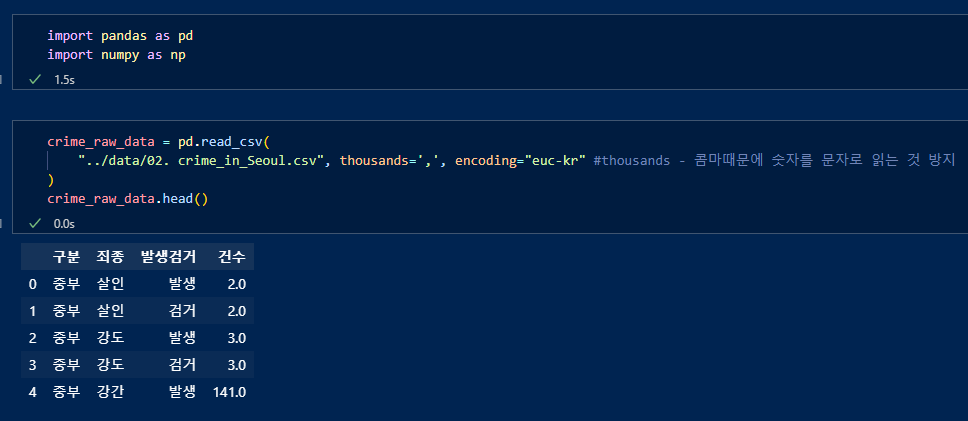
데이터 불러오기
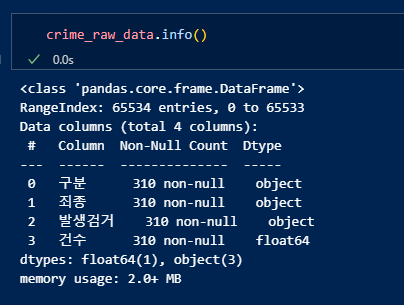
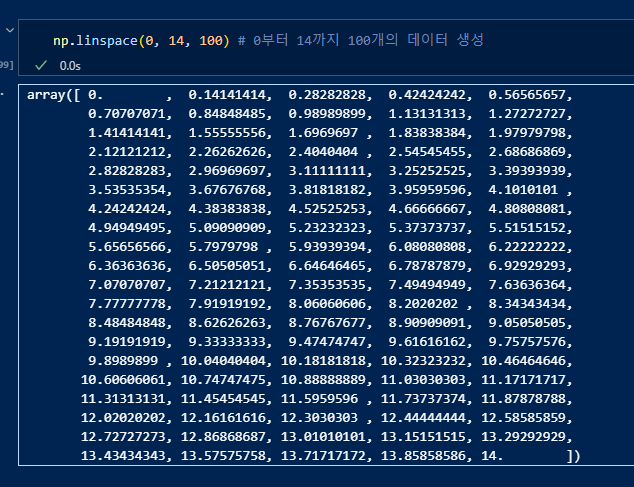
데이터 개요 확인. 인덱스는 65534, 데이터는 310개를 확인
죄종에 널값이 있음을 확인.
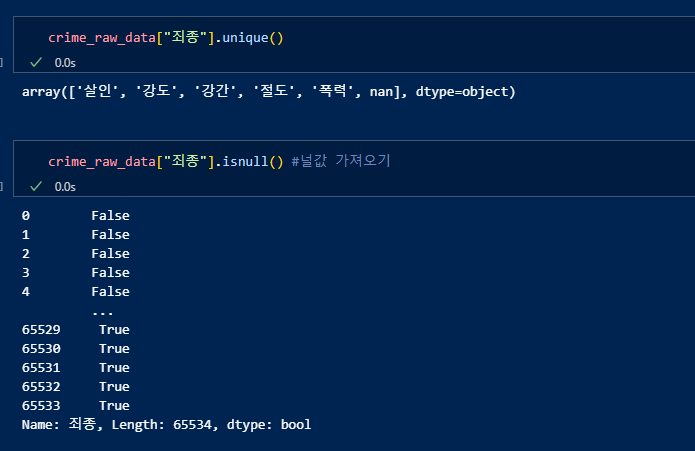
notnull()로 널값이 아닌 것을 가지고 오기. 그리고 데이터 확인.
서울시 범죄 현황 데이터 정리
pivot_table()을 이용하여 데이터 정리. 인덱스는 "구분", 재구성할 컬럼설정, value를 sum으로 채워줌.
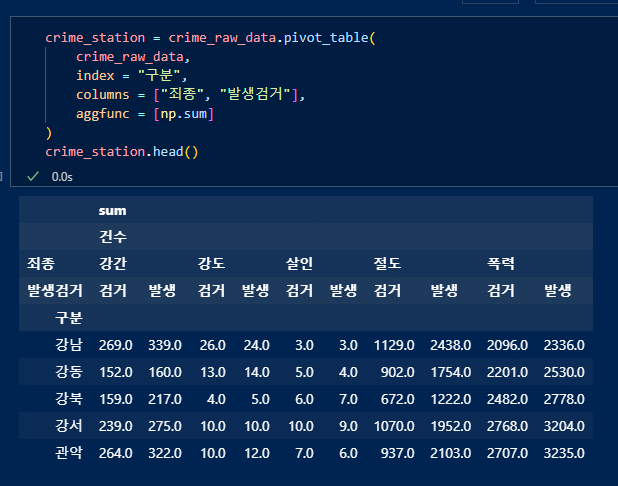
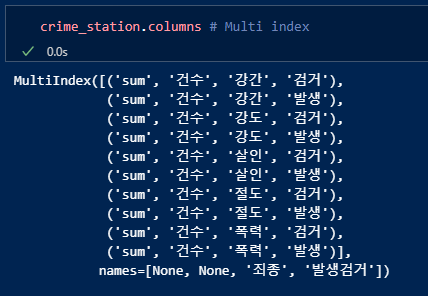
컬럼확인. 멀티인덱스(다중컬럼) 형태임을 확인.
불필요 컬럼 삭제.
- droplevel() : axis를 인자로 받아 행(0)삭제(default), 열(1)삭제 가능.
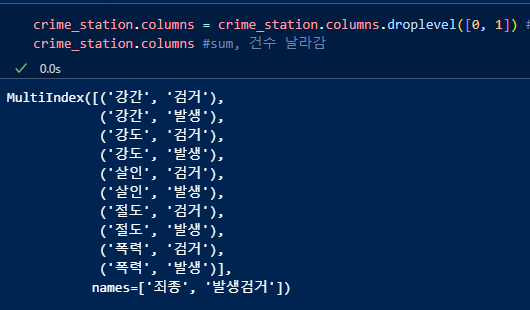
삭제 후 데이터와 인덱스 조회
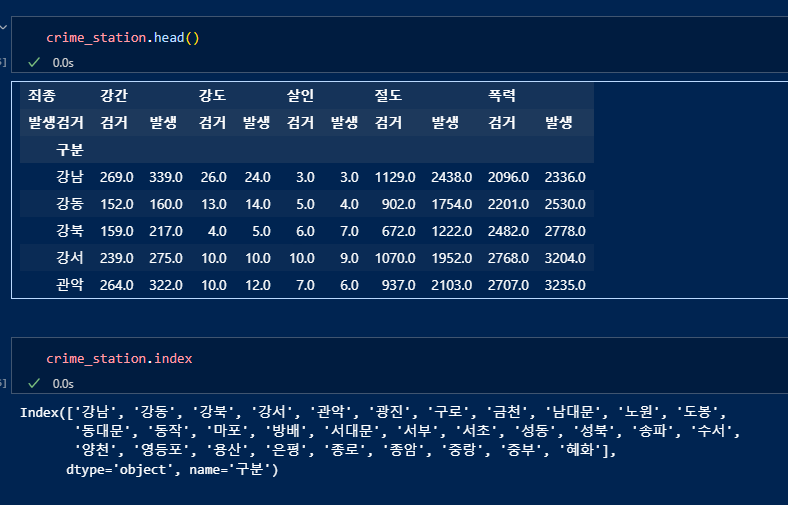
지역을 나타내는 "구별"의 인덱스를 활용하여 각 경찰서가 속해있는 해당 '구' 데이터 넣어주기
google api연동, import googlemaps의 geocode()함수 이용하여 주소값 가져오기.
tmp변수에 담아주고
길이 확인하기. 타입은 딕셔너리. 써야할 데이터 확인 후,
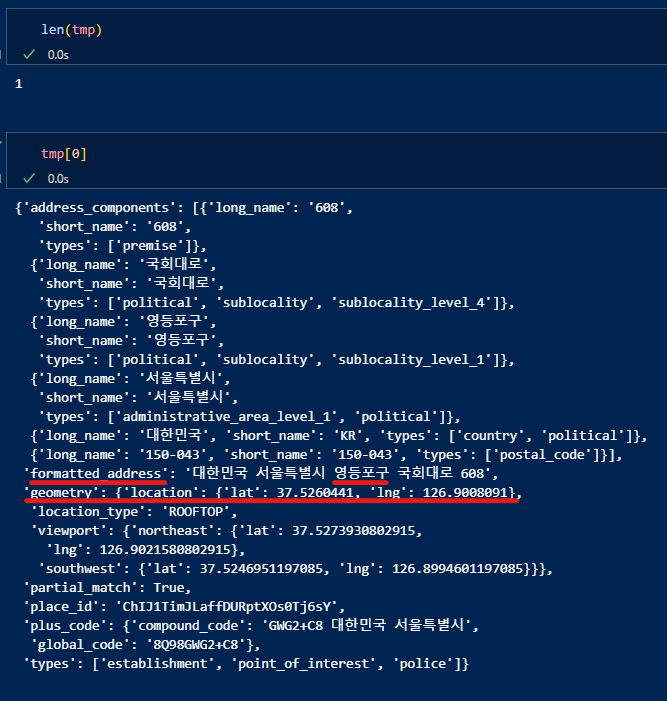
get() 함수와 'geometry', 'location', 'lat', 'lng' 등의 키값을 이용하여 원하고자 하는 데이터에 접근. (데이터 타입이 딕셔너리.)
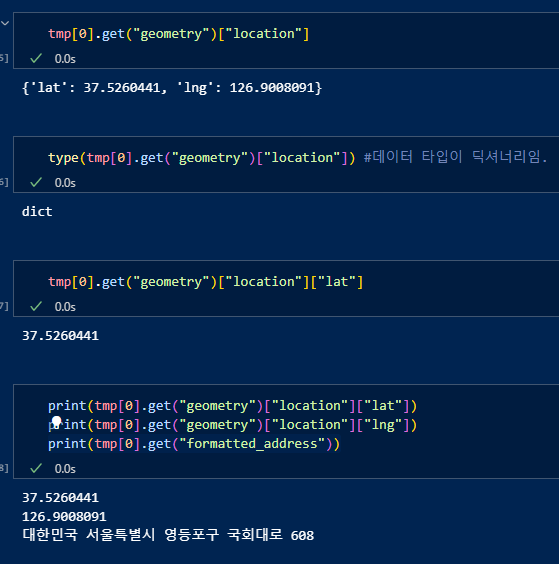
'구'데이터는 split()함수와 리스트 타입인것을 감안해 인덱스 값으로 접근.
'구별', 'lat', 'lng' 컬럼 생성
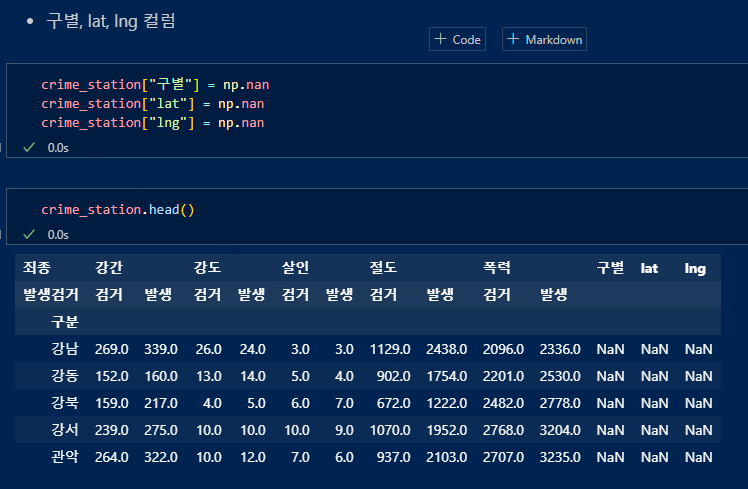
데이터가 '구분(구이름)'이 인덱스로 잡혀있던 것을 감안하여
iterrows()를 사용, 인덱스를 하나씩 받아 '서울+index+경찰서' 형태로 재할당할 수 있음을 확인.
