들어가며

둘다 무언가를 가져온다는 의미는 비슷한 것 같은데 무엇이 다를까?
결론부터 말하면, 둘다 Id값을 통해서 엔티티 정보를 가져오는 것은 동일하지만, 영속성 컨텍스트와 데이터베이스 간 동작 방식에서 차이가 있다. 이번 글에서는 둘의 차이와 함께 get, find 네이밍에 대해서 알아보자.
findById()

findById()는 CrudReposiotry에 정의된 메소드다.
해당 메소드는 전달받은 Id에 해당하는 엔티티 혹은 해당하는 엔티티가 없을 경우 Optional.empty()를 반환한다고 한다. 즉, 엔티티가 없더라도 내부적으로 예외를 발생시키지 않는다.
물론, Id가 유효하지 않다면 IlleagalArgumentException이 발생할 수 있다. 이는 Throws에서 확인할 수 있다.
그렇다면 getReferenceById()는 어떨까?
getReferenceById()

getReferenceById()는 JpaRepository에 정의된 메소드다.
해당 메소드는 전달받은 Id에 해당하는 엔티티를 반환한다. 없을 경우 내부적으로 예외를 발생시킨다.
차이점
현재까지 알게된 것을 정리하면 다음과 같다.
findById()
- id에 해당하는 엔티티 반환, 엔티티 없으면 Optional.empty() 반환
- 내부적으로 예외가 발생하지 않음
getReferenceById()
- id에 해당하는 엔티티 반환, 엔티티 없으면 예외 발생
이렇게 보면 둘을 언제 써야하는지 잘 감이 안잡힌다. 하지만, getReferenceById()에는 특별한 기능이 하나 숨겨져있다.
getReferenceById() 는 EntityManager의 getReference 메서드를 호출하여, 참조값만 가져온 후, 조회된 엔티티의 내부 값이 필요해지는 시점에 지연 로딩으로 DB를 조회해 값을 가져오도록 동작한다. 따라서, 값을 단순하게 할당하는 기능에서는 findById()에 비해 성능상의 이점이 있다.
그렇다면 지연로딩은 무엇이길래 성능상의 이점이 있는걸까?
🤔 get? find?
무언가 찾는다는점은 동일한듯한데.. 네이밍을 왜 find, get으로 구분한걸까? 각 메소드의 인터페이스를 살펴보며 정리한 나의 생각은 이렇다.
CrudRepository를 보면 항상 무언가를 찾는 반면JpaRepository는 무언가를 얻는다.findById()는 전혀 결과가 없을 수도 있지만getReferenceById()는 항상 무언가를 반환한다. 그렇지 않으면 예외가 발생한다.
즉,find는 값이 있을 수도 없을 수도 있고get은 무조건 값이 있어야 된다 라는 것이 내 결론이다.
정보를 조금 더 찾아보니 사람마다 네이밍 규칙은 다르나 공통적인 의견으로는 find는 상대적으로 시간복잡도가 느릴때, get은 시간복잡도가 빠를때 사용한다고 한다.
프록시
로딩 전략을 알기 전, 지연로딩의 핵심인 프록시에 대한 개념부터 알아보도록 하자.
객체는 객체 그래프로 연관된 객체들을 자유롭게 탐색할 수 있다. 하지만 데이터베이스에 매핑하는 엔티티 객체에서는 자유도가 떨어진다. 연관된 테이블의 데이터를 조회하기 위해 Join을 사용하여 조회해야 하기 때문이다.
자유로운 객체 그래프 탐색의 가능성으로 인해 연관된 모든 테이블을 조회하는 것은 비용이 따른다. 실제로 연관된 테이블을 사용하지 않으면 쓸데없이 Join으로 조회한 결과를 가져오기 떄문이다.
이러한 문제를 해결하기 위해 프록시가 등장하였다.
연관된 객체를 처음부터 모두 조회하는 것이 아니라, 실제 사용 시점에 조회할 수 있도록 해준다.
JPA에서 프록시는 실제 엔티티 객체 대신 DB 조회를 지연할 수 있는 가짜 객체를 의미한다.
실제 엔티티 클래스를 상속받아 만들어지므로 사용자 입장에서는 진짜 객체인지 가짜 객체인지 구분하지 않고 사용하면 된다.
겉모양이 같아 사용자 입장에서 동일하게 사용하면 내부적으로는 다르게 동작한다.
프록시 객체의 메서드를 호출하면 참조를 통해 메서드 호출을 위임하고 실제 객체의 메서드를 호출한다.
