해당 내용은 Standford CS224N Spring 2024를 바탕으로 합니다.
📽️ 강의 영상
📝 강의 자료(Slides)
Regularization
Regularization(정규화)는 많은 피처가 있을 때 Overfitting(과적합)이 발생하는 것을 방지한다.
Overfitting(과적합)이란?
훈련 데이터를 잘 설명하는 모델이 새로운 데이터(테스트 데이터)에 대해서는 제대로 일반화하지 못하는 것이다.
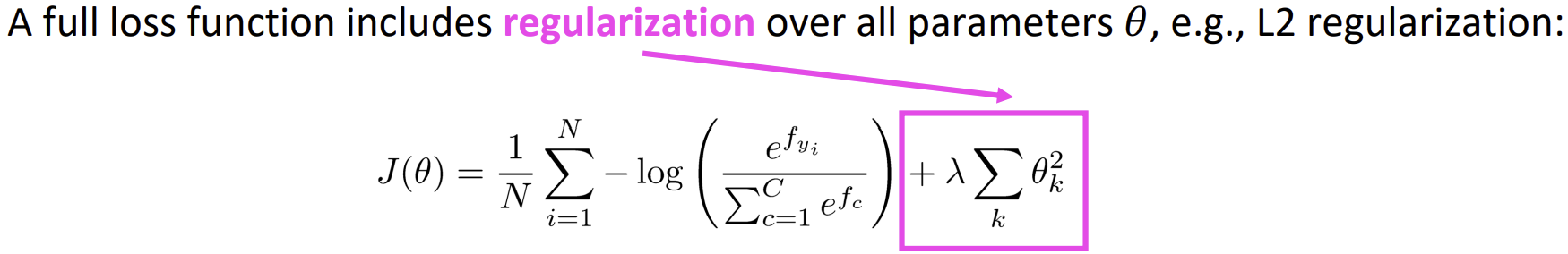 L2 regularization이란?
L2 regularization이란?
모델의 가중치(weight) 값이 지나치게 커지는 것을 방지하여 과적합(overfitting)을 줄이는 정규화 기법이다.
손실 함수(loss function)에 가중치의 제곱합을 추가하여, 가중치의 크기가 크면 손실이 커지므로 가중치가 작아지도록 유도하는 효과가 있다.
오늘날의 거대 신경망에서는 정규화 기법을 잘 적용한 뒤, 훈련 데이터에 거의 완벽하게 과적합하기 위해 학습을 진행한다. (정규화가 잘 이루어진다면 모델이 잘 일반화할 것이기에, 다만 L1, L2 정규화만으로는 충분하지 않다)
Dropout
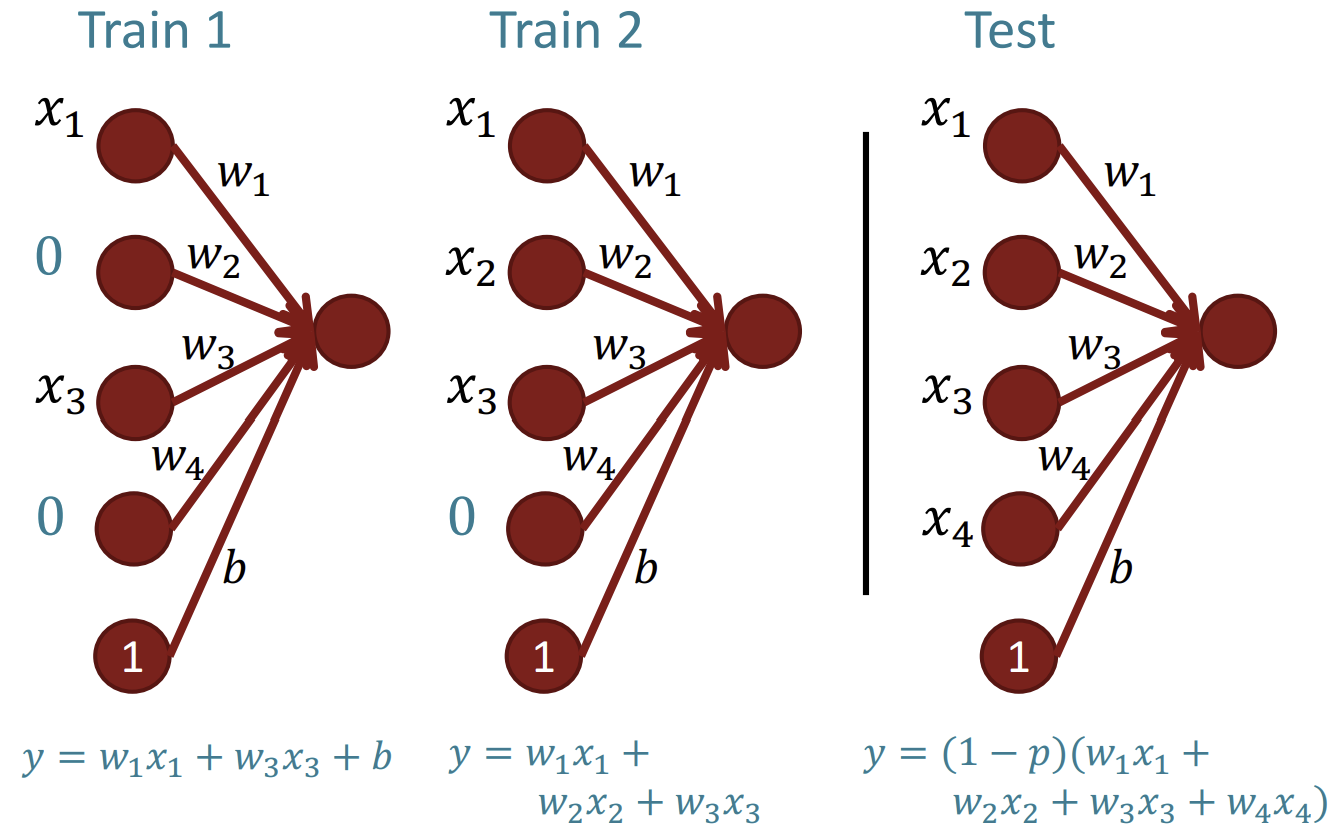 모델 훈련 동안 의 확률로 dropout mask를 적용하여 입력을 0으로 만든다.
모델 훈련 동안 의 확률로 dropout mask를 적용하여 입력을 0으로 만든다.
