I. ABSTRACT
비디오 장면 분할은 긴 분량의 비디오에서 의미론적으로 일관된 경계를 검출하는 것을 목표로 하며, 이는 low-level의 시각적 신호와 high-level의 서사 이해 사이의 간극을 메우는 작업이다. 그러나 기존 방법론들은 주로 인접한 셧간의 시각적 유사성에 의존하기 때문에, 서사적 전환이 시각적 변화와 일치하지 않는 경우 장면 경계를 정확히 식별하는데 어려움을 격는다.
본 논문에서는 제작 수준의 메타데이터, 구체적으로는 장르 컨벤션과 샷 길이 패턴을 비디오 장면분할에 통합하는 새로운 접근 방식을 제안한다. 본 연구의 주요 기여는 다음과 같다.
- 텍스트 기반 장르 정의를 의미론적 sementic priors로 활용하여 자기지도 학습 과정에서 샷 수준의 표현 학습을 가이드 함으로써 서사적 일관성을 더 잘 포착할 수 있게 합니다.
- 경험적 길이 통계에 기반하여 짧은 샷에 우선순위를 두는 duration-aware anchor selection strategy를 도입하여 pseudo-boundary 생성 품질을 개선한다.
- 추론시 긴 샷을 세부 세그먼트로 나누어 시간적 모델링을 향상시키는 test-time shot splitting strategy를 제안한다.
II. INTRODICTION
긴 분량의 비디오 콘텐츠를 이해하기 위해서는 근저에 깔린 서사를 반영하는 의미있는 단위로 구조화하는 작업이 필요하다. 짧은 클립과 달리 영화, TV, 다큐멘터리와 같은 서사 중심의 비디오는 서사적 일관성을 유지하는 개별 SCENE으로 자연스럽게 조직되어 있다. 이러한 콘테츠를 장면 단위로 분할하는 것은 콘텐츠 기반 검색, 요약, QA, 등 광범위한 다운스트림 태스크를 지원하는 유용한 추상화 기능으로 제공한다. 그러나 현재의 접근 방식들은 장면 경계를 식별하기 위해 주로 visual-features를 사용하며, 이로인해 시각적 불연속성 없이 서사적 전환이 일어날때 오류가 발생한다. 이러한 한계는 순수하게 시각적인 접근 방석을 넘어 더 풍부한 문맥 정보를 활용할 수 있는 방법론이 필요함을 시사한다.
전문적인 비디오 제작 과정은 편집 패턴, 카메라 움직임, 시간적 구조와 같이 서사적 전환을 알리는 의도적으로 설계된 요소들을 통해 풍부한 문맥적 단서를 제공한다. 이러한 제작 요소 중 장르 컨벤션과 샷 길이 패턴은 컴퓨터를 이용한 장면 분석에 특히 유망한 신호이다. 하지만 이러한 신호를 활용하는 데는 몇가지 어려움이 있다. 장르 정보는 일반적으로 비디오 전체 수준에서만 제공되는 반면, 샷 길이 패턴은 장르와 제작 스타일에 따라 크게 변한다. 이를 해결하기 위해서는 메타데이타의 내재적 변동성과 granularity의 불일치를 처리하면서 제작 메타 데이터를 장면 분할에 통합할 수 있는 새로운 방법이 필요하다.
본 논문은 장르 컨벤션을 특스트 설명으로 인코딩하고, 이를 샷 표현 학습을 위한 의미론적 사전 정보로 사용할 것을 제안한다. 프레임워크는 사전 학습 단계에서 이 장르 정보를 통합하여 샷 수준의 표현을 강화한다.
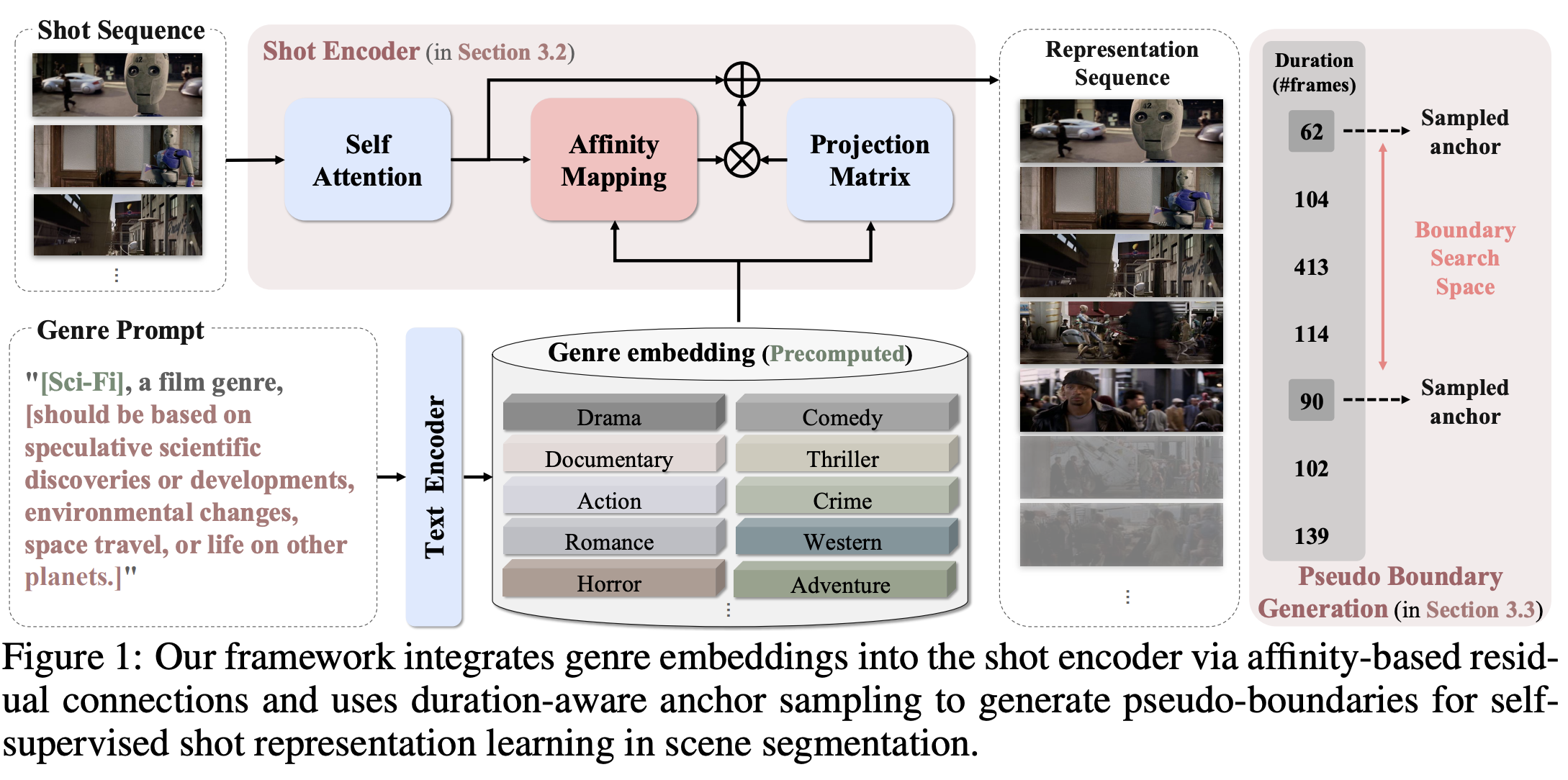