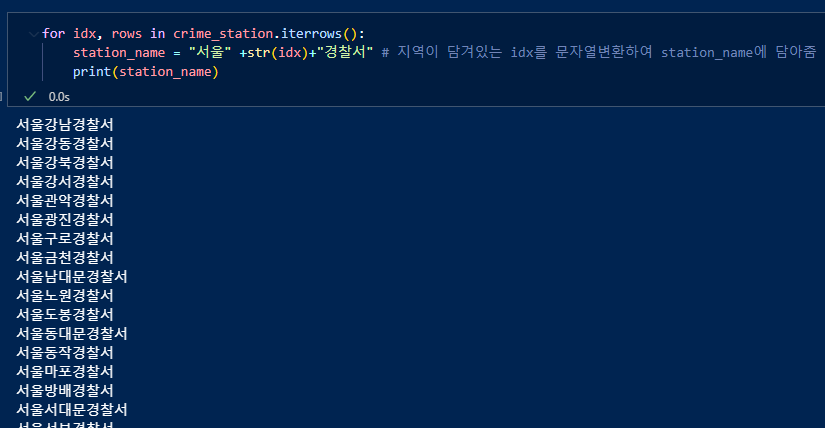
iterrows()를 이용하여 반복한다. '서울+index+경찰서'형태로 geocode()에 넣어주고 반환되는 값중, 키 'lat, lng, formatted_address'의 밸류값을 받아와서 "lat", "lng", "구별"컬럼에 넣어준다. count는 진행되는 상황을 보기위한 변수.
들어온 데이터의 갯수와 데이터 확인.
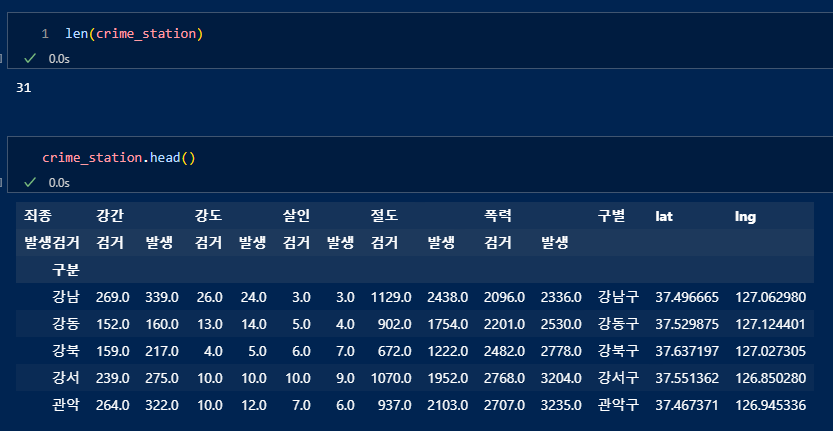
멀티인덱스를 수정

타입은 string, 인덱스 0행의 인덱스 2(강도) + 인덱스 1행의 인덱스 2(검거)
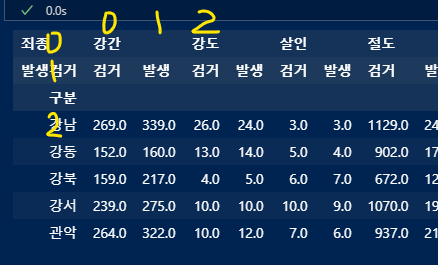
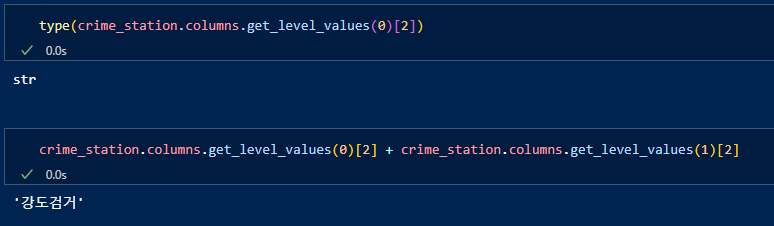
이를 활용하여 컬럼값을 재설정하여 'tmp'에 담아준다.
이를 다시 column값에 넣어주고 조회.
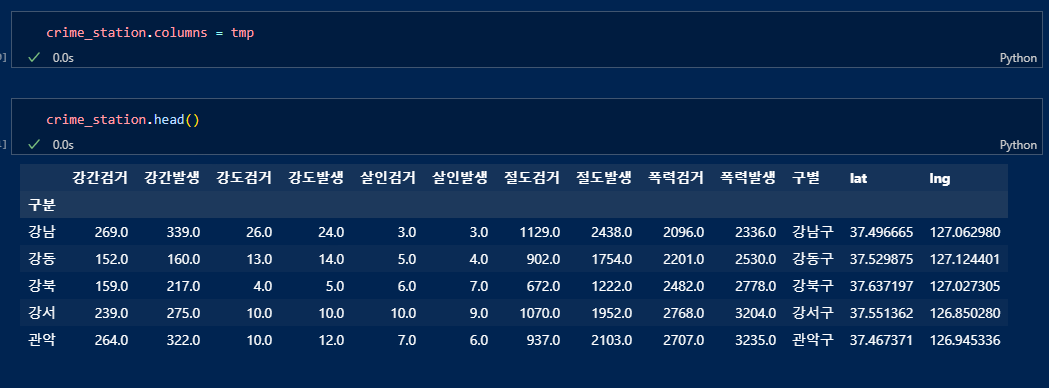
저장.
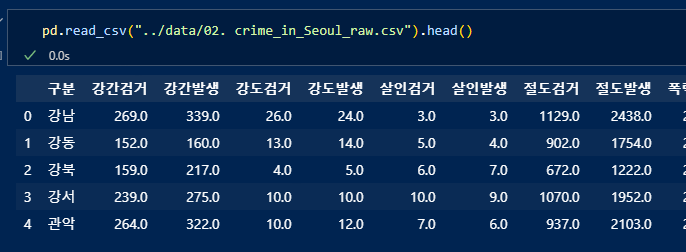
다시 불러와서 pivot_table() 함수 이용. index_col = 0은 첫번째 철럼이 인덱스 라고 설정.
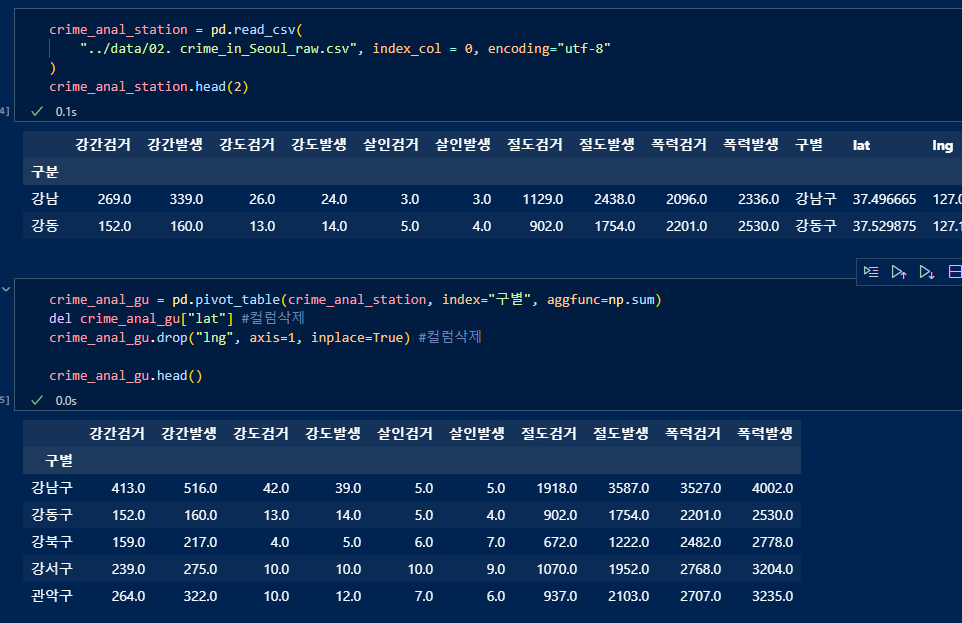
index컬럼 "구별", aggfunc=np.sum 구별 각인덱스의 합산을 조회.
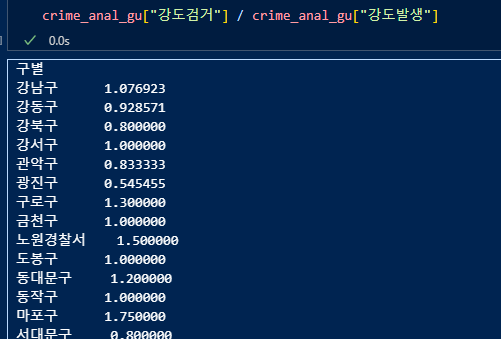
검거율 컬럼 생성하기.
강도검거 컬럼을 강도발생 컬럼으로 나눌 수 있고, 그것이 강도검거율
리스트 형태로도 가능하다.
검거율 컬럼을 만들어주고, 각 죄종마다 검거/발생을 실행.
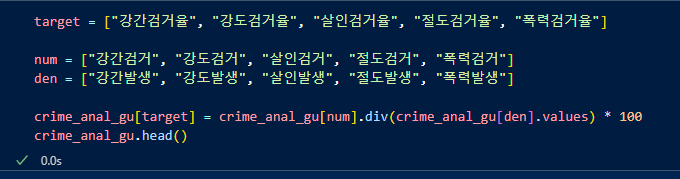
기존데이터에 검거율 컬럼이 생성.(단위:%)
불필요한 검거데이터는 삭제.
del키워드나 drop()도 사용가능
검거 데이터 중에서 당해년도 아닌 범죄까지 검거한 경우의 데이터가 포함되면 검거율이 100을 넘는 경우가 있음.
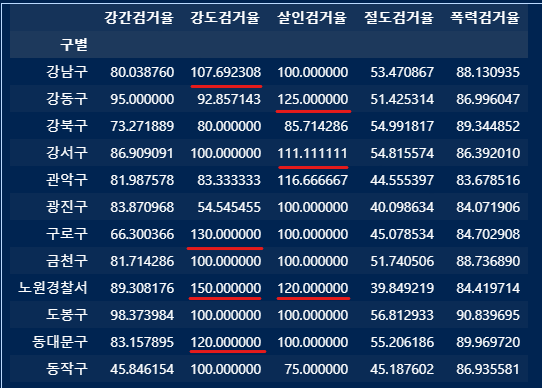
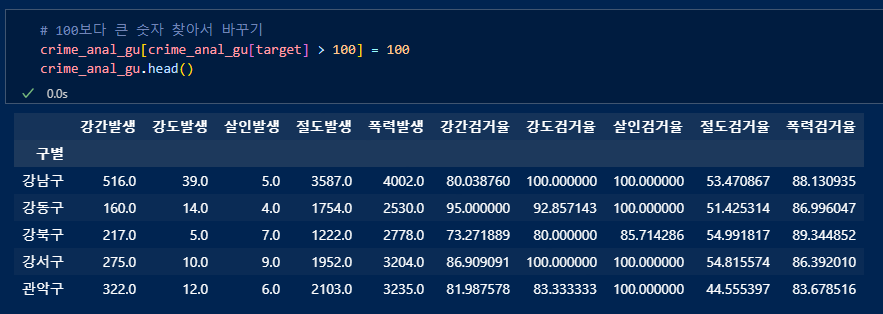
조건문을 써서 100넘는 검거율은 100으로 설정.
컬럼 rename하기
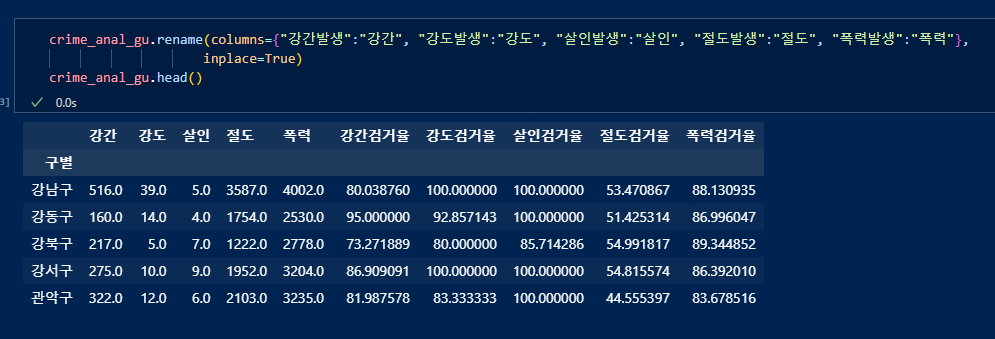
min-max 정규화하기 (데이터간 상대적 비교를 하기 위함)
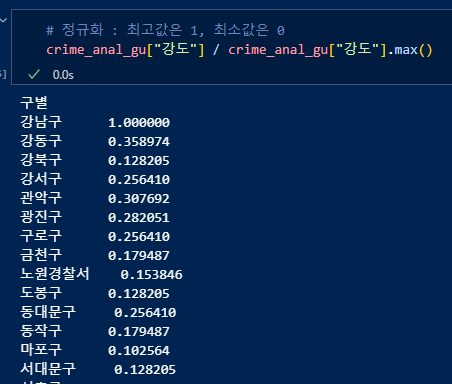
'crime_anal_norm' 변수 생성하여 각 죄종 정규화. 리스트로 묶어서도 계산을 해준다.
