
여러 개의 프로세스가 있는데 어느 프로세스를 실행해야 할까?
-> 스케줄러가 누구를 선택해야 할까?
- 목표
어차피 전부 종료하는 시간은 정해져 있지 않은가? -> 누구를 먼저 끝낼 것인가도 중요하다
공정해야 한다
가능하면 많은 프로세스가 일찍 종료해야 한다 -> 반환 시간(프로그램이 도착하고 끝날때 까지의 시간)의 합이 작아야 한다 - 작업
멈춤없이 실행되는 실행 구간
CPU만 사용한다
구간의 크기를 미리 알 수도 있고, 모를 수도 있다.
프로세스가 아니라 작업 단위로 스케줄 한다 - 스케줄링 평가 항목
성능 평가 기준 : 반환 시간(Turnaround time) = 완료시간 - 도착시간
작업이 완료된 시간에서 작업이 도착한 시간을 뺀 시간으로 전체 반환시간이 작을수록 좋다.
다른 평가 기준 : 공정성(fairness)
성능과 대립할 수 있다.
📌FIFO
First In First Out(선입 선출)
가장 먼저 들어온 놈이 가장 빨리 나간다.
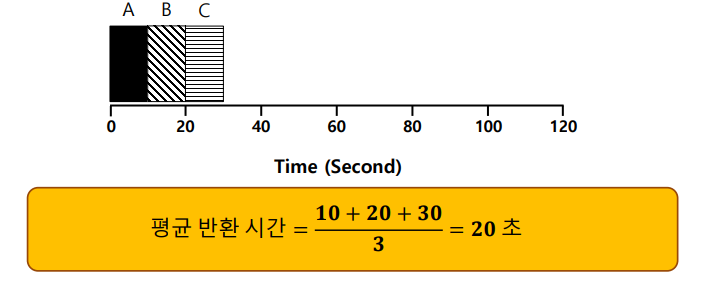
장점 : 매우 간단하고 구현하기 쉽다.
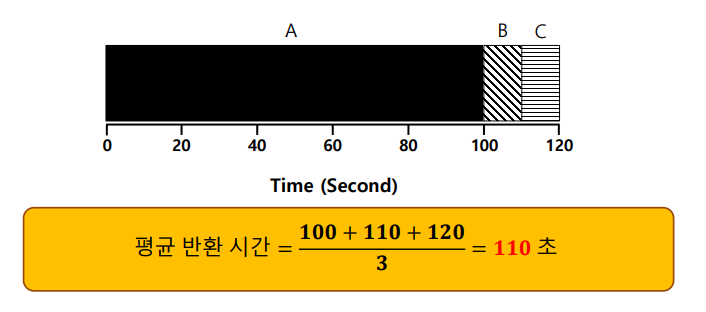
단점 : 호위 효과(Convoy effect)
작업마다 실행 시간이 다를 경우
다음 그림과 같이 A는 100초, B는 10초, C는 10초간 실행하였을 때, A가 매우 긴 시간동안 점유하고 있기 때문에 B와 C의 완료 시간도 늦어지고 따라서 반환 시간이 매우 커진다.
📌SJF
Shortest Job First
가장 짧은 작업 먼저, 다음으로 짧은 작업,,,
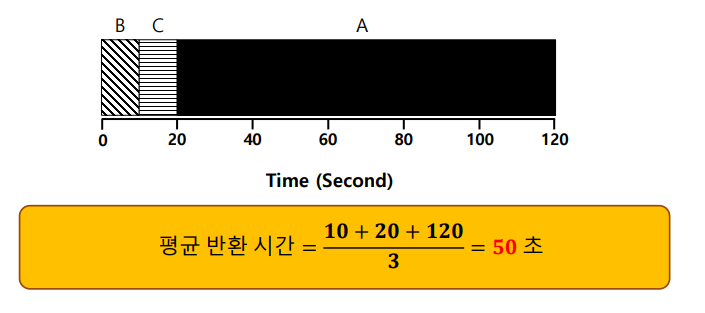
늦게 들어왔으면 그에 맞게 뒤에 줄을 서는 비선점 스케줄러이다.
평균 반환 시간을 줄이는 가장 좋은 방법이다.
