
시작하며
오늘은 NoSQL 중에서 널리 사용되는 도큐먼트 데이터베이스인 MongoDB에 대해서 학습하였다. MongoDB를 설치하고 쿼리를 배우고 실제로 사용하면서 그동안 학습한 관계형 데이터베이스에 비해 어떤 장점이 있고 어떤 경우에 사용하는 것이 좋을지 생각해 볼 수 있었다.
MongoDB
NoSQL
NoSQL은 매우 넓은 범위에서 사용하는 용어로, 관계형 테이블의 레거시한 방법을 사용하지 않는 데이터 저장소를 말하며, MongoDB는 널리 사용되는 NoSQL 데이터베이스이다.
NoSQL가 사용되는 경우
- 비구조적인 대용량의 데이터를 저장하는 경우
- 클라우드 컴퓨팅 및 저장공간을 최대한 활용하는 경우
- 빠르게 서비스를 구축하고 데이터 구조를 자주 업데이트 하는 경우
Atlas Cloud
MongoDB에서는 아틀라스(Atlas)로 클라우드에 데이터베이스를 설정한다. 아틀라스는 GUI와 CLI로 데이터를 시각화, 분석, 내보내기, 그리고 빌드하는 데에 사용할 수 있고, 아틀라스 사용자는 클러스터를 배포 할 수 있으며, 클러스터는 그룹화된 서버에 데이터를 저장한다.
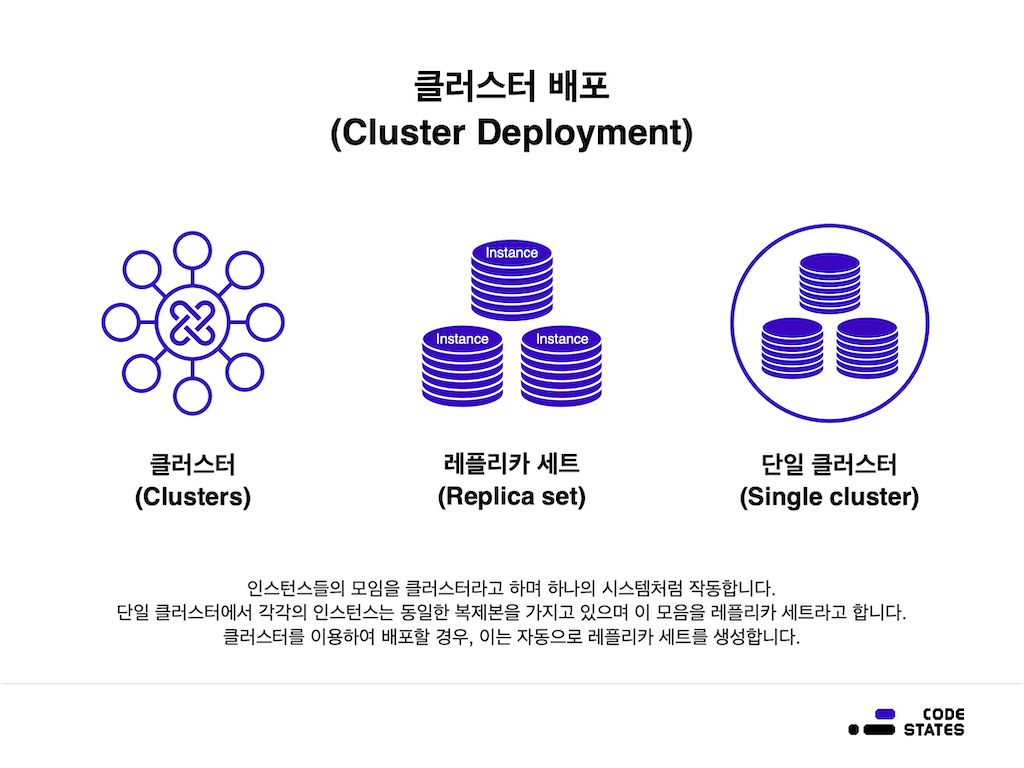
이 서버는 레플리카 세트(Replica set)로 구성되어 있으며, 레플리카 세트는 동일한 데이터를 저장하는 몇 개의 연결된 MongoDB 인스턴스의 모음이다.
- 인스턴스는 특정 소프트웨어를 실행하는 로컬 또는 클라우드의 단일 머신입니다. 이 경우에서 인스턴스는 클라우드에서 실행되는 MongoDB 데이터베이스이다.

- 레플리카 세트 : 동일한 데이터를 저장하는 소수의 연결된 머신을 뜻하며, 레플리카 세트 중 하나에 문제가 발생하더라도, 데이터를 그대로 유지할 수 있다.
- 인스턴스 : 로컬 또는 클라우드에서 특정 소프트웨어를 실행하는 단일 머신, MongoDB에서는 데이터베이스이다.
- 클러스터 : 데이터를 저장하는 서버 그룹으로 여러 대의 컴퓨터를 네트워크를 통해 연결하여 하나의 단일 컴퓨터처럼 동작하도록 제작한 컴퓨터를 말한다.
용어
- 도큐먼트(Document) : 필드 - 값 쌍으로 저장된 데이터
- 필드(Field) : 데이터 포인트를 위한 고유한 식별자
- 값(Value) : 주어진 식별자와 연결된 데이터
- 컬렉션(Collection) : MongoDB의 도큐먼트로 구성된 저장소로, 일반적으로 도큐먼트 간의 공통 필드가 있다. 데이터베이스 당 많은 컬렉션이 있고, 컬렉션 당 많은 도큐먼트가 있을 수 있다.