User라는 엔티티가 있고, 필드값으로 Id와 Name이 존재한다고 가정해보자.
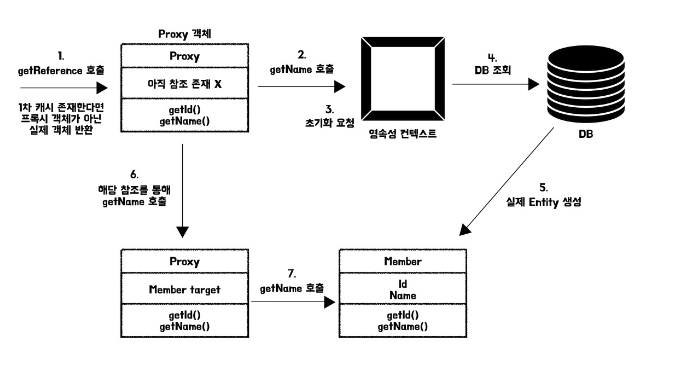
getReference()를 통해 프록시 객체를 생성한다. 해당 프록시 객체의 정보가 영속성 컨텍스트에 1차 캐시로 존재한다면 프록시 객체가 아닌 실제 객체를 반환한다. 아직 사용이 존재하지 않기에 실제 엔티티 객체의 참조를 가지고 있지 않는다.- 실제 사용을 위해 메소드를 호출한다.
- 메서드가 호출되면 영속성 컨텍스트에 초기화를 요청한다. 실제 엔티티 객체의 참조를 가지기 위해서는 실제 엔티티 객체의 생성이 필요한다.
- 영속성 컨텍스트는 데이터베이스를 조회해서 실제 엔티티 객체의 정보를 얻는다.
- 조회된 정보를 바탕으로 실제 엔티티 객체를 생성한다.
- 참조를 통해 실제 엔티티 객체의 메서드를 호출한다.
- 메서드 호출의 결과를 반환한다.
즉시로딩, 지연로딩
프록시 객체를 사용하게 되면 자주 함께 사용하는 것은 바로 가져올 수도 있고, 사용할 때 가져올 수 있도록 설정하는 방법이 존재한다. 이름에서 알 수 있듯 바로 가져오는 방법이 즉시 로딩이고 사용할 때 가져오는 방법이 지연 로딩이다. 각각의 특징은 무엇일까? 결론부터 말하면 다음과 같다.
✅ 즉시로딩과 지연로딩의 차이
EAGER(즉시로딩)는 사전적 의미인 열심인, 열렬한 처럼 Member를 조회하면 연관관계에 있는 Team 역시 함께 조회한다. 즉, 한번에 모두 가져온다!
LAZY(지연로딩)는 게을러서 Member만 조회해오고 연관관계에 있는 나머지 데이터는 실제로 사용할때까지 조회를 미룬다. 즉, 사용할 때 호출이 된다!
즉시 로딩
@Entity
public class Member {
// ...
@ManyToOne(fetch = FetchType.EAGER)
@JoinColumn(name = "TEAM_ID")
private Team team;
// ...
}
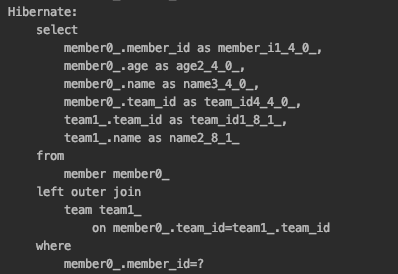
엔티티를 조회할 때 연관관계에 있는 엔티티도 함께 조회하는 방법이다. 즉시 로딩을 사용하기 위해서는 fetch 속성을 FetchType.EAGER로 지정한다. JPA 구현체는 즉시 로딩을 최적화하기 위해 가능하면 조인 쿼리를 사용한다.
즉시 로딩 실행 쿼리문을 보면 JPA가 내부 조인(INNER JOIN)이 아닌 외부 조인(LEFT OUTER JOIN)을 사용하는 것을 확인할 수 있는데 이는 NULL 가능성 때문이다.
현재 회원 테이블에서 team_id 외래 키는 NULL 값을 허용하고 있다. 내부 조인이 외부 조인보다 성능이 좋기에 최적화를 위해 내부 조인을 사용하는 것이 유리한데 이때는 외래키에 NOT NULL 제약 조건을 설정하면 값이 있는 것을 보장하기 때문에 이런 경우에는 내부조인만 사용해도 된다.
@Entity
public class Member {
// ...
@ManyToOne(fetch = FetchType.EAGER)
@JoinColumn(name = "TEAM_ID", nullable = false)
private Team team;
// ...
