
✍ 해당 시리즈 포스팅은 미시간 대학의 EECS 498-007 강의 내용을 정리한 글입니다. cs231n 강의와 유사하여 해당 시리즈 포스팅과 겹치는 부분이 많이 있을 수 있습니다.
Interpreting a Linear Classifier
Parametric Approach
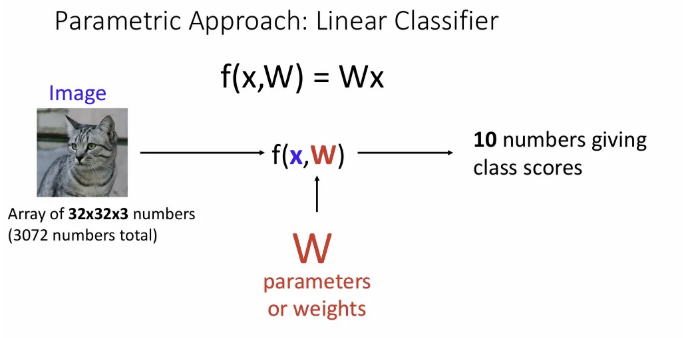
오늘 보는 LInear Classifier, 그 중에서도 위 는 데이터(ex. 이미지)를 input 로 넣어서 가중치 와 곱해져서 행렬 벡터가 되는 가장 간단한 형태이다.
의 각 픽셀들(이미지라고 가정)이 가중치 행렬 와 곱해져서 CIFAR10 기준 10개 클래스에 대한 확률값이 벡터로 나오게 되고, 이 중 가장 높은 확률을 갖는 클래스에 할당된다.
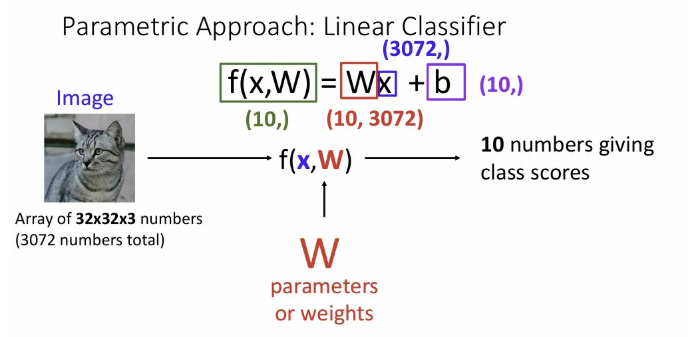
만약 위 예시처럼 32x32x3 이미지를 input으로 받게 되면 총 3072개의 픽셀이 되고, 가중치 행렬과 행렬 곱을 하기 위해 가중치 행렬의 shape은 (N, 3072)가 된다. 여기서 N은 데이터 셋의 클래수 수가 들어가게 되고, CIFAR10은 클래스가 10개이므로 위 슬라이드에선 10이 들어갔다.
행렬 곱 뒤에 bias term이 더해지기도 한다(에 더해져야 하므로 이 또한 크기가 (10,) 이다).
Algebraic Viewpoint

