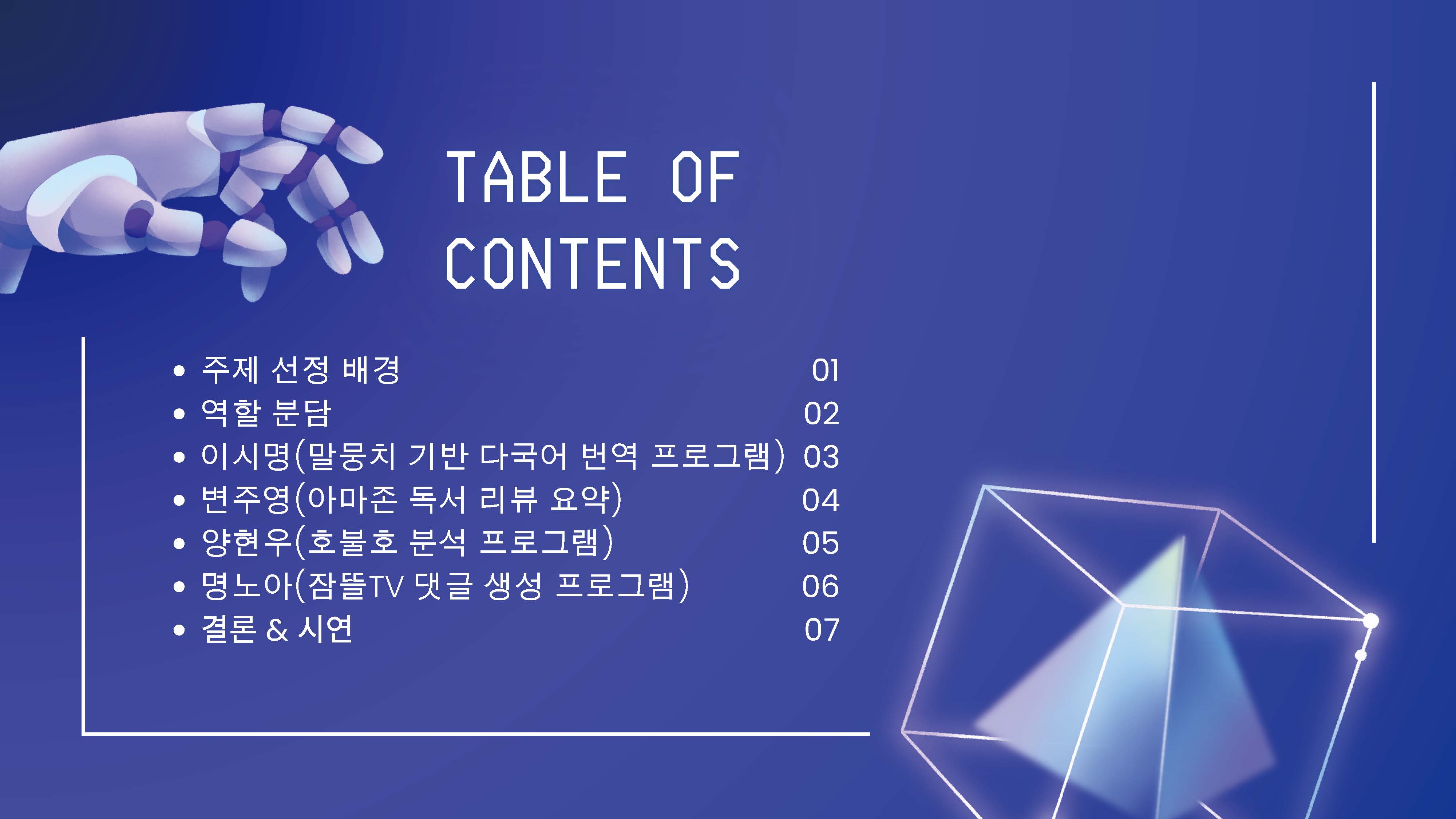
내 파트만 이미지 업로드
< 공통파트 >


트랜스포머 모델을 중심으로 어떤 주제를 잡을 수 있을지 고민하다가
위와 같은 주제로 가져가는 것으로 결정
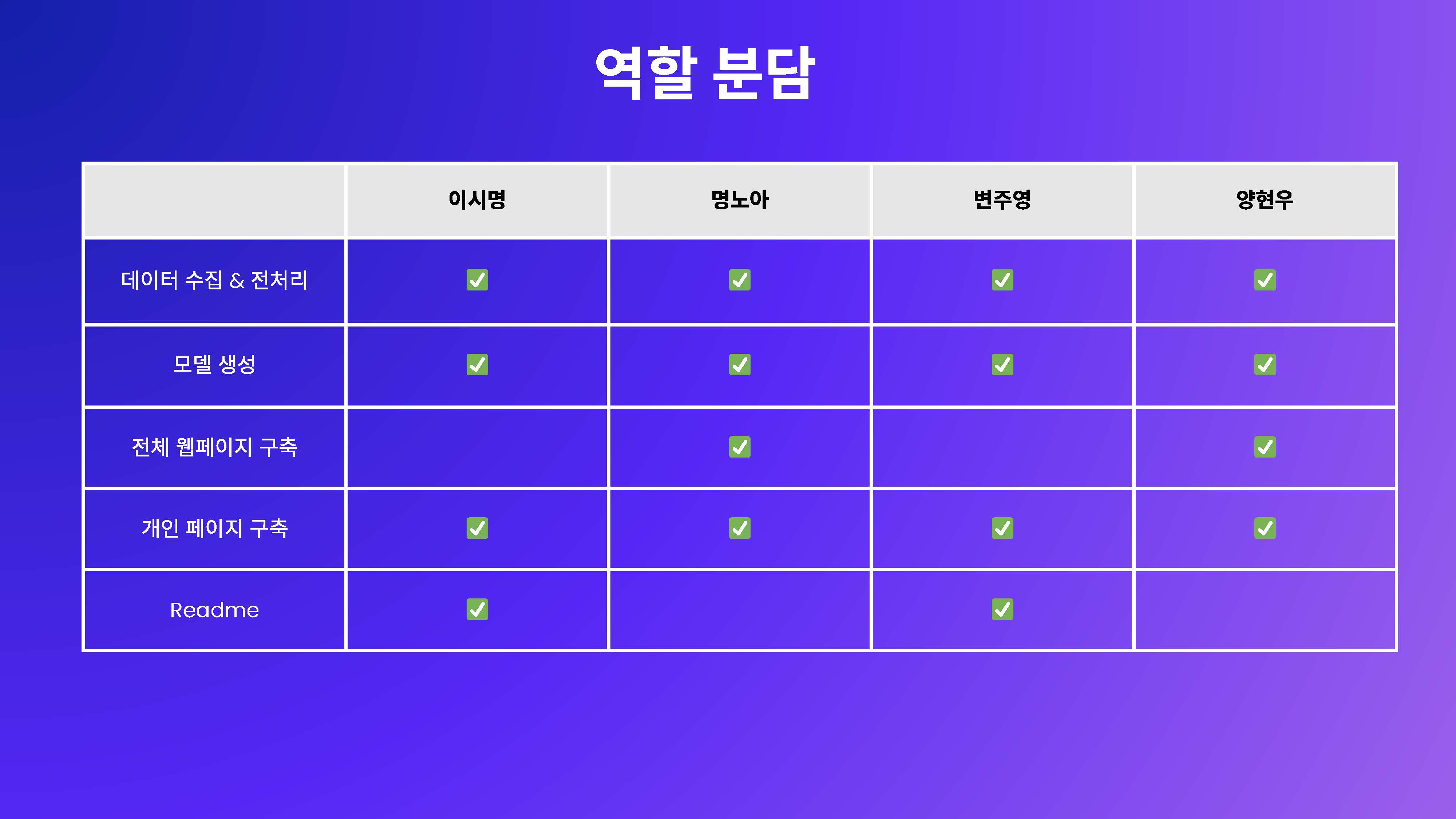
최초에는 모두 같은 데이터셋을 바탕으로 진행하는 것을 추구하였으나
각자의 모델이 원하는 성능이 나오지 않았기 때문에
좀 더 적합한 데이터셋을 사용하기로 하면서 트랜스포머 외에는 주제 및 데이터까지 각자 많은 부분에서 갈라짐
< 개인파트 >

