 바운드 방식에는 몇가지 비효율성이 있다.
- 너무 큰 빈 영역
- 빈 공간이 물리 메모리를 차지한다.
- 맞는 주소 공간이 물리 메모리에 없다면 실행이 어렵다 (너무 크거나 쪼개져 있거나)
이러한 문제를 해결하기 위해 나온 아이디어가 있다.
바로 세그멘테이션이다.
- 세그먼트 : 일정한 크기의 연속된 메모리 공간
일반적인 주소 공간은 3개의 세그먼트(Code, Stack, Heap)으로 구성된다.
논리적으로 하나의 프로세스를 여러 개의 세그먼트로 나눌 수 있다. - 각 세그먼트는 물리메모리의 여러 곳에 산재할 수 있고 세그먼트 별로 베이스와 바운드가 존재한다.
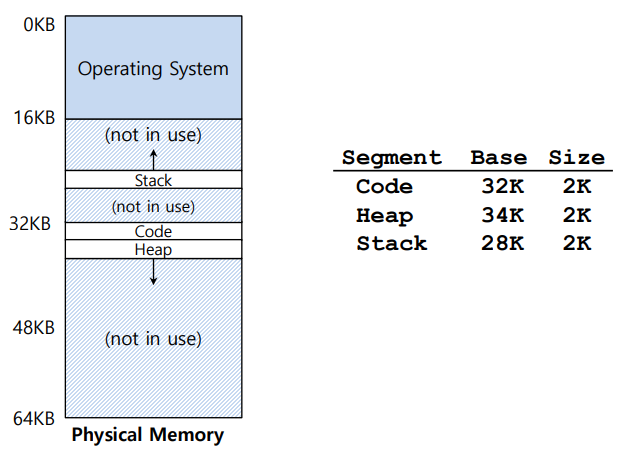
위 그림처럼 프로세스를 세그먼트를 사용하여 메모리에 배치한 경우, heap과 stack사이의 공간 낭비가 없는 것을 볼 수 있다.
따라서 이렇게 세그먼트를 사용하여 메모리에 프로세서를 배치하려먼 위 사진과 같은 레지스터 쌍들이 필요하다.
- 코드 세그먼트의 경우 32KB에 배치가 되며 크기는 2K이다.
- 힙 세그먼트는 34KB에 배치가 되며 크기는 2K이다.
- 스택 세그먼트는 28KB에 배치되며 크기는 2K이다.
📌세그먼트의 주소변환
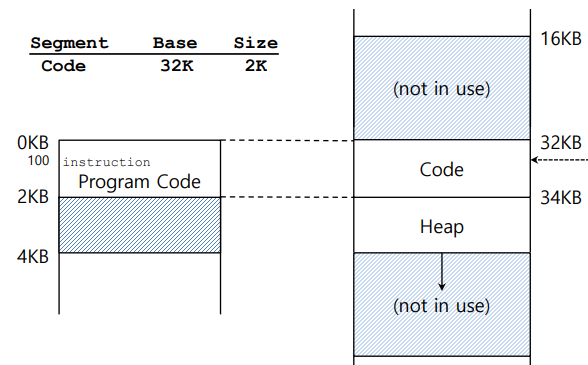
가상 주소를 실제 물리주소로 변환하는 방법이다.
offset이라는 개념이 존재하며 현재 코드 세그먼트의 가상 주소는 0부터 2KB이고 접근하려는 메모리의 offset은 100이다.
따라서 코드의 Base 부분과 offset부분을 합치면 물리주소를 얻을 수 있다.
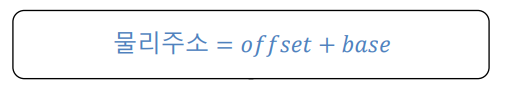
그러나 여기서 주의할 점이 있다.
Base + 가상주소가 물리주소가 아니라는 것이다.