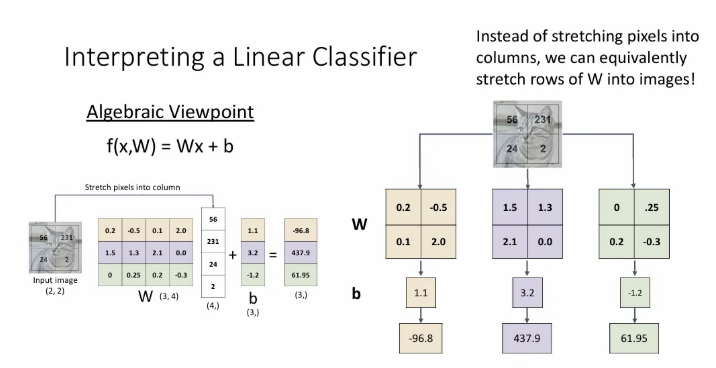
아주 간단한 예시로 위 선형 분류기를 적용해보자. Input이 (2,2) 의 gray scale(channel이 1) 이미지이다. 이를 벡터로 표현하려면 각 행을 잘라서 열로 쭉쭉 이어 붙이게 된다. 그렇게 되면 input 이미지는 오른쪽과 같이 stretch 될 수 있다.
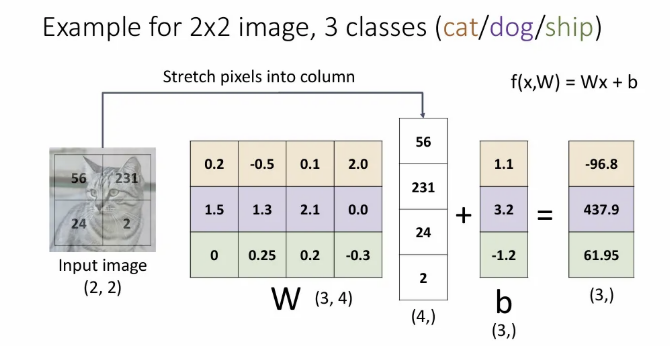
이제 이 와 행렬곱 할 learnable 의 형태를 생각해보자. 예측하고자 하는 클래스의 수는 3개 (고양이/개/배) 이므로 output은 (3,) 크기가 되어야 하고, 와 곱해져서 (3,) 크기를 뱉어야 하는 의 shape은 (3, 4)여야 한다. (bias도 와 같은 (3,))
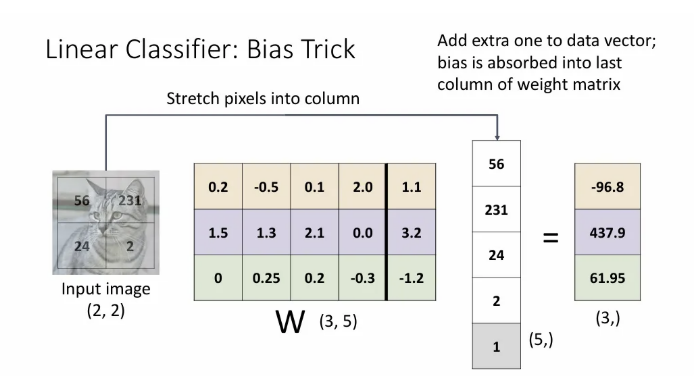
Bias term을 에 확장시키고, 곱 연산을 위해 의 마지막에 추가 상수를 붙이는 bias trick도 있다. 하지만 이 방법은 Input data에 기본 벡터 형식이 있는 경우 사용하고, 컴퓨터 비전에서는 선형 분류기에서 다음으로 이동할 때, 이 bias trick이 잘 적용되지 않아서 덜 사용되는 것이 일반적이다.
하지만 좀 전처럼 대수적 관점에서만 보면 직관적으로 이해하기엔 헷갈릴 수 있다.
이는 의 각 행을 따로 따로 빼서, Input image와 같은 shape으로 맞춰서 오른쪽 처럼 따로 생각해보면 이해하기 좋다.
주황색 행렬과 는 Input image를 넣었을 때 “개” 클래스에 대한 점수를, 보라색 행렬과 는 “고양이” 클래스에 대한 점수를, 연두색 행렬과 는 “배” 클래스에 대한 점수를 출력하게 된다. 위 경우 보라색(고양이) 클래스에 대한 점수가 가장 높게 나온다.
Visual Viewpoint
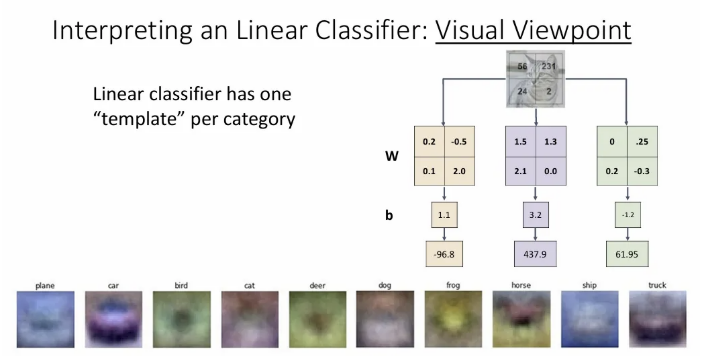
그리고 각 클래스 별 가중치 행렬을 시각화 해보면 위와 같이 나온다. Linear classifier에서 각 카테고리는 하나의 “템플릿”을 가지게 학습되고, 입력 이미지와 각 템플릿을 내적하여 점수를 얻게 된다(두 벡터가 최대한 같은 방향을 바라보아야 내적 값이 크다). 예를 들면 가장 왼쪽의 plane 템플릿은 가운데 큰 덩어리와 전체적으로 파란색의 이미지를 찾게 된다.
하지만 Linear classifier는 이렇게 각 클래스 당 하나의 템플릿만 찾게된다는 점이 단점이다. 같은 클래스의 이미지여도 다양한 방식으로 나타날 수 있기 때문이다.
예를 들어 말 이미지의 경우 CIFAR10으로 학습할 때 오른쪽을 보는 말도 있을 것이고, 왼쪽을 보는 말도 있을 것이다. 이런 경우를 하나의 템플릿에서 모두 반영하자니, 마치 말의 머리가 두 개 인듯한 템플릿이 나온다. 이렇게 되면 다른 방향을 보고 있는(ex. 뒤) 말도 잡기 힘들 뿐더러, 오른쪽이나 왼쪽을 보는 말에 대한 confidence도 낮게 나올 듯 하다.
Geometric Viewpoint