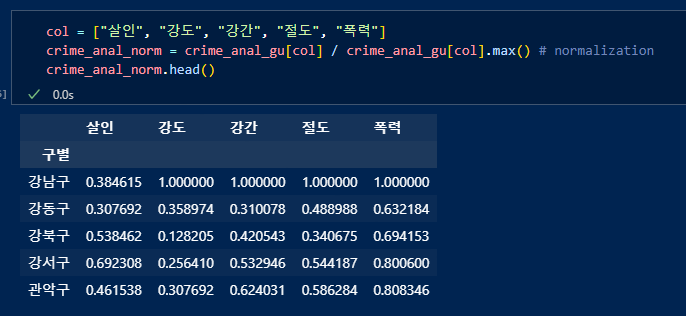
거기에다 전 데이터의 검거율 컬럼들 리스트 형태로 추가
구별 CCTV데이터 불러와 인구수,CCTV 컬럼 추가하기
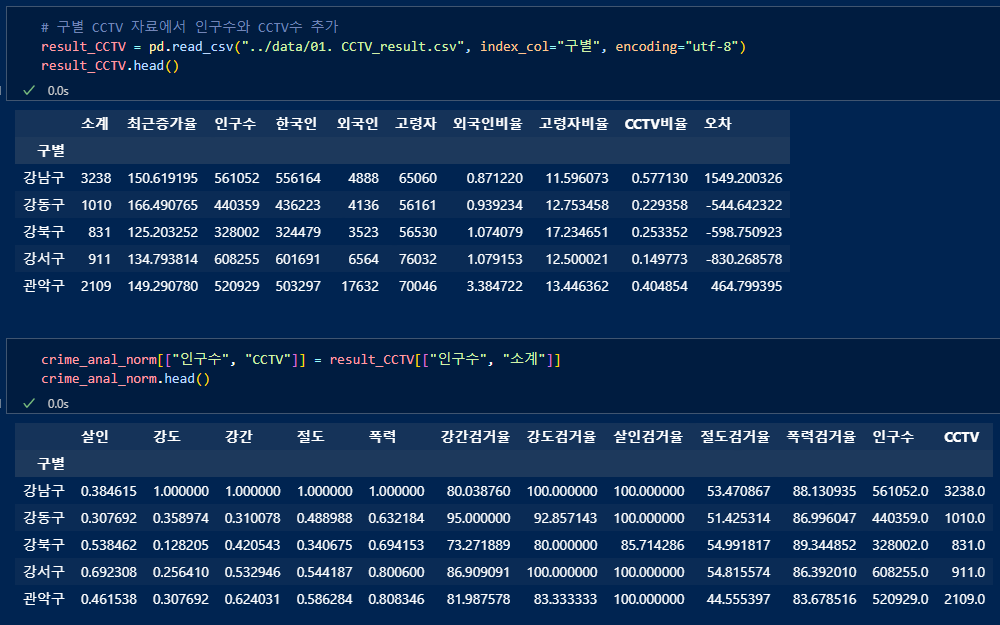
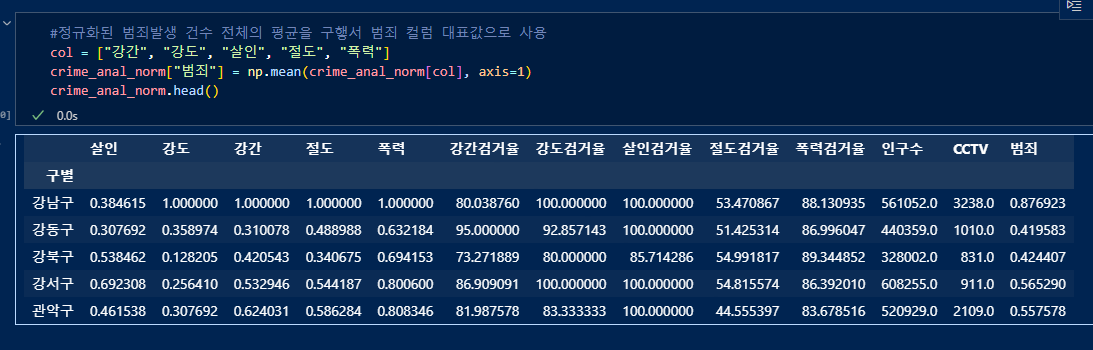
numpy의 mean()함수로 각 죄종의 정규화된 값의 평균을 "범죄"컬럼에 넣어준다.
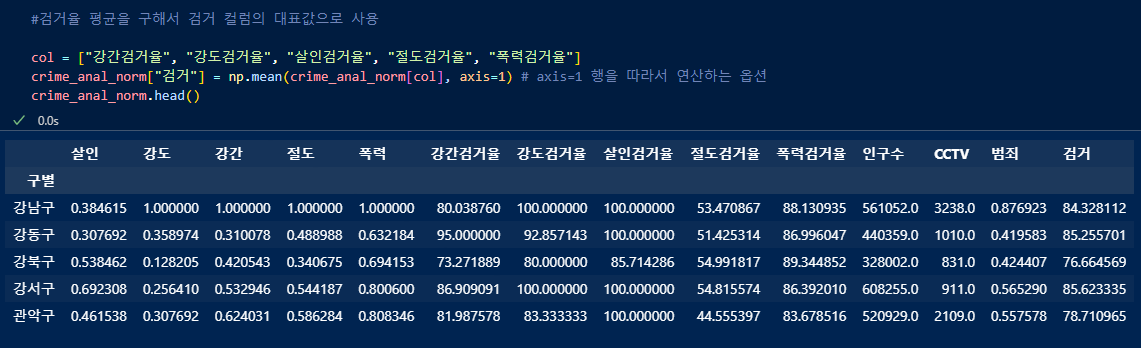
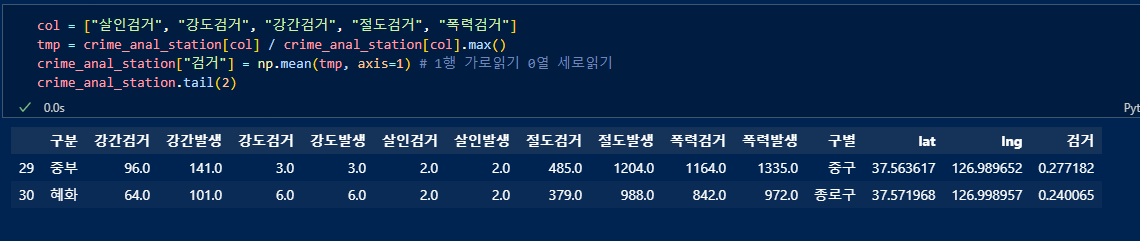
각 범죄의 검거율의 평균을 구하여 "검거"컬럼 생성 후 할당
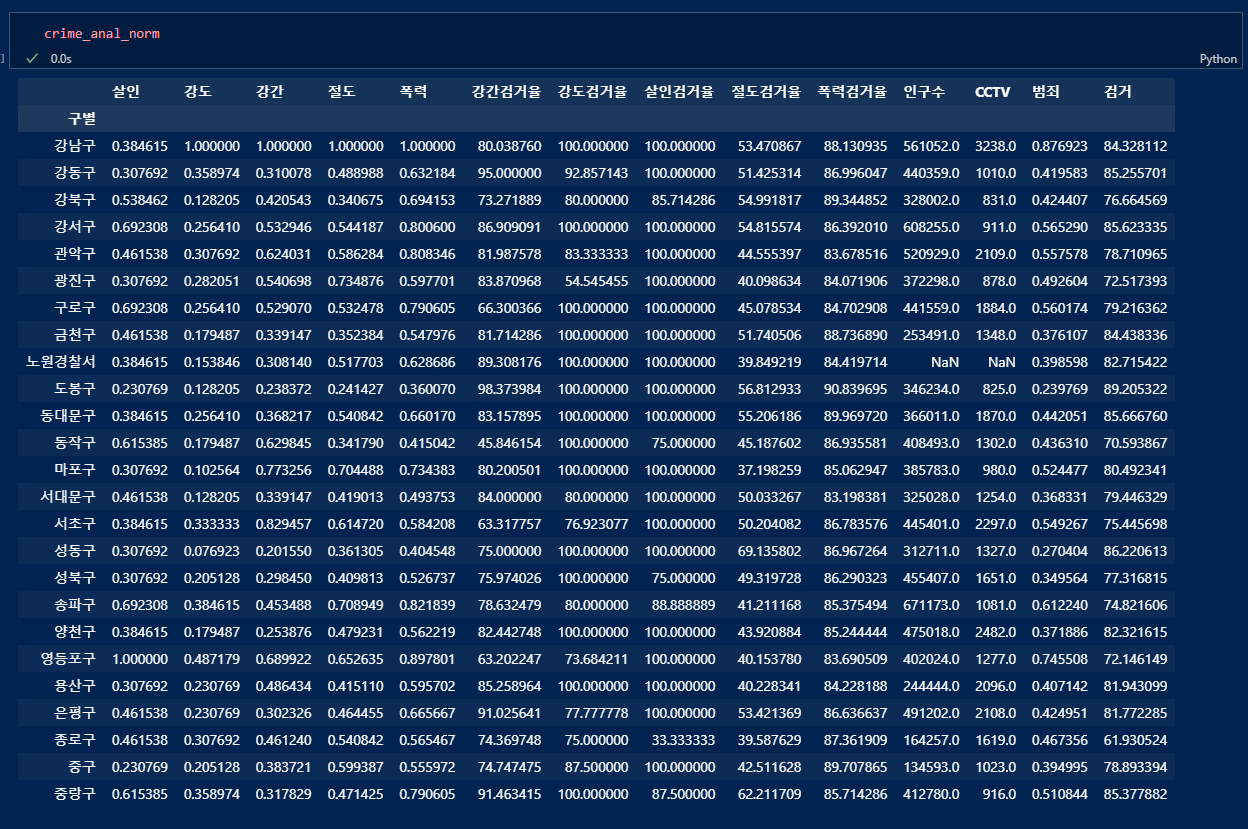
결과
Seaborn
- 시각화 도구 라이브러리
- 데이터셋의 관계와 패턴 등을 다양한 그래프 스타일로 표현할 수 있다.
예제1
데이터 생성 후
각 sin함수에 다른 계수를 곱해줌
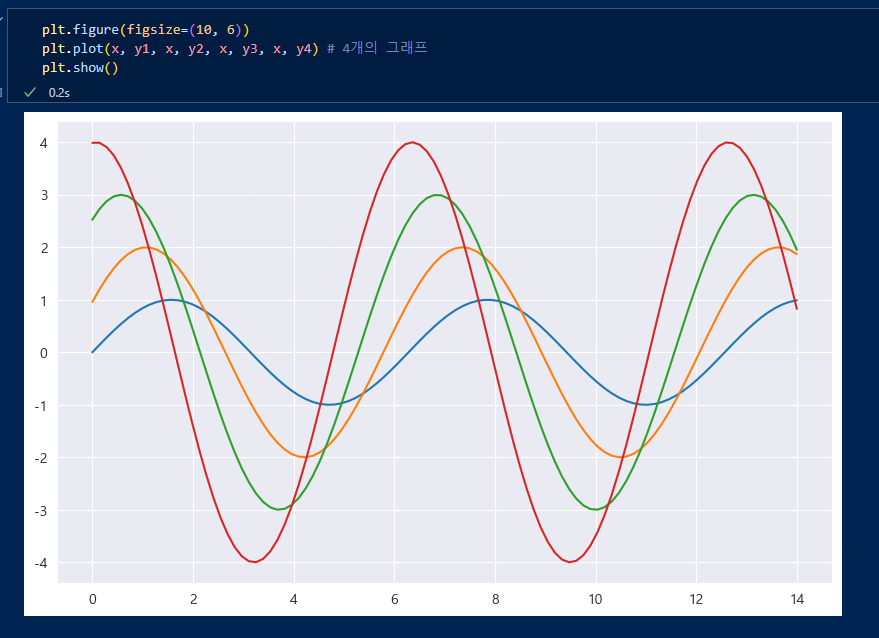
figure(), plot(), show() 등 matplotlib에 기반해서 그런지 기본적인 함수는 같다.
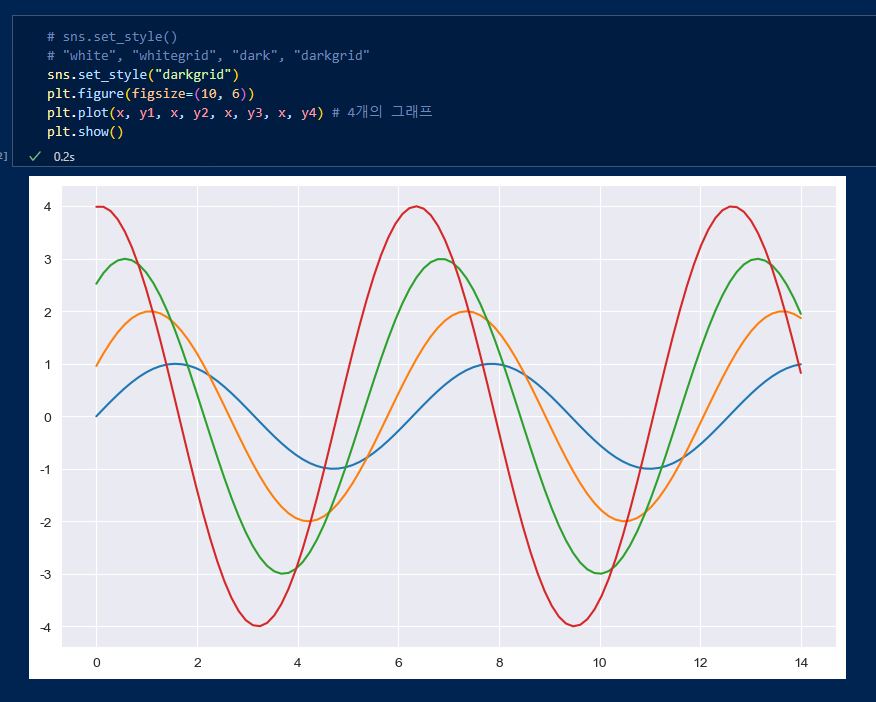
set_style()로 darkgrid, white등을 인자로 줄 수 있다. 그래프 사이즈, x값과 각 y절편을 다르게 준다.