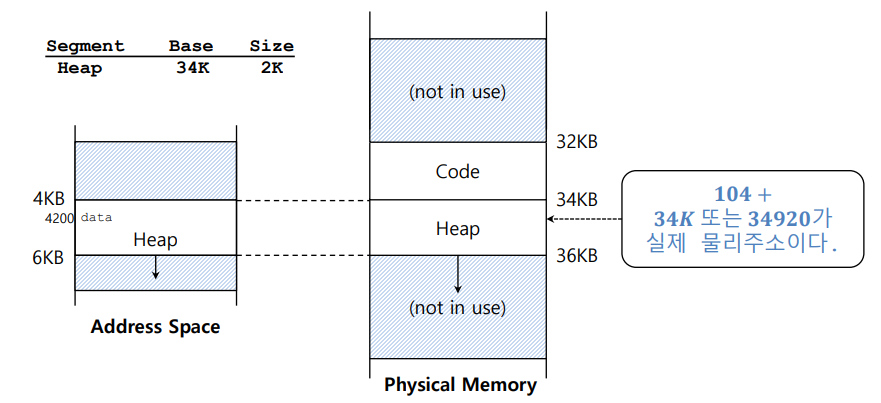
이 그림에서 힙 세그먼트의 가상 주소 시작은 4096이다.
따라서 접근하려는 데이터는 가상 주소 4200에 위치하며 offset은 104이다.
그러므로 Base + offset을 통해 34K + 104 = 34920이 실제 물리 주소라는 것을 알 수 있다.
유의하자.
세그먼트 주소
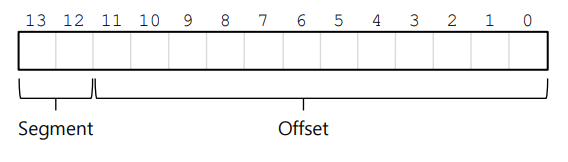
- 명시적 접근 : 주소공간의 상위 몇 비트를 세그먼트 지정에 사용한다.

예를 들어 가상 주소 4200이 있다고 하였을 때 (01000001101000)2 이진수를 갖는다.
따라서 맨 앞의 01은 Heap을 의미하므로 우리는 이 세그먼트가 힙 세그먼트이구나를 명시적으로 알 수 있다.
이러한 가상 주소를 보고 어느 세그먼트에 있는가는 HW가 판단하는 것이다.
그러나 단점으로는 최대 크기가 고정이라는 것이다. 쉽게 말해 Heap, Code 등 각각만 많이 쓰는 프로그램은 제한적이라는 것이다.

다음은 세그먼트의 하드웨어 구현이다.
맨 처음 상위 2비트를 통해 어느 세그먼트인지 구분할 수 있다.
그 다음 하위 2비트를 통해 offset을 얻는다.
offset이 bound를 넘게 되면 오류가 나는 것이다.
넘지 않으면 무리주소에서 데이터를 얻을 수 있다.
스택 세그먼트 변환
스택은 힙과 코드와는 다르게 거꾸로 확장된다.
따라서 추가적인 하드웨어 지원이 필요하고 세그먼트 확장 방향을 결정할 수 있어야 한다.

그래서 세그먼트 레지스터는 Grows Positive라는 정보를 통해 세그먼트의 주소가 늘어나면 1, 줄어들면 0으로 방향을 결정해준다.
📌세그먼트 오류(Fault, Violation)
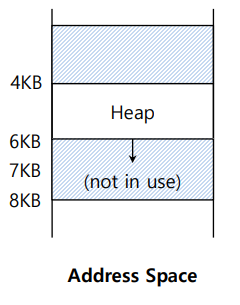
만약 위 그림처럼 Heap영역이 아닌 7KB의 잘못된 주소에 접근하게 되면 세그먼트 폴트 또는 세그먼트 위반 처리를 해야 한다.
HW가 메모리 접근을 검사하여 오류가 났다면 인터럽트를 발생시킬 수 있어야 한다.