오른쪽 고양이 이미지에서 한 픽셀을 뽑아서, 해당 픽셀 값의 변화에 따른 각 클래스 score를 그려본 것이 바로 왼쪽 플롯이다(x축은 0~255 값의 범위). 해당 Linear classifier는 선형 함수이기 때문에 값이 변화되면 classifier score도 선형으로 변한다.
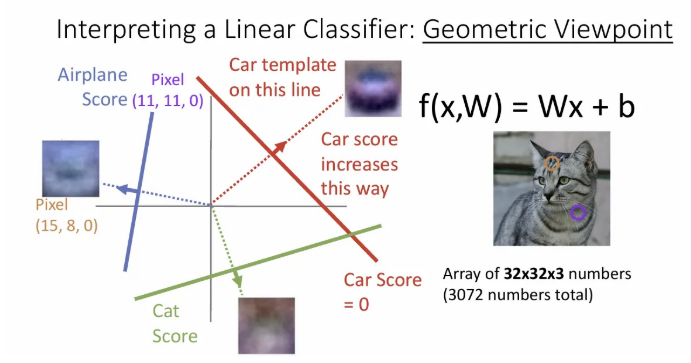
근데 사실 한 픽셀의 변화에 따라 변동하는 class score는 크게 의미 없고, 우리가 가진 모든 픽셀 간 통합적인 관계를 보아야 한다.
예를 들어 이번엔 두 픽셀의 관계를 함께 볼 때 빨간 직선에 해당하는 부분이 Car 인지 판별하는 기준이 되고, 이 직선에서 수직 방향으로 멀리 떨어질수록 Car score는 증가하게 된다.
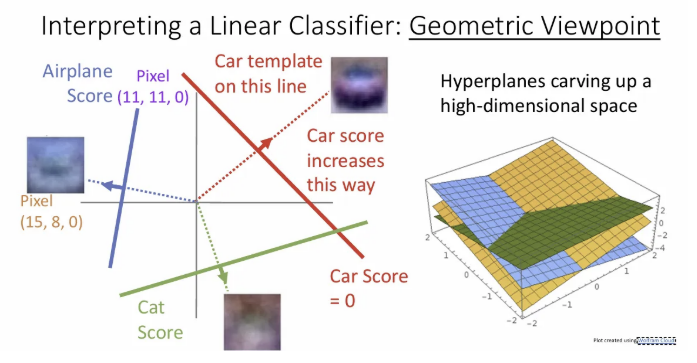
이를 3차원에서 표현해보면 오른쪽처럼 표현될 수 있다. 이런 Geometric 관점에서 2,3 차원으로 직관적인 이해를 확보할 순 있으나 실제 이미지 픽셀은 매우 많고, 이런 고차원에서 상상하기엔 매우 어렵다.
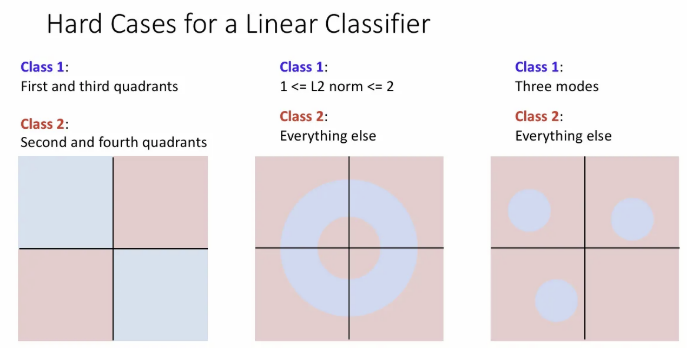
이런 기하학적 관점에서 우리는 Linear classifier가 인식할 수 있는 것과 인식 할 수 없는 것에 대한 아이디어를 얻을 수 있다.
위 세 가지 케이스에서 우리는 하나의 직선 만으로 두 개의 클래스를 완벽히 분류할 수 없다. 앞서 Visual Viewpoint에서 말의 경우를 생각해보면 된다. 픽셀 공간에서 오른쪽을 바라보는 말에 해당하는 공간과 왼쪽을 바라보는 말에 해당하는 공간이 있지만, Linear classifier가 이를 완벽히 분할하는 것이 불가능했던 것이다.