}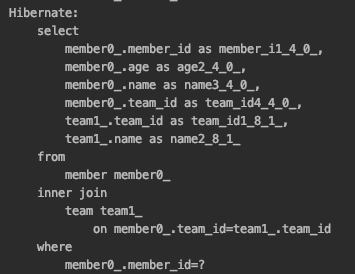
위와 같이 외래키에 NULL 값을 허용하지 않는다고 JPA에게 알려주는 경우 외부 조인 대신 내부 조인을 사용하게 된다.
✅ nullable 설정에 따른 조인 전략
@JoinColumn(nullable = true): NULL 허용(기본값), 외부 조인 사용
@JoinColumn(nullable = false): NULL 허용하지 않음, 내부 조인 사용
지연 로딩
@Entity
public class Member {
// ...
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "TEAM_ID")
private Team team;
// ...
}연관된 엔티티를 프록시 객체로 불러오고 실제 사용할 때 DB를 조회하는 방법이다. 지연 로딩을 사용하기 위해서는 fetch 속성을 FetchType.LAZY로 지정한다. 지연 로딩을 사용하게 되는 경우 실제 엔티티 객체 대신 앞에서 설명한 프록시 객체가 들어가게 된다. 값이 실제로 사용될 때, DB에서 조회하기 때문에 DB의 부하를 줄여줘 즉시로딩보다 성능상의 이점이 있다.
위 코드에서는 Member를 호출하면 Team을 조회하진 않는다. 대신 team 멤버변수에 프록시 객체를 넣어 둔다. 이 프록시 객체는 실제 사용될 때까지 데이터 로딩을 미룬다.
✅ JPA 기본 Fetch 옵션
@ManyToOne,@OneToOne: 즉시 로딩(FetchType.EAGER)
@OneToMany,@ManyToMany: 지연 로딩(FetchType.LAZY)
로딩 전략의 경우 되도록 지연 로딩만 사용하도록 권장하고 있다. 그 이유는 즉시 로딩을 사용하게 되면 예상치 못한 문제가 발생할 가능성이 존재하기 때문이다. 예를 들면 N+1 문제처럼, select로 Member만 가져오는 SQL을 작성했지만, 해당 SQL의 개수만큼 필요하지도 않은 Team select SQL가 발생하게 될 수도 있다. 그렇다고 지연 로딩을 하면 무조건 N+1을 막는 것은 아니다.
fetchJoin, @EntityGraph, fetchSize등 다양한 해결방법이 존재하고, 각각의 프로덕션 상황에 따라서 적절히 방법을 고르는 것이 중요하다.
결론
마지막으로 정리해보자.
findById
장점
안정성 : 데이터베이스에 해당 ID의 엔티티가 없을 경우, Optional.empty()를 반환하여 존재하지 않는 경우를 orElse(), orElseThrow()를 사용해서 명시적으로 처리할 수 있다.
-> null 체크를 안전하고 편리하게 할 수 있음
단점
성능: getReferenceById에 비해 성능이 살짝 떨어질 수 있다. 특히, 엔티티가 필요하지 않은 경우에도 데이터를 가져오기 때문에 불필요한 성능 오버헤드가 발생할 수 있다.
getReferenceById
장점
성능: 엔티티가 필요할 때까지 데이터베이스 접근을 지연시키기 때문에 성능상 유리하다.
단점
존재 보장 필요: 데이터베이스에 해당 ID의 엔티티가 반드시 존재해야 한다. 그렇지 않으면 런타임 시 EntityNotFoundException이 발생한다. 존재하지 않을 경우 예외가 발생하므로, 이를 항상 처리해야 한다. 코드 작성 시 프록시 객체를 사용할 때 언제 예외가 발생할지 예측하기 어렵기 때문에, 모든 데이터 접근 코드에 예외 처리가 필요하다.
나는 특별한 경우가 아니라면 findById를 더 많이 사용할 것 같다. 물론, 성능은 getReferenceById가 이점이 있지만 그정도로 큰 성능차이는 아닌 것 같고, 성능을 조금 포기하더라도 코드 안정성을 높이는 방향이 유지보수에 있어서 더 나은 방향이라고 생각하기 때문이다.
마치며
오늘은 언젠간 꼭! 다뤄보고 싶었던 findById()와 getReferenceById()의 차이에 대해 알아보았다. 프록시에 대한 개념이 조금 모호했는데 글을 작성하는 과정에서 실마리를 잡은 것 같다.
참고자료
CrudRepository 공식 문서
get, find의 차이
JpaRepository 공식 문서
프록시와 로딩전략