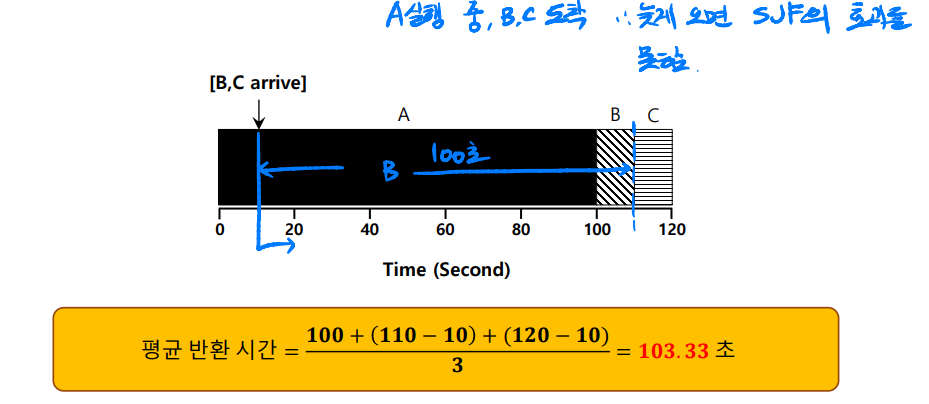
단점 : 위 그림과 같이 A 실행 중 B, C가 도착해서 10초간 실행해야 하지만 비선점이기 때문에 그대로 밀려난다. SJF의 효과를 못본다.
📌STCF
Shortest Time-to-Complition First
잔여 시간이 제일 작은 작업을 우선 실행 -> 실행 하는데 가장 빨리 완료할 작업을 우선으로 실행
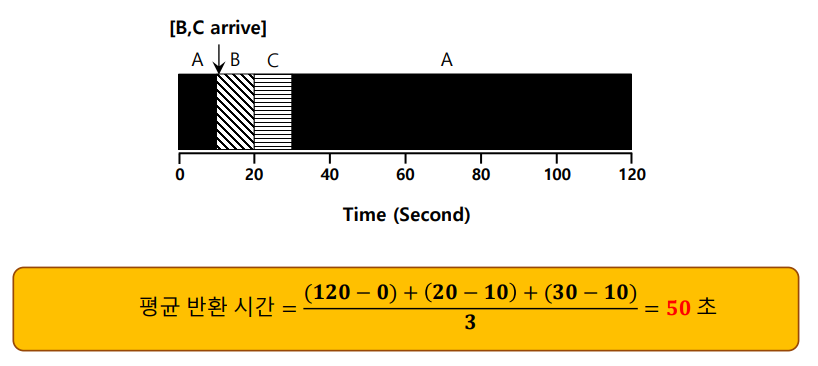
SJF에서 선점을 추가한 것이다.
따라서 강제 작업 전환이 필요하다.
새로운 작업이 시작되면 새 작업과 기존의 작업들의 잔여시간을 조사하고 잔여시간이 가장 작은 작업을 스케쥴한다.
단점 : 응답 시간이 좋지 않음
📌응답 시간
새로운 평가 기준인 응답 시간이 추가 되었다.
HWP나 PPT와 같이 대화형 프로그램은 실행시간이 없고 키보드를 눌렀을 때 얼마나 빨리 반응하는지가 중요하다.
작업이 도착한 시간부터 처음 스케줄 될 때까지의 시간이다.
응답시간 = 최초 실행 - 도착 시간
STCF관련 기법은 먼저 들어오더라도 잔여 작업시간이 적게 남은 프로세스를 먼저 스케줄링하기 때문에 응답시간이 좋지 않다.
📌RR
Round Robin
타임 슬라이스 스케줄링으로 작업을 실행하고 정해진 시간 주기인 타임 슬라이스에 따라 시간이 지나면 준비 큐에 있는 다음 작업으로 문맥이 교환된다. 위의 과정을 작업이 종료될 때 까지 반복하며 타임슬라이스의 크기는 타이머 인터럽트 간격의 정수배이다.