III. Related Work
3.1 Video Scene Segmentation
비디오 장면 분할은 일반적으로 기본 시간 단위를 식병하기 위해 shot boundary detection부터 시작한다. 전통적인 방법들은 색상 히스토그램이나 모션 패턴 같은 low-level 시각 특징을 사용하여 연속된 샷들을 장면으로 그룹화한다. 그러나 이러한 특징 기반 접근 방식은 종종 샷 간의 high-level 의미론적 관계를 포착하는데 실패하여 복잡한 서사 콘텐츠에서의 효과가 제한된다.
MovieNet 공개는 여러 영화 장르에 걸친 주석을 제공하여 장면 분할 연구를 위한 실질적인 벤치마크를 제공했다. 이 데이터셋을 활용한 지도 학습 접근 방식은 강력한 성능을 달성하지만 방대한 수동 주석을 요구하여, 대규모 언레이블 비디오 컬렉션에 적용하기 어렵다는 한계가 있습니다. 이 한계를 극복하기 위해, 최근 연구들은 언레이블 비디오를 활용하는 자기지도 학습 프레임 워크를 채택하고 있다. 이러한 접근 방식은 전형적으로 pretext task에 의해 생성된 pseudo-boundary를 사용하여 대규모 언레이블 데이터 셋에서 샷 인코더를 사전학습하고, 더 작은 레이블 데이터셋에서 파인튜닝하는 2단계 패러다임을 따른다.
자기지도 장면 분할을 위해 샷 유사도, 장면 일관성, 메타데이터 기반 영화 유사도를 바탕으로 한 다양한 pretext task가 제안됩니다. 대표적으로 BaSSL은 주어진 샷 시퀸스의 양 끝에 위치한 두 개의 고정된 앵커 샷을 사용하여 의사장면 경계를 생성하는 방법을 소개한다. 이후 모델은 시퀸스 내 샷 간의 관계를 인코딩하여 문맥적 표현을 학습한다. 후속 연구들은 장거리 샷 간 관계와 다중 스케일 시간 문맥을 통합하여 이 프레임워크를 확장했다. 이러한 방법들이 유망한 결과를 보여주었지만, 대부분 주로 시각적 및 시간적 단서에 의존하며 의미론적 가이드를 위해 포괄적인 제작 수준의 메타데이터를 탐색하는 데는 한계가 있다.
메타데이터를 활용한 예로, Movie2Scenes는 장면 그룹화를 위해 동시 시청 패턴, 장르 레이블, 시놉시스 텍스트와 같은 메타 데이터 태그의 사용을 탐구한다. 구체적으로 이 방법은 이러한 메타 데이터를 사용하여 영화 수준의 유사도를 측정하고, 유사한 태그를 가진 영화 전번에 걸쳐 긍적장면 쌍을 구성하여 대조 학습 목적 함수를 훈련한다. 이 연구는 영화간 메타데이터 비교에 중점을 두어, 장면 수준 분석에 메타 데이터를 활용할 수 있는 잠재력을 보여주었다.
VSS-MGP는 다중 모달 신호를 사용하여 가장 빈번한 4개 장르에 대한 분류 모델을 훈련시킨 다음, 샷 수준의 장르 예측 분포를 기반으로 인접한 샷 간의 유사도를 계산하여 장면 분할을 수행한다. Movie-CLIP은 원래 장르 예측을 위해 설계된 다중 모달 융합 아키텍처를 제안하며, 이 구조가 장면 분할에 적용될 수 있음을 보여주었다. 그러나 VSS-MGP는 샷 단위의 장르 예측이 필요하며, Movie-CLIP은 장면 분할을 위해 장르 정보를 명시적으로 활용하지 않는다.