이후 모델 테스트에서 를 곱하여 가중치를 보정한다. (dropout하여 모델 훈련을 진행했기 때문)
- 훈련된 모델이 가능한 모든 입력을 활용하여 잘 작동할 수 있도록 한다.
- 때때로 한 성분이 무작위로 사라지기 때문에 하나의 성분에 극도로 의존할 수 없도록 하며, 여러 특징이 합쳐져 공동으로 예측을 수행하는 것을 막는다.
- Model ensemble(모델 앙상블), 즉 서로 다른 모델을 결합하여 성능을 향상시키는 것과 유사하게 작동한다.
Vectorization
for 반복문을 활용하여 일일히 계산을 진행하면 매우 느리다.
이때, 벡터나 행렬을 이용하면 CPU에서 조차 훨씬 빠르다.
어떤 것에 대해 for 반복문을 작성하고 있고 그것이 표면적인 입력 처리 작업이 아니라면, 실수를 한 것이며 벡터와 행렬을 이용해 처리할 방법을 생각해야 한다.
따라서 Dropout에서도 for 반복문을 이용하는 것이 아닌 mask를 이용한 벡터 연산으로 몇몇 성분을 0으로 만든다.
Parameter Initialization
가중치를 작은 랜덤값으로 초기화한다.
(행렬을 모두 0이나 다른 상수로 초기화하면 대칭성으로 인해 훈련이 제대로 이루어지기 어렵다)
Optimizer
평범한 SGD(Stochastic gradient descent, 확률적 경사 하강법)도 괜찮지만 좋은 결과를 얻기 위해서는 손수 epoch에 따라 learning rate를 조절하는 것이 중요하다.
더 복잡한 신경망을 위해, 적응적 optimizer는 각 파라미터에 대해 과거에 기울기가 어떻게 변해 왔는지 누적하여 조절한다.