예제2
load_dataset()으로 내장되어있는 데이터셋 'tips'조회
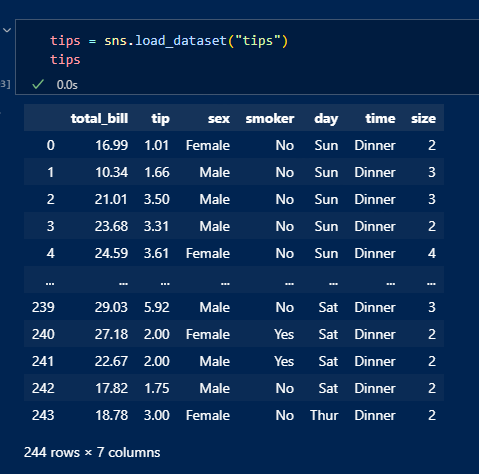
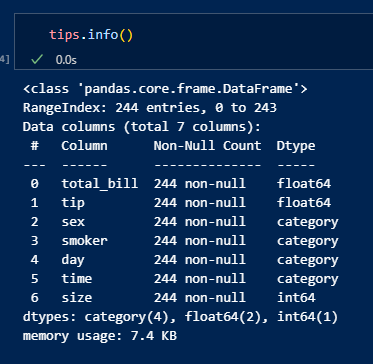
데이터 정보
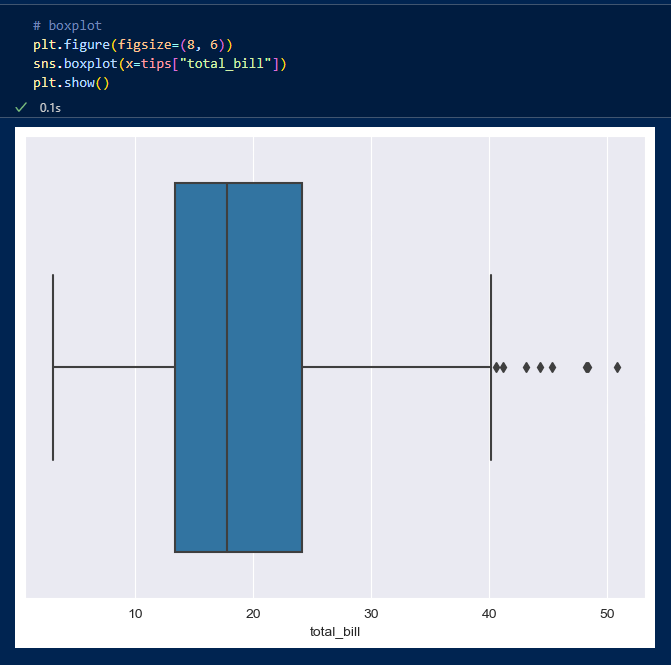
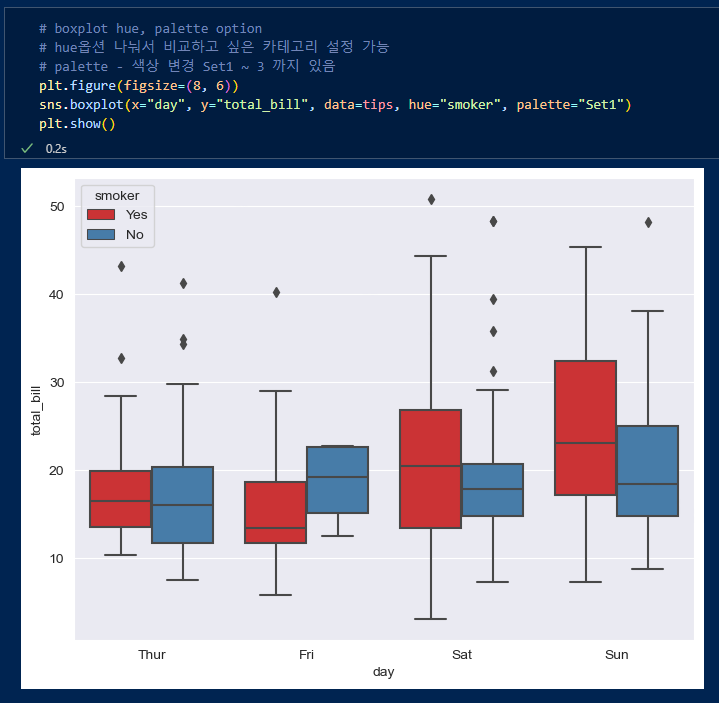
- boxplot
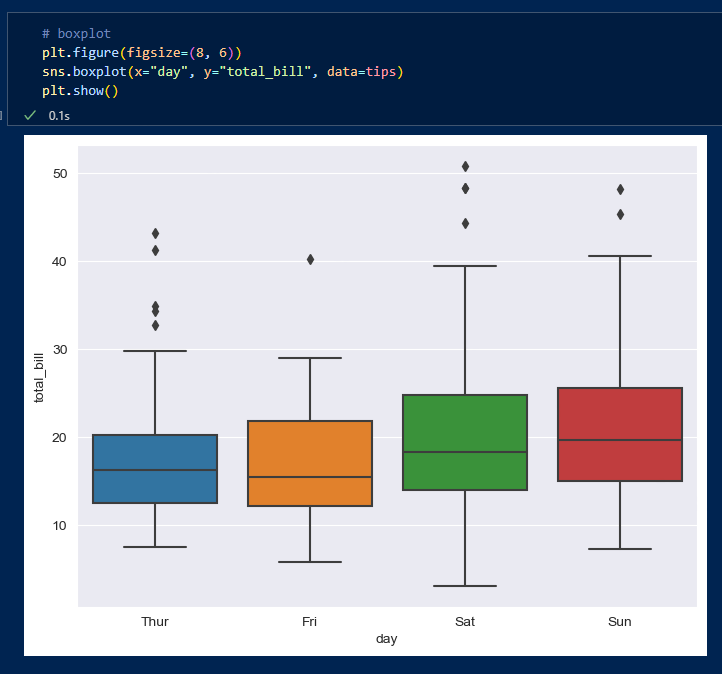
'hue'인자로 기준으로 구분지을수 있고 'palette'인자로 박스의 색상을 정할 수 있다.
- swqrmlot
boxplot과 sqqrmlot을 겹쳐쓸 수도 있다.
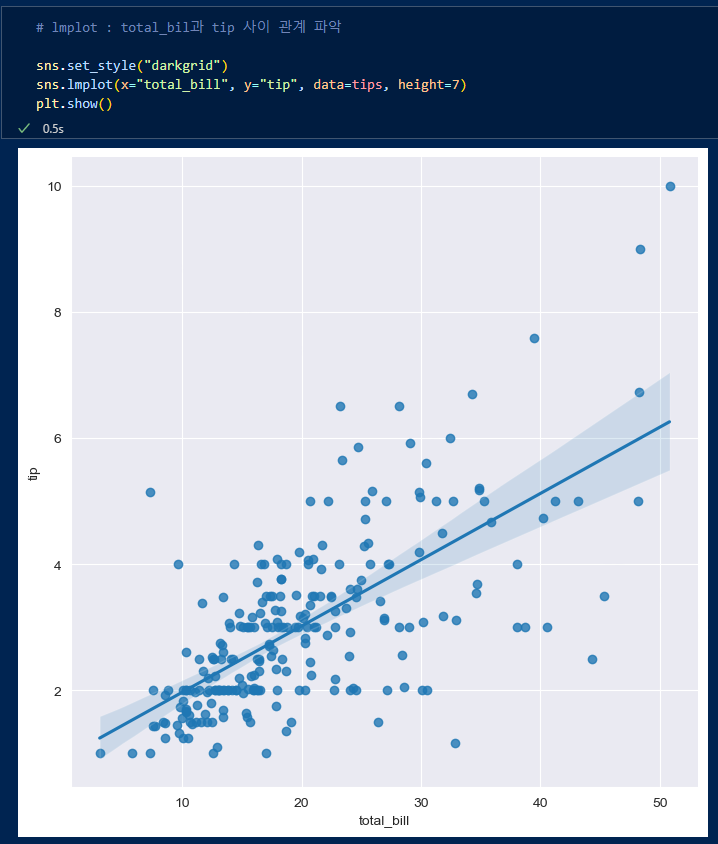
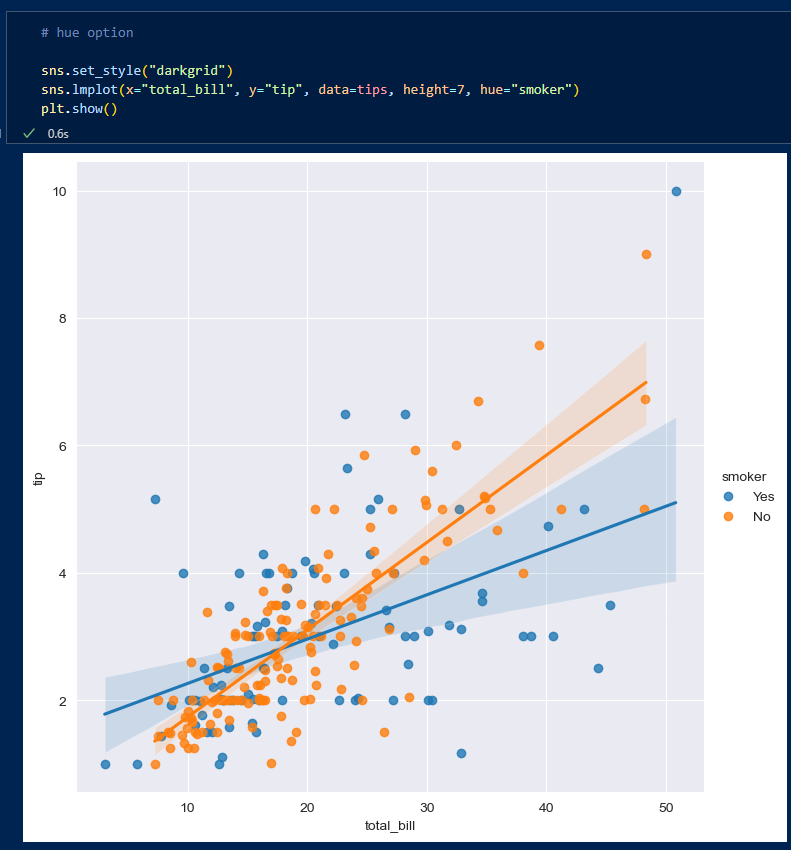
- lmplot
hue옵션으로 smoker을 주어 흡연 여부에 따라 팁의 차이가 나는 것을 알 수 있다.
