
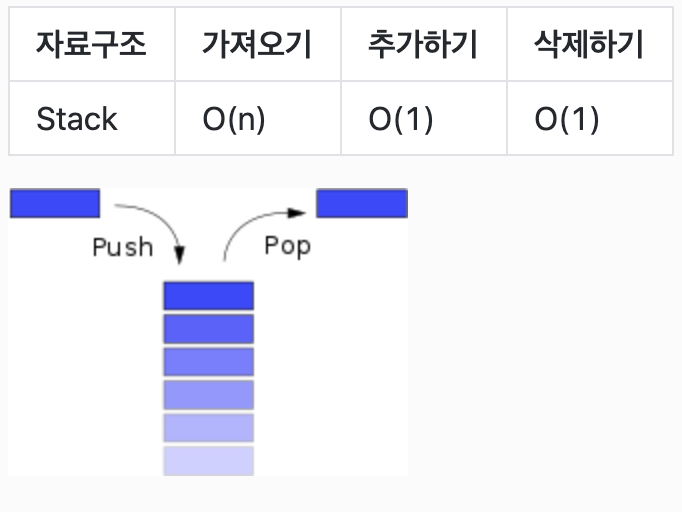
Stack
-
stack은 쌓여있는 접시 더미와 비슷한 개념. 쌓일때도 맨 위에서부터, 가져갈때도 맨 위에서부터.
-
(LIFO : Last in, First out)
-
스택을 사용한 예 : 포토샵에서 사용하는 ctrl+z(history), 웹브라우저의 뒤로 가기 등
-
stack method :
pop: 데이터를 스토리지에 넣음
push: 데이터를 스토리지에서 빼냄
peek: 최상위 데이터(마지막 데이터)를 추적함
size: 스토리지의 크기를 나타냄 -
stack 장점 : 구현이 쉽고 원하는 데이터의 접근 속도가 빠르다
단점 : 데이터 최대 갯수를 미리 정해야한다. 데이터 삭제와 삽입에 있어 비효율적
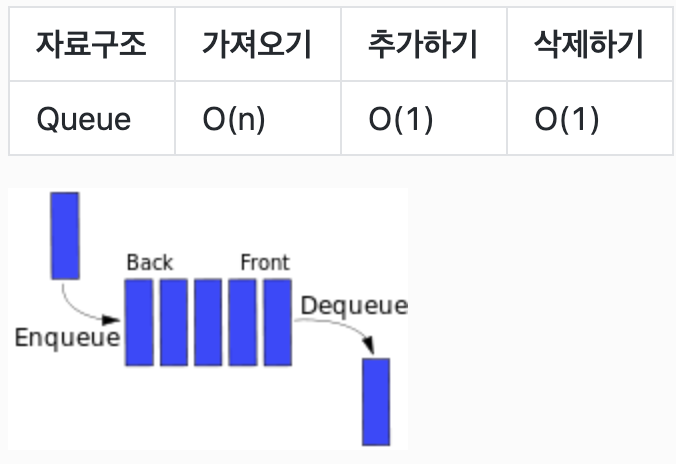
Queue
-
queue는 줄서는것과 같은 개념. (rear)맽 끝에서부터 줄을서고, (front)맨 앞에서부터 탑승.
-
(FIFO : First in, First out)
-
Queue를 사용한 예 : 우선순위가 같은 작업 예약, 선입선출이 필요한 대기열, 프린터의 출력 처리, 캐시 구현
-
Queue method :
enqueue : 데이터를 스토리지 안에 추가
dequeue : 스토리지에서 제거
size : 스토리지의 크기
empty : 데이터의 유무 반환 -
Queue 장점 : 데이터가 입력된 시간 순서대로 처리해야할 상황에 효율적.
단점 : 배열의 크기가 정해져 있기 때문에, 데이터가 다 차게 되면 추가하는데 시간이 오래걸리거나 불가하다.
데이터를 뺐을때, 빈 공간을 사용할 수가 없어서 메모리가 효율적으로 사용이 불가. 단점을 보완하기 위해 만든 자료구조는 원형 큐(Circular Queue)라고 한다.
- Circular Queue : 제일 처음 시작하는 인덱스를 비워 놓고 다음 인덱스부터 저장을 한다.