시각적 특징외에도 샷 길이 패턴은 영화 연구에서 서사 구조의 지표로 인식되어 왔다. 그러나 장르와 제작 스타일에 따라 샷 길이 분포의 변화가 상당히 크기 때문에 일관된 학습 전략을 개발하는 것이 까다로우며, 이는 adaptive 접근 방식의 필요성을 유발한다.
3.2 Long-Form Video Understanding
비디오 질의응답 및 서사 요약을 포함한 긴 비디오의 이해는 확장된 시간 범위에 걸쳐 의미론적 구조를 모델링해야한다. 이러한 태스크들은 프레임 수준의 분석보다는 장면이나 이벤트와 같은 더 높은 수준의 서사 단위에서 작동하는 것이 일반적이다. 장면 분할은 시간적 추론 및 콘텐츠 구성을 위한 의미론적으로 일관된 세그먼트를 정의함으로써 이러한 태스크에 유용한 구조적 단위를 제공할 수 있다.
Movie-Chat-1K 및 TVQA와 같은 긴 비디오 이해를 위한 최근 데이터셋들은 멀티모달 추론 태스크를 지원하기 위해 자막과 대화를 포함한 텍스트 주석을 통합한다. 그러나 이러한 데이터셋의 상당수는 명시적인 장면 경계 주석이 부족하여 장면 수준의 비디오 구성을 연구할 기회를 제한한다. 예를 들어, Movie-Chat-1k는 멀티 모달 QA 태스크에 중점을 두며 장면 경계 주석을 포함하지 않는다.
IV. Method
4.1 Task Definition
영화 및 TV쇼와 같은 서사 중심의 비디오는 일반적으로 프레임, 샷, 장면, 전체비디오라는 4단계 계층 구조로 구성된다. 샷은 단일 카메라에 의해 중단 없이 촬영된 연속된 프레임 시퀸스를 의미하며, 저수준의 시각적 단서를 사용하여 안정적으로 식별할 수 있습니다. 반명 장면은 동작, 장소, 시간의 연속성을 유지하는 여러삿으로 구성된 의미론적으로 응집력 있는 단위이며, 서사적 스토리텔링의 핵심 구조 요소 역할을 한다.
샷 경계가 종종 시각적 불연속성과 연관되는 반면, 장면 경계를 검출하려면 주제의 일관성, 장소의 변화, 시간적 연속성과 같은 고수준의 의미론적 관계를 이해해야한다. 비디오 장면 분할은 주어진 샷이 장면의 끝을 표시하는지 여부를 결정함으로써 이러한 경계를 식별하는 것을 목표로한다. 이는 각 샷에 대한 이진 분류 문제로 공식화될 수 있으며, 모델은 경계 예측을 수행하기 위해 시각적 특징을 주변 샷들의 문맥 정보와 통합해야 한다.
형식적으로 비디오는 개의 샷으로 구성된 시퀸스 와 대응하는 이진 경계 레이블 로 표현될 수 있다. 여기서 는 가 장면의 끝을 표시하는지 여부를 나타낸다. 각 샷 샷 는 샷 인코더 에 의해 특징 벡터 로 변환된다. 이러한 샷 표현들은 이어지는 섹션에서 설명할 보조 의미론적 신호에 의해 강화되어 경계 예측을 위한 입력으로 사용된다.
4.2 Genre-Guided Shot Representation
장르 컨벤션은 장면의 시각적 및 시각적 요소에 영향을 미치며, 잠재적으로 장면 구조를 이해하기 위한 의미론적 문맥을 제공한다. 샷들 전반에 걸쳐 시각적 외형은 다양할 수 있지만, 장르 컨벤션은 장면 내의 서사적 일관성을 식별하는 데 도움이 될 수 있는 일관된 의미론적 신호를 제공할 수 있다. 그러나 대부분의 영화가 여러 장르 태그와 연관되어 있어 각 샷이나 장면에 단일 장르를 할당하기 어렵기 때문에 장르를 직접 적용하는 것은 쉽지 않다.
이를 해결하기 위해, 자기지도 사전학습 단계에서 장르 컨벤션을 soft semantic prior로 활용한다. 각 장르에 대한 특징적인 시각적 서사적 설명을 통합하여 IMDb 정의에 기반한 장르별 텍스트 프롬프트를 구성한다. 이 프롬프트들은 CLIP의 텍스트 인코더를 사용하여 임베딩 벡터로 인코딩되어 장르 임베딩 세트 를 형성한다.
(여기서 는 장르 카테고리의 수, 는 임베딩 차원).
샷 인코더는 사전 계산된 장르 임베딩을 ViT 아키텍처 내에 고정된 파라미터로 통합한다.
ViT 레이어 내에서 우리는 코사인 유사도를 사용하여 시각적 토큰 특징 와 저장된 장르 임베딩 간의 유사도를 계산한다. 결과로 도출된 유사도 행렬 는 시각적 토큰에 대한 장르의 관련성을 나타낸다. 그 다음 장르 임베딩은 projected되고 잔차 연결을 통해 원래의 시각적 특징과 통합한다.
여기서 는 통합 전에 가중치가 적용된 장르 정보를 투영한다. ViT 아키텍처를 따라, 강화된 토큰 특징 는 집계되어 최종 샷 수준 표현 를 형성한다.
