1. Introduction
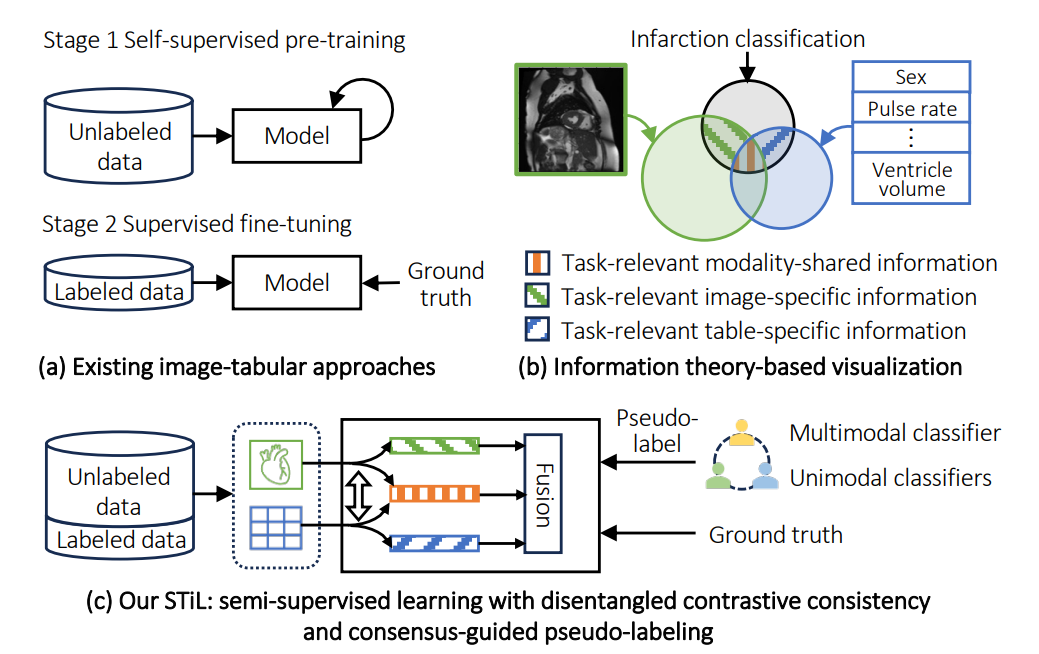
- 최근 image-tabular 멀티모달 학습은 의료 및 마케팅과 같은 다양한 분야에서 주목받고 있음. 이는 이미지와 같은 시각 데이터와 테이블 형식의 구조화된 데이터를 결합하여 더욱 포괄적인 이해를 제공
- 그러나 이러한 접근 방식은 일반적으로 광범위한 레이블링된 훈련 데이터에 대한 의존도가 높으며, 이는 특히 희귀 질환 분류와 같이 레이블링된 데이터가 부족한 시나리오에서는 큰 제약이 됨
- 기존 연구들은 이러한 문제를 해결하기 위해 Self-supervised Learning을 사용하여 대규모의 레이블되지 않은 데이터로 모델을 사전 학습한 후, 레이블링된 데이터로 fine tuning하는 2-stage 접근 방식을 사용하나, 아래 두 가지 한계를 지님
- 사전 학습이 task-agnostic하므로 downstream task에 특화된 정보를 잘 포착하지 못함
- Fine-tuning 단계에서 제한된 레이블링된 데이터에만 의존하여 과적합 위험과 일반화 능력 저하를 초래
- 이러한 문제를 해결하기 위한 유망한 대안으로 소수의 레이블링된 데이터와 다량의 레이블링되지 않은 데이터를 동시에 활용하여 task 관련 정보를 추출하는 Semi-supervised Learning이 있음
- 기존의 Multi-modal Semi-supervised Learning 방법들은 주로 cross-modal consistency 또는 co-pseudo-labeling에 중점을 둠.
