Database 란
특정 조직의 업무를 수행하는 데 필요한 상호 관련된 데이터들의 집합
| 특징 | 설명 |
|---|---|
| 실시간 접근성(Real-Time Accessibility) | 비정형적인 질의(조회)에 대하여 실시간 처리에 의한 응답이 가능 |
| 지속적인 변화(Continuous Evloution) | 데이터베이스의 상태는 동적. 즉 새로운 데이터의 삽입(Insert), 삭제(Delete), 갱신(Update)으로 항상 최신의 데이터를 유지 |
| 동시 공용(Concurrent Sharing) | 데이터베이스는 서로 다른 목적을 가진 여러 응용자들을 위한 것이므로 다수의 사용자가 동시에 같은 내용의 데이터를 이용 |
| 내용에 의한 참조(Content Reference) | 데이터베이스에 있는 데이터를 참조할 때 데이터 레코드의 주소나 위치에 의해서가 아니라 사용자가 요구하는 데이터 내용으로 찾음 |
데이터베이스 언어(SQL)
데이터베이스에서 데이터를 추출하고 조작하는 데에 사용하는 데이터 처리 언어
DML (Data Manipulation Language) - 데이터베이스에 들어 있는 데이터를 조회하거나 검색하기 위한 명령어
-
select
FROM, ON, JOIN > WHERE, GROUP BY, HAVING > SELECT > DISTINCT > ORDER BY > LIMIT //실행 순서 -
insert
-
update
-
delete
DDL (Data Definition Language) - 데이터 구조와 관련된 명령어
- create
- alter
- drop
- truncate
- rename
DCL (Data Control Language) - 데이터베이스에 접근하고 객체들을 사용하도록 권한을 주고 회수하는 명령어
- grant
- revoke
TCL (Transaction Control Language) - DML에 의해 조작된 결과를 작업단위 별로 제어하는 명령어
- commit
- rollback
- savepoint
RDBMS? NoSQL?
| 종류 | 설명 | 장점 | 단점 | 상황 |
|---|---|---|---|---|
| RDBMS (Relational DataBase Management System) | 모든 데이터를 2차원 테이블 형태로 표현 | 스키마에 맞춰 데이터를 관리하기 때문에 데이터의 정합성을 보장 | 시스템이 커질 수록 쿼리가 복잡해지고 성능이 저하되며 Scale-out이 어렵다(Scale-up만 가능) | 데이터 구조가 명확하고, 변경 될 여지가 없으며 스키마가 중요한 경우 중복된 데이터가 없어(데이터 무결성) 변경이 용이하기 때문에 관계를 맺고 있는 데이터가 자주 변경이 이루어지는 시스템 |
| NoSQL | 데이터간의 관계를 정의하지 않고, 스키마가 없어 좀 더 자유롭게 데이터를 관리할 수 있으며, 컬렉션이라는 형태로 데이터를 관리 | 키마 없이 Key-Value 형태로 데이터를 관리해 자유롭게 데이터를 관리할 수 있다. 데이터 분산이 용이하여 성능 향상을 위한 scale-up 뿐만아닌 scale-out 또한 가능하다. | 데이터 중복이 발생할 수 있고, 중복된 데이터가 변경될 경우 수정을 모든 컬렉션에서 수행해야 한다. 스키마가 존재하지 않기에 명확한 데이터 구조를 보장하지 않아 데이터 구조 결정이 어려울 수 있다. | 확한 데이터 구조를 알 수 없고 데이터가 변경/확장 될 수 있는 경우 Update가 많이 이루어지지 않는 시스템에 좋으며, Scale-out이 가능하다는 장점을 활용해 막대한 데이터를 저장해야 해서 DB를 Scale-out 해야 되는 시스템 |
무결성 제약조건(Integrity Constraint)
데이터의 내용이 서로 모순되는 일이 없고, 데이터베이스에 걸린 제약을 완전히 만족하게 되는 성질
| 종류 | 설명 |
|---|---|
| 개체 무결성 | 기본키는 NULL이 올 수 없으며, 기본키를 구성하는 어떠한 속성값이라도 중복값이나 NULL값을 가질 수 없음 |
| 참조 무결성 | 참조할 수 없는 외래키 값은 가질 수 없음. 즉 외래키는 NULL값을 가질 수 없으며, 참조하는 릴레이션의 기본키와 동일해야합니다 |
| 도메인 무결성 | 각 속성값은 반드시 정의된 도메인(하나의 속성이 가질 수 있는 값들의 범위)만을 가져야 함 |
키(key)
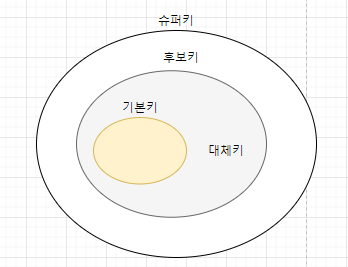
| 키 종류 | 설명 |
|---|---|
| 슈퍼키 | 릴레이션에서 유일성을 보장하는 열들의 집합으로, 중복된 값을 가지지 않음 |
| 후보키 | 슈퍼키 중에서 최소성을 만족하는 키로, 유일성과 최소성을 모두 충족 |
| 기본키 | 후보키 중에서 선택된 주요 식별자로, 릴레이션의 각 튜플을 고유하게 식별 |
| 대체키 | 후보키 중에서 선택된 기본키가 아닌 다른 후보키로, 레코드를 유일하게 식별 |
| 외래키 | 다른 테이블의 기본키를 참조하는 열로, 참조 무결성을 유지하며 관계를 형성 |