- 유사도 행렬 연산:
-: Query (비디오 샷의 각 패치 토큰)
-: Key (21개의 장르 텍스트 임베딩)
-: 각 시각 패치가 21개 장르 중 어느 장르와 가장 높은 코사인 유사도(내적)를 가지는지 계산합니다.
-로 나누는 것은 스케일 점곱 주의(Scaled Dot-Product Attention)의 표준 정규화 방식이며, Softmax를 통해 합이 1이 되는 확률 분포 를 얻습니다. 즉, 특정 시각 토큰이 'SF 장르 60%, 액션 장르 30%, 로맨스 10%'의 특징을 가진다고 Soft(부드럽게) 할당합니다.
- 잔차 연결 및 특성 주입:
-: Value ()에 어텐션 가중치 를 곱하여 각 시각 토큰에 주입할 '장르 특징 벡터'를 만듭니다.
-: 차원 축소/변환을 위한 학습 가능한 가중치 행렬입니다. (텍스트 임베딩 공간의 정보를 시각 임베딩 공간에 맞게 선형 변환)
-최종적으로 기존 시각 특징 에 장르 정보를 더해주는 잔차 연결() 구조를 취하여 시각적 원본 정보의 손실을 막습니다.
3.3 Duration-Aware Pseudo-Boundary Generation
특히 BaSSL과 같은 기존 pseudo-boundary 생성 방법들은 시퀸스 양 끝점에 고정된 앵커 위치를 사용하여 비디오 시퀸스 내의 다양한 시각적 패턴을 포착하는데 한계가 있다. 장면들이 일관된 샷 길이 패턴을 나타내며, 많은 장면들이 응집력 있는 서사 단위를 형성하는 더 짧은 샷들에 의해 지배된다는 점을 관찰했다. 이러한 통찰을 활용하기 위해, 고정된 끝점 선택 대신 짧은 샷에 우선순위를 두는 duration-aware 샘플링 전략을 도입학여 앵커 선택 메커니즘을 수정한다.
고정된 앵커를 선택하는 대신, 시퀸스 내 샷 길이의 역수에 기반하여 타겟 샷의 양쪽 하위 시퀸스에서 앵커 샷을 샘플링한다.
여기서 는 번째 샷의 길이를 나타내며, 은 하위 시퀀스의 총 샷 수이다. 그런 다음 동적 시간 워핑을 차용한 유사도 기반 접근법을 사용하여 이러한 앵커 샷들 사이의 가짜 경계 를 탐색한다.
여기서 는 샷 표현 간의 코사인 유사도, 는 타겟 샷의 인덱스, 은 각각 왼쪽과 오른쪽 앵커까지의 거리를 나타낸다. 이 과정은 입력 시퀀스를 두 개의 가짜 장면 시퀀스 S_i^l = {s_{i-L}, ..., s_{b^}}와 로 나눈다.
3.4 Test-Time Shot Split Strategy
훈련 방법이 샷 표현 학습을 향상시키지만, 실제 추론 과정은 샷 길이의 큰 변동성으로 인해 어려움에 직면한다. 긴 샷들은 단일 단위로 처리하기 어려운 여러 개의 의미론적 세그먼트를 포함할 수 있으며, 이는 시퀸스 기반 접근 방식에서 경계 검출 정확도에 잠재적으로 영향을 미칠 수 있다. 이 문제를 해결하기 위해, 모델을 재학습할 필요 없이 추론시에 긴 샷을 세분화하는 테스트 시간 샷 분할 전략을 제안한다.
길이가 (10초로 설정)인 임의의 샷 에 대해, 이를 동일한 길이의 세 개의 세그먼트로 분할하고 각각을 독립적인 샷으로 취급한다. 사전 추출된 키프레임이 사용 가능한 경우(예: MovieNet의 샷당 3개의 키프레임), 이들을 해당 세그먼트에 직접 할당한다. 그렇지 않은 경우 Uniform Temporal sampling을 사용하여 각 세그먼트에서 키 프레임을 추출한다.
이 전략은 전처리 수준에서 작동하므로 기존 아키텍처들과 호환된다. 경계 예측 후 검출된 경계들은 원본 시간 좌표로 다시 매핑된다.
V. MovieChat-SSeg Dataset
Video Scene Segmentation의 평가를 위해 수동으로 주석처리된 벤치마크인 MovieChat-SSeg를 제안한다. 이 테이터셋은 원래 긴 형식의 비디오-언어 테스크를 위한 쿠레이션된 1000개의 비디오 클립을 포함하는 공개 데이터셋 MovieChat-1k를 기반으로 구축되었다. 장면 분할 연구를 위한 테스트베드를 만들기 위해 장면 경계를 수동으로 주석 처리하여 이 클립들을 확장했다.

Annotation Process 장면 경계는 서사적 일관성, 장소 변화, 시간적 전환을 고려하여 확립된 가이드라인을 따르는 훈련된 작업자들에 의해 주석처리 된다. 이 주석 프로세스는 다중 단계로 이루어진다. 초기 독립적 주석 작업, 경계 모호 사례에 대한 논의, 그리고 의견 불일치에 대한 합의 도출. 모든 주석은 데이터셋 전체의 일관성을 보장하기 위해 검토된다.
Dataset Characteristics MovieChat-SSeg는 영화, TV, 다큐멘터리를 아우르는 다양한 콘텐츠 유형을 포함함으로서 기존 벤치마크들을 보완한다. 이러한 콘텐츠의 다양성은 서로 다른 서사 구조와 편집 스타일에 걸친 평가를 가능케한다. 이 다양성은 다양한 편집 스타일과 스토리텔링 접근법에 걸쳐 장면 분할 방법론을 평가할 수 있게 한다.