- 이러한 방법들은 task 관련 정보가 모달리티 간의 공유된 특성뿐만 아니라 modality-specific 특징에도 존재함에도 불구하고, 공유 정보나 단일 모달 정보에만 의존하여 불완전한 task 이해를 초래하는modality information gap이라는 한계를 가짐.
- 본 논문에서는 이러한 modality information gap과 레이블링된 데이터의 부족 문제를 해결하기 위해 STiL (Semi-supervised Tabular-Image Learning)이라는 새로운 Semi-supervised image-tabular 프레임워크를 제안함.
2. Related Works
Semi-supervised Learning (SemiSL)
SemiSL은 레이블링된 데이터에 대한 의존도를 줄이기 위해 레이블링되지 않은 샘플에서 잠재 패턴을 탐색하는 것을 목표로 함. 초기 연구는 주로 single modality/view 설정에 집중하였으며, pseudo-labeling 기법과 consistency regularization 전략 등을 제안하였고, 최근에는 이 두 가지 접근법을 결합한 weak-to-strong consistency regularization이 유망한 결과를 보임
최근 몇몇 연구들은 cross-modal consistency 또는 co-pseudo-labeling을 통해 멀티모달 데이터에서 SemiSL을 탐구하였으나, 이들은 modality information gap이 없다고 가정하여 유사한 modality/view에 맞춰 설계되었기 때문에 image-tabular와 같이 이질적인 모달리티를 효과적으로 다루지 못함
Multimodal Image-Tabular Learning
이 분야는 특히 의료 분야에서 큰 주목을 받았으며, 초기 연구는 주로 다양한 fusion 방법 설계에 중점을 두고 제한된 레이블링 데이터 문제를 고려하지 않았음.
MMCL과 TIP와 같은 최근 연구들은 Self-supervised Learning 기반의 사전 학습을 통해 대규모 image-tabular 쌍에서 표현을 학습한 후, 레이블링된 데이터로 fine-tuning하는 2-stage 접근 방식을 사용하였으나, 본 논문에서 제안하는 STiL은 레이블링된 데이터와 레이블링되지 않은 데이터를 함께 활용하여 task 관련 정보 학습을 통합적으로 향상시킴.