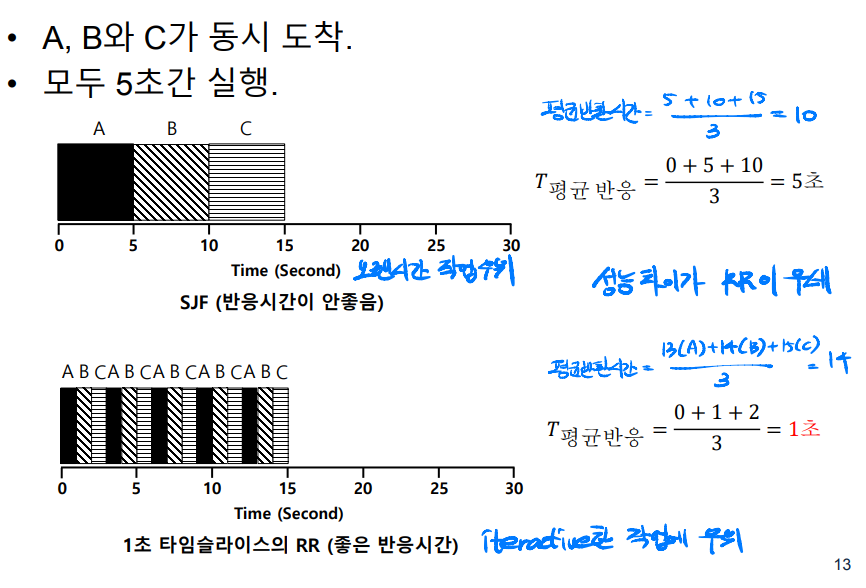
다음 그림과 같이 SJF는 반환시간은 좋지만 응답시간은 좋지 않다. 그러나 RR은 반환시간은 좋지 않지만 응답시간은 매우 좋다.
이렇게 인터렉티브한 작업에 우위를 둔다.
- 타임 슬라이스의 크기
타임슬라이스의 크기가 작을 수록 반응시간이 짧아진다. 잦은 문맥교환으로 문맥교환비용이 전체 성능을 좌우한다.
타임슬라이스가 길수록 교환 비용이 차지하는 비중이 줄어든다. 반응시간이 줄어든다.
📌I/O 연산 고려
모든 프로그램은 I/O를 수행한다.
다음과 같이 A와 B는 CPU를 둘 다 50ms 사용한다.
A는 10ms 실행할 때 마다 I/O요청을 한다 (모든 I/O는 10ms 동안 실행)
B는 I/O없이 50ms 계속 실행한다.
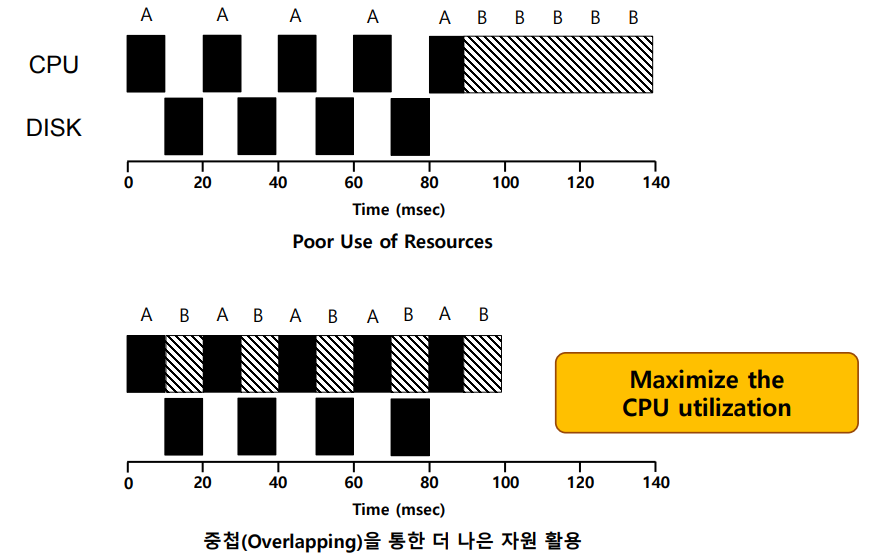
- 스케줄러가 A를 먼저 실행하고 A종료 후 B를 실행한다면?