Language Modeling
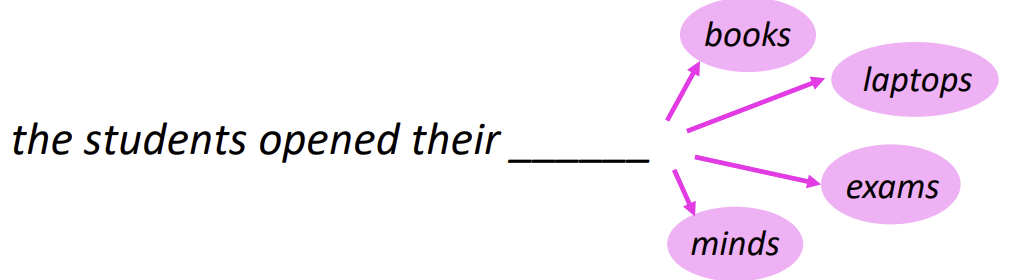 Language modeling(언어 모델링)은 무슨 단어가 다음에 등장할 지 예측하는 과제로, 단어의 시퀀스(앞선 단어들의 문맥)가 주어졌을 때 다음 단어의 확률 분포를 계산하는 것이다.
Language modeling(언어 모델링)은 무슨 단어가 다음에 등장할 지 예측하는 과제로, 단어의 시퀀스(앞선 단어들의 문맥)가 주어졌을 때 다음 단어의 확률 분포를 계산하는 것이다.
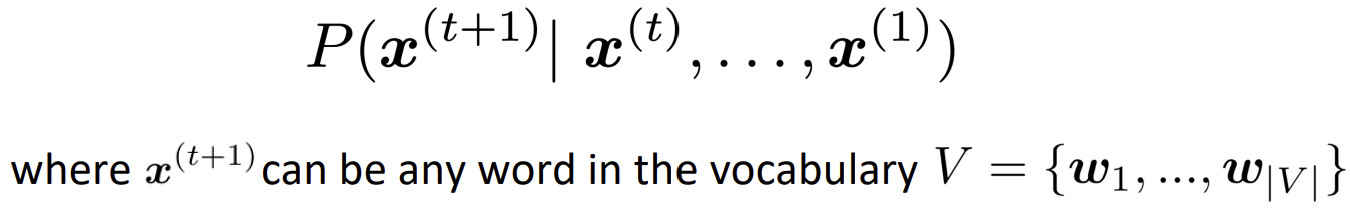
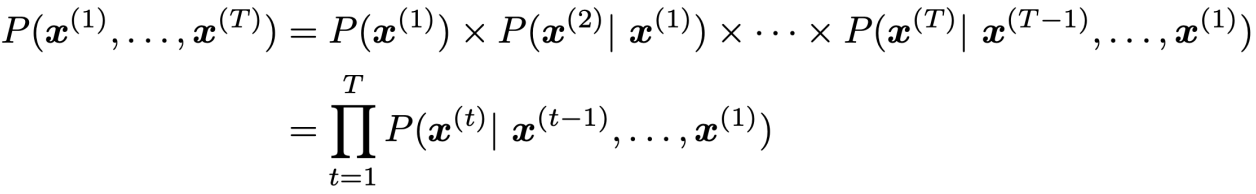 Chain rule를 이용해 계산할 수 있다.
Chain rule를 이용해 계산할 수 있다.
n-gram Language Models
n-gram은 n개 단어의 부분 시퀀스를 사용하여 예측한다.
- monograms: “the”, “students”, “opened”, ”their”
- diagrams: “the students”, “students opened”, “opened their”
- trigrams: “the students opened”, “students opened their”
- four-grams: “the students opened their”
얼마나 자주 다른 n-grams이 등장했는지 세고, 이를 이용하여 확률적 추정을 수행한다.
이때, Markov assumption, 즉 단어 의 확률이 n-1개의 단어에만 의존한다는 가정을 이용한다.

