
내 파트만 이미지 업로드
< 공통파트 >

<표지>
조이름 : 조선왕조 씰룩쌜룩

목차텍스트
< 개인파트 >

개인 표지
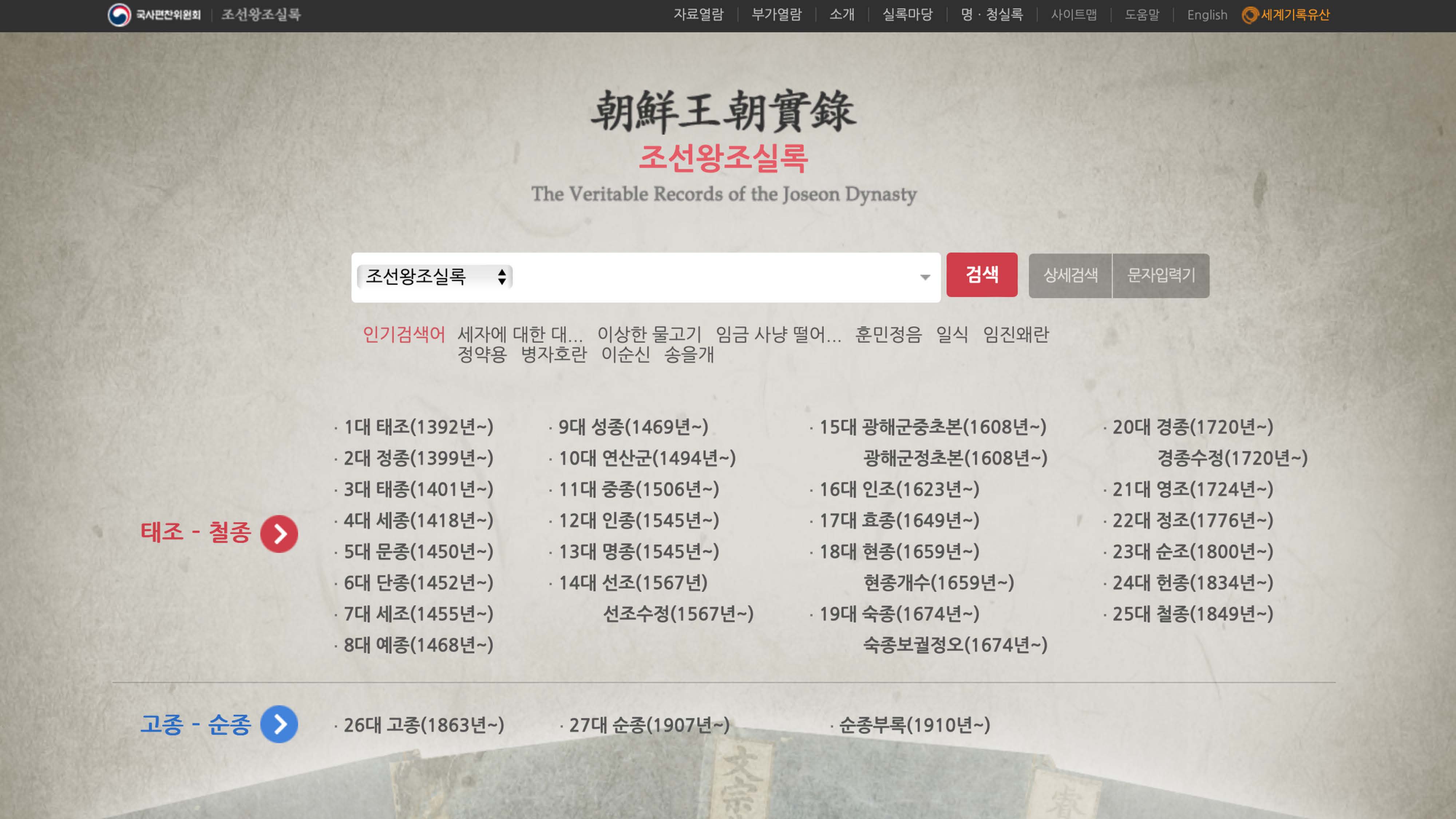
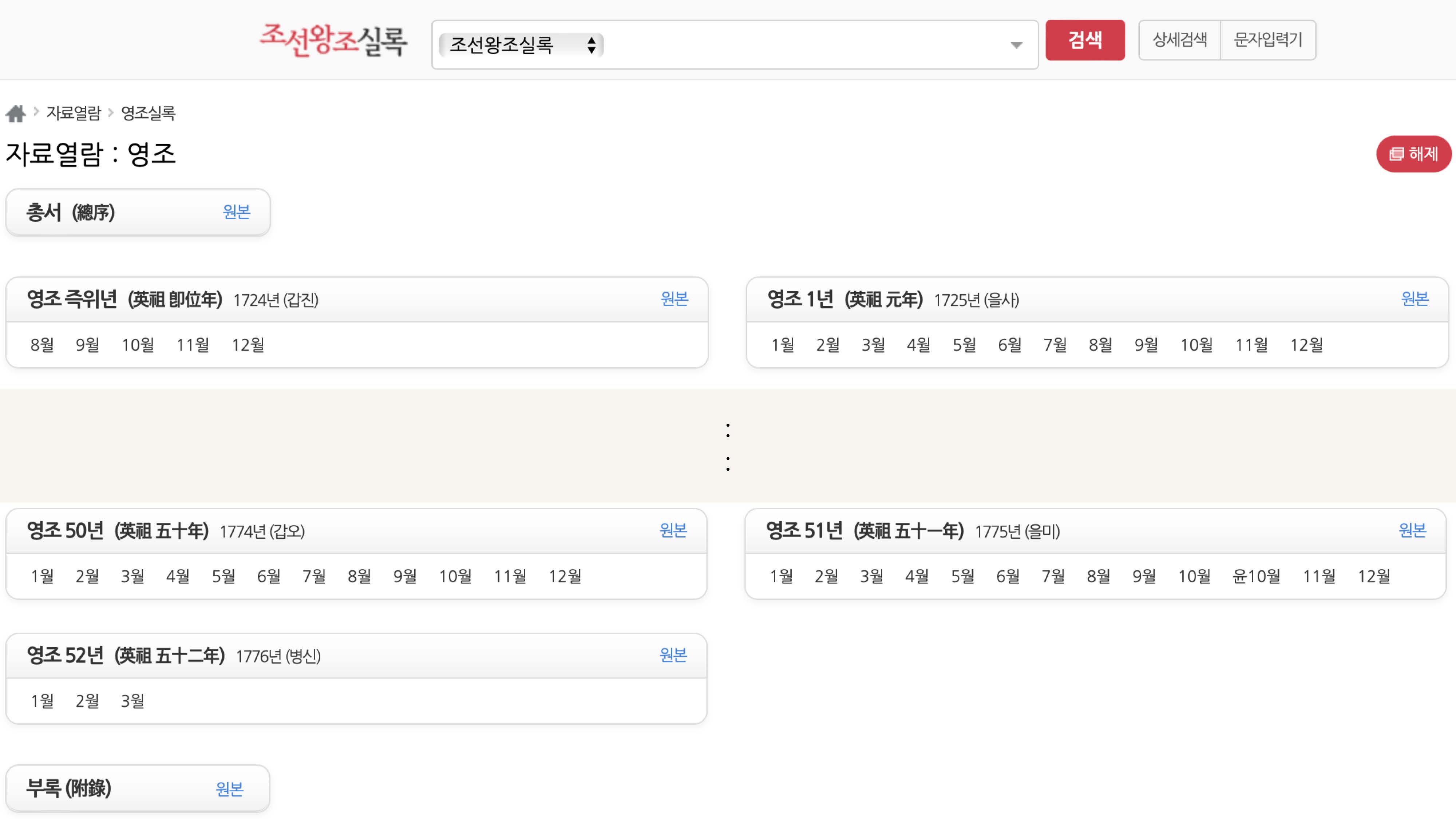
조선왕조실록 웹사이트
https://sillok.history.go.kr/main/main.do