여기까지 선형 분류기에 대한 이해가 되었다면, 그래서 최대한 10개 클래스를 잘 구분하기 위해 의 값들을 어떻게 선택할 수 있을까?
- Loss function으로 가 얼마나 좋은 값 인지를 정량화 한다.
- Optimization을 통해서 Loss 값을 최소화하는 를 찾는다.
Loss Function

Loss function 은 우리의 분류기가 얼마나 잘 작동하는지 보여준다. Objective function이나 cost function으로도 불린다.
번째 샘플에서의 loss는 로 볼 수 있는데, 여기서 는 번째 샘플 와 가중치 가 주어졌을 때 우리 분류기가 예측한 값을 의미하고, 이를 와 비교하는 loss 함수를 적용하여 얻을 수 있다.
그리고 모든 개 샘플에 대한 loss를 합한 값이 전체 Loss인 이 된다.
Cross-Entropy Loss

분류기에서 얻은 각 클래스 별 score 자체를 확률값으로 보게 된다. 각 score를 의미하는 값에 소프트맥스를 적용하여 각 클래스 별 확률의 합이 1이 되도록 취한다.

그리고 해당 샘플에 대한 정답 레이블의 확률에 를 씌워 cross entropy loss를 얻게 된다. 따라서, 위 샘플의 예측에 대한 cross entropy loss는 이 된다.
※ 여기서 슬라이드의 는 무엇을 의미하는가?
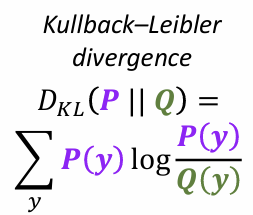
→ Kullback Leibler 발산으로, 정보 이론의 cross entropy에서 유도된 와 두 개의 분포의 차이를 계산하는 함수이다. Cross entropy loss의 위 슬라이드 예시를 보면 우리가 예측으로 얻은 각 클래스의 확률에 대한 분포(초록색 박스)와 target class 확률 분포(보라색 박스) 의 분포 차이를 계산한다고 보면 된다. 는 고정된 상수이므로 결국 를 최소화 하는 것이 크로스 엔트로피()를 최소화 하는 것.
Q1. loss 의 가능한 max / min 값은?
- 최소는 0, 최대는 무한대. SVM Loss와는 달리 모델이 완벽히 예측할 때. 즉, 예측 확률 가 실제 레이블 와 정확히 일치할 때 0이된다.
Q2. 모든 score가 작은 랜덤 값이라면 loss는 어떻게 되는가?
- 개 카테고리 별 uniform distribution을 갖게 되고, 따라서 값이 된다. 따라서 CIFAR10 기준으로는 이면 2.3 근사하는 값이 되고, 처음 학습 시 loss가 해당값을 갖는지를 확인해 봄으로써, 그리고 학습이 오래 이루어 졌을 때도 2.3보다는 loss가 작은 지 체크함으로써 디버깅이 가능하다.
Multiclass SVM Loss

정답 클래스의 score{)와 정답이 아닌 클래스의score()를 비교하는 방법이다. 만일 에서 를 뺀 값이 사전에 정해놓은 margin 값보다 크게되면(정답 score가 월등히 높을 경우) 엔 loss가 0이 되고, 그 전엔 loss가 점점 줄어드는 방식의, 위 hinge loss 형태를 보인다.
위 슬라이드에서 오른쪽 식의 예시로는 와 의 차이가 1 이상 되어야 loss는 비로소 0이 된다. 각 클래스 별 score 차이를 모두 더하면 해당 샘플에서의 loss 를 얻을 수 있고, 전체 샘플에 대한 Loss인 은 각 들의 평균울 취해준다. 아래 슬라이드를 보면 더 이해하기 쉽다.

