1. 시간복잡도가 무엇이고 왜 사용되는지?
1-1. 시간복잡도란 무엇인가?
시간 복잡도는 알고리즘을 구성하는 명령어들이 몇 번이나 실행이 되는지를 센 결과에 각 명령어의 실행시간을 곱한 합계를 의미한다. 그러나 각 명령어의 실행시간은 특정 하드웨어 혹은 프로그래밍 언어에 따라서 그 값이 달라질 수 있기 때문에 알고리즘의 일반적인 시간 복잡도는 명령어의 실제 실행시간을 제외한 명령어의 실행 횟수만을 고려하게 된다. 또한, 알고리즘의 분석은 일반적으로 공간복잡도 보다는 시간 복잡도를 통해서 이루어 진다.
시간 복잡도를 표기하는 방법 중 Big-O 표기법이 있는데, 이는 실행 시간 n을 O(n)으로 표기한다. Big-O에서 차수가 가장 높은 최고차항만 두고 나머지는 버린다.

-
O(1) : 입력 데이터의 크기와 상관없이 언제나 일정한 시간이 걸리는 알고리즘을 말한다. (Constant Time)
-
입력되는 데이터양과 상관없이 일정한 실행 시간을 가진다.
-
알고리즘이 문제를 해결하는데 오직 한 단계만 거친다.
-
-
O(n) : 입력 데이터의 크기에 비례해서 처리시간에 걸리는 알고리즘을 표현할 때 사용 (Linear Time)
-
데이터양에 따라 시간이 정비례한다.
-
Linear search, for 문을 통한 탐색을 생각하면 된다.
-
-
O(n^2) : Quadratic Time
-
데이터양에 따라 걸리는 시간은 제곱에 비례한다. (효율이 좋지 않음, 사용 X)
-
해당 유형은 이중 Loop내에서 입력 자료를 처리 하는 경우에 나타난다. N값이 큰 값이 되면 실행 시간은 감당하지 못할 정도로 커지게 될 것이다.
-
문제를 해결하기 위한 단계의 수는 입력값 n의 제곱
-
-
O(log n) : Binary search tree access(이진 검색) - search(검색), insertion(삽입), deletion(삭제)
-
데이터양이 많아져도, 시간이 조금씩 늘어난다.
-
시간에 비례하여, 탐색 가능한 데이터양이 2의 n승이 된다.
-
문제를 해결하는데 필요한 단계들이 연산마다 특정 요인에 의해 줄어든다.
-
만약 입력 자료의 수에 따라 실행 시간이 이 log N의 관계를 만족한다면 N이 증가함에 따라 실행시간이 조금씩 늘어난다. 주로 커다란 문제를 일정한 크기를 갖는 작은 문제로 쪼갤때 나타나는 유형이다.
-
1-2. 시간복잡도는 왜 사용하는가?
- 수행시간을 통해 시간복잡도를 구하고 효율적인 알고리즘인지 분석한다.
2. 각 자료구조별 시간복잡도 분석
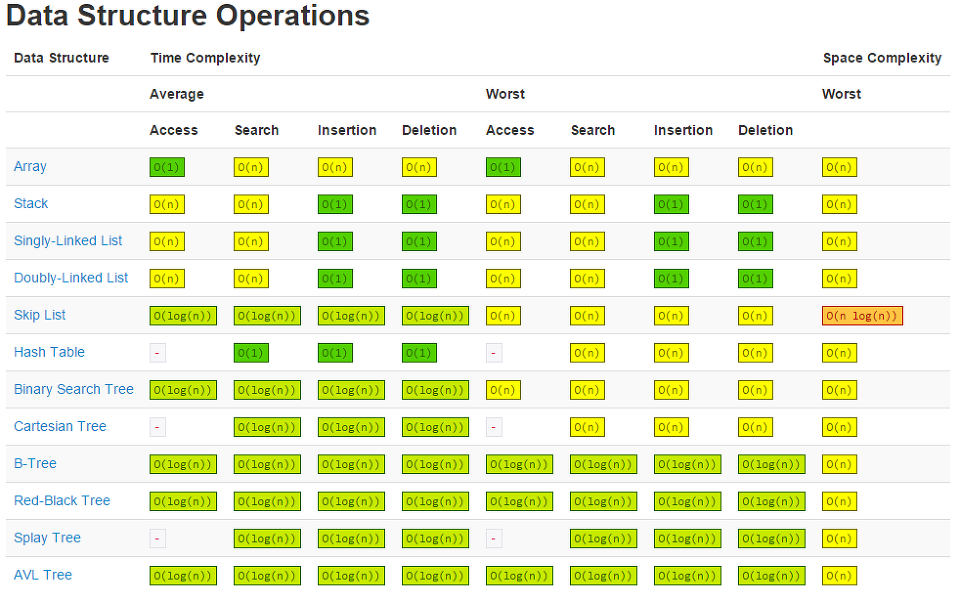
3. 참고문서