-> 평균적으로 성능이 좋지 않다. - B를 먼저 실행했다면?
-> RR이 아닌 경우 작업 중첩이 일어나지 않는다. - 작업이 I/O를 요청하면?
-> I/O가 종료될 때 까지 작업은 대기상태가 된다.
-> 스케줄러는 다른 작업에게 CPU를 할당해야 한다 : 중첩 A와 B가 동시에 실행 - I/O가 종료되면?
-> 인터럽트로 운영체제가 실행 되면서 스케줄러가 동작
📌멀티레벨 피드백 큐(MLFQ)
- 목표
-> 반환 시간 최적화 -> Run Shortest Jobs First(누가 가장 작은지 모름) -> 작업의 길이를 몰라도 동작 가능하게 하자
-> 반응 시간 최소화 -> 작업의 성격에 따라서
-> 응답 시간이 많은 작업은 I/O등이 있으며 반응시간 최적화에 적합하다.
MLFQ는 여러 개의 서로 다른 큐(작업 리스트)를 갖는다. 각 큐는 서로 다른 우선순위를 갖는다.
- 실행 준비 상태의 작업은 큐에 위치한다.
-> 높은 우선 순위 큐에 있는 작업이 먼저 실행된다.
-> 같은 큐에 있는 작업들은 라운드 로빈으로 스케줄링 된다.
MLFQ 기본 규칙
MLFQ는 관찰된 행동에 따라 작업이 속할 우선순위 큐가 정해진다.
ex) 자주 IO요청을 해서 CPU를 놓아주는 작업 : 높은 우선순위, 긴 시간동안 CPU를 사용하는 작업 -> 낮은 우선순위
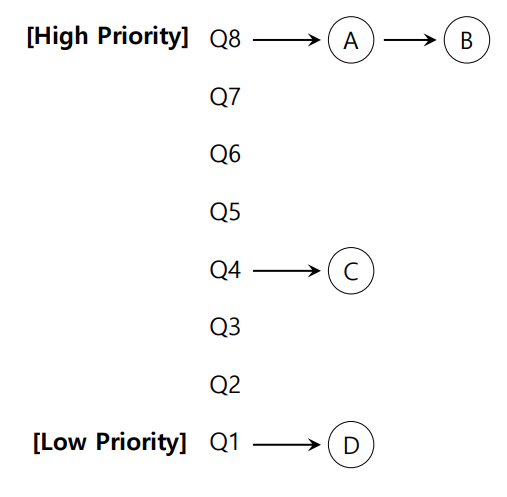
MLFQ 우선순위 변경
이 MLPQ에서 가장 높은 우선순위를 가진 A와 B가 아주 오래 걸리는 작업이라면 C와 D는 매우 성능이 안좋아진다.
따라서 상황에 따라 우선순위를 변경해줘야 한다.
- MLFQ 우선순위 변경 알고리즘
-> Rule 3: 작업이 처음 시작되면 가장 높은 우선 순위를 갖는다
-> Rule 4a: 작업이 타임 슬라이스를 전부 사용하면 우선 순위가 낮아진다.(낮은 우선순위 큐로 이동)
-> Rule 4b: 작업이 타임 슬라이스 사용 도중 CPU를 놓아 주면 우선 순위를 높인다.
긴 실행 시간 작업 예시
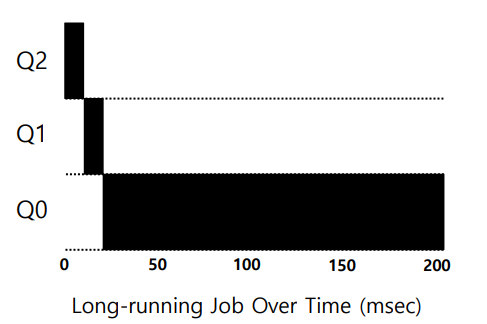
다음 그림과 같이 큐가 3개일 때, 하나의 작업이 수행되는 과정을 보여준다. 우선 타임 슬라이스가 10일때, 처음으로 Rule 3에 의해 우선순위가 가장 높은 Q2에 위치한다. 그리고 타임 슬라이스를 모두 사용하였기 때문에 다음 우선순위 Q1으로 이동한다. 10초 후 다시 Q0으로 이동하게 된다.