Q1. 만약 두번째 샘플(자동차) 이미지가 살짝 바뀐다면 loss는 어떻게 변화할까?
- 자동차 클래스에 할당 된 score가 다른 클래스에 할당 된 score보다 훨씬 높아서 기존에도 loss가 zero였고, 이미지가 아주 살짝 바뀐다고 해서 score 차이에 큰 변동은 없기 때문에 그대로 0일 것이다.
Q2. 해당 loss의 max / min 값은?
- min 값은 위에서도 볼 수 있듯 0이고, max값은 만약 정답 클래스의 score가 다른 class의 score보다 매우 매우 낮다면 이론상 무한대까지도 가능하다.
Q3. 만약 모든 score가 랜덤이면, loss값은 어떻게 될까? (표준편차 0.001의 가우시안 분포에서 추출)
- 추출되는 와 는 모두 평균 0을 기준으로 생성되고, 역시 평균 0이 된다. 따라서 은 1에 근사하게 되고, 이는 각 클래스에서 평균적으로 loss가 1씩 나온다고 볼 수 있다. 따라서 loss 값은 이 된다(전체 클래스 수에서 정답 클래스 하나만 뺀 값).
Q4. 정답 클래스까지 포함해서 모든 클래스에 대해 합산한다면?
- 정답 클래스의 경우 이 추가된다고 보면 되고, 이는 1이기 때문에 기존 loss에서 1이 더해진다고 생각하면 된다.
Q5. loss를 합하지 않고 평균을 쓴다면?
- 각 클래스의 loss가 모든 클래스 수에 의해 정규화되는 효과를 가진다.
Q6. 기존 loss의 제곱값을 loss로 쓴다면?
- 비선형적인 방법으로 모든 score를 변화시키게 된다.
Cross-Entropy vs SVM Loss
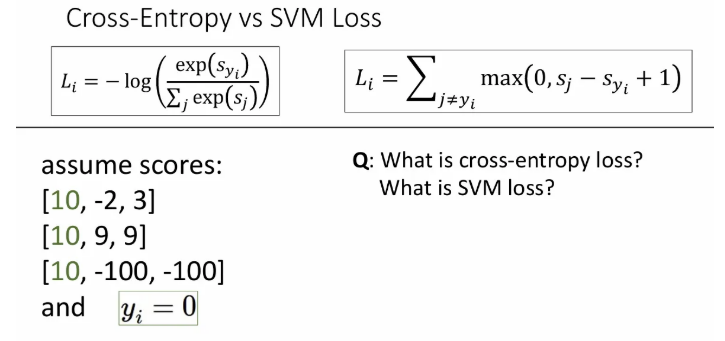
샘플 세 개의 score가 위와 같을 때, 아래 질문에 대해 생각해보자.
Q1. Cross-entropy loss와 SVM loss 값은 각각 어떻게 되는가?
- SVM loss는 각 샘플 모두 모두 정답 클래스 score가 다른 클래스보다 1 이상 높아서 0이 되고, cross-entropy loss는 0보다는 큰 어떤 값이 된다.
Q2. 마지막 세 번째 샘플에서 score가 조금씩 변하면 각각 어떻게 되는가?
- 정답 클래스의 score가 월등히 높기 때문에 SVM loss는 여전히 0이고, cross-entropy loss는 미세하게 변화한다.
Q3. 각 샘플의 정답 클래스 score가 10에서 20으로 변화하면 각각 어떻게 되는가?
- SVM loss는 여전히 0이고, cross entropy loss는 감소하게 된다.
Regularization

여태까지 본 Data loss에 하나의 term을 추가함으로써 정규화를 할 수 있는데, 이는 모델이 training data에만 잘 동작하는 overfitting을 방지하기 위한 것이다. 는 하이퍼파라미터이다.
신경망 모델로 이동하면서 L1, L2같은 유형에 Dropout, BatchNormalization 같은 유형의 정규화도 생겨났다.
References
유튜브 강의: https://www.youtube.com/watch?v=qcSEP17uKKY&list=PL5-TkQAfAZFbzxjBHtzdVCWE0Zbhomg7r&index=3
PDF: https://web.eecs.umich.edu/~justincj/slides/eecs498/FA2020/598_FA2020_lecture03.pdf