태조에서 철종까지가 목표
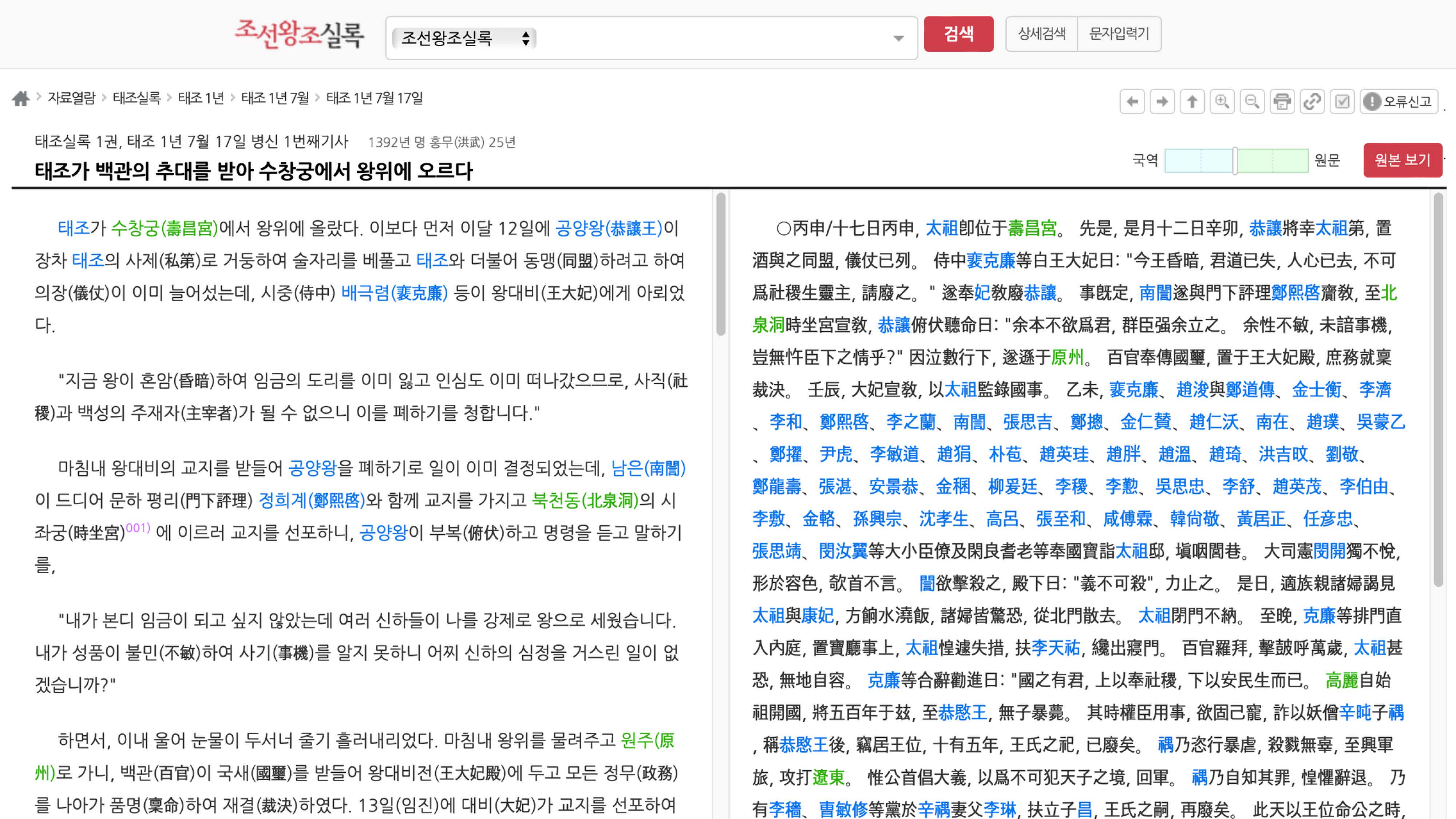
조선왕조실록 태조실록 페이지는 한글과 한자가 모두 나오고
팝업페이지는 원본 이미지까지 제공
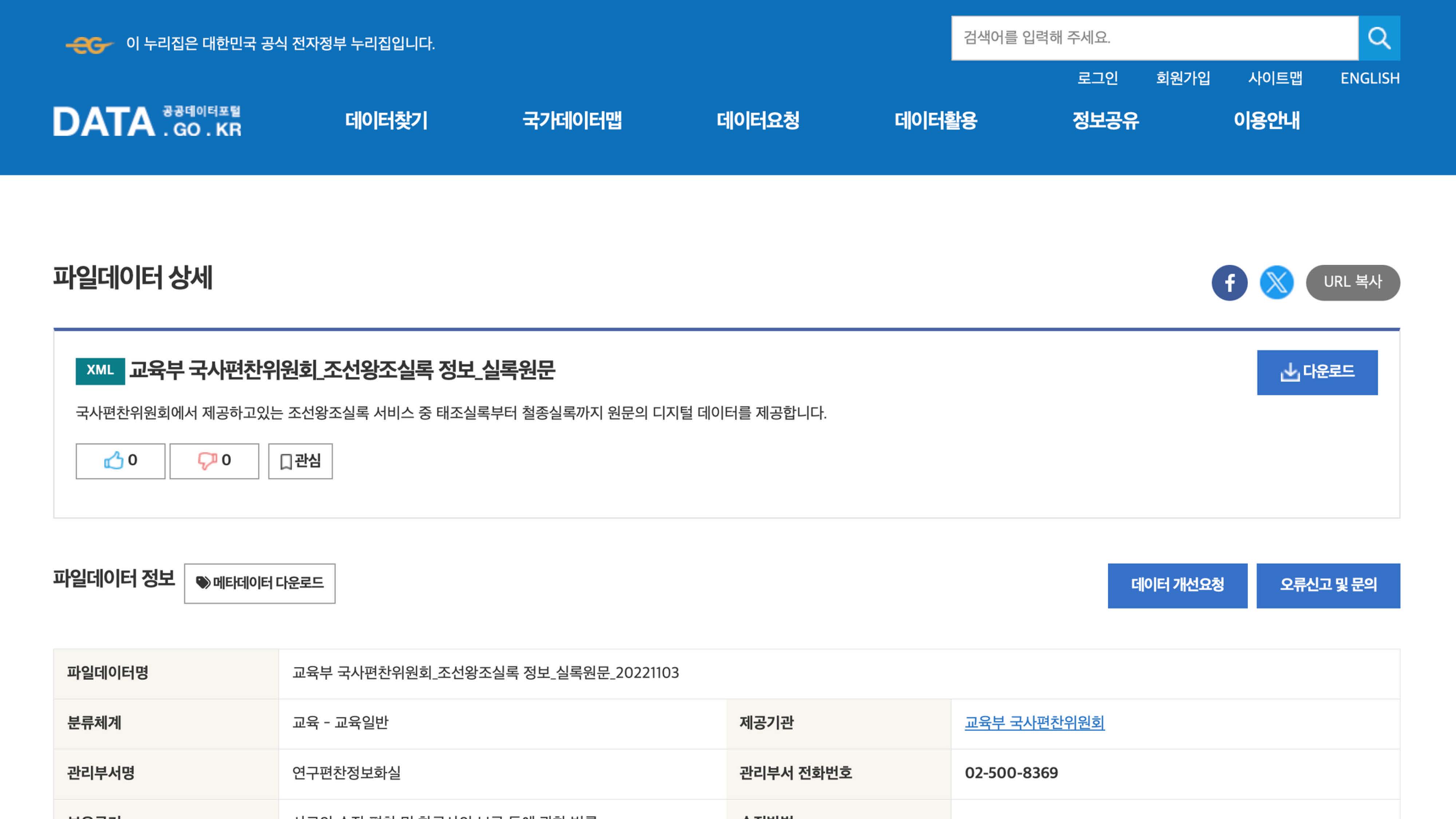
공공데이터포털에 공유된 실록원문 자료
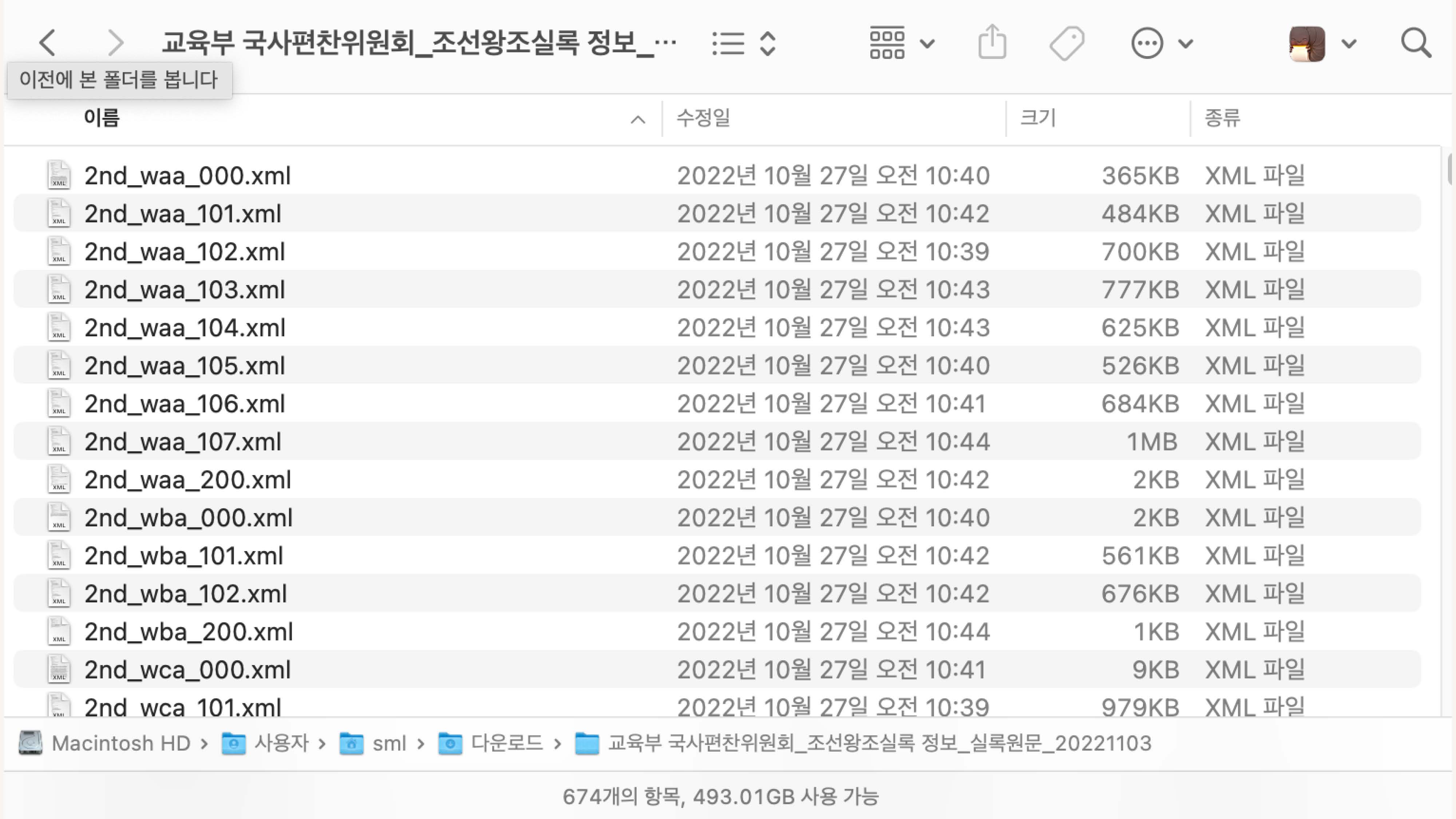