Disentangled Representation Learning
이 분야는 데이터 내의 특정 숨겨진 요인을 분리하는 모델 개발을 목표로 함. 모달리티 간의 중복성 또는 누락된 모달리티와 같은 문제를 해결하기 위해 modality-shared 및 modality-specific 특징을 분리하는 데 널리 적용되었음.
최근 SSL 연구들은 cross-modality 대조 사전 학습에서 modality-specific 정보 억제를 완화하기 위해 이 방식을 많이 사용하였으나, 주로 각 모달리티에 대한 개별적인 표현 학습에만 초점을 맞추고 모달리티 간의 관계 탐색을 간과하며, task-agnostic 사전 학습으로 인해 레이블링되지 않은 데이터에서 task 관련 정보를 포착하는 데 한계가 있음. 본 논문에서 제안하는 STiL은 이러한 한게를 넘어 멀티모달 표현을 학습하고, 레이블링된 데이터와 레이블링되지 않은 데이터 모두에서 task 관련 정보를 효과적으로 탐색함
3. Method
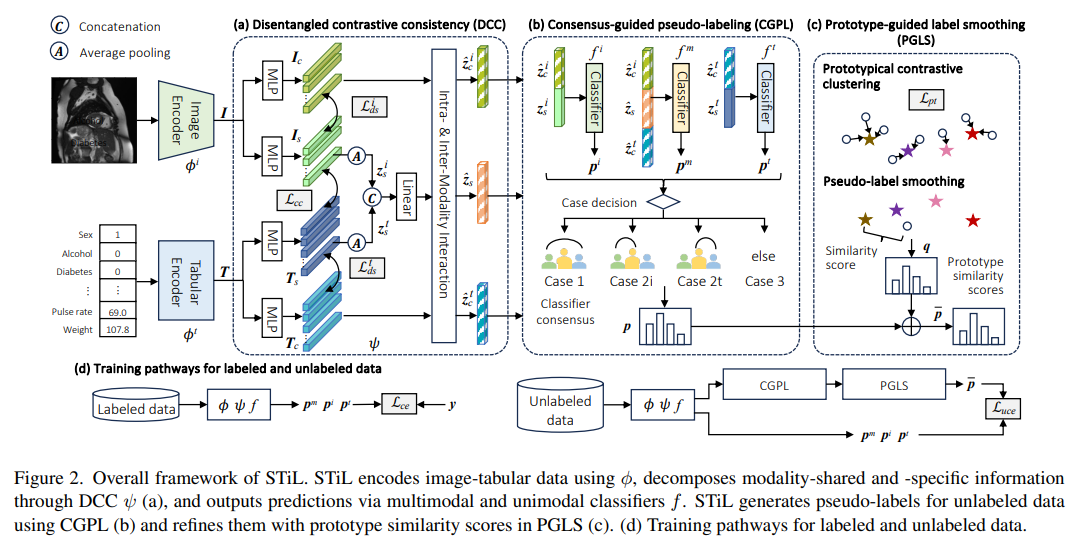
3.1. Problem Formulation and Overall Framework
입력 데이터:
- 레이블링된 image-tabular 쌍 배치
- 레이블링되지 않은 샘플 배치 (는 레이블링된 데이터 대비 레이블링되지 않은 데이터의 상대적 크기 비율)
모델은 CNN 기반의 image encoder 와 트랜스포머 기반의 tabular encoder을 통해 각 모달리티의 표현 와 를 추출. 여기서 는 이미지 패치 수, 는 테이블 컬럼 수, 는 임베딩 차원
제안하는 STiL은 세 가지 핵심 구성 요소로 이루어짐
- Disentangled Contrastive Consistency (DCC) module
- Consensus-Guided Pseudo-Labeling (CGPL) strategy
- Prototype-Guided Label Smoothing (PGLS) strategy
3.2. Disentangled Contrastive Consistency (DCC)
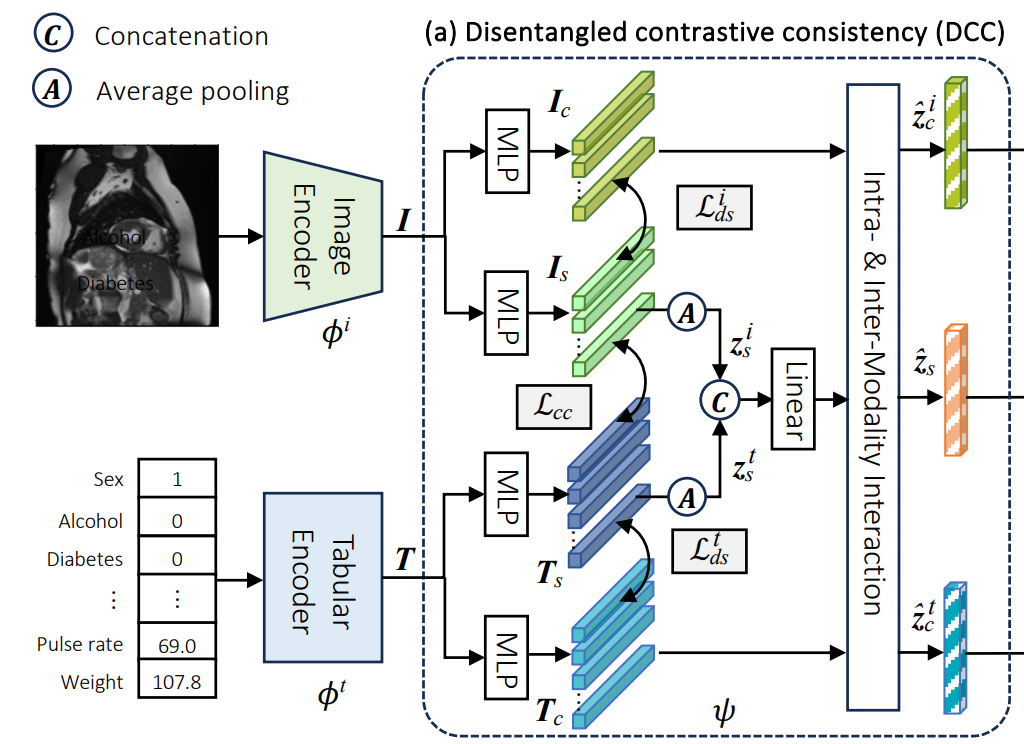
DCC는 지도 감독 없이 포괄적인 멀티모달 표현을 탐색하는 것을 목표로 함.