데이터셋은 비디오당 여러장면 전환을 포착하면서도 효율적인 주석 작업을 가능하게 하는 집중된 세그먼트(평균 7.4분)로 구성된다. 그러나 이렇게 짧은 세그먼트에 집중하는 것은 전체 길이 콘텐츠에 존재하는 장기적인 서사 패턴을 포착하지 못할 수도 있다는 한계가 있다.
향후 연구를 지원하기 위해 주석 가이드라인 및 평가 프로토콜과 함께 MovieChat-SSeg를 공개적으로 배포한다.
VI. Evaluation
6.1 Dataset and Evaluation Metrics
pre-traing을 위해 1100편의 영화가 포함된 MovieNet을 사용한다. 지도 학습 및 평가를 위해서는, 훈련 190, 검증 64, 테스트 64 분할을 따라 장면 경계 주석이 포함된 318편의 영화로 구성된 Movie-SSeg 하위 집합을 활용한다. 모델의 일반화 능력을 평가하기 위해, BBC 데이터셋과 새롭게 제안하나 MovieChat-SSeg 데이터셋 모두에서 제로샷 평가를 수행한다.
shot-level classification을 위해 AP, AUC-ROC, F1점수를 사용하고 Sequence-level segment alignment를 위해 mIoU를 사용하여 모델 성능을 평가한다.
6.2 Training Strategy
이전 연구들을 따라, 샷 인코더, 문맥 인코더, 그리고 예측 헤드로 구성된 모듈식 아키텍처를 채택한다. 문맥 인코더는 샷 간의 temporal dependencies를 모델링하고, 예측 헤드는 이진 장면 경계 예측을 출력한다. 사전 학습 동안 샷 인코더는 pseudo-boundaries를 사용하여 최적화된 후 fine-tuning 과정에서는 동결되며, 파인튜닝시에는 문맥 인코더와 예측 헤드만 업데이트 된다.
사전학습 단계어서 두 가지 목적 함수를 사용한다. 첫째, InfoNCE에 기반한 대조 손실을 적용한다. 여기서 의사 장면 내 샷들의 평균 표현을 scene-level 특징으로 간주하고, 이를 동일한 장면 내의 앵커샷과 쌍을 이루게 한다.
여기서 는 앵커 샷 표현을, 는 의사 장면의 평균 특징을 나타낸다. 과 은 각각 네거티브 샷 표현과 네거티브 의사 장면 특징을 나타낸다. 각 샷 시퀀스는 인덱스 b^의 의사 경계에 의해 두 개의 의사 장면으로 나뉘므로, 두 세그먼트 모두에 대해 대조 손실을 계산한다: . 여기서 과 은 각각 왼쪽 및 오른쪽 의사 장면에 대한 앵커 표현이다\bar{e}l = \text{avg}(e_l, ..., e{b^})와 는 각 세그먼트의 평균 장면 수준 특징을 나타낸다.
둘째, 의사 경계 샷과 주어진 시퀸스에서 무작위로 선택된 non-boundary 샷을 구별하기 위해 binary-cross entropy loss를 적용한다.
여기서 와 은 문맥 인코더로부터 얻은 의사 경계 및 비경계 샷의 context-aware 샷 표현을 나타낸다. 함수 는 예측 헤드로, 입력 표현을 경계일 확률로 매핑한다. 사전 학습 단계의 전체 목적 함수는 의사 경계 예측을 위한 대조 손실과 이진 교차 엔트로피 손실의 선형 결합으로 정의된다.
파인튜닝 동안에는 표준 binary-cross entropy loss를 사용하여 장면 경계 레이블을 바탕으로 문맥 인코더와 예측 헤드를 훈련하다.
여기서 는 번째 샷의 문맥 인식 표현이고 는 실제 장면 ground truth이다. 추론 시에는 경계 확률 가 0.5 이상인 경우 해당 샷을 장면 경계로 예측한다.
6.3 Implementation Details
샷 인코더 백본으로 ViT-B/32를 사용하고 OpenCLIP 가중치로 초기화하여, 224 X 224 해상도의 이미지를 32 X 32패치 크기로 처리한다. 사전 학습된 ViT 백본 가중치는 동결하고, 장르 통합 모듈()과 최종 MLP 분류 헤드만 학습한다. 이전 연구들을 따라, IMDb의 텍스트 정의가 포함된 21개의 장르 카테고리를 사용하며 OpenCLIP 텍스트 인코더를 사용하여 인코딩한다. 시퀸스 수준 경계 예측을 위해, 768은 은닉 차원을 가진 2층 BERT 아키텍처를 스크래치부터 훈련하여 적용한다.
훈련은 2단계 전략을 채택한다. 사전 학습 동안 배치 크기 256, 기본 학습률 0.3으로 20 에폭 동안 샷 및 문맥 인코더를 훈련합니다. 파인튜닝은 배치 크기 1024로 20 에폭 동안 수행된다. 옵티마이저는 Adam을 사용하며, 학습률은 , 모멘텀은 0.9이다. 모든 모델은 8개의 A100 GPU에서 훈련된다.