한국어에서 영어로 번역하는 모델을 개발하고 싶었다
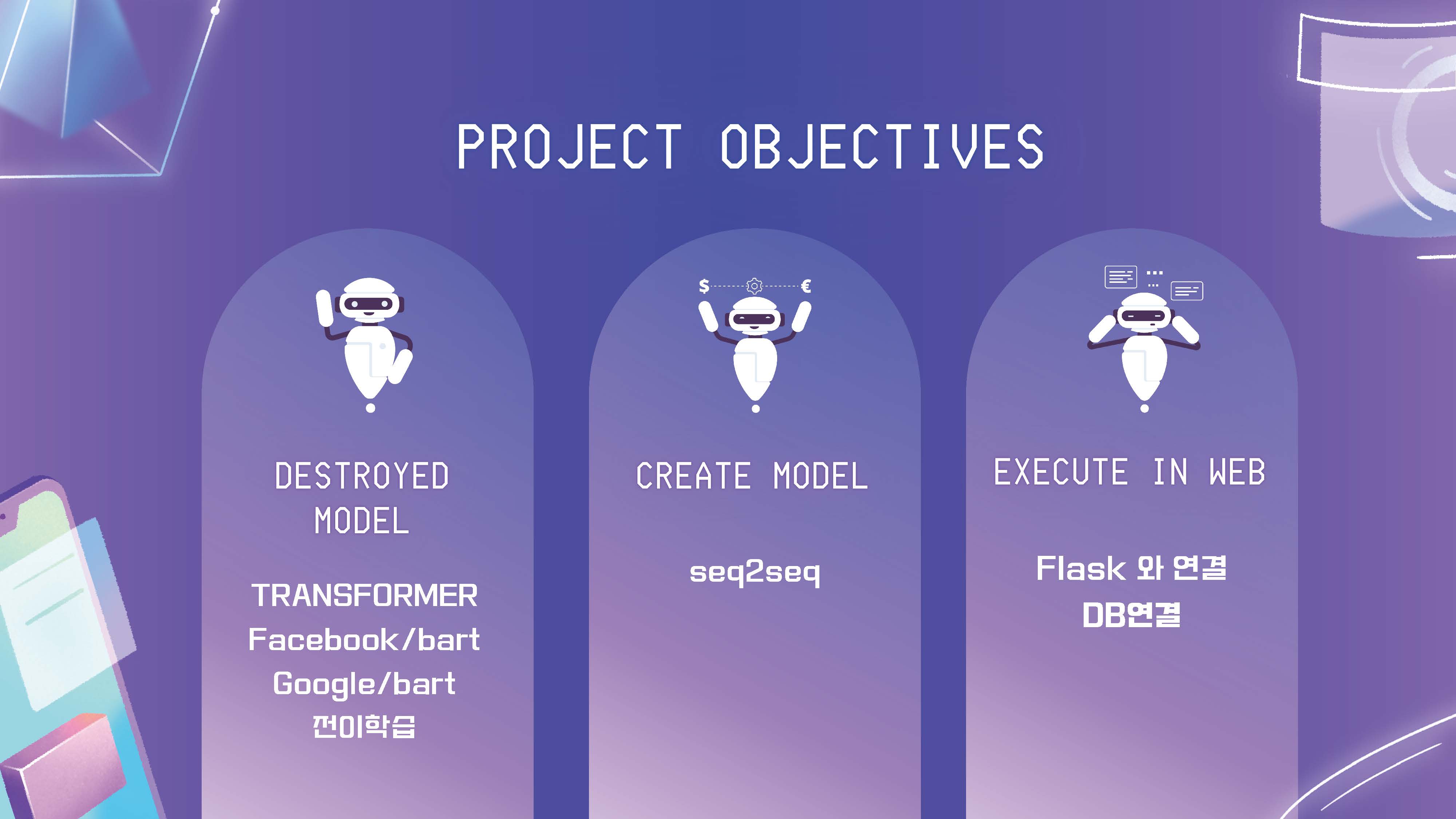
이 과정에서 다양한 모델을 다뤄보았고 실패한 기록이라고 봐도 무방하다
최종 모델은 seq2seq

내가 잡고 있던 목표는 기존의 라이브러리를 그대로 임포트 하지 않는, 코드를 쭉 짜서 돌려보는 모델이었다

총 3대의 컴퓨터에서 3개의 가상환경을 파괴하고 12개의 모델에서 실패했다

교재에 있던 트랜스포머 모델이 정상작동하는 지 13시간을 실행시켜본 결과
위와 같은 알 수 없는 문자만을 뱉어냈다.
이 중 예제 7.02~7.08 트랜스포머 모델 번역 결과.ipynb를 이용했다.