Representation Disentangling and Consistency
- Disentangled constraint
- 이미지 와 테이블 의 표현을 각각 모달리티 공유 표현 와, 모달리티 특정 표현 으로 분리하는 것을 목표로 함.
- 공유 특징과 특정 특징 간의 상호 정보량을 최소화하여 서로 독립적인 정보를 포함하도록 함. 이는 CLUB (Contrastive Log-ratio Upper Bound) loss를 통해 와 로 공식화됨.
- Shared-information consistency constraint
-
공유 표현 와 에 기반한 cross-modal contrastive loss 를 도입하여 모달리티 간의 불변 표현을 학습함.
-
Average pooling을 통해 얻은 저차원 표현 에 대해 InfoNCE loss를 적용
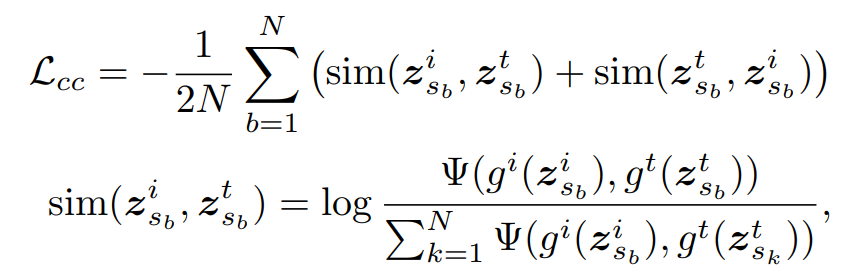
-
그렇게 를 결합하여 전체 loss를 구성
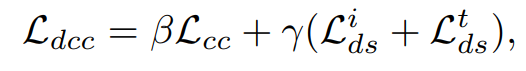
Intra- & Inter-Modality Interaction
- 이 모듈은 모달리티 내 관계와 멀티모달 상호작용에서 발생하는 시너지 정보를 활용
- 특수화된 트랜스포머 레이어를 사용하여 모달리티 특정 특징에 대한 self-attention을 통해 modality 내 의존성을 추출
- 공유 특징과 특정 특징 간의 cross-attention을 통해 모달리티 간 관계를 모델링
- 이를 통해 향상된 공유 표현 와 응축된 모달리티 특정 표현 를 얻음
3.3. Consensus-Guided Pseudo-Labeling (CGPL)
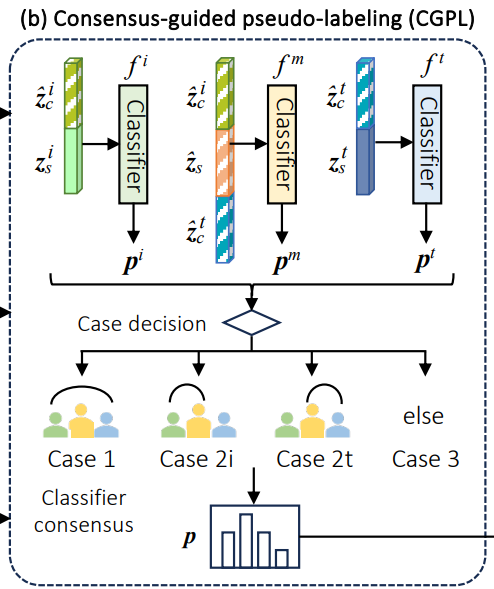
DCC가 특징 수준에서 레이블링되지 않은 데이터를 활용한다면, CGPL은 task 관련 정보 추출을 위해 pseudo-label을 생성함. 특히 classifier consensus를 통해 신뢰성 높은 pseudo label을 생성하여 confirmation bias를 완화
Consensus Collaboration & Pseudo-Labeling
- 멀티모달 분류기 와 두 개의 단일 모달 분류기 를 사용
- 모달리티 정보 격차로 인해 단일 분류기가 모든 task 지식을 가질 수 없다는 점을 고려하여, 멀티모달 분류기와 단일 모달 분류기 간의 alignment에 기반한 rule-based strategy를 사용함.