작은 실행 시간 작업 예시
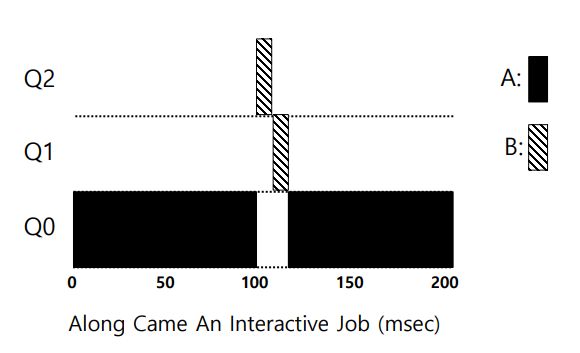
다음 그림과 같이 A는 CPU를 오래 사용하는 작업이고 B는 짧게 실행되는 작업이다.
A가 실행 중 B가 들어오게 되면 마치 STCF처럼 작동한다.
입출력 작업 예시
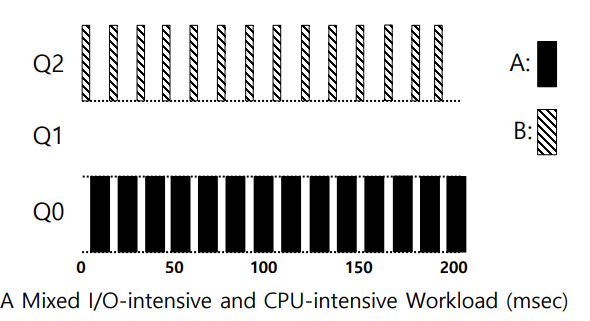
다음 그림과 같이 A는 CPU 중심의 작업이지만 B는 I/O 요청 전 1ms 정도만 실행되는 대화형 작업이기 때문에 Rule 4b처럼 우선순위가 제일 높고 반드시 A보다 먼저 수행할 수 있게 스케줄링 되었다.
MLFQ의 문제점
이처럼 MLFQ는 매우 빨리 수행할 수 있을 거 같아 좋아 보이지만 이러한 규칙을 교묘하게 피해갈 수 있다.
- 기아(Starvation)
"너무 많은" 대화형 작업이 있을 때 이 작업이 모두 수행되기 전까지는 다른 작업을 수행할 수 없을 것이다.
오랜 시간 실행 작업은 CPU를 사용하지 못할 것이다. - 교활한 사용자
99%의 타임 슬라이스만 사용하고 I/O를 요청
계속 대부분의 CPU시간을 사용할 수 있다. - 실행하면서 작업의 성격이 바뀔 수 있다.
CPU 위주의 작업에서 -> I/O 위주의 작업으로
우선 순위 상향 조정
이러한 문제점을 해결하기 위해 나온 것이 우선순위 상향 조정이다.
오래동안 실행되지 않은 작업의 우선순위를 올려주는 것이다.
-> 이를 알아내기 힘드니 그냥 모든 작업의 우선순위를 주기적으로 가장 높게 만들어 주는 것이다.
- Rule 5 : 일정한 주기 S마다, 모든 작업을 가장 위의 큐로 이동
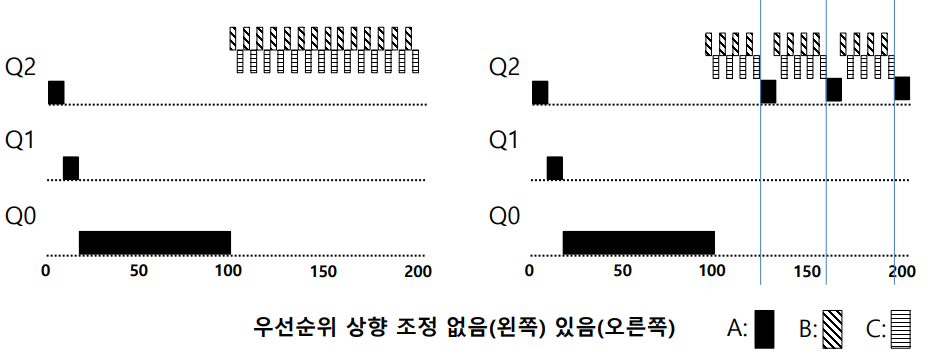
스케줄러 속이기 대처
아까 앞에서 봤듯이 타임 슬라이스의 99.9퍼센트만 사용하는 악질 사용자가 있다.