.xml 파일로 총 674개 파일로 되어있음

실제 .xml파일 내부.
xml태그를 이해하고 제거해 보았더니 원문파일이라 한자만 있어서 포기함
다시 웹사이트에서 크롤링하기로 결심
나라의 보물 도둑놈입니다
도메인을 분석하여 가져올 구문 분석
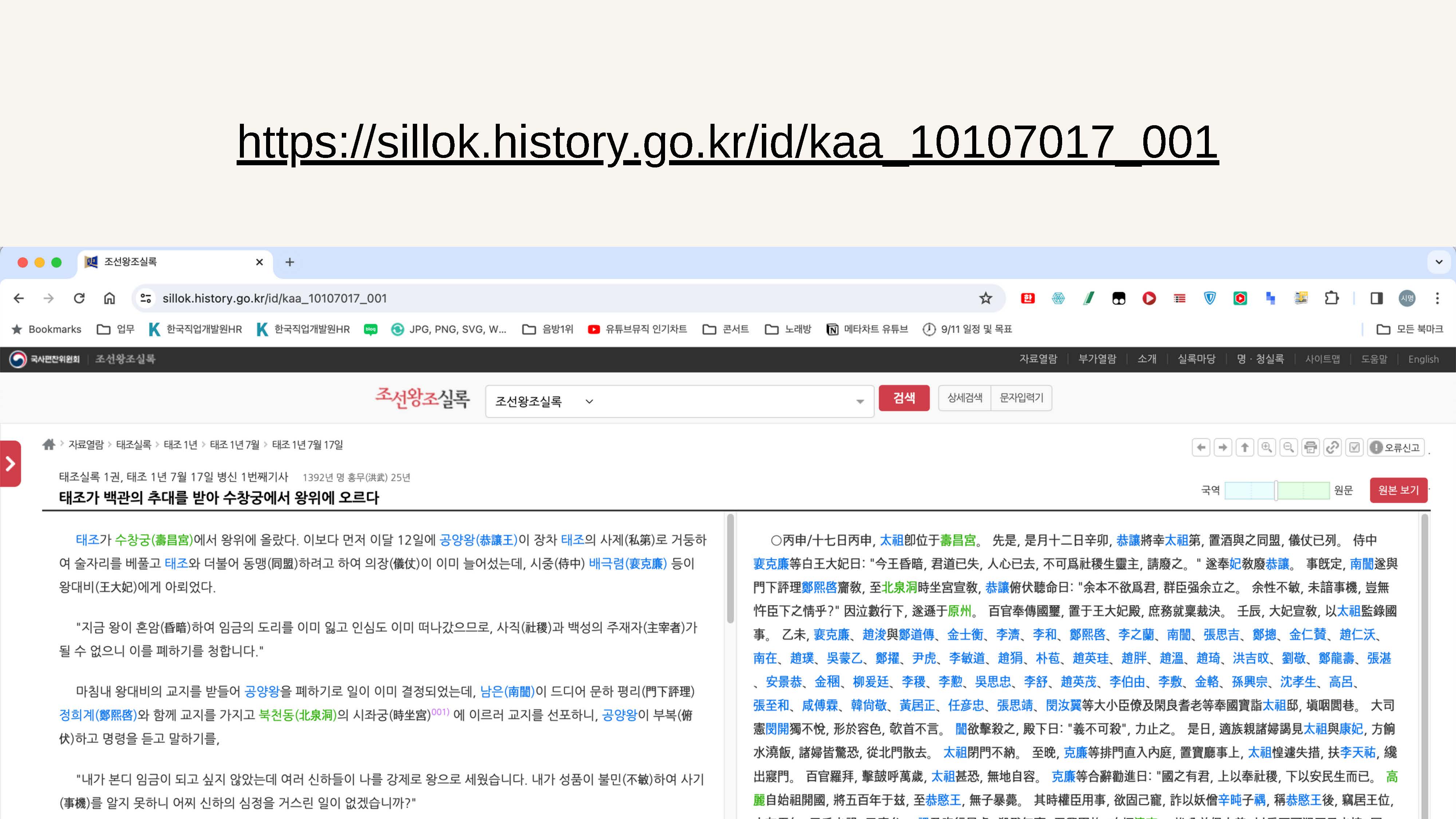