Selective Classifier Update
- Classifier collusion 위험(모든 분류기가 잘못된 클래스에 대해 실수로 동의하는 경우)을 줄이기 위해, 분류기 다양성을 허용하는 selective update 전략을 사용
- Case 1: 모든 분류기를 업데이트
- Case 2: 일치하지 않는 예측을 한 분류기만 업데이트
- Case 3: 또는 중 하나를 무작위로 업데이트
- 레이블링되지 않은 데이터에 대한 분류 손실 는 아래와 같이 공식화
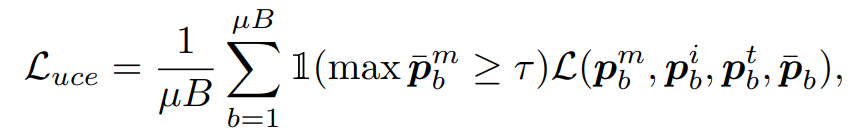
3.4. Prototype-Guided Label Smoothing (PGLS)
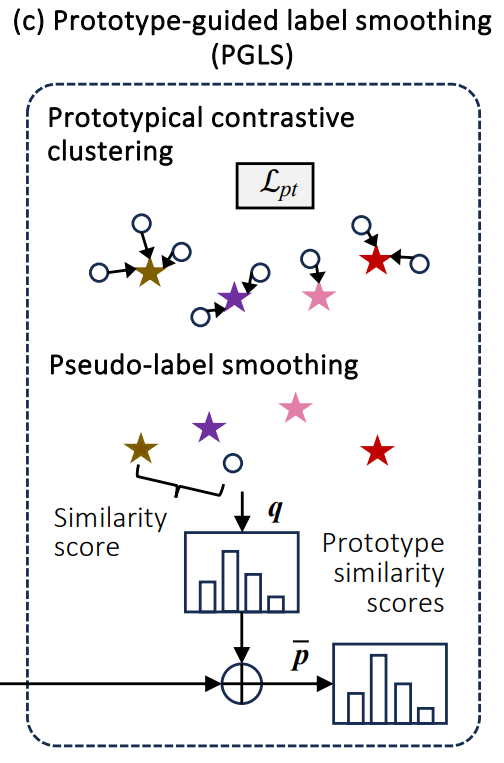
PGLS는 pseudo label의 신뢰성을 더욱 높이기 위해 특징 수준의 레이블 정보를 통합하여 pseudo-label을 정제
-
Class Prototype Extraction
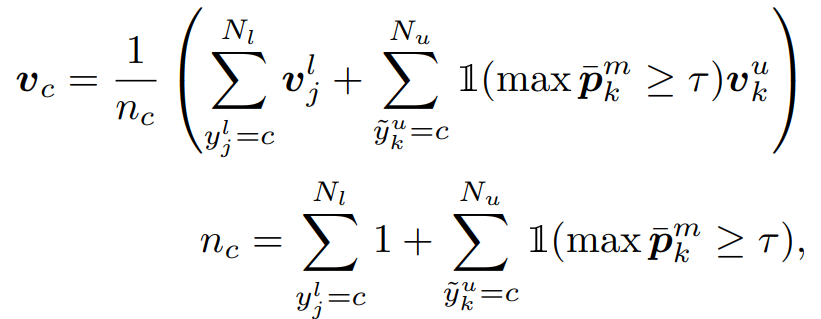
- 각 클래스의 프로토타입 는 해당 클래스에 속하는 임베딩들의 평균 벡터로 정의
- 프로토타입의 신뢰성을 높이기 위해 레이블링된 샘플뿐만 아니라 확신도가 높은 레이블링되지 않은 샘플도 활용 (인 샘플)
-
Prototypical Contrastive Learning
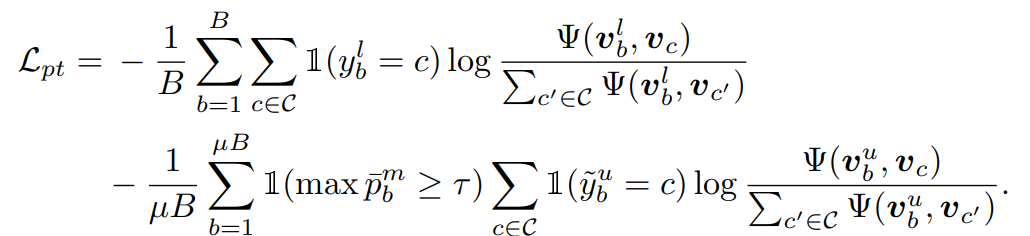
- 프로토타입 임베딩을 얻은 후, 레이블링된 샘플과 확신도 높은 레이블링되지 않은 샘플 모두에 대해 프로토타입 대조 손실 를 도입. 이는 샘플을 해당 클래스 프로토타입에 가깝게 당기고 다른 프로토타입과는 멀어지게 함
-
Pseudo-Label Smoothing
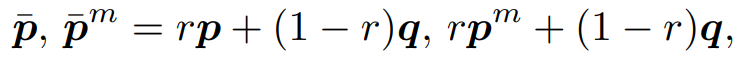
- Confirmation bias를 완화하기 위해 프로토타입 유사도를 사용하여 pseudo label을 평활화
- 프로토타입 유사도 점수 는 샘플 임베딩과 클래스 프로토타입 간의 유사도로 계산
- 평활화된 예측 계산
-