📌공유 지원
세그먼트의 매우 효율적인 장점이 있다.
같은 물리 메모리를 여러 세그먼트에서 공유할 수 있다는 것이다.
코드 공유 형식으로 많이 사용하며 보호를 위해서 추가적인 하드웨어 지원이 필요하다.
따라서 Protection bits라는 추가 하드웨어가 등장하는데

위 그림을 보면 세그먼트당 몇 개의 추가 bit로 Read, Write, Execute 권한을 표시할 수 있다.
또한 특정 세그먼트에서 오류나 버그들을 OS가 처리해줘야 한다.
📌대단위 vs 소단위 세그멘테이션
현재 까지 알아본 세그멘테이션은 3개만 존재하는 시스템이었다.
그렇다면 사이즈가 큰 소단위 세그먼트가 좋을까 아니면 사이즈가 작은 대단위 세그먼트가 좋을까
당연히 둘다 장단점이 존재한다.
- 대단위 세그먼트 장점 : 세그먼트의 수가 줄어 관리가 편하며 하드웨어가 간단해진다
- 소단위 세그먼트 장점 : 유연하게 메모리를 구성할 수 있지만 관리가 힘들다.
그러나 현재는 이 세그먼트를 잘 쓰지는 않는다.
📌OS지원 : 단편화(Fragmentation)
세그멘테이션은 OS에게 문제점을 야기한다.
- 외부 단편화 : 작은 크기의 빈 공간들이 많이 생기는 현상
힙 스택 사이 빈공간을 쓰지 않아 낭비가 있는 내부 단편화는 세그먼트로 해결했다.
그러나 프로세스들간의 빈 공간이 많이 생기며 크기가 작아 사용하기 어려운 외부 단편화가 발생한다.
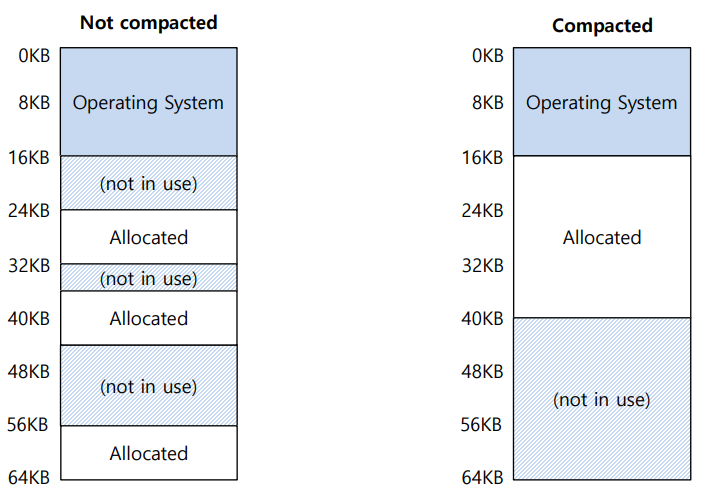
따라서 24KB의 빈 공간이 있지만 여기저기 흩어져 있다면 20KB의 요청을 OS가 들어줄 수 없게 될 것이다. - 압축 : 기존의 세그먼트들의 물리적 위치를 재조정 하는 것
압축에는 비용이 든다.
📌빈 공간 관리
앞서 나온 외부 단편화 문제를 최소화 할 수 있는 방법을 알아보자
단편화를 관리하기 위한 기법으로
- 저수준 기법
분할과 병합
개별 리스트 - 버디 시스템
먼저 분할을 알아보자
분할
메모리 할당은 기존의 빈 공간을 여러개로 쪼갤 수 있다.