JSON vs. BSON
JSON
shell을 이용하여 도큐먼트를 조회하거나 업데이트 할 때, 도큐먼트는 JSON(JavaScript Object Notation) 형식으로 출력되는데, JSON 형식으로 도큐먼트를 작성하기 위해서는, 다음과 같은 조건을 만족해야 한다.
{}중괄호로 도큐먼트가 시작하고, 끝나야 한다.- 필드와 값이 콜론(
:)으로 분리되어야 하며, 필드와 값을 포함하는 쌍은 쉼표(,)로 구분된다. - 문자열인 필드도 쌍따옴표(
"")로 감싸야 한다.
Import
mongoimport --uri "<Atlas Cluster URL>" --drop=<filename>.json
Export
mongoexport --uri "<Atlas Cluster URL>" --collection=<collection name> --out=<filename>.json
BSON
JSON 형식은 읽기 쉽고, 많은 개발자들이 사용하기 편리한 형태를 가지고 있지만, 파싱이 느리고 메모리 사용이 비효율적이다. 그리고 기본 데이터 타입만을 지원하기 때문에, 사용 할 수 있는 데이터 타입에 제약이 있다.
이런 문제점을 해결하기 위한 방안으로 BSON(Binary JSON) 형식을 도입하였다.
BSON은 컴퓨터의 언어에 가까운 이진법에 기반을 둔 표현법으로, JSON 보다 메모리 사용이 효율적이며 빠르고, 가볍고, 유연하며, 더 많은 데이터 타입을 사용할 수 있다.
MongoDB는 JSON형식으로 작성된 것은 무엇이든 데이터베이스에 추가할 수 있고, 쉽게 조회할 수 있다. 그러나 그 내부에서는 속도, 효율성, 유연성의 장점이 있는 BSON으로 데이터를 저장, 사용하고 있다.
Import
mongorestore --uri "<Atlas Cluster URL>" --drop dump
Export
mongodump --uri "<Atlas Cluster URL>"
CRUD
Create
db.collection.insert([document or array of documents], {ordered: <boolean>})
여러개의 데이터를 삽입할 경우, 배열 내 객체 형태로 입력해주면 되고 ordered: false로 옵션을 설정할 경우,
duplicate key 에러가 발생하더라도 그 이후에 적혀있는 도큐먼트들이 고유한 _id를 가지고 있다면 모두 컬렉션에 삽입된다.
READ
find()
db.collection.find(query, projection)
query에 찾을 도큐먼트의 조건을 "필드":"값" 형태로 작성해주면 해당하는 도큐먼트들을 조회할 수 있다.
두 번째 인자인 projection에 { "필드" : 1 } 을 적어주면 쿼리 조건에 맞는 데이터들의 해당하는 필드:값만 보여지게 된다. 값을 0으로 적을 경우, 해당 필드를 제외하고 조회되며, 여러 필드에 동시 적용할 경우, 1과 0은 혼용해서 사용할 수 없다(단, { "_id" : 0, "필드" : 1 }처럼 _id만 제외하는 경우에는 사용 가능)
findOne()
db.collection.findOne()
findone을 사용하면 조건에 해당하는 데이터 1개를 무작위로 가져온다.
count()
db.collection.find().count()
find().count()를 사용하면 조회된 데이터들의 개수를 리턴한다.
pretty()
db.collection.find().pretty()
pretty( )는 도큐먼트의 구조와 각 필드, 값의 쌍을 조금 더 읽기 편한 형태로 출력한다.
UPDATE
updateOne()
db.collection.updateOne({"field":"value"}, {"$set" : {"field": "value"}})
updateOne은 주어진 기준에 맞는 다수의 도큐먼트 중 첫번째 도큐먼트 하나만 업데이트한다.
첫번째 인자에는 업데이트할 데이터의 조건을 적고 두번째인자에는 변경할 필드와 값을 입력하면되는데, "$set" 대신에 "$inc" 를 입력할 경우 "value"에 쓴 숫자만큼 증가가 가능하다.
updateMany()
db.collection.updateMany({"field":"value"}, {"$set" : {"field": "value"}})
updateMany는 쿼리문과 일치하는 모든 도큐먼트를 업데이트하고 사용법은 updateOne과 동일하다.
DELETE
deleteOne()
db.collection.deleteOne({"field":"value"})
deleteOne은 첫번째 인자로 주어진 기준에 맞는 다수의 도큐먼트 중 첫번째 도큐먼트 하나만 삭제한다.
deleteMany()
db.collection.deleteMany({"field":"value"})
deleteMany는 쿼리문과 일치하는 모든 도큐먼트를 삭제한다.
drop()
db.collection.drop()
drop을 사용할 경우, 해당하는 컬렉션이 삭제된다.
마치며
MongoDB가 비관계형 데이터베이스이지만 이전에 SQL을 학습한 후이기 때문에 훨씬 수월하게 개념과 구조를 익힐 수 있었다. 데이터 베이스라는 개념을 이해하고 있기 때문에 도큐먼트, 필드, 컬렉션이라는 개념이 용어만 다를 뿐 SQL과 일치하는 부분이 많았고 JSON도 javaScript를 배우면서 알고 있는 걔념이여서 데이터를 관리거나 조회하는 명령문을 빠르게 익힐 수 있었다. 블로깅하지는 않았지만 추가로 학습한 연산자들과 aggregation Framework도 연습해서 MongoDB를 사용하는데 익숙해 질 수 있도록 해야겠다.