이 중 예제 7.15~7.17 BERT 모델 실습.ipynb와 구글링한 내용을 참고했는데 원문을 못 찾겠다.




그나마 결과물을 내놓는 녀석이라
100, 1,000, 10,000, 100,000, 200,000 행을 기준으로
5개 모델을 valid_loss 기준으로 스케쥴러의 patience 20으로 돌렸다
그러나 모두 100회 이상 돌질 않았다.

모든 모델에서 실패.
업적 달성.

눈물을 마시는 새의 두억시니 마냥 이상한 말만 하는 모델이 만들어졌다
심심한 장미를 콧구멍에--!!

트랜스포머는 일반 로컬 환경에서 건드릴 게 아닌 것 같다
데이터와 학습 자체가 훨씬 방대하게 진행해야할 것 같다.
그나마 얻은 점이라면 다양한 트랜스포머 모델들 구조를 이렇게 저렇게 만져보며 차이를 조금 익혔다는 것? 정도가 있겠다.
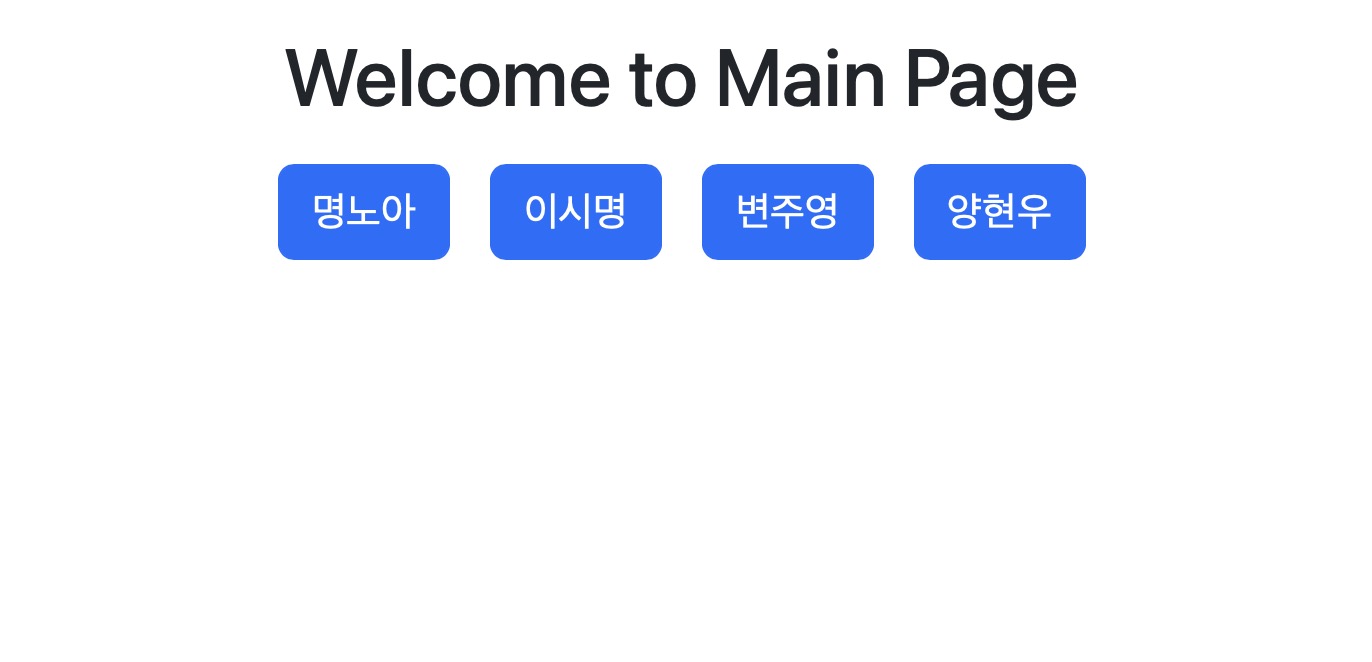
< WEB >

모델 1 : 100행 학습
모델 2 : 1,000행 학습
모델 3 : 10,000행 학습
모델 4 : 200,000행 학습

결과 : 외계어를 뱉고 있다.
