Bloom Filter 란?
-
Bloom Filter는 특정 원소가 집합에 속하는지 검사하는데 사용할 수 있는 확률형 자료 구조
-
굉장히 빠르고, 메모리 효율적
-
하지만 확률형 자료 구조이기 때문에 가끔 틀린 사실을 뱉어낸다.
-
집합에 속한 원소를 속하지 않았다고 말하는 일(False Negative)은 절대 없으며, 반대로 속하지 않은 원소를 가끔 속해있다(False Positive)고 할때는 있다.
- 예를 들어서 ('aa', 'bb', 'cc', 'dd')라는 집합을 Bloom Filter를 이용해 저장하면 이 안에 'xx'라는 원소가 있는지 검사했을 때 있다고 얘기할 수도 있지만 'aa'라는 원소가 있는지 검사했을 때 없다고 나올 일은 절대 없다
Bloom Filter의 원리

-
Bloom Filter의 원리는 비교적 간단하다. 해싱 함수를 이용해서 원소를 해싱한 다음, 위 그림처럼 모두 더한다.
-
그 후 원소의 존재 여부를 검사할 때는 검사 대상 원소를 해싱한 다음 Bloom Filter에 계산된 해시가 마스킹되어 있는지 확인한다.
어디에 쓰는가?
- 집합의 크기가 굉장히 크거나 집합의 속해있는 원소의 크기가 커서 원소가 집합에 속해있는지 정확히 판단하는데 시간이 오래걸리는 경우 이 과정의 전처리 과정으로 Bloom Filter를 이용해서 아예 집합에 속할 일이 없는 원소를 미리 걸러낸다.
- 예를 들어 필자는 중복된 상품들을 걸러내기위해 Bloom Filter를 이용하여 paging 처리시 한번 노출된 상품들은 중복을 제거하여 노출하는 방법으로 paging 처리할때 넘겨주는 cursor의 크기를 커지지 않게 만들며 효율적으로 메모리를 사용할 수 있게 구현하였다.
- Google Chrome은 위험한 사이트 검사에 Bloom Filter를 사용한다고 알려져있는데 Bloom Filter를 사용해서 빠르게 대충 검사한 다음, 의심이 가는 사이트인 경우 데이터베이스에 다시 정확하게 검사하는 것으로 위험 사이트 데이터베이스의 크기가 크고, 검사 요청이 굉장히 빈번하게 일어나기 때문에 Bloom Filter를 전처리 과정으로 사용해서 데이터베이스 요청 부하를 줄이는 것으로 보인다.
- 비트코인도 내부적으로 Bloom Filter를 사용하는 것으로 알려져 있으며 보통은 Disk IO를 줄이기 위한 최적화 방법으로 많이 사용된다.
코드 구현
class BloomFilter(
private val size: Int,
private val hashCount: Int
) {
private val bitArray = BitSet(size)
private fun hash(value: String, seed: Int): Int {
return (value.hashCode() * seed % size).absoluteValue
}
fun add(value: String) {
repeat(hashCount) {
val index = hash(value, it + 1)
bitArray.set(index)
}
}
fun contain(value: String): Boolean {
return (0 until hashCount).all {
val index = hash(value, it + 1)
bitArray.get(index)
}
}
fun serialize(): ByteArray {
return bitArray.toByteArray()
}
companion object {
fun deserialize(data: ByteArray, size: Int, hashCount: Int): BloomFilter {
val filter = BloomFilter(size, hashCount)
filter.bitArray.or(BitSet.valueOf(data))
return filter
}
}
}해싱 과정 예시
val value = "PID_123"
val size = 1000 // 비트 배열 크기
val hashCount = 3 // 해시 함수 개수private fun hash(value: String, seed: Int) 동작
-
첫 번째 해시 (seed = 1)
- value.hashCode() → 123456789 (가정).
- 123456789 * 1 = 123456789.
- 123456789 % 1000 = 789.
-
두 번째 해시 (seed = 2)
- 123456789 * 2 = 246913578.
- 246913578 % 1000 = 578.
-
세 번째 해시 (seed = 3)
- 123456789 * 3 = 370370367.
- 370370367 % 1000 = 367.
fun add(value: String) 동작
-
첫 번째 해시 (seed = 1)
- 인덱스 789 선택 → bitArray[789]를 1로 설정.
-
두 번째 해시 (seed = 2)
- 인덱스 578 선택 → bitArray[578]를 1로 설정.
-
세 번째 해시 (seed = 3)
- 인덱스 367 선택 → bitArray[367]를 1로 설정.
-
Bloom Filter의 비트 배열에서 다음 인덱스들이 1로 설정
- bitArray[789]
- bitArray[578]
- bitArray[367]
fun contain(value: String): Boolean 동작
-
다시 “PID_123”를 확인할 때
- 동일한 해싱 과정을 반복하여 789, 578, 367을 계산.
- 비트 배열에서 이 세 위치가 모두 1인지 확인.
- 세 위치가 모두 1이면 “PID_123”가 이미 존재한다고 판단.
-
새로운 값 “PID_456”을 추가하려 하면
- 해싱 결과가 새로운 위치(bitArray[123], bitArray[456], 등)로 나올 가능성이 높음.
- 새로운 위치 중 하나라도 0이면 해당 값은 존재하지 않는다고 판단.
왜 Bloom Filter는 빠르고 메모리 효율적인가?
- 문자열(“PID_123”)을 저장하지 않고도, 고유한 인덱스 조합만으로 값을 추적.
- 메모리 사용량이 매우 적음. 예: 비트 배열 크기(size)가 1000이면 125바이트(1비트 × 1000 = 125바이트)만 사용.
- 추가적으로 해시 함수(hashCount)만큼의 연산으로 빠르게 중복 여부 확인 가능.
hashCount(해시 함수의 개수)와 size(비트 배열 크기)
- hashCount와 size는 트레이드오프 관계
- 너무 큰 size는 메모리를 많이 사용하지만, 오탐률을 줄이는 데 효과적
- 너무 많은 hashCount는 정확성을 높이지만, 계산 비용이 증가
hashCount
- 정확성을 높이려면 hashCount를 높인다.
- hashCount = 1일 때는 하나의 위치만 확인하므로 충돌 가능성이 높지만, hashCount = 3일 때는 세 위치를 확인하므로 충돌로 인한 오탐률(FP, False Positive)이 줄어든다.
- 하지만 너무 큰 hashCount는 각 값을 추가하거나 확인할 때, 해시 함수를 여러 번 호출해야 하므로 계산 비용이 증가하여 Bloom Filter의 성능을 저하시킬 수 있다.
- k : 해시 함수 개수 (hashCount)
- m : 비트 배열 크기 (size)
- n : 예상 삽입 값의 개수 (예: 상품 리스트의 개수)
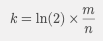
size
- 비트 배열의 크기가 작으면 충돌이 발생할 가능성이 높아져서 삽입 값이 갯수가 많아지면 size를 증가시켜야 한다.
- 비트 배열 크기(size)가 10일 때, 여러 값을 추가하면 이미 설정된 비트가 반복적으로 사용되므로 많은 값이 충돌하게 된다.
- m : 비트 배열 크기 (size)
- p : 허용할 오탐률(예: 0.01 = 1% 허용)
- n : 예상 삽입 값의 개수 (예: 상품 리스트의 개수)
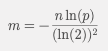
참고

Data Engineer