예제3
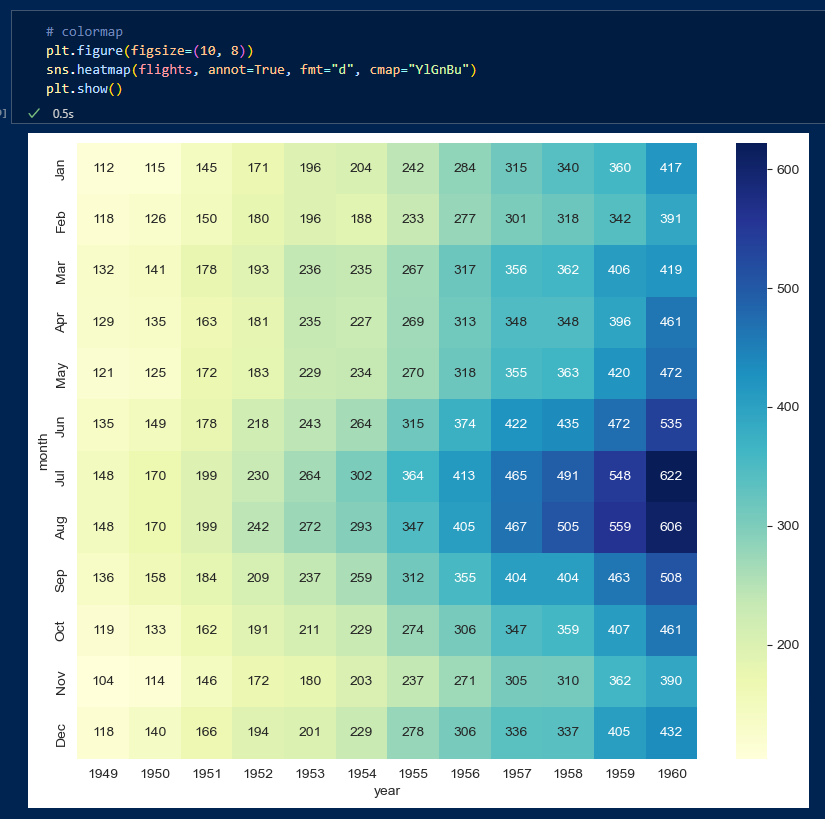
내장된 데이터셋 'flight'
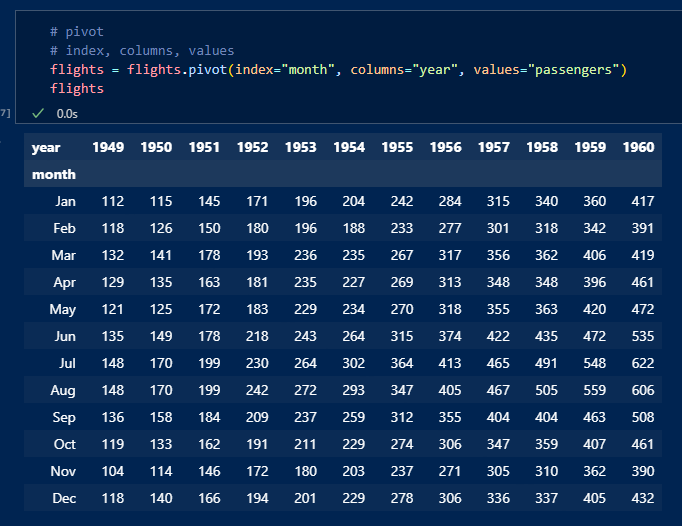
pivot_table을 이용하여 표로 매년 매월마다의 승객수를 표시.
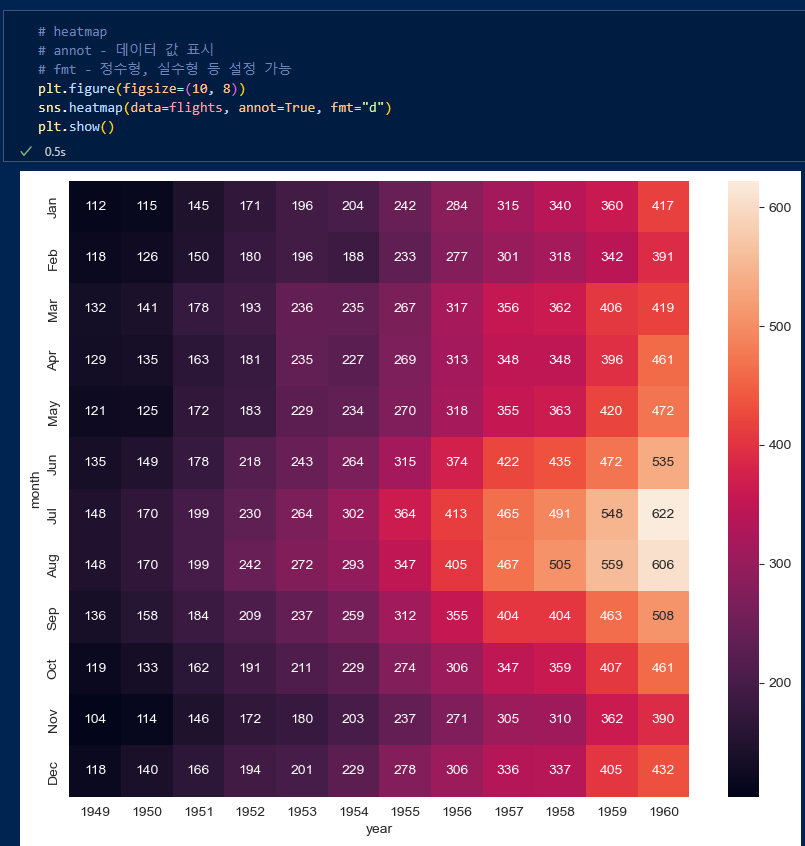
- heatmap그리기
annot는 데이터값을 표시여부, fmt는 표시할 데이터를 정수형으로 한다는 뜻.
colormap옵션으로 색상을 줄 수도 있음.
시각화 해보니 년도가 갈수록 july, aug 등 여름에 승객수가 많아지는 것을 쉽게 알 수 있음.
예제4
'iris' 데이터 셋 활용
- pairplot()
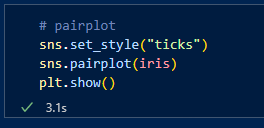
어떤 상관관계가 있는지 잘 알 수 없었다
species라는 컬럼이 있고, 구분자를 주어서 출력하면
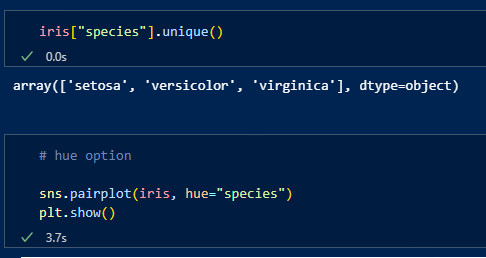
종에 따라서 분포되어있는 양상을 좀 더 쉽게 알 수 있다.
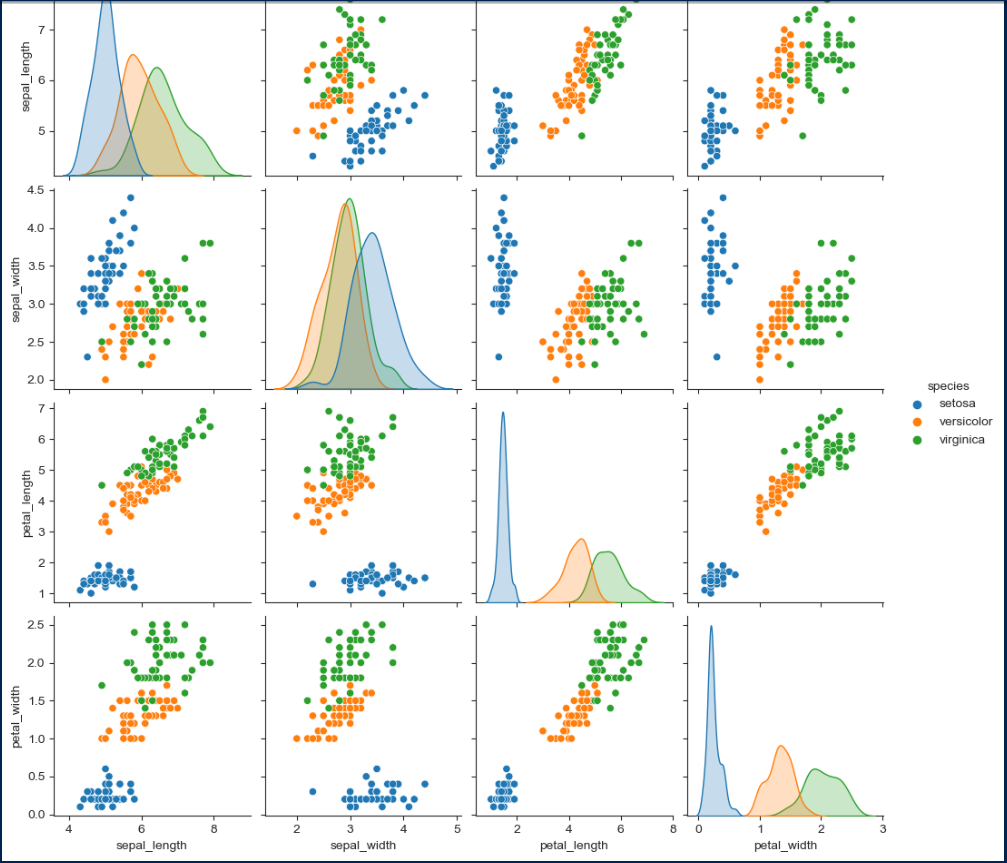
원하는 컬럼만 뽑아서 출력할 수도 있다.
예제3
'anscombe' 데이터 셋 활용
- lmplot
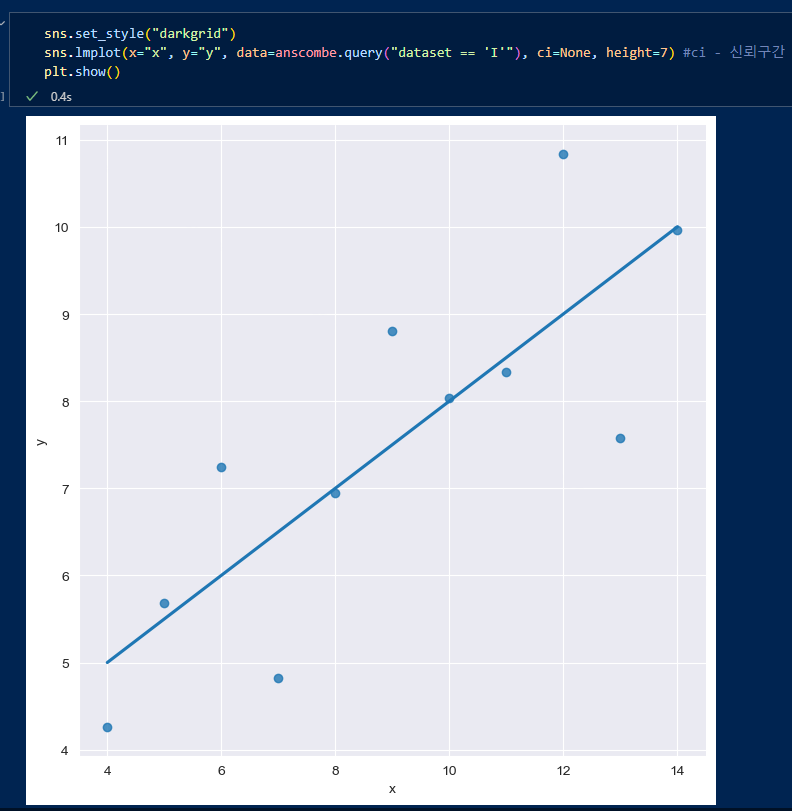
data인자에 dataset.query(조건)으로 특정 데이터만 쓸 수 있고, ci인자는 신뢰구간을 주지않을 수도 있다.
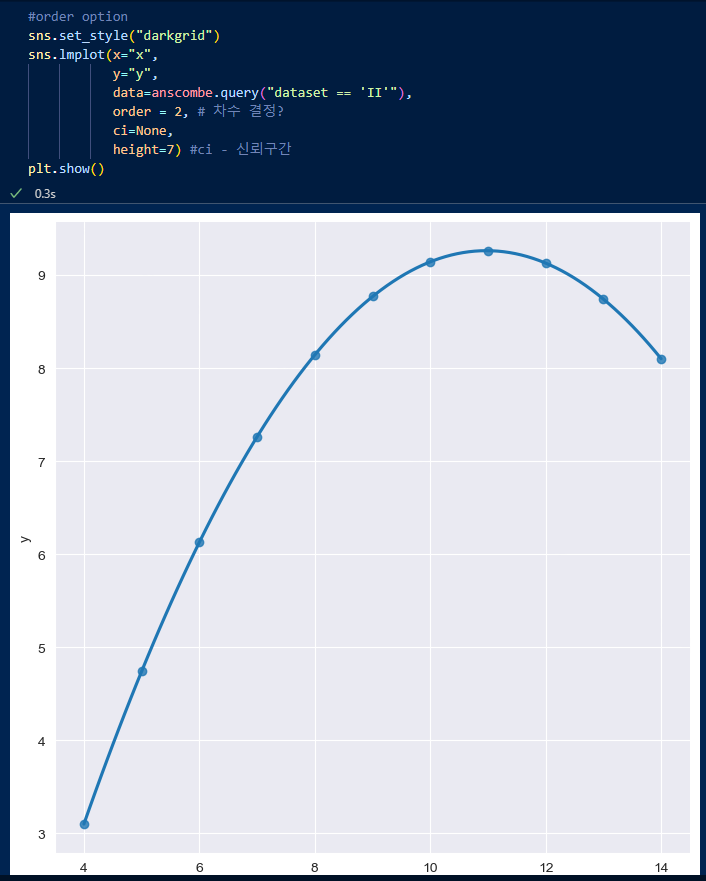
2차 함수를 그릴 수도 있는데, order인자에 '2'를 적어주어야 한다.