Overall Loss
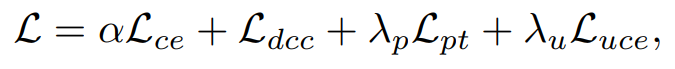
- 그렇게 앞의 loss를 조합하여 최종 loss는 위와 같이 설정됨
-
Teacher-Student Framework
- 학습을 안정화하기 위해 Teacher-Student 프레임워크를 도입
- Teacher 모델은 Student 모델과 같은 아키텍처를 갖지만, EMA로 업데이트 됨.
- Teacher 모델은 pseudo label과 프로토타입을 생성하는 데 사용되고, 추론 시에는 Student 모델의 멀티모달 분류기 의 출력 이 최종 예측으로 사용됨
이러한 통합된 접근 방식을 통해 STiL은 제한된 레이블링 데이터 환경에서 멀티모달 image-tabular 분류의 성능을 크게 향상시킴
4. Experiment
Datasets and Evaluation Metrics
- Natural image dataset - DVM (Data Visual Marketing)
- Task: 자동차 모델 예측 (283개 클래스)
- 데이터: RGB 이미지와 17개 테이블 특징
- 평가 지표: Accuracy
- 데이터 분할: 학습(70,565), 검증(17,642), 테스트(88,207)
- Medical dataset - UKBB (UK Biobank)
- Task: 두 가지 심장 질환 분류
- Coronary artery disease (CAD)
- Myocardial infarction (Infarction)
- 데이터: 2D MRIs와 75가지 테이블 특징
- 평가 지표: AUC (Area Under the Curve)
- 데이터 분할: 학습(26,040), 검증(6,510), 테스트(3,617)
- Task: 두 가지 심장 질환 분류
Implementation Details
논문 원문 참고
4.1. Overall Results
Comparing Against Supervised/SSL SOTAs
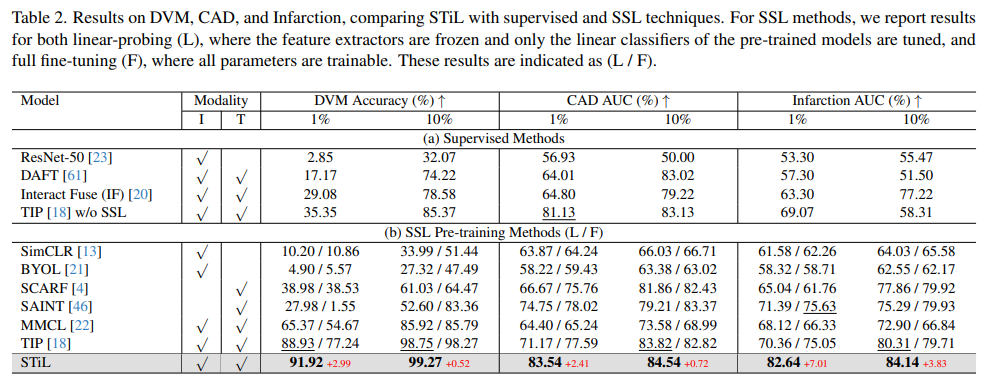
- STiL이 모든 task에서 가장 우수한 성능을 보임.