kaa_10107017_001
kaa
k : korea
a : a~y까지 순서대로 부여됨
a : 원본 a, 수정실록 b
10107017
1 : 고정
01 ~ NN : 재위년부터 마지막해까지 증가
07 = 01~12 : 월
0 : 기본 0, 윤달은 1
17 = 01~28? : 일 (음력이라 28일?정도까지 있음)
001
001 ~ NNN : 하루에 여러기사가 있는 경우 001부터 시작해서 점차 증가
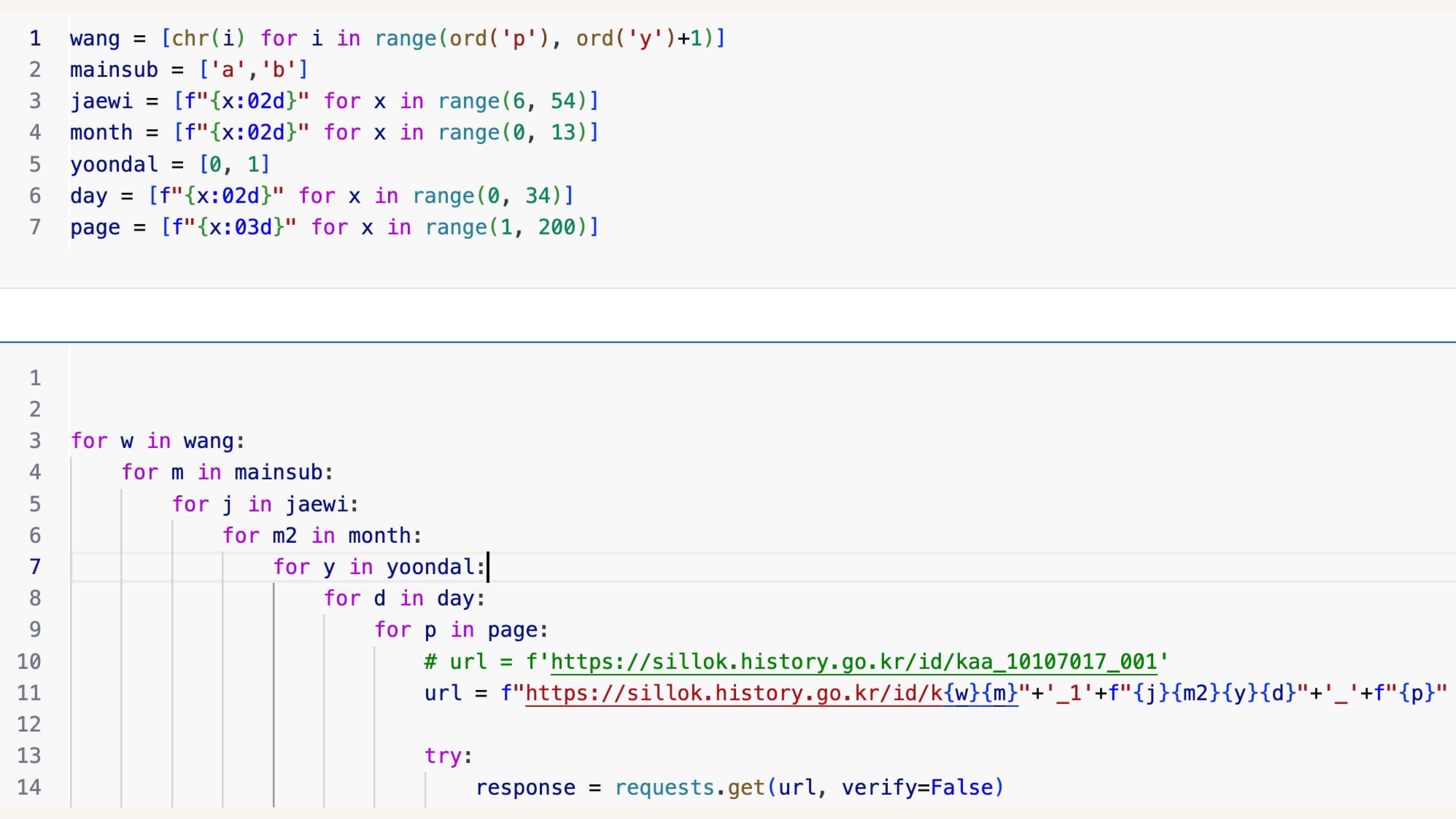
중간중간 탈출문을 만들진 못해서
마지막 페이지에서만 try: except:로 최소한으로 돌림
각 왕별로 돌리고 멈추고 돌리고 멈추고 해서 헛도는 시간을 단축
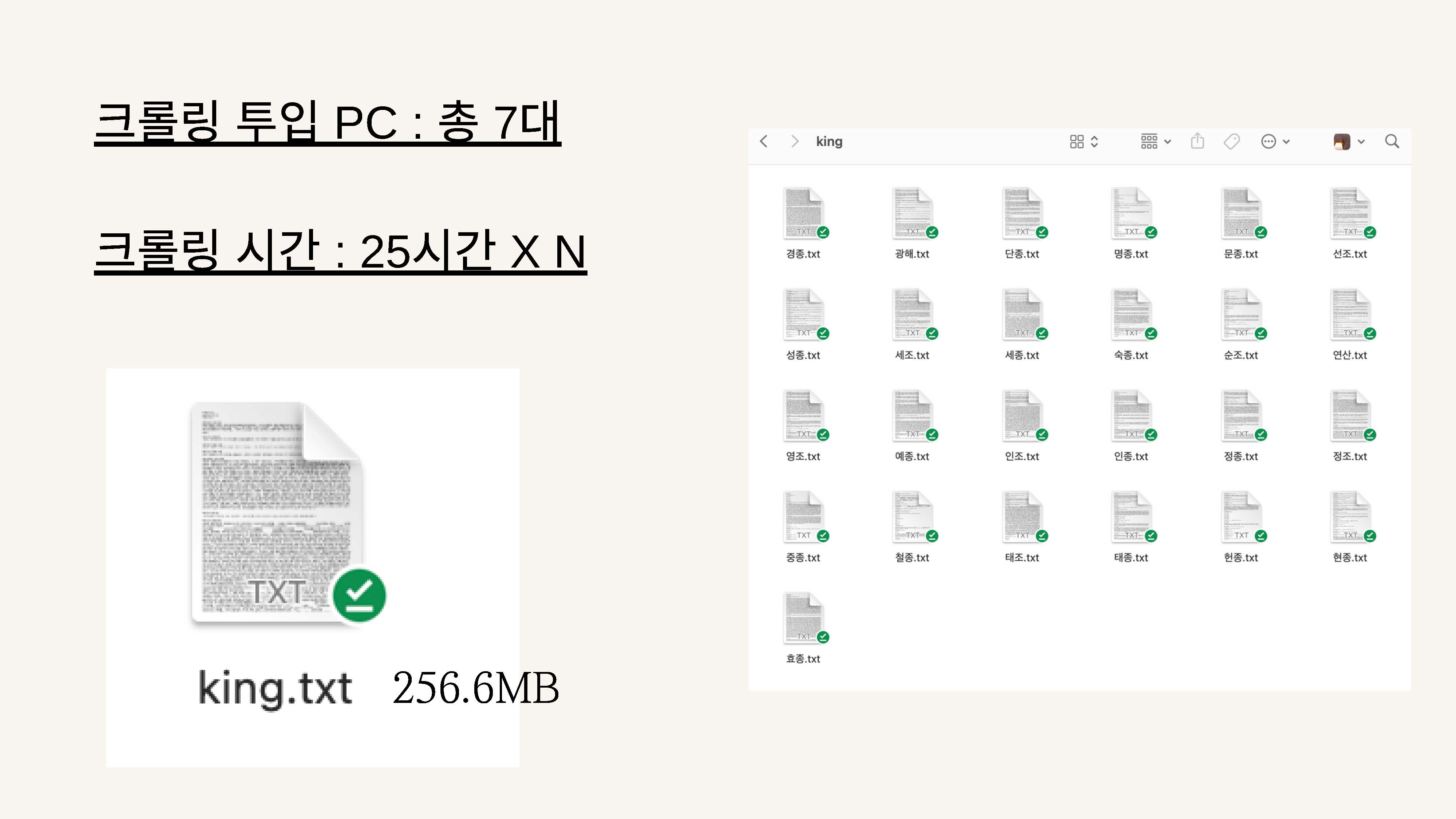