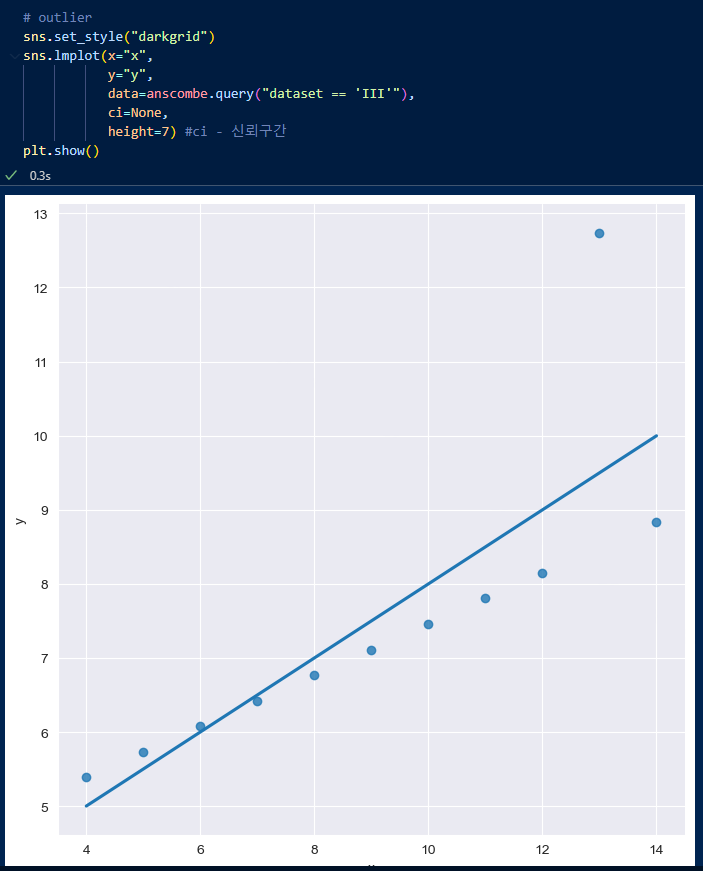
noise가 생겨서 경향과 맞지 않게 선이 비뚤어졌다.
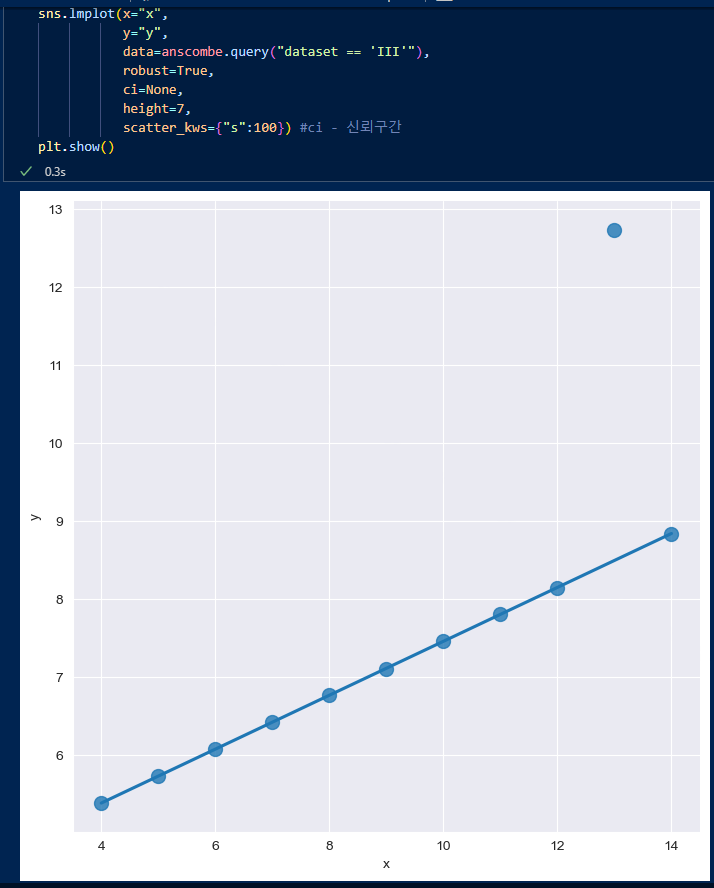
robust 옵션에 True를 주면 noise를 제외한다.
서울시 데이터 시각화
저장해두었던 'crime_anal_norm' 불러오기
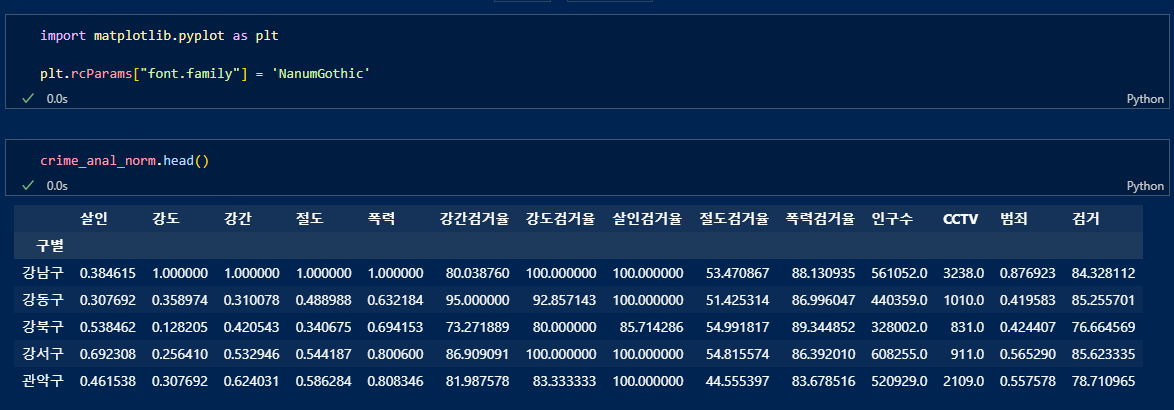
pairplot으로 강도, 살인, 폭력에 대한 상관관계를 확인.

기울기가 클 수록 상관관계가 있다고 볼 수도 있다.
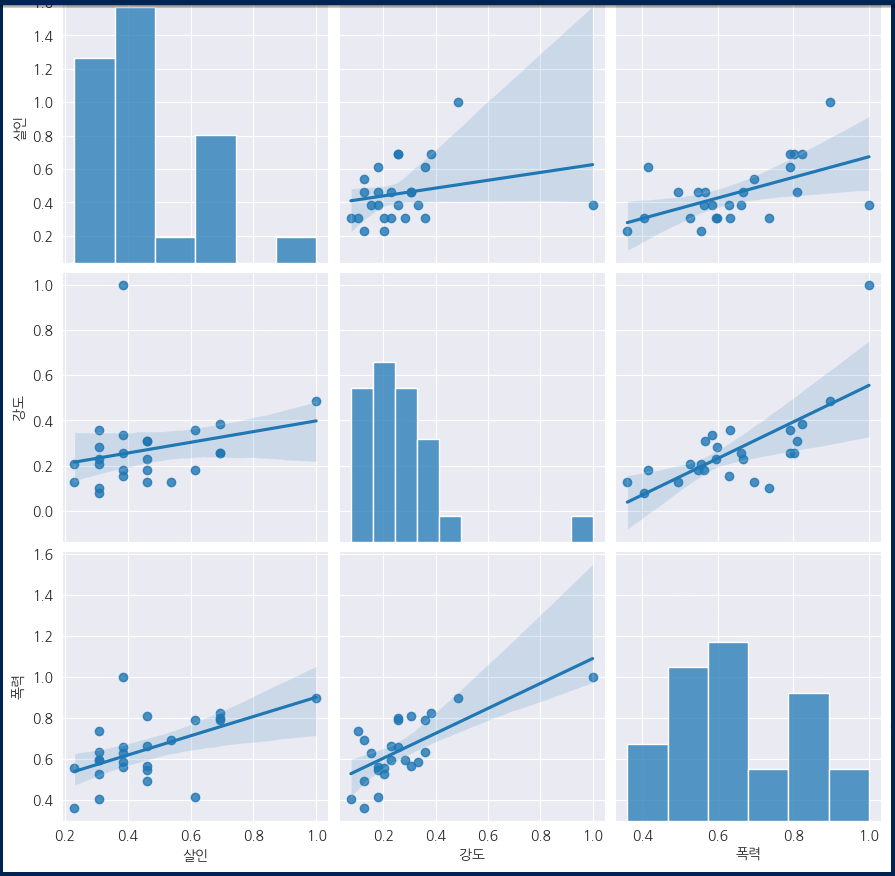
함수를 만들어서 출력. 인구수, CCTV가 X축 살인검거율, 폭력검거율이 y축.
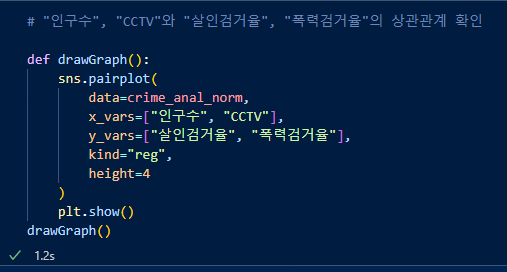
인구수 증가에 따라 강도, 살인 발생 관계 / CCTV수 증가함에 따라 강도, 살인 발생 관계
검거기준 내림차순 한다음, 각 범죄별 검거율을 출력.
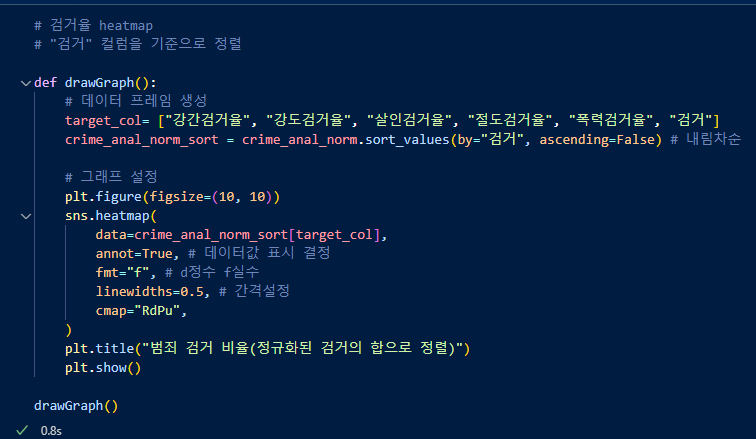
색이 진한 위에 구들이 검거율이 높은 경향이 있다고 볼 수 있음.
검거기준 내림차순 한다음, 각 범죄발생을 출력.
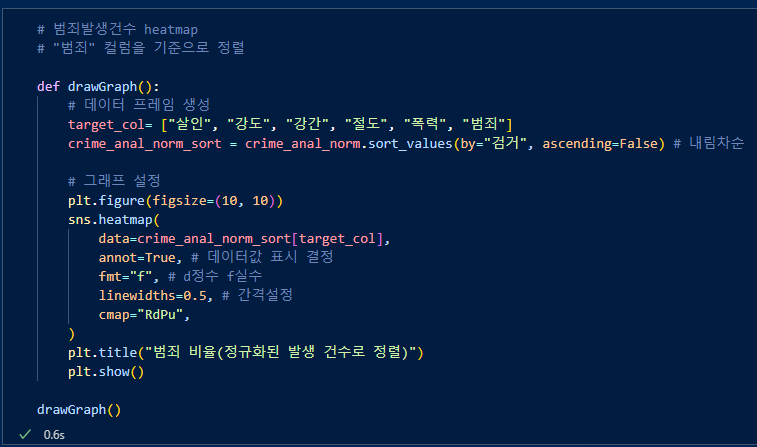
진한 색의 강남구가 범죄가 많이 일어난다는 것을 알 수 있다.
저장

folium
folium 설치, import하기. 지도맵을 받을 것을 대비 json도 import하기
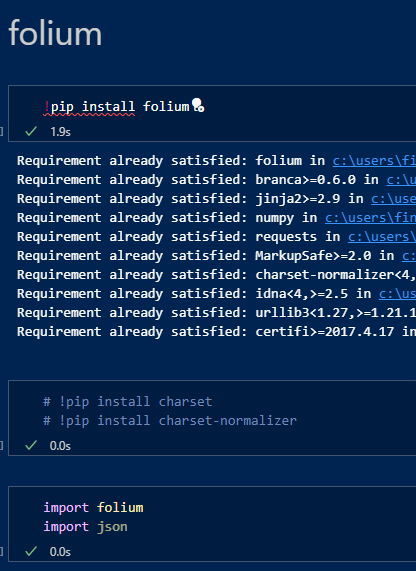
- folium.Map(locatiom=[lat:lng]) 좌표를 적어주면 지도로 나타내준다.
지도를 html로 저장가능
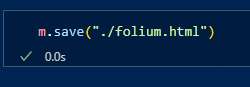
지도 타일의 옵션
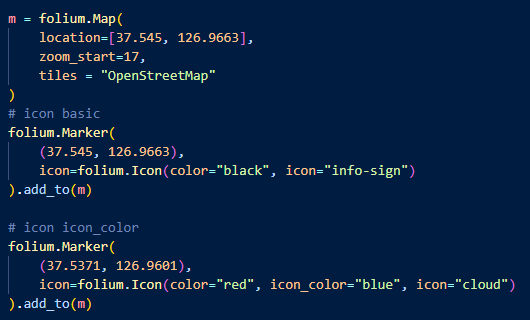
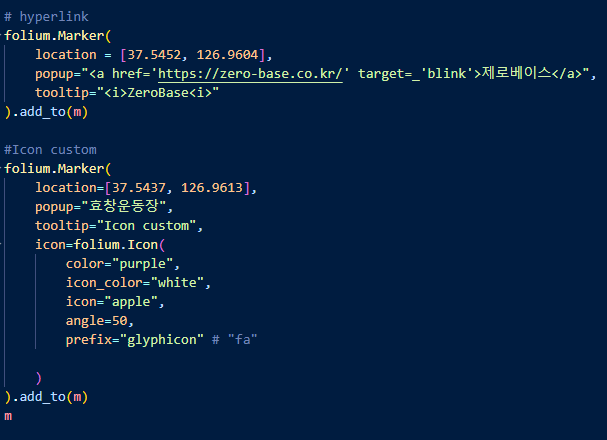
- folium.Icon() : icon의 marker, color, hyperling, popup등의 옵션을 줄 수 있다.