우선 삽입 후 데이터를 빼는 이유때문, 혹은 큐의 데이터 저장사이즈를 판단하기 위해서 필요.

Linked List
- 연결리스트는 동적인 자료구조이다.
- 자료구조를 구성하는 요소는 노드(Node)
- 노드의 연결로 이루어진 자료구조.
- 인덱스를 갖지 않으며, 어떤 특정 데이터를 연결 리스트에서 검색하고자 하면, 처음부터 전체 연결리스트를 돌아야한다
- 장점 : 배열보다 데이터 추가가 용이하고 메모리를 효율적으로 쓸 수 있다.
단점 : 특정 위치의 데이터를 검색하기 위해서는 처음부터 끝까지 순회해야함 - 연속되는 항목들이 포인트가 다음 노드를 향하여 연결되어 있고 마지막 노드는 null을 가리킨다.
- head의 링크를 끊어버리면 데이터가 삭제되기 때문에 전체 삭제 가능
- Linked List를 사용한 예 : 지하철노선도
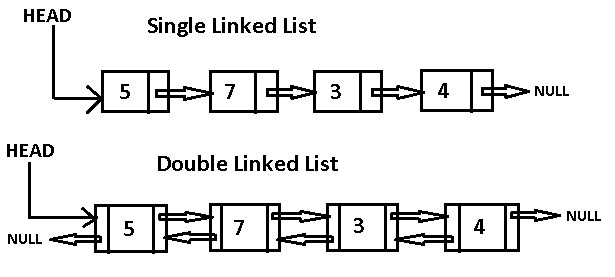
Sigly linked list
(일방향 연결 리스트) : 단일 방향, 이전노드로 갈 수가 없다. 4바이트 차지
Douvlt linked list
(이중 연결 리스트) : 노드 하나에 포인트가 두개 있는 이중 연결 리스트, 이전노드로 갈 수가 있음. 그만큼 데이터가 두배로 사용되 8바이트를 차지
Circular linked list
(환형 연결 리스트) : 헤드와 테일이 붙어 있는 모양. 테일의 포인터가 헤드를 가리키고 있음. 순회할때 좋은 연결리스트
HashTable
- 연관 배열을 이용하여 키에 결과 값을 저장 하는 원리.
- 해시테이블 혹은 해시 맵은 키 값,쌍을 저장하고 있는 자료 구조.
- 키를 저장할 때에 메모리 공간을 효율적으로 사용하기위해 키를 해시 함수(Hash function)를 통해 특정 숫자값의 인덱스로 변환한다.
- 해쉬테이블은 가능한 작은 크기를 유지한다.
- HashTable을 사용한 예 : 핸드폰 전화번호 주소록
- 장점 : 해싱된 키를 가지고 배열의 인덱스를 사용하여 검색하기 때문에 삭제 및 탐색이 쉽고 빠르다
단점 : 해시 함수를 따로 구현해야함. 해시 테이블의 크기가 유한적. 충돌이 일어날 수 있음 - 해시테이블의 size는 25% ~ 75%의 공간을 맞추기 위해 resizing을 함
75%이상 데이터가 차지하면 공간을 2배로 늘린다. 혹은 25%밑으로 차지하면 2배 줄인다.