6.4 Comparison Results
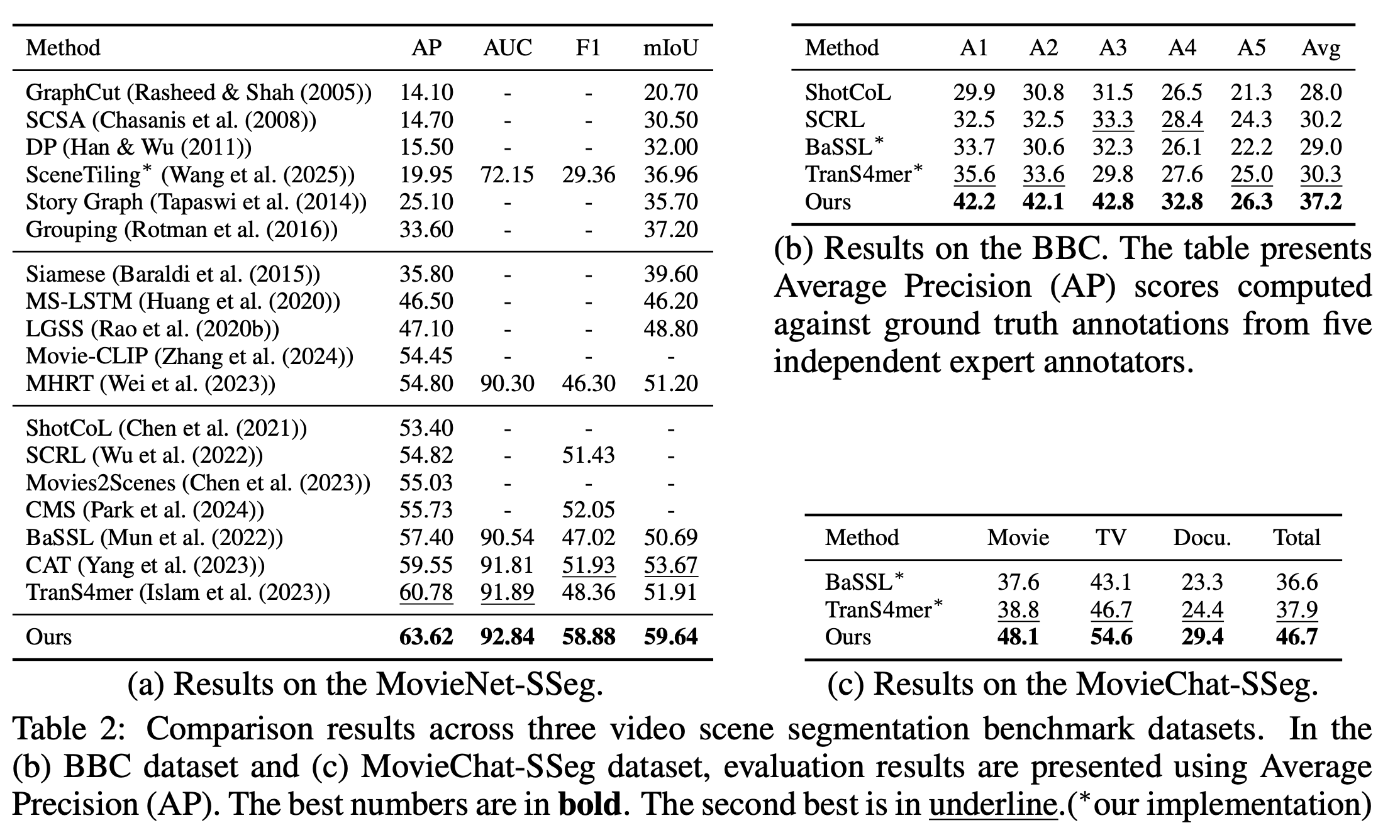
MovieNet-SSeg 데이터셋 결과: MovieNet-SSeg에서 SOTA 방법론들과 모델을 비교한 결과이다. 의사 경계 기반의 자기지도 학습 방법들(BaSSL, CAT, TranS4mer)이 전통적인 접근 방식에 비해 강력한 성능을 달성함을 볼 수 있다. 방법론은 동일한 ViT 백본을 사용하는 방법들(TranS4mer)대비 상당한 성능 향상을 포함하여 기존 접근법들보다 일관된 개선을 보여준다. 장르 가이드 표현과 같이 길이 기반 샘플링이라는 기여가 아키텍처 선택을 넘어 상호 보완적인 이점을 제공한다는 것을 입증한다.
BBC 데이터셋 교차 도메인 평가: 교차 도메인 평가를 위헤 BBC 데이터셋에서 추가 실험을 수행했다. BBC 데이터셋은 MovieNet의 극장판 콘텐츠와는 다른 서사 구조를 가진 자연 및 야생 동물 다큐멘터리를 포함한다. 2번째 테이블과 같이, 방법은 기존 방식들과 비교하여 경쟁력 있는 성능을 달성했다. 이는 접근 방식이 극장판 영화를 넘어 다큐멘터리 콘텐츠에도 꽤 잘 일반화됨을 시사한다.
MovieChat-SSeg 데이터셋 평가: MovieChat-SSeg는 영화, TV, 다큐멘터리라는 세 가지 뚜렷한 포맷을 갖춘 다양한 평가 벤치마크를 제공한다. 3번째 테이블과 같이, 모델은 TranS4mer대비 전체적으로 +8.8 AP의 개성을 보이며 모든 포맷에 걸쳐 경쟁력 있는 성능을 달성했다.
6.5 Ablation Studies
설계 선택을 평가하고 다양한 구성의 영향을 조사하기 위해 절제 연구를 수행한다.