- 멀티모달 방법이 단일 모달 방법보다 성능이 우수하여 테이블 정보 통합의 이점을 보여주는 실험
- SSL 방법은 데이터 부족 환경에서 성능이 향상되지만, 여전히 과적합 문제를 겪을 수 있지만, STiL은 레이블링되지 않은 데이터를 활용하여 과적합을 완화하고 우수한 성능을 달성
Comparing Against SemiSL SOTAs
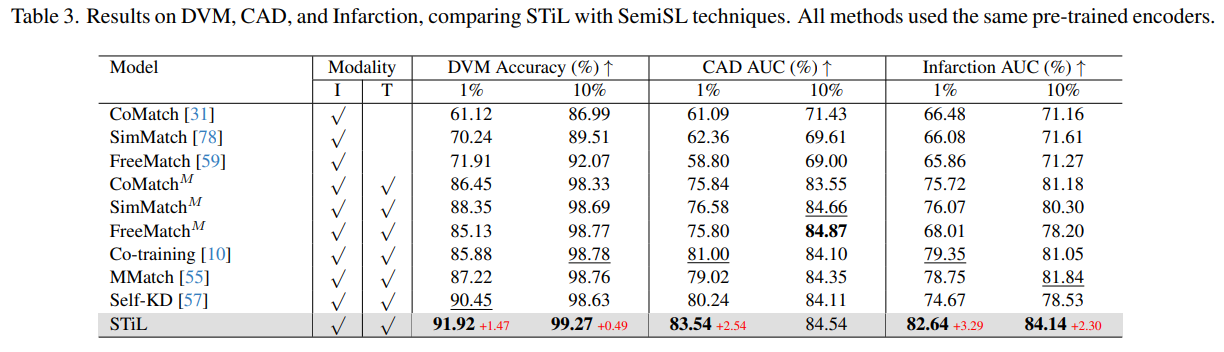
- STiL은 모든 SemiSL SOTA보다 뛰어난 성능을 보임.
- SemiSL 방법은 레이블링되지 않은 데이터 활용을 통해 지도 학습 및 SSL보다 성능이 좋음
- 기존 이미지 SemiSL 방법을 멀티모달 환경에 적용하면 성능이 향상되지만, 멀티모달 task에 특화된 방법에는 미치지 못함
- STiL은 Modality-information gap을 해결하여 task 관련 정보를 더 효과적으로 활용하며, 기존 SOTA들을 능가하는 결과를 보여줌
Ablation Studies
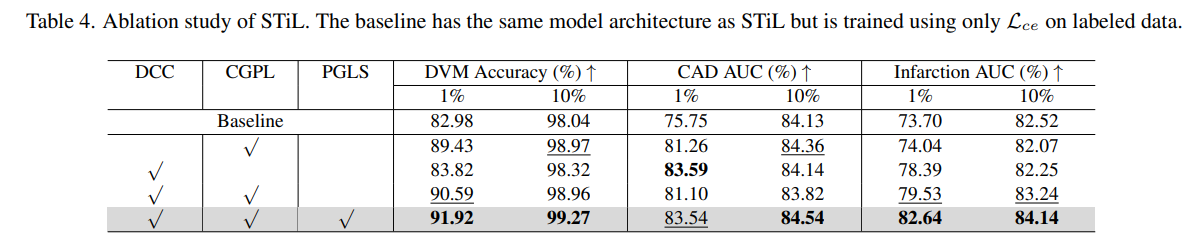
- 세가지 주요 구성 요소인 DCC, CGPL, PGLS 각각의 기여도를 평가.