빈 공간보다 필요한 메모리 크기가 작은 경우 가능
ex) 30바이트의 빈 공간이 10바이트 요청으로 인해 3개로 쪼개어지는 경우
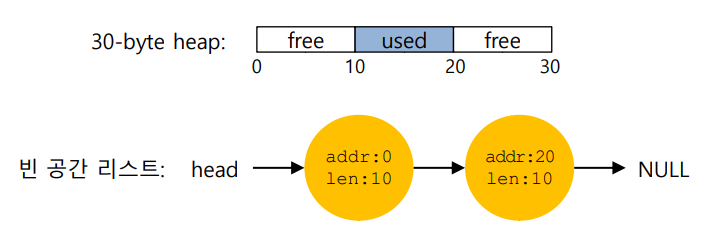
이 상황에서 1바이트의 요청이 들어온다면
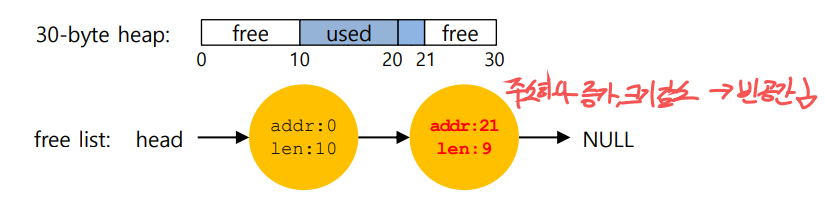
다음 그림과 같이 빈공간 리스트의 주소크기가 하나 증가하며 크기가 하나 감소하게 되고 결국 빈공간이 줄어들 것이다.
이것이 바로 메모리 분할이다.
병합
가장 큰 빈 공간보다 큰 크기의 요청이 있다면 들어줄 수 없다.
이런 경우 빈 공간이 이웃해 있는 경우에 하나로 합쳐 크기를 늘려준다.
이것이 바로 병합이다.
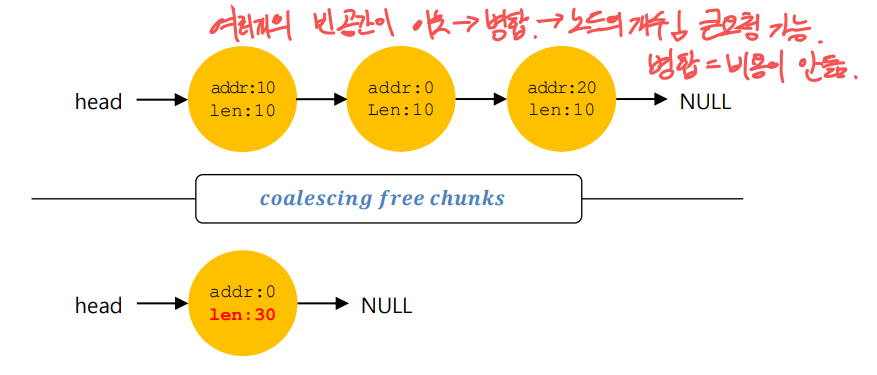
위 그림과 같이 여러 개의 빈공간이 존재하고 서로 이웃한 경우에는 병합하여 사이즈를 늘린다.
이 병합은 비용이 안들기 때문에 무조건적으로 좋다고 볼 수 있다.
📌할당 영역 크기 관리
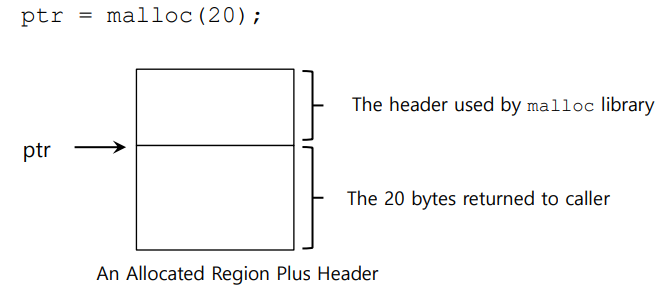
free는 c언어 사용자라면 모두 알다시피 크기를 매개변수로 받지 않는다.
ptr = malloc(20)여기서 20바이트만큼 할당을 받고 모두 사용시 해제를 해줘야 한다.