1. 샷 표현 학습에 장르 임베딩을 통합하는 방법(Index 1-3, 8)
2. 장르 임베딩 생성을 위한 프롬프트 설계 전략(Index 4-5, 8)
3. 길이 기반 앵커 샘플링을 위한 파라미터 설정(Index 6-7, 8)
4. 다양한 길이 설정 전반에 걸친 테스트 시간 샷 분할을 위한 임계값 구성 (Index 8-11)
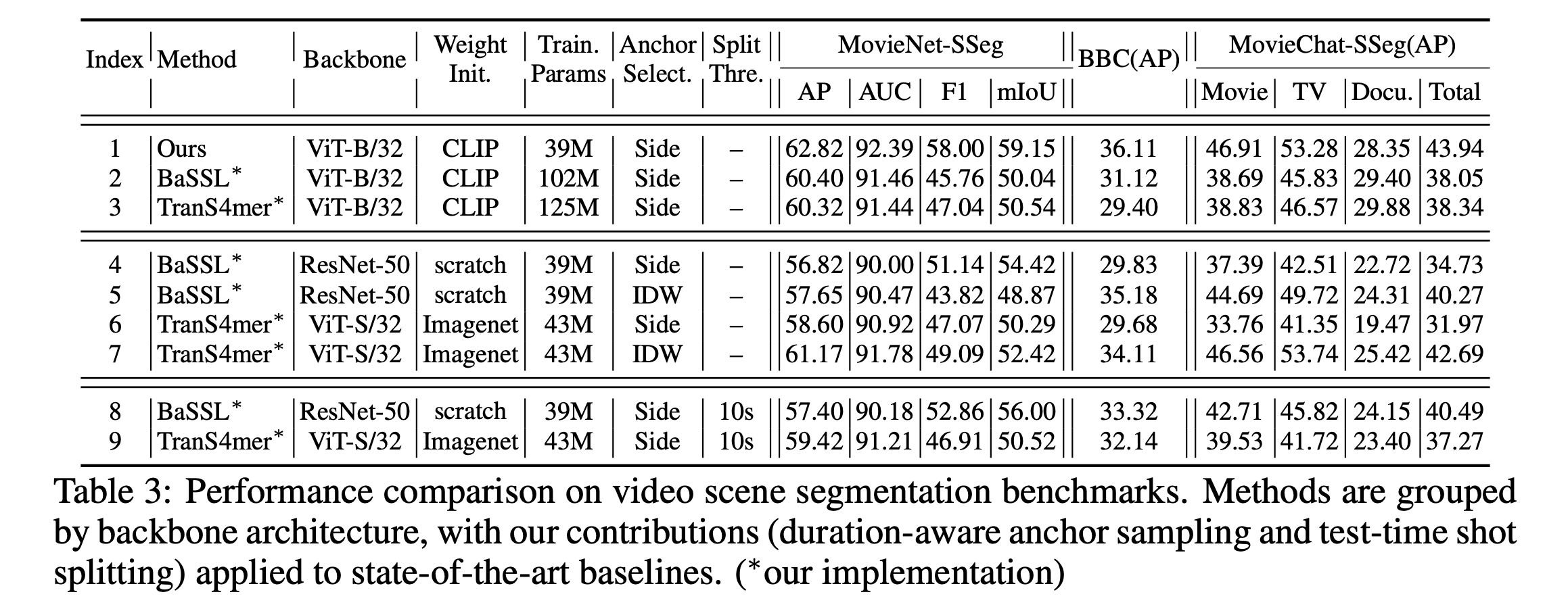
Genre Embedding Integration: 단순 연결 전략보다 유사도 기반 잔차 접근 방식이 가장 좋은 성능(63.62 AP)를 달성했다. 이는 어텐션 메커니즘을 통한 장르 정보의 동적 통합이 단순 결합보다 효과적임을 보여준다.