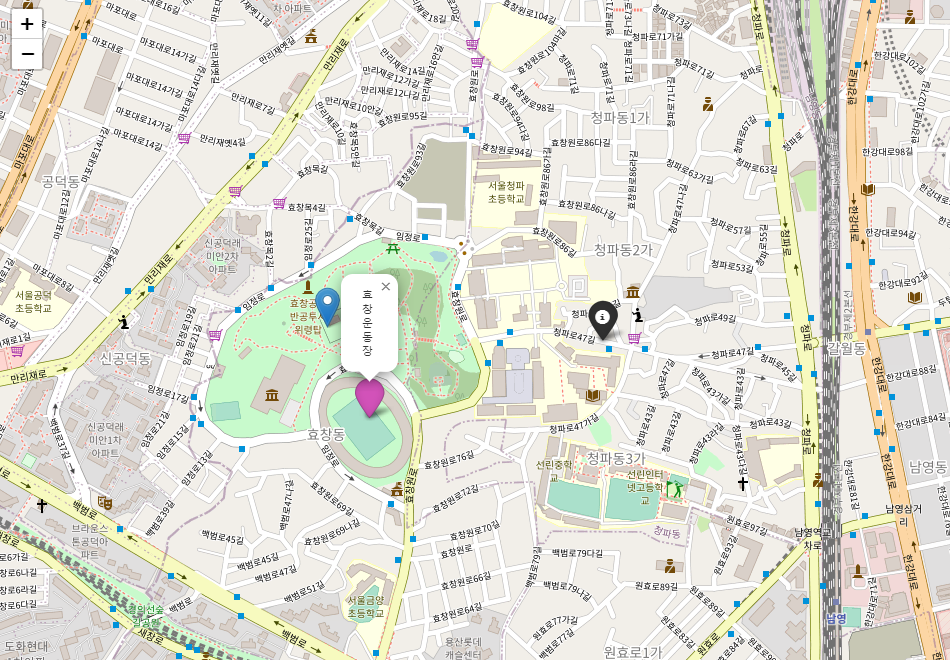
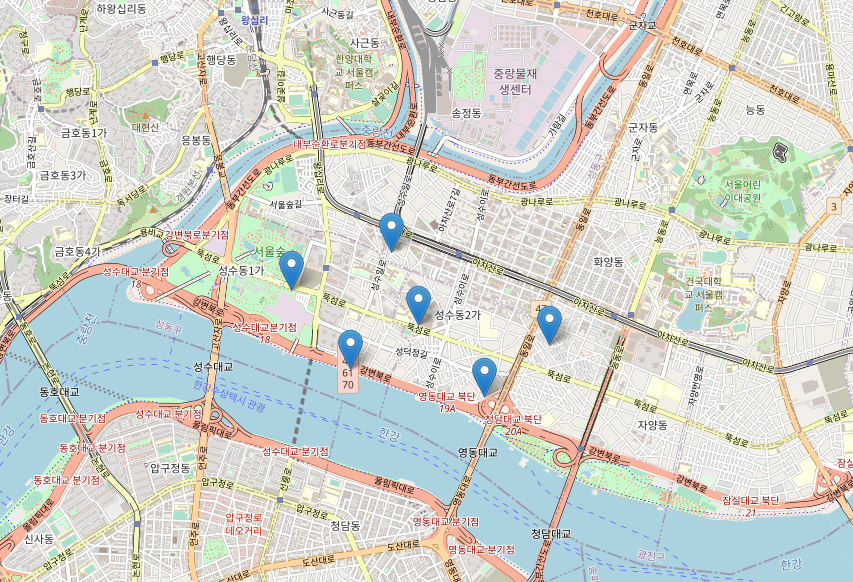
- folium.ClickForMarker() : 지도위에 마우스로 클릭했을 때 마커를 생성해줌.
클릭할 때마다 마커가 생성된다.
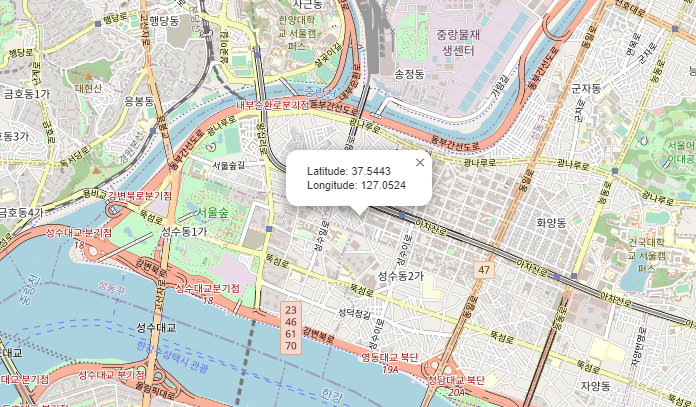
- folium.LatLngPopup() : 지도를 마우스로 클릭했을 때 위도 경도 정보를 반환해줌
- folium.Circle(), folium.CircleMarker() : 좌표 기준으로 원을 그려준다. popup이나 color의 옵션도 줄 수 있다.
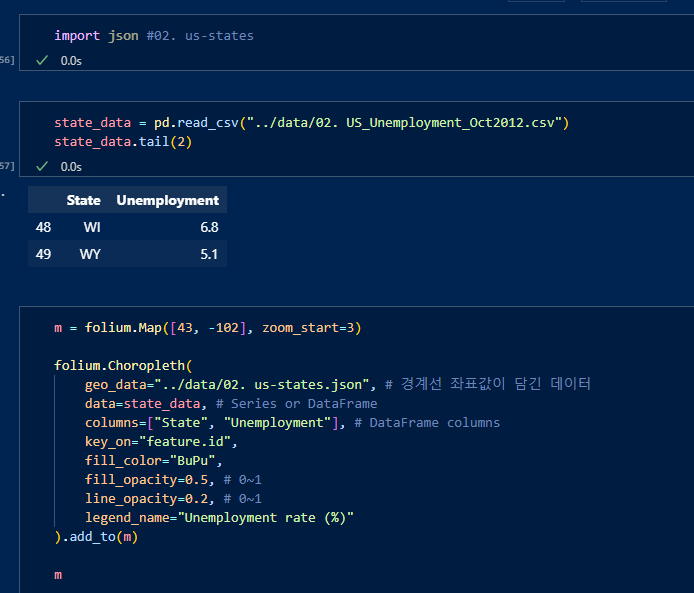
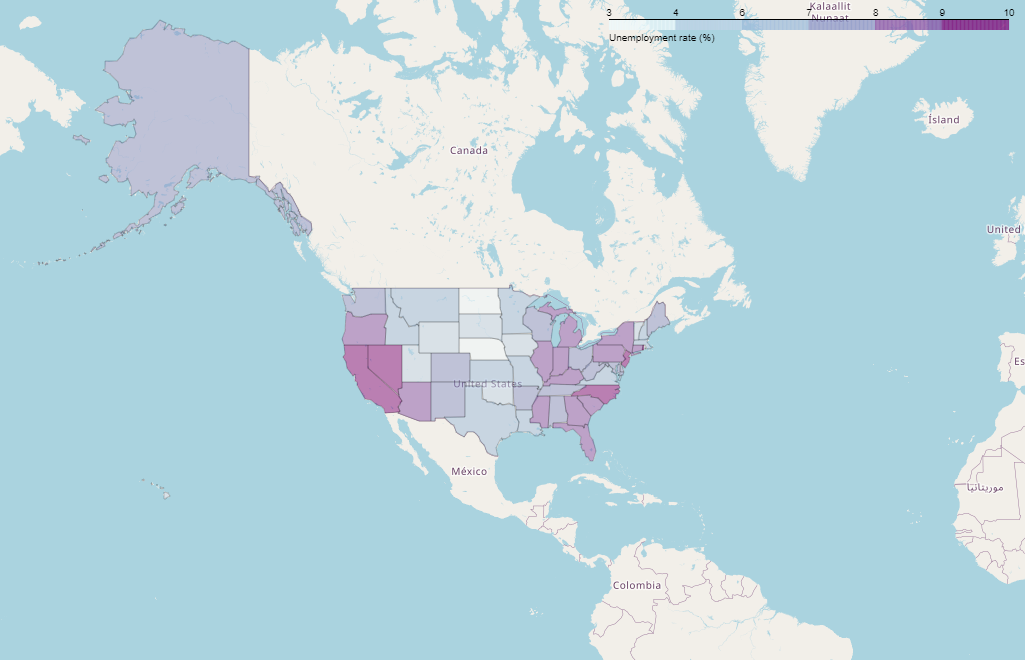
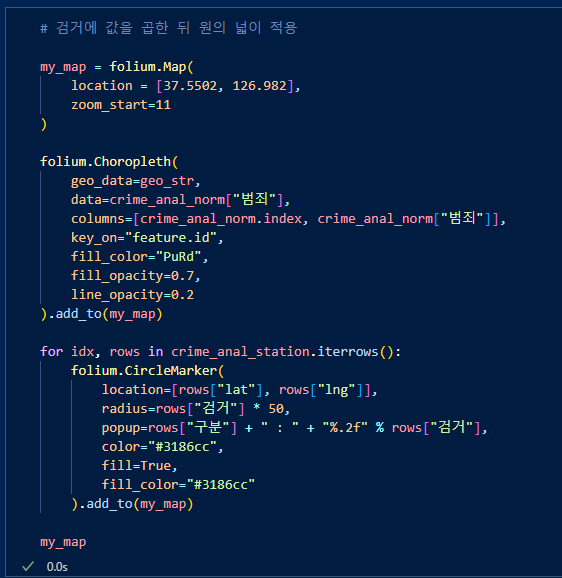
- folium.Choropleth()
미국 지도파일을 json으로 받고, 미국 실업률 데이터를 이용한다.
data인자에는 미국 실업률 데이터를 읽어온 state_data로 설정하고, geo_data는 미국 영토에 구분을 지어주는 json파일을 인자로 넣어준다음 컬럼과 색등의 옵션을 준다.
서울시 범죄 현황에 대한 지도 시각화
필요한 모듈 import, 서울시 범죄데이터를 가져오고, geo_path로 한국 지도를 json파일로 받아서 열어준다.
성범죄 건수에 따라 지도에 시각화. data는 성범죄 컬럼을 넣어주고, columns에 구index와 성범죄 컬럼을 넣어준다. 'feature.id'는 서울시의 각 구의 구간을 식별하는 속성이다.
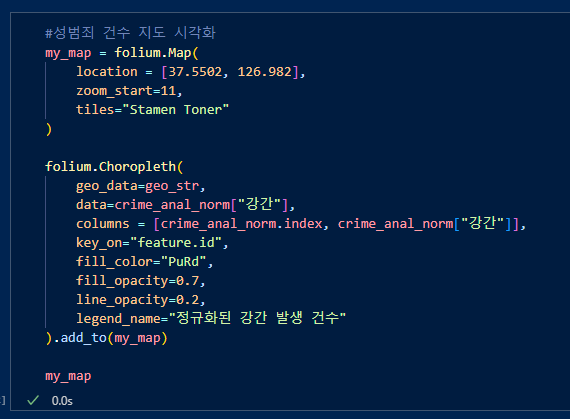
성범죄가 가장 많은 구는 강남구와 마포구.
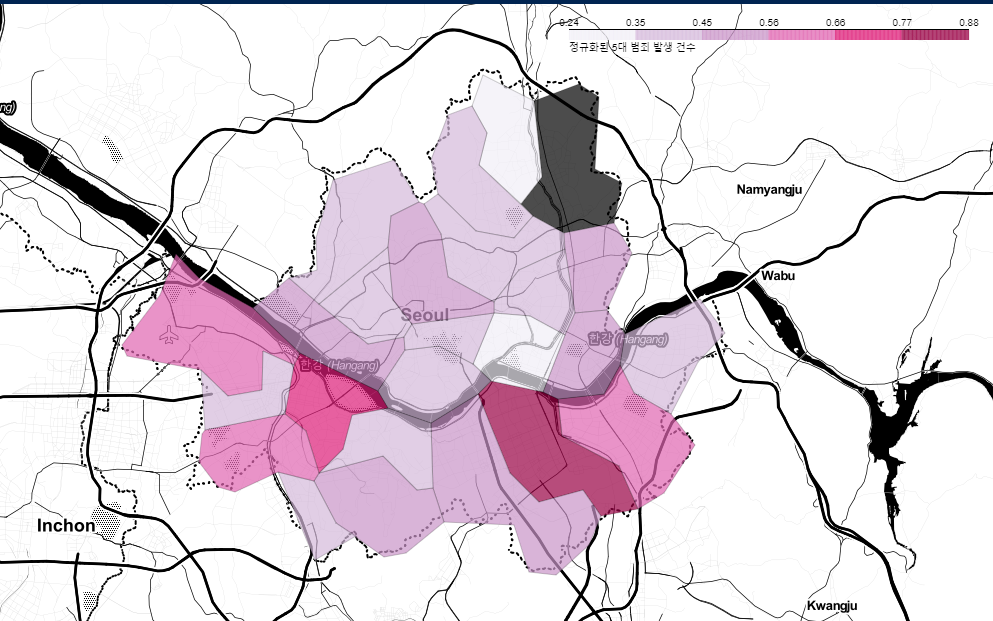
범죄컬럼을 넣어 범죄가 가장 많이 일어나는 구를 시각화.