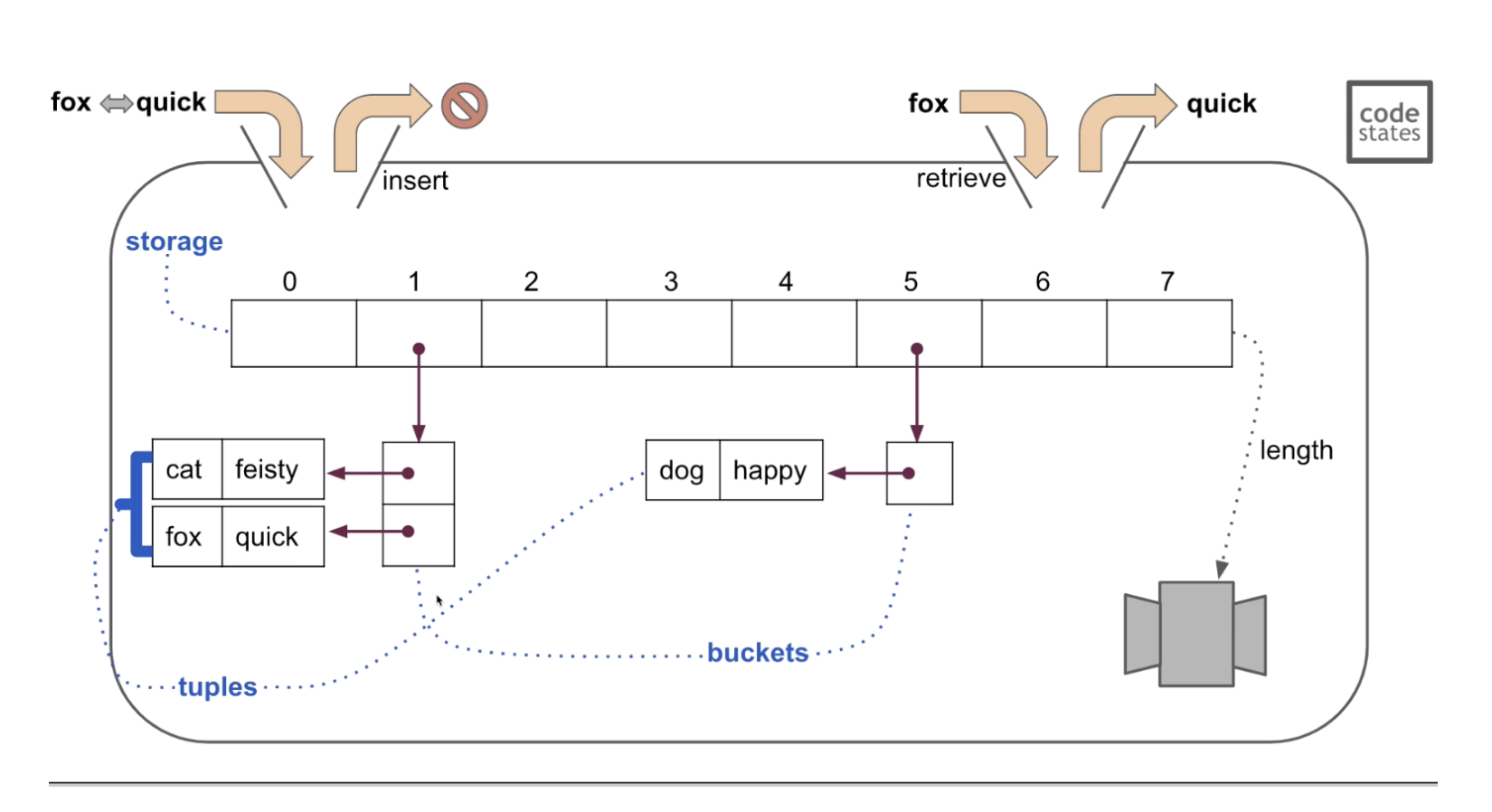
해시 충돌
문자열은 무한하고 인덱스는 유한하므로 하나의 인덱스에 여러개의 문자가 들어갈 수 있음
해시 충돌을 피하기 위해선 두가지 방법이 있다.
1. open addressing
: 충돌이 발생하면, 옆 인덱스가 비어 있는지 검사 후 비었을 경우 저장
- 선형 탐사 : 충돌이 일어난 바로 다음의 비어있는 자리를 찾아 저장
- 이중 해시 : 충돌이 일어난 인덱스로부터 빈 버킷을 찾기위해 두개의 해시 함수를 사용해 탐색을 불규칙적으로 한다음 저장
2. close addressing
: 충돌이 일어나도 그 인덱스에 저장.
- 버킷에서 충돌된 값들을 연결리스트로 연결 튜플을 만든다, 이 과정을 체이닝이라고 한다.
- 버킷(bucket) : 데이터가 들어갈 공간. 인덱스에 담겨 있고 버킷 하나가 들어간다.
- 튜플(tuple) : 버킷안에서 데이터들을 담고 있는 공간. 키와 값으로 이루어져있고 읽기전용이라 추가, 삭제등이 불가