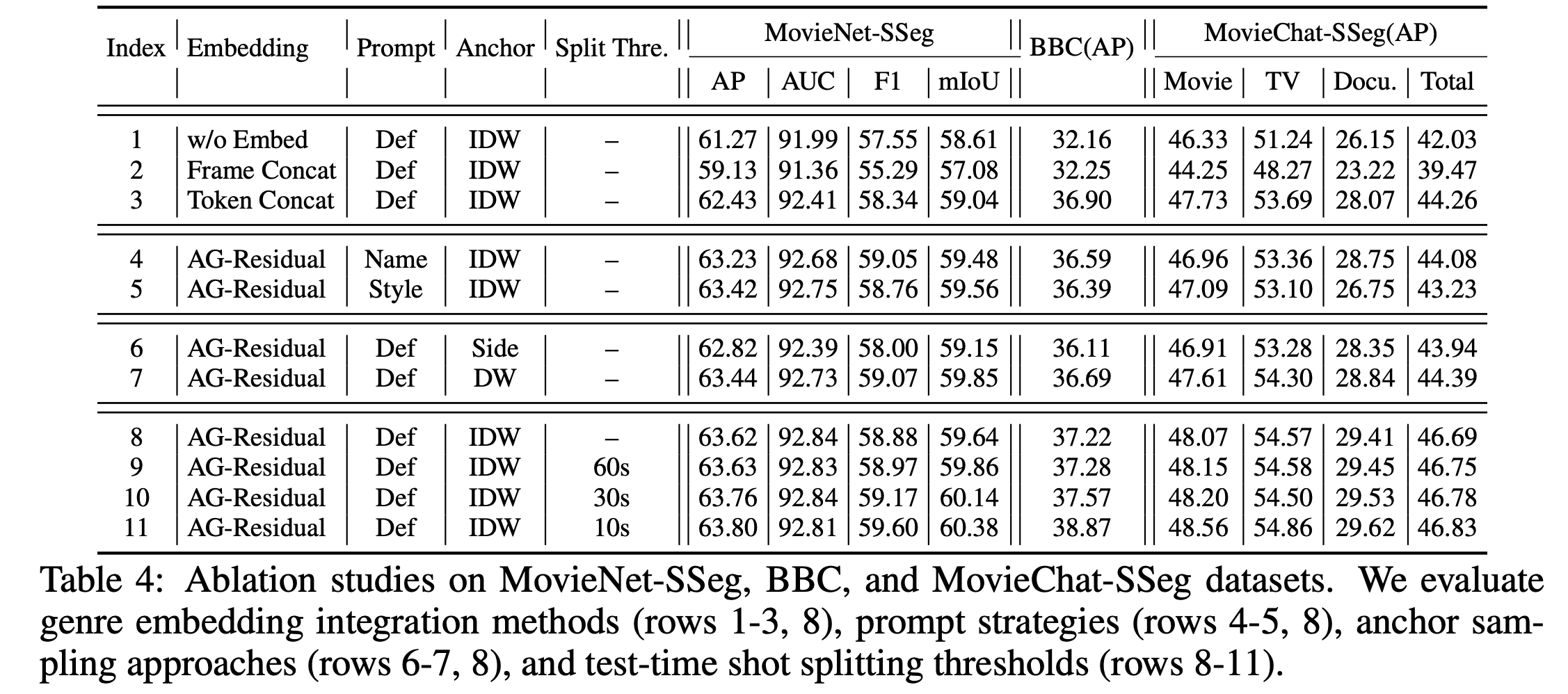
Genre Prompt Design: 장르 이름만 사용한 것보다 상세한 서술이 포함된 '정의 기반' 프롬프트가 가장 높은 성능을 달성
Shot Duration: 고정된 끝점이나 긴 샷을 우선하는 전략보다, 역-길이 가중치 전략이 가장 좋은 성능을 달성했다. 짧은 샷을 앵커로 우선순위화하는 것이 더 다양한 훈련 신호를 제공함을 보여준다.
Shot Split Threshold: 추론시 긴 샷을 분할할때 임계값이 작아질수록 일관된 성능 향상이 있었으며 10초 임게값이 최상의 성능을 달성했다.
6.6 Qualitative Analysis of Failure Cases
시스템적인 실패 패턴을 식별하기 위해 Movie-SSeg 테스트 세트에서 성능이 가장 낮은 세 편의 비디오를 분석했다.

-
Insert Shots : TV, 사진 등 짧은 삽입 영상이 장면 경계로 오분류되는 경우가 빈번하다. 이는 시각 기반 접근 방식이 주변 시퀸스와의 서사적 일관성을 유지하는 스토리텔링 기법을 이해할 수 있는 서사적 이해도가 부족함을 보여준다.
-
Lighting Variations : 번개, 깜빡임 등은 시각적 불연속성을 만들어 장면 변화로 오해를 일으킨다.
-
Subtle Spatial Transitions: 서사 흐름은 유지하면서 실내에서 실외로 확장되는 경우, 높은 시각적 유사도 때문에 분할하지 못하는 현상이 발생
-
CGI: 디지털 합성이나 CGI는 장면에 무관한 시각적 불연속성을 생성하여 경계로 오해받기 쉽다.
VII. CONCLUSION
장르 가이드 표현학습, 길이 기반 앵커 샘플링, 테스트 타임샷 분할을 통해 제작 수준의 메타데이터를 활용하는 비디오 장면 분할을 위한 새로운 접근 방식을 제시합니다.
또한, 다양한 서사 구조에 대한 평가를 지원하기 이해 영화, TV, 다큐멘터리 등 여러 콘텐츠 유형에 걸쳐 1000개의 비디오 클립에 사람이 직접 주석을 단 장면 분할 벤치마크인 MovieChat-SSeg를 소개한다. 광범위한 실험을 통해 우리의 방법론이 여러 벤치 마크에서 SOTA 성능을 달성했으며, 다양한 비디오 콘텐츠 유형 전반에서 기존 접근 방식 대비 상당한 성능 향상을 이루었음을 입증했다.
방법론이 장르 및 시간적 메타데이터를 성공적으로 통합하기는 했으나, 시각적 변동성이 거의 없는 대화 중심의 장면과 같이 장면 경계 검출을 위한 시각적 및 제작 단서가 불충분한 콘텐츠에서는 여전히 한계에 직면한다.
접근 방식은 영화 스타일의 콘텐츠에 초점을 맞추고 있어 다른 컨벤션을 가진 비디오 포맷에서는 추가적인 adaptation이 필요할 수 있다. 현재의 사전 학습은 전적으로 MovieNet 데이터에만 의존하고 있으며, 더 다양하고 대규모의 비디오 데이터셋을 통합한다면 다양한 콘텐츠 유형에 대한 일반화 성능을 잠재적으로 향상시킬 수 있다.
더 나아가 뉴스 방송, 브이로그, 교육용 콘텐츠와 같은 광범위한 비디오 카테고리에 대한 평가는 서사 중심 콘텐츠를 넘어선 방법론의 적용 가능성에 대한 통찰을 제공할 것이다.
Open Review