크롤링 총 25시간, PC 7대로 완료
DDOS로 인식하지 않아주셔서 감사합니다 국사편찬위원회
학교 IP라 용서받은걸까
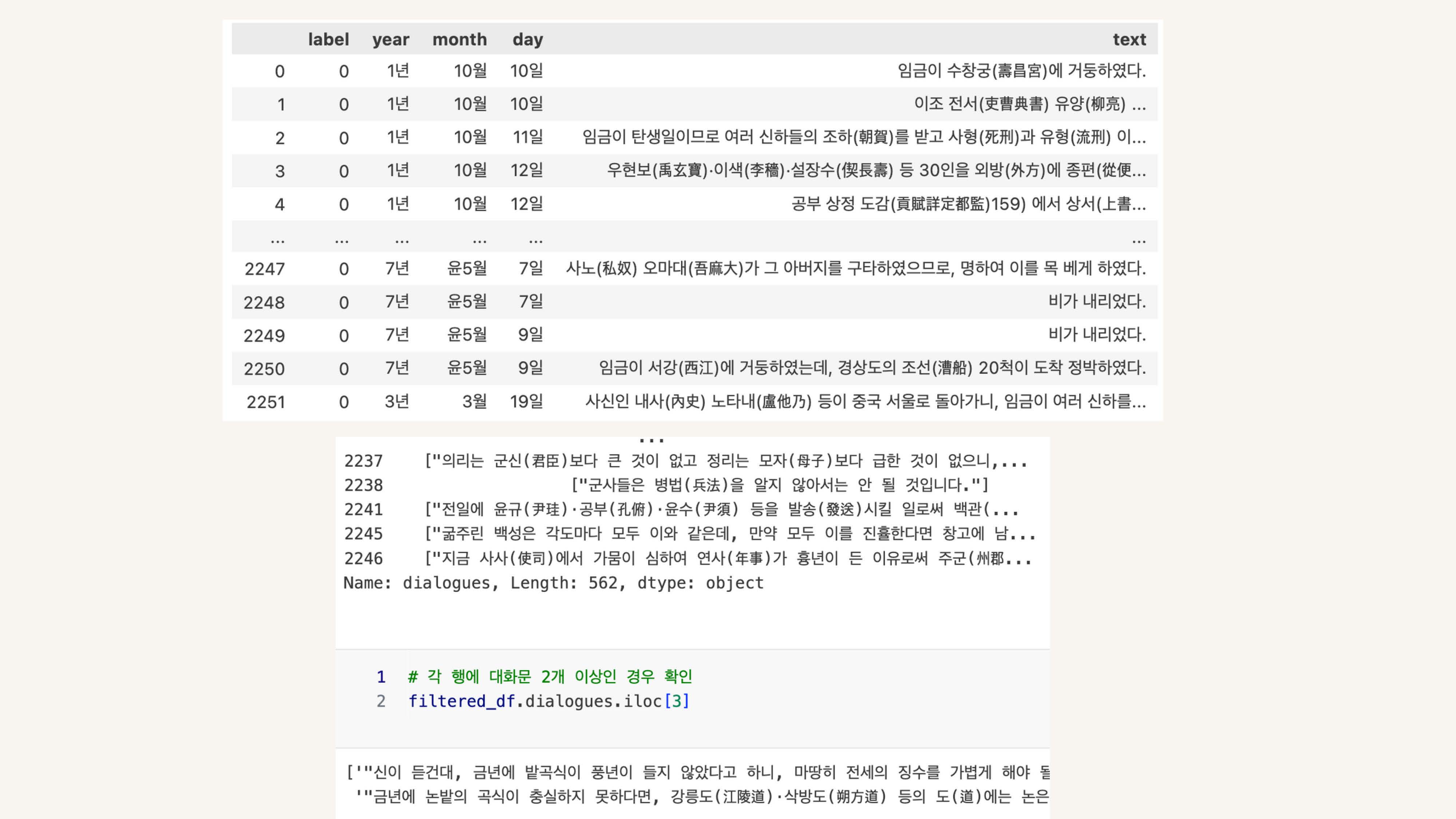
모델 제작 전처리
txt를 csv로 팀원이 바꿔주고 이 내용을 DF로 불러와서 작업
text 컬럼에는 하루치 모든 기사가 들어있음
임금님과 신하의 대사를 구분하는 모델을 만들고 싶었기 때문에