이러한 놈들을 솜방망이를 내리칠 수 있는 대처가 존재한다.
바로 Rule 4a와 Rule 4b를 통합하여 정의한 새로운 규칙 Rule 4이다.
- Rule 4 (Rewrite Rules 4a and 4b) : 작업은 모든 우선순위에서 주어진 타임 슬라이스를 모두 사용하면 우선순위가 감소한다.
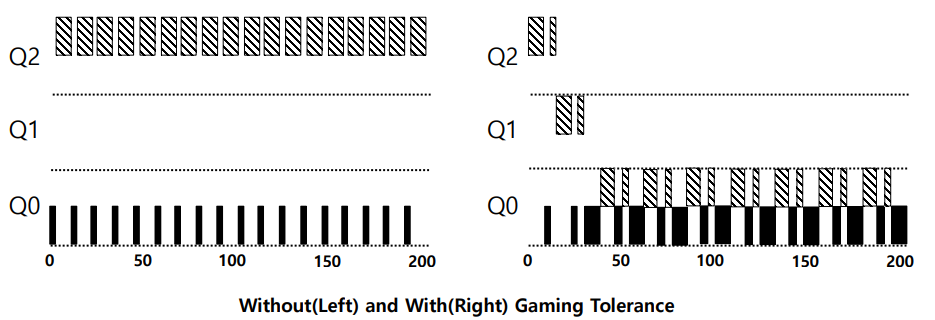
다음과 같이 왼쪽은 적용하지 않고, 오른쪽은 Rule 4를 적용한 것이다.
빗선이 그어진 B가 얌체같이 조금만 쓰고 포기하지만 일정한 타임 슬라이스가 누적되기 때문에 타임 슬라이스가 끝나고 다음 우선순위로 내려간다. 결국 마지막 Q0에 도착하여 A와 B는 같은 우선순위에서 RR을 하게 된다.
MLFQ 조정과 다른 쟁점들
모든 문제는 해결하였지만 최적화와 구현의 문제는 남아있다. 우선순위, 큐의 개수, 타임슬라이스 등을 어떻게 설정해야 하는지다.
실제 사용되는 MLFQ의 방식이다.
- 높은 우선순위 -> 작은 타임 슬라이스
- 낮은 우선순위 -> 긴 타임 슬라이스
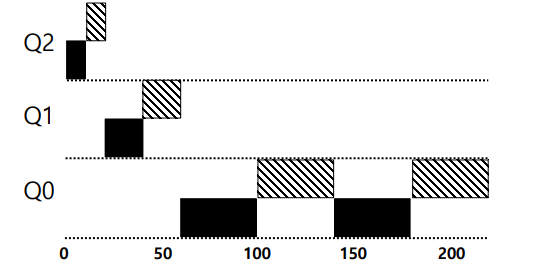
위와 같이 Q0, Q1, Q2가 서로 다른 타임슬라이스를 갖고 있다.
우선순위가 낮다는 것은 CPU를 주로 사용한다는 것이며 실행시간이 긴 작업들이 속한다.
따라서 타임 슬라이스가 큰 것이 더 작동이 잘 될 수 있다. -> context switch에서 비용 발생을 절약할 수 있다.
MLFQ 요약
- MLFQ 규칙 정리
Rule 1 : 우선순위(A) > 우선순위(B) : A 실행
Rule 2 : 우선순위(A) = 우선순위(B) : A, B를 RR로 실행
Rule 3 : 작업이 도착하면 가장 높은 우선순위에서 시작
Rule 4 : 작업이 지정된 단계에서 배정받은 시간을 소진하면 우선순위 감소
Rule 5 : 일정 주기 S마다 모든 작업을 가장 높은 우선 순위 큐로 이동
실제 운영체제들도 비슷한 스케줄링 알고리즘으로 동작한다.