- 각 구성 요소들은 성능 향상에 기여하였으며, 모든 구성 요소를 사용할 때 가장 좋은 성능을 보임
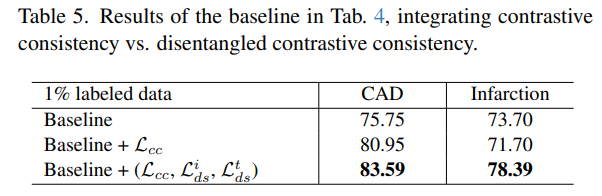
- Disentangled Contrastive Consistency (DCC) 모듈에 대한 ablation 결과
- 단순한 대조학습 만으로는 모든 모달리티 정보를 포괄적으로 활용하기 어려울 수 있으며, 특정 태스크에서는 오히려 성능 저하를 가져올 수 있음
- 모달리티 간 공유 정보뿐만 아니라 모달리티 고유 정보를 명시적으로 분리하고 보존하는 것이 multi-modality 학습에서 중요
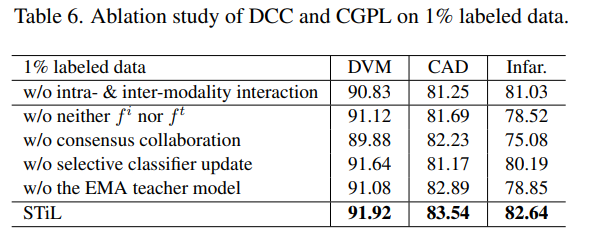
- STiL 모델의 각 핵심 구성 요소가 전체 성능에 미치는 영향을 평가
- STiL의 각 독창적인 구성 요소가 특히 레이블링된 데이터가 부족한 시나리오에서 모델의 뛰어난 성능에 필수적인 기여를 한다는 것을 보여줌
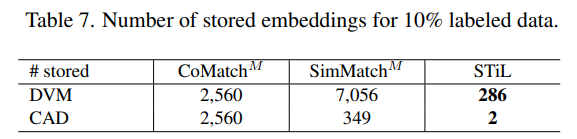
- SemiSL, 특히 임베딩 유사성을 사용하는 접근 방식들의 효율성 비교
- STiL은 CoMatch, SimMatch에 비해 압도적으로 적은 수의 임베딩을 저장
- 이는 STiL이 각 클래스에 대한 프로토타입 임베딩만을 저장하기 때문
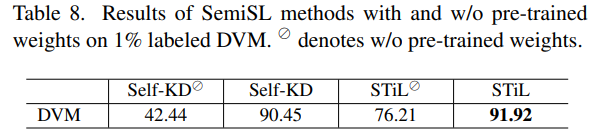
- 1%의 레이블링된 DVM 데이터셋에서 SemiSL 방법론들이 사전 학습된 가중치 사용 여부에 따라 어떻게 다른 성능을 보이는지 비교
- STiL의 경우 사전학습된 가중치를 사용하지 않고도 Self-KD에 비해 훨씬 높은 정확도를 달성.
- 이는 STiL이 사전 학습된 가중치에 대한 의존도가 상대적으로 낮으며, 제한된 레이블링 데이터와 대량의 언레이블링된 데이터를 효과적으로 활용하여 강력한 특징을 학습하는 데 강건함을 의미