그런데 free에 매개 변수로 크기를 넣어주지 않았는데 어떻게 알아서 빈공간 리스트에 넣을 크기를 알 수 있을까?
실제로는 메모리를 할당 받을 때 20바이트 만큼이 아닌 더 큰 크기를 할당 받아서 가장 위에 존재하는 헤더 블록에 정보를 추가한다.
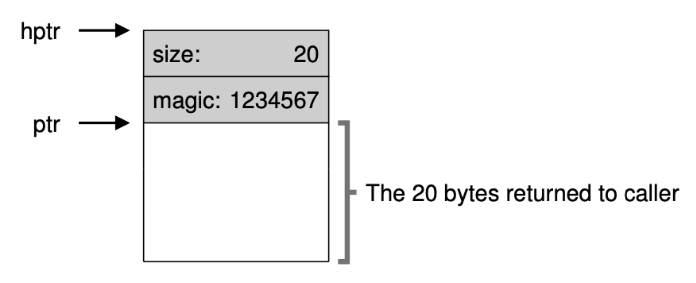
이와 같이 말이다. 헤더 부분에 사이즈 정보를 저장하는 공간과 매직 넘버라는 공간이 저장되어 있는것을 볼 수 있다.
매직 넘버란 간단히 할당받은 메모리임을 확인시켜주는 일종의 사인이라고 볼 수 있다.
만약 매직 넘버가 1234567이 아니라면 버그가 생김을 알려줄 수 있다.

이처럼 메모리 조각 헤더는 다음과 같은 구조체로 이뤄져 있다.

위 그림을 보면 free를 할 때 헤더의 사이즈 만큼 뺀 여유 공간의 정보를 알 수 있다.
📌빈 공간 리스트

빈 공간 리스트에서 빈 공간의 위치는 어떻게 알 수 있을까
이것은 운영체제가 별도로 해준다.
운영체제가 빈 공간을 관리해주고 빈공간끼리 링크드리스트로 연결이 된다.
전부 해제되었을 경우 외부 단편화가 발생하고 병합이 필요하다.
병합을 해야 큰 메모리 할당이 가능하다.
📌힙의 확장
대부분 메모리 관리자는 처음의 작은 크기의 힙을 할당해 시작하고 부족하면 OS에게 더 요청한다.
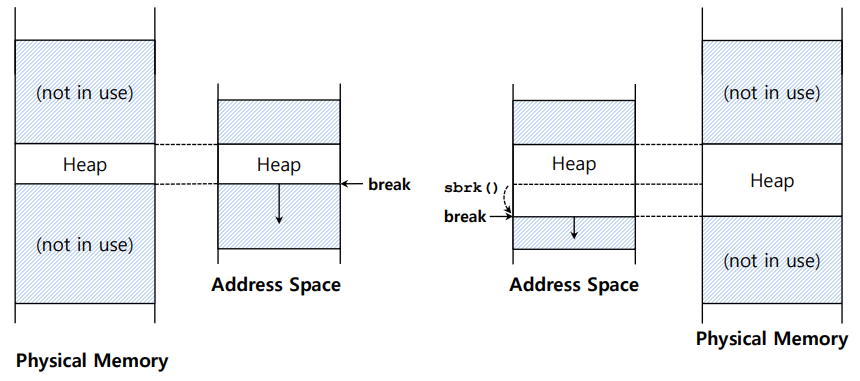
다음과 같이 sbrk -> set break를 통해 break를 재설정 하여 확장한다.