정규식을 통해 대사문만 가져옴
2개 이상 있는 경우도 누락없이 가져왔는지 확인

한국어 언중으로서 직접 라벨링 하는 것으로 결정
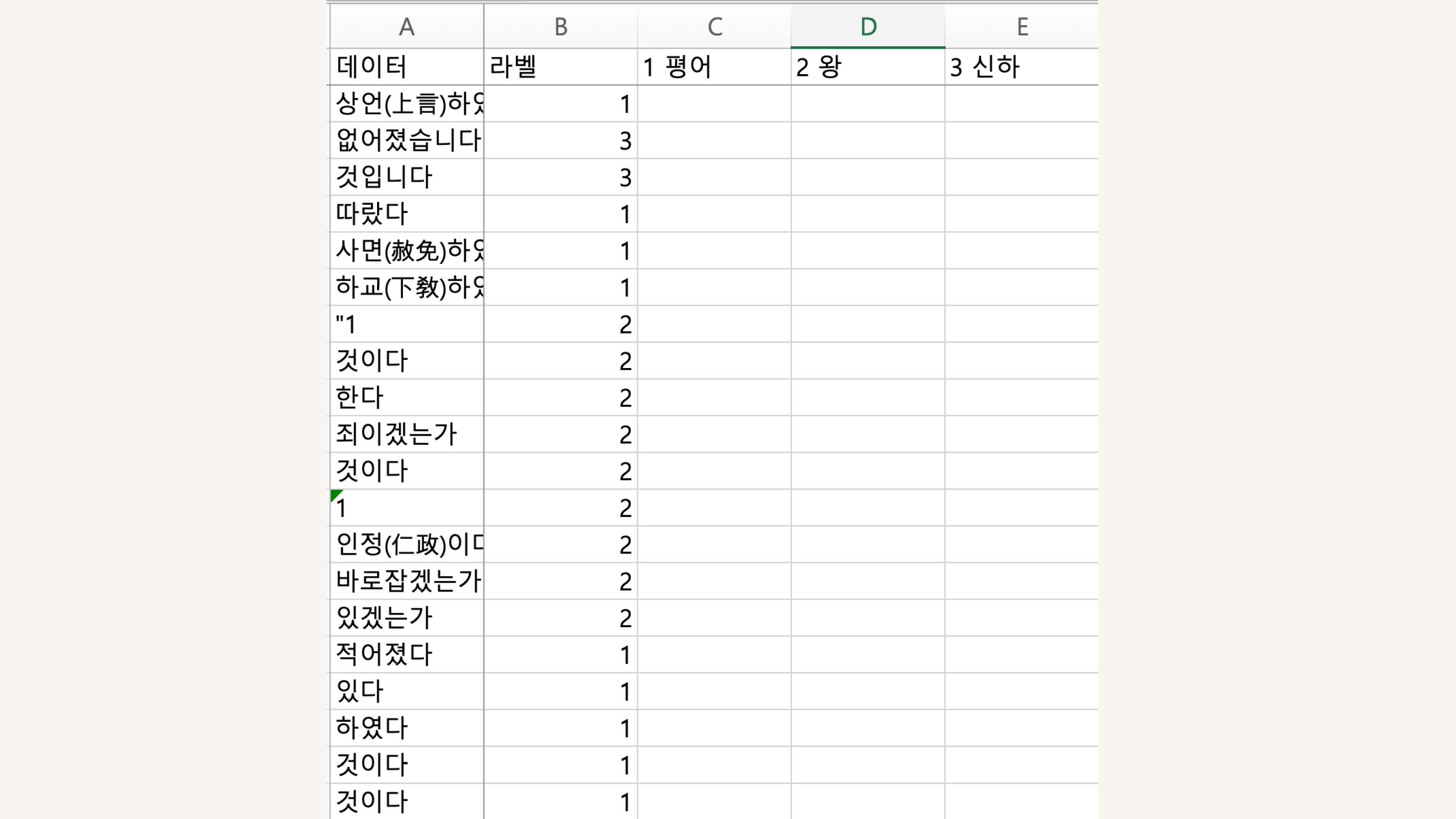
태조 데이터인데 약 800개 정도가 나옴 CSV에서 라벨링
해설에 해당하는 내용은 평어, 임금님의 하대, 신하의 존대 라고 생각하고 진행

?

