✍K-Means 군집화란?
중심기반 분리형 군집화의 한 방법으로 데이터를 K개의 겹치지 않는 군집으로 분리하는 알고리즘
- 각 군집은 하나의 중심(centroid)를 가짐
- 각 개체는 가장 가까운 중심에 할당되며, 같은 중심에 할당된 개체들이 모여 하나의 군집 생성
- 사전에 군집 수 K를 정해주어야 함
알고리즘 순서
- K개의 초기 군집 중심 설정
- 모든 개체를 가장 가까운 군집 중심에 할당하여 군집 구성
- 할당된 개체들을 이용하여 군집 중심을 업데이트
- 종료 조건: 모든 군집 중심들의 위치가 변하지 않고, 모든 개체의 군집 할당 결과에 변화가 없을 때
※ 초기 군집 중심은 실행할 때마다 달라서 분석 결과가 상이할 수 있다.
(예시 그림)
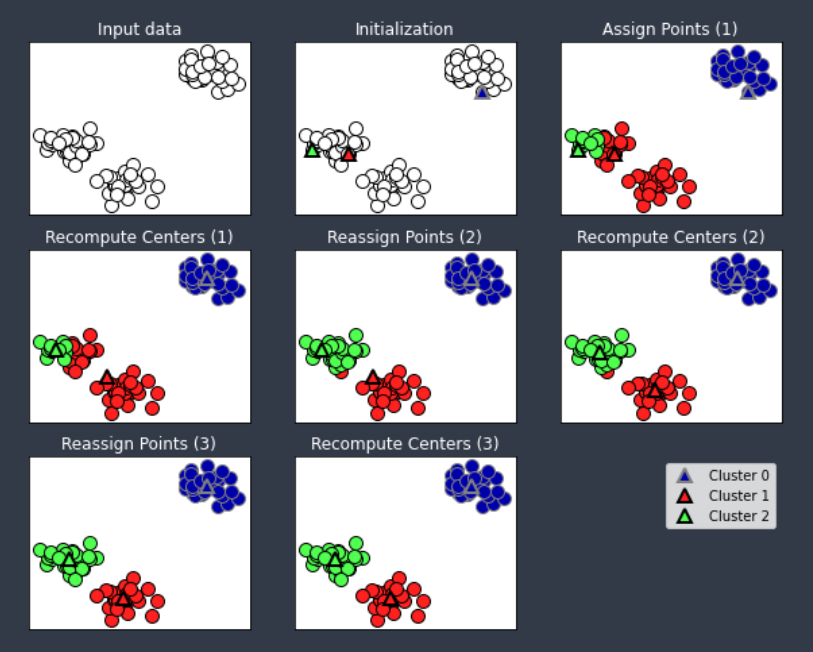
위 그림은 mglearn에서 제공하는 사전에 K를 3으로 설정하고 K-Means를 실행한 예시 그림이다. 초기 군집 중심은 랜덤으로 배치된다. iter이 돌 때마다 군집 중심과 군집 개체들은 업데이트 되고 있고, 둘 다 변하지 않는 시점에서 종료되는 것을 확인할 수 있다.
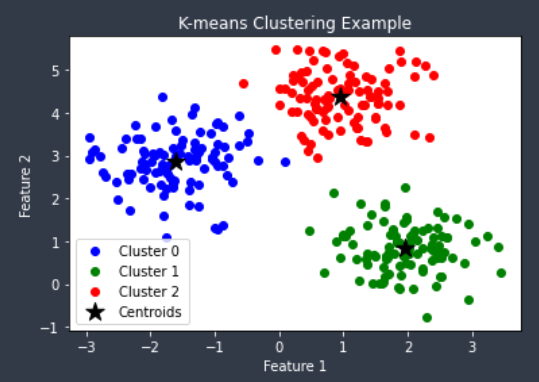
아래는 예시 코드와 결과이다.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
# make_blobs를 사용하여 원형 군집 데이터 생성
X, y = make_blobs(n_samples=300, centers=3, cluster_std=0.6, random_state=0)
# K-means 알고리즘으로 군집화
kmeans = KMeans(n_clusters=3, random_state=0)
kmeans.fit(X)
# 군집 중심 확인
centroids = kmeans.cluster_centers_
# 군집화 결과 시각화
colors = ['b', 'g', 'r', 'c', 'm', 'y', 'k']
for label in set(kmeans.labels_):
color = colors[label % len(colors)]
cluster_points = X[kmeans.labels_ == label]
plt.scatter(cluster_points[:, 0], cluster_points[:, 1], c=color, label=f'Cluster {label}')
plt.scatter(centroids[:, 0], centroids[:, 1], marker='*', c='k', s=200, label='Centroids')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('K-means Clustering Example')
plt.legend()
plt.show()
- 실행 결과
한계점
-
서로 다른 크기의 군집을 잘 찾아내지 못한다.

-
서로 다른 밀도의 군집을 잘 찾아내지 못한다. (좌: 정답, 우 : K-means 결과)

-
지역적 패턴이 존재하는 군집을 판별하기 어렵다. (구형이 아닌 형태의 군집을 판별하기 어려움)

-
이상치에 민감하다.

K-Means++
K-Means 알고리즘의 가장 큰 문제점인 초기 중심점 무작위 설정을 어느정도 해결하기 위한 알고리즘
- 데이터 포인트 중 하나를 무작위로 선택하여 첫 번째 중심점으로 설정한다.
- 첫 번째 중심점으로부터 나머지 데이터 포인트에 대한 거리를 계산한다.
- 중심점으로부터 가장 먼 데이터 포인트를 그 다음 중심점으로 지정
- 2, 3번을 K개의 중심점이 생길 때 까지 반복
- 이후로 K-Means와 동일하게 중심점 최신화 수행
전체적인 알고리즘 흐름은 K-Means와 같으나 초기 중심점을 좀 더 제대로 설정해 주고 시작한다고 생각하면 되겠다.
References

큰 사람이 되겠어요