📌빈 공간 관리 : 기본 전략
많은 여유 공간이 있을 때 어디에 어떻게 할당을 해야할까
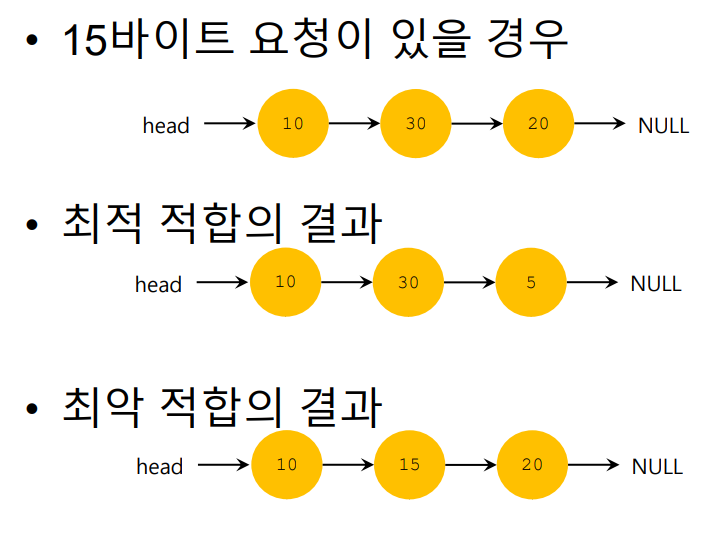
- 최적 접합(Best Fit) : 요청보다 작거나 같은 조각을 찾는다. 조각중 가장 작은 것을 반환한다.
- 최악 접합(Worst Fit) : 요청보다 크거나 같은 조각을 찾는다. 조각중 가장 큰 것을 반환한다.
- 최초 접합(First Fit) : 처음 만나는 요청에 할당한다.
- 다음 접합(Next Fit) : 처음 만나는 요청이 아닌 다음에 만나는 요청에 할당한다.
📌다른 접근법 : 개별 리스트
- 개별 리스트 : 많이 사용되는 크기별로 별도의 리스트를 만들어 관리
해당 크기의 조각의 재활용은 외부 단편화가 생기지 않는다.
해당 크기의 조각의 할당은 검색이 필요가 없다. - 문제 : 각 크기별로 얼마나 할당해야 할까? 크기를 미리 알 수 없다.
-> 슬랩 할당기를 사용해야 한다. - 슬랩 할당기 : 자주 요청되는 메모리 크기를 객체 캐시로 할당한다. 해당 크기만큼 요청이 발생하면 바로 메모리 할당이 가능하다.
빈 객체들을 사전에 초기화 된 상태로 유지한다.
캐시 관리 : 리스트가 비어가면 미리 한번에 여러개를 할당 받아 저장한다.
📌다른 접근법 : 버디 할당
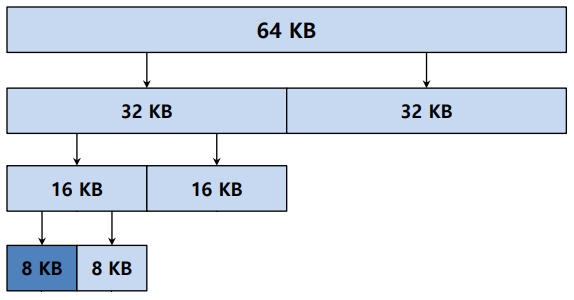
- 이진 버디 할당 : 메모리 요청이 있을 때, 맞는 사이즈의 조각이 나올 때까지 반으로 자르며 빈 공간을 관리한다. -> 더이상 자를 필요가 없을 때까지
만약 총 64KB의 메모리에 8KB의 요청이 들어왔다고 하였을 때 64KB를 32KB 16KB 8KB로 쪼개어 현재 Best Fit으로 요청을 할당한다.
그런 뒤 이 공간을 해제할 때는 다시 쪼개진 메모리, 즉 버디를 찾고 사용하고 있지 않다면 합병한다.
- 버디할당 장점 : 병합이 매우 쉽다
이웃 블록만 가능 - 버디할당 단점 : 7KB 할당시 1KB 낭비로 내부 단편화와 40KB할당 불가한 외부 단편화가 있음
다음으로 가변 크기 할당이 아닌 고정 크기 할당 방법인 페이지에 대해 알아보자