조선왕조의 지엄함을 느껴라
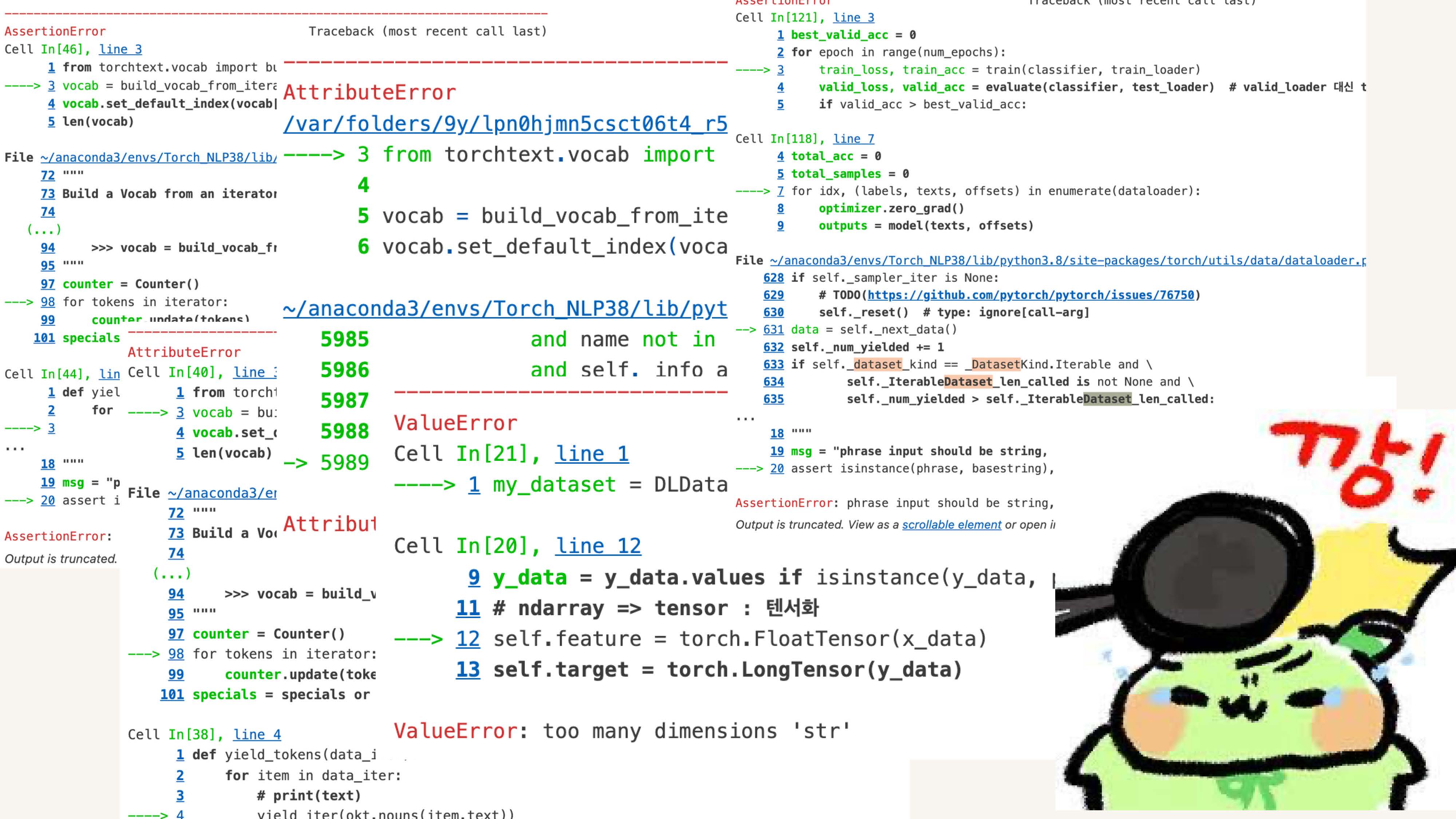
너무 많은 데이터에 토크나이저, 데이터셋, 데이터로더 할 것 없이 다들 오류를 뿜음..
아직 딥러닝 너무 어렵다 하

발표날 오전의 내 멘탈 상황
최종 모델이 나오면 이걸 해보고 싶었는데 하지 못해서 아쉬움

발표 직전 준비할 때의 내 기분

사실 아님