강남구와 관악구가 눈에 띈다.
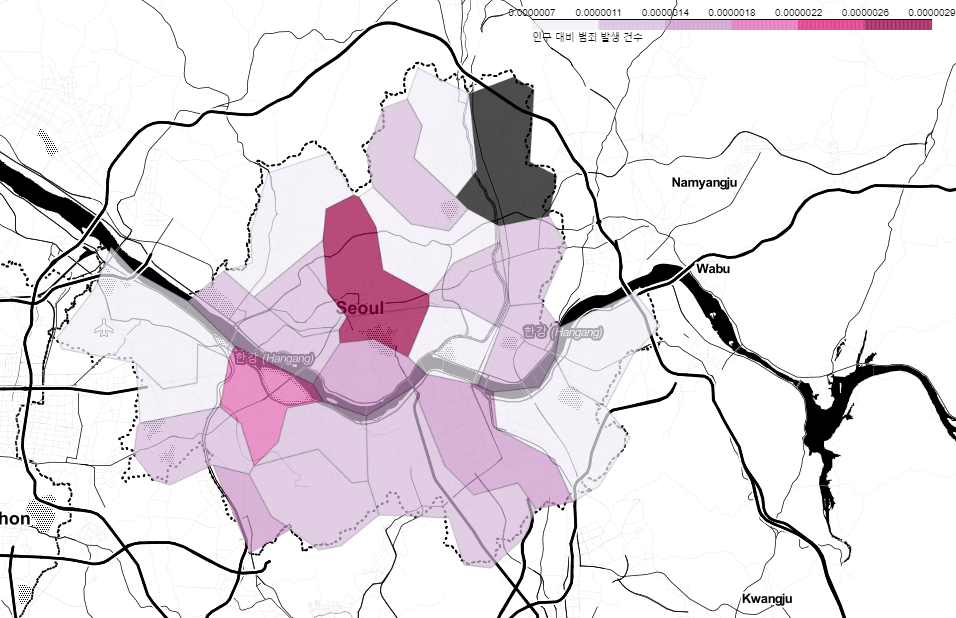
범죄 컬럼에 인구수 컬럼을 나누어 인구수 대비 범죄 발생 건수를 확인한다.
인구수 대비로는 중구와 관악구가 눈에 띈다.
경찰서별 검거데이터를 정규화하여 그 평균값(검거 종합 점수)을 "검거"컬럼에 넣어준다.
경찰서 데이터에서 각 서별 좌표값을 가져와 마커로 표시.
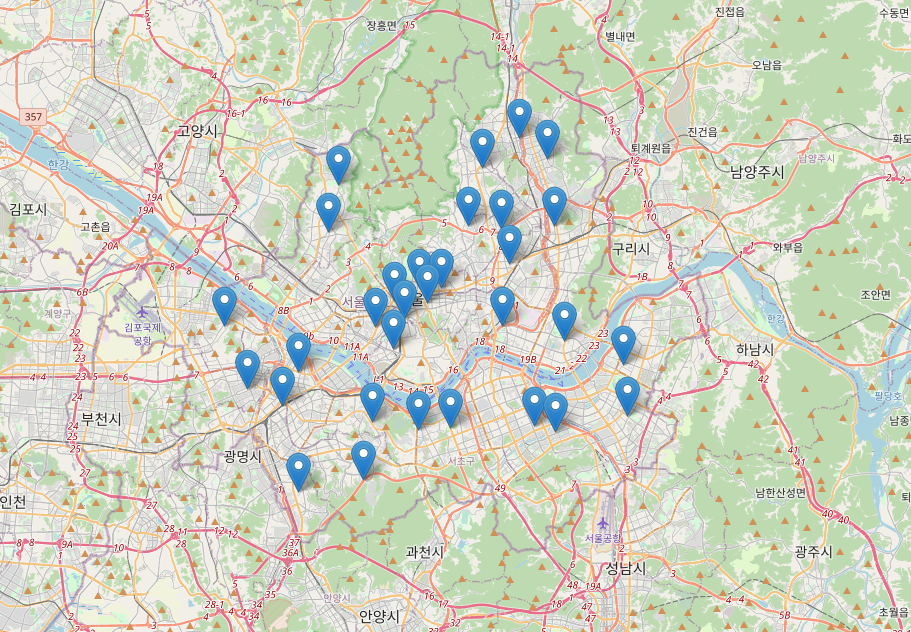
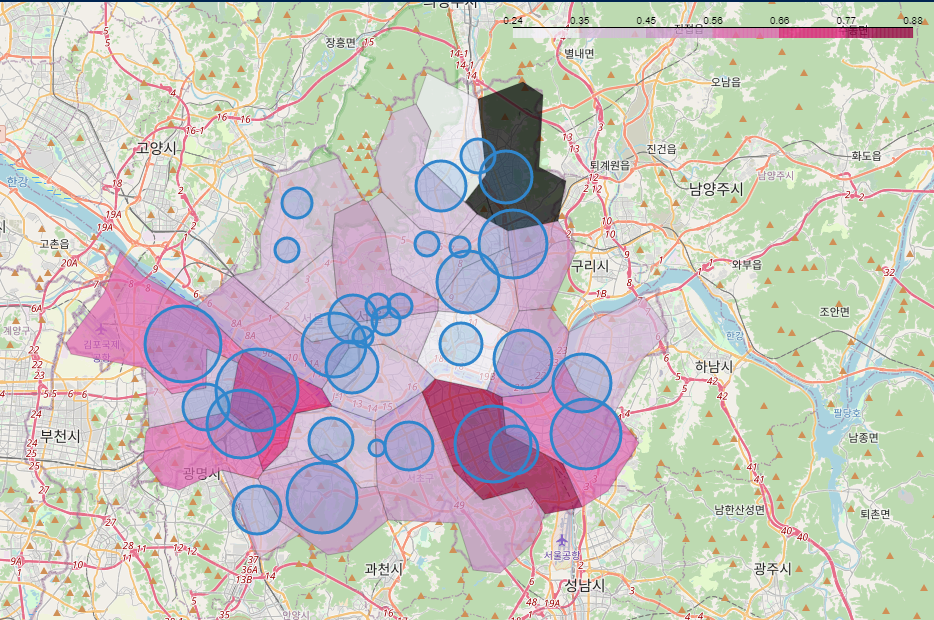
folium.Choropleth()를 이용, 서울시 구 구간을 표시하여주고 CircleMarker를 "검거(검거 점수)"컬럼을 기준으로 그려줌. 원이 클수록 검거 점수가 높음.
영등포구, 강서구, 강남구 순으로 높음.
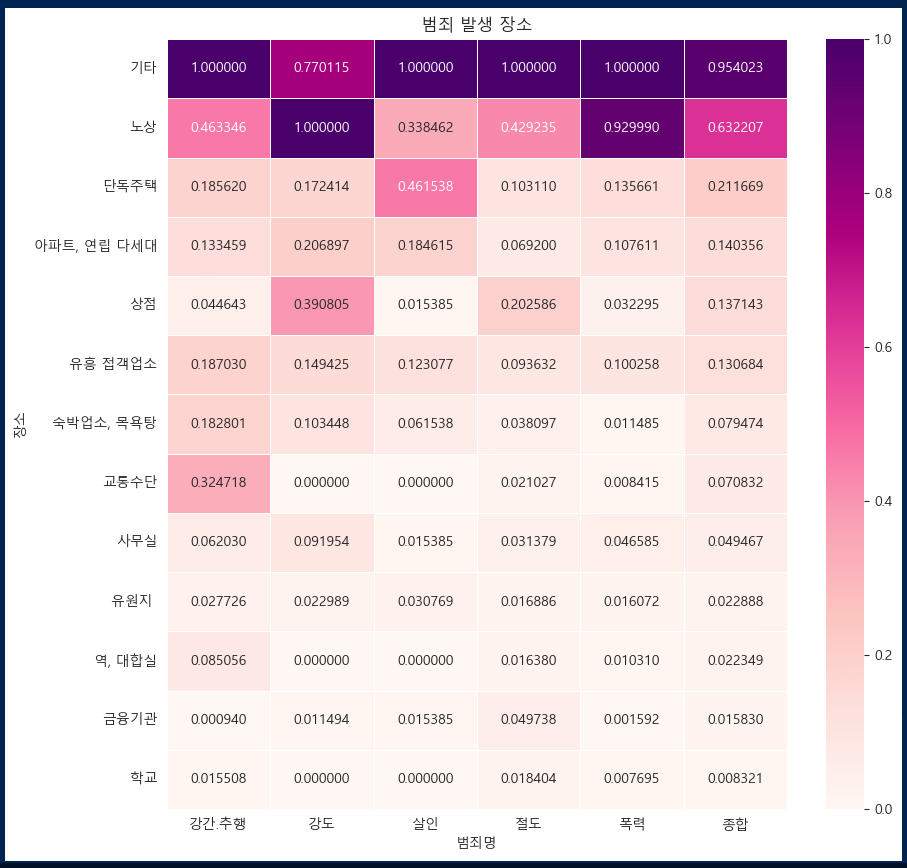
서울시 범죄 현황 발생 장소 분석
범죄가 발생한 장소 데이터 읽어오기. 범죄명, 장소, 발생건수가 담겨있음.
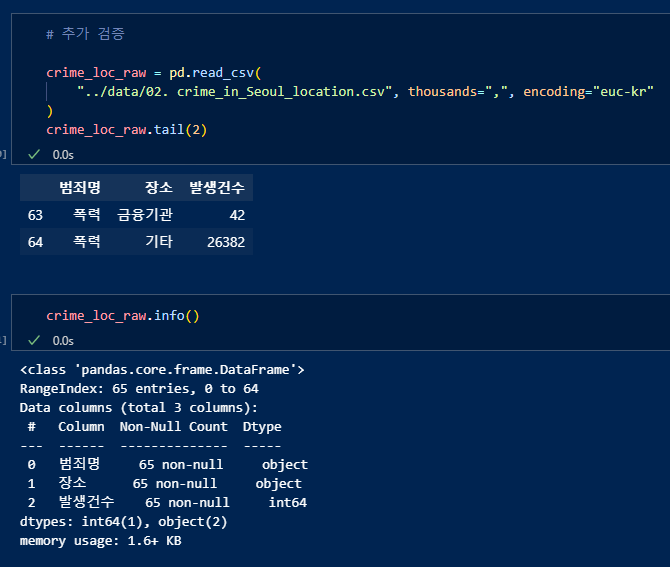
장소 데이터 종류 확인

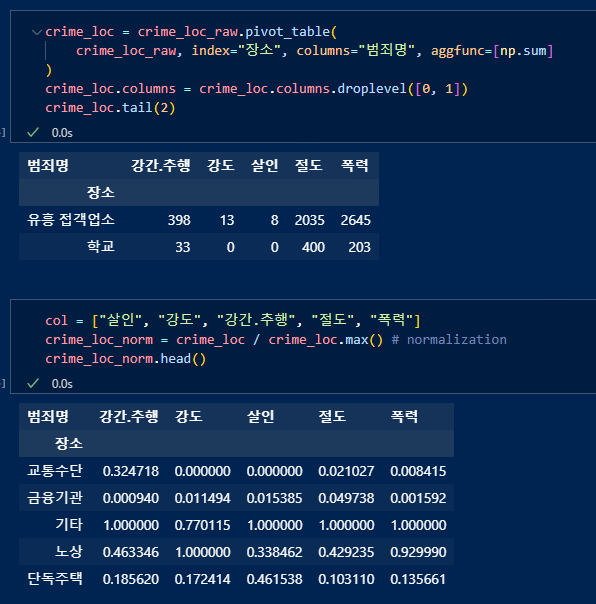
장소에 따른 범죄별 합산 출력. 각 범죄별 정규화.
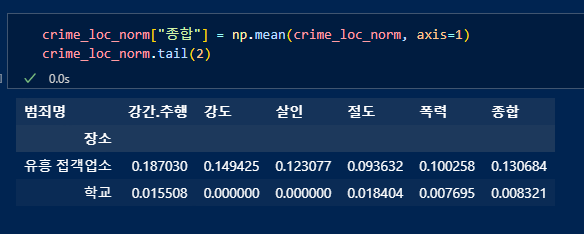
정규화한 장소별 데이터의 평균값을 "종합"컬럼 생성하여 할당.
종합컬럼 내림차순 정렬하여 히트맵으로 표현.
'기타', '노상' 이 범죄가 많이 발생한 장소임을 확인.