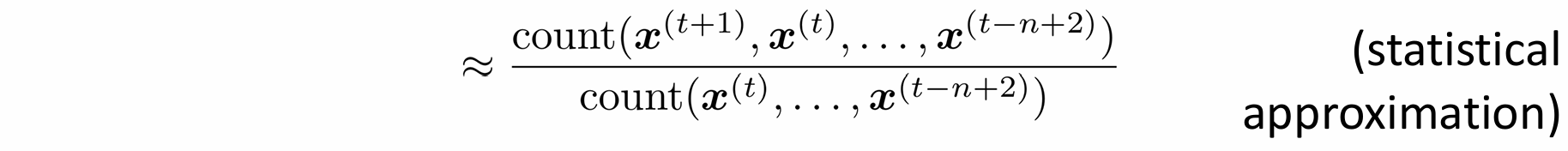
 만약 “students opened their”이 1000번 등장했을 때,
만약 “students opened their”이 1000번 등장했을 때,
“students opened their books”가 400번 등장했다면 다음 단어로 "books"가 등장할 확률을 0.4가 되고,
“students opened their exams”가 100번 등장했다면 다음 단어로 "exams"가 등장할 확률을 0.1이 된다.
그러나 앞에서 버린 "protor(시험 감독관)" 단어의 맥락을 고려하면, 답은 "books"보다 "exams"에 더 가까운 것을 알 수 있다.
Problems with n-gram Language Models
Sparsity Problem 1
만약 “students opened their ”가 데이터에서 절대 등장하지 않는다면 는 등장할 확률이 0이 된다.
count에 작은 값을 더하여 확률이 0이 되는 것을 방지한다. 이를 Smoothing이라고 한다. (다만, 전체 확률 분포의 합이 1이 되지 않는 문제가 발생하므로, 추가적인 정규화 과정이 필요하다)
Sparsity Problem 2
만약 “students opened their”가 데이터에서 절대 등장하지 않는다면 어떤 에 대해서도 확률 값을 계산할 수 없다.
확률 분포에 대한 추정을 얻을 수 있을 때까지 점점 더 작은 문맥을 활용한다. 예로, “opened their”를 대상으로 (즉, 3-grams으로 변경하여) 계산한다. 이를 Backoff라 한다.
Storage Problems
n이 증가할 수록 모델 크기는 지수배(exponentially)로 증가한다.
좋은 추정을 얻기 위해서는 더 많은 맥락(n)을 사용하는 것이 필요하지만,
많은 조건적 단어들의 사용은 공간 문제를 발생시키고 (n이 증가할 수록 공간은 지수배로 증가), 희소성 문제도 악화시킨다.
Generating text with a n-gram Language Model
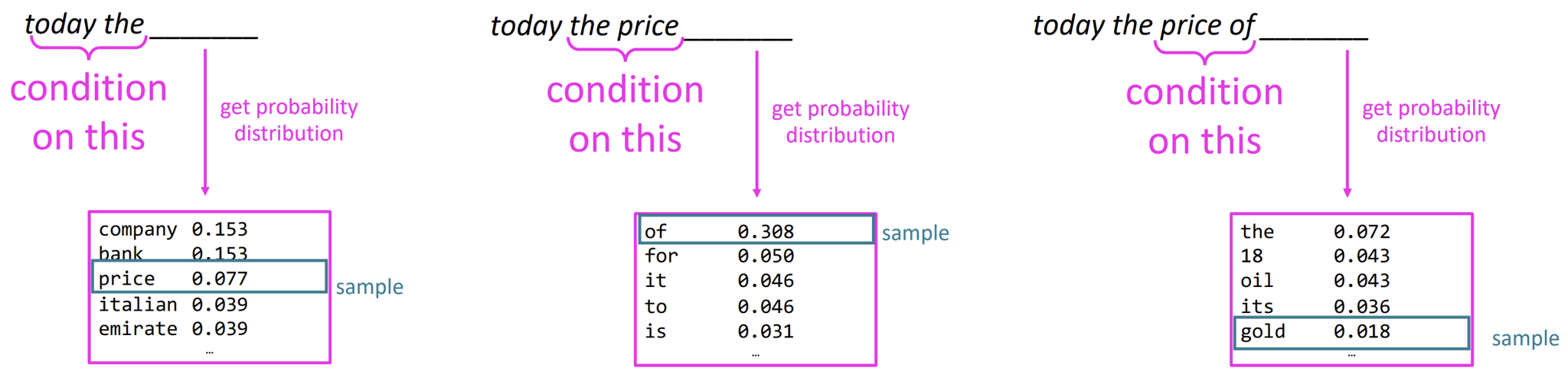 확률 분포를 바탕으로 무작위로 샘플링하여 텍스트를 생성한다.
확률 분포를 바탕으로 무작위로 샘플링하여 텍스트를 생성한다.
