1. Elastic Search란?

- Apache Lucene(아파치 루씬) 기반의
Java 오픈 소스 분산 검색 엔진 - 방대한 양의
비정형 데이터를 신속하게,거의 실시간(NRT, Near Real Time)으로 저장, 검색, 분석 가능 RESTful API기반 CRUD 처리- 요청/응답 데이터 포멧으로
JSON사용(JSON 기반의 스키마 없는(스키마리스) 저장소 - 역색인 기반 데이터 탐색(검색) ⇒ 일반 DB보다 월등히 빠름
- scale out하여 분산 환경에서 사용 가능, shard 단위로 분산
- Elastic Search 단독으로 쓰이기도 하지만,대부분 ELK(Elasticsearch/Logstatsh/Kibana) Stack으로 함께 쓰임
2. Elastic Search의 특징
Scale out
- 샤드를 통해 규모가 수평적으로 늘어날 수 있다
- 프라이머리 샤드와 리플리카를 통해 규모 확산 가능
고가용성
- Replica를 통해 데이터의 안정성을 보장
Schema Free
Json문서를 통해 데이터 검색을 수행하므로 스키마 개념이 존재하지 않는다
RESTful
- 데이터 CRUD 작업은 HTTP RERTful API를 통해 수행한다
- curl
- kibana devtool
3. Elastic Search의 핵심 개념
- 색인과 역색인
- 색인 : 책의 목차 개념
- 역색인 : 책 맨 뒷 부분의 키워드 검색
역색인 기능은 일반 DB에는 없고, ES에만 있는 기능이 기능으로 인해서 ES가 일반 DB에 비해 월등히 빠름
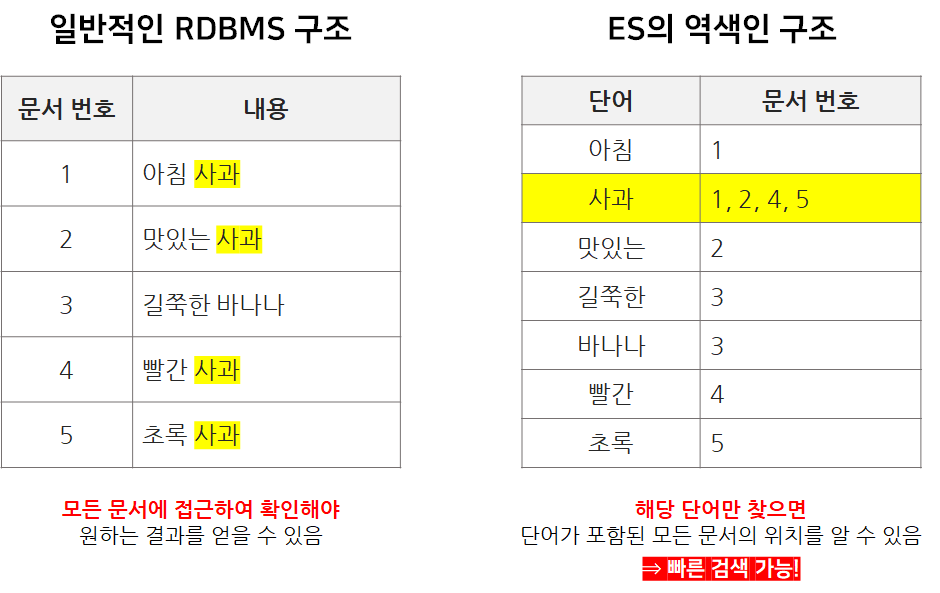
- 모든 문서(document)가 가지고 있는 고유 단어 목록
- 특정 단어가 어떤 문서에 속해 있는지에 대한 정보
- 전체 문서에 특정 단어가 몇 개 들어 있는지에 대한 정보
- 하나의 문서에 특정 단어가 몇 번씩 출현했는지에 대한 정보
데이터가 늘어날/새로 입력될 경우
- 일반 DB 구조에서처럼 검색해야 할 행이 늘어나는 것 X
- 역색인 내 문서 번호 배열값 추가(새로 입력된 데이터 내 단어를 토큰화하여 어떤 단어를 포함하는지 해당 단어 포함 문서 번호에 값 추가)⇒ 큰 속도 저하 없이 빠른 속도로 검색 가능
- 역색인을 데이터 저장 과정에서 만들기 때문에, ES에서는 데이터 입력/저장을
색인한다고 표현
역색인 단계
1단계: 문서 토큰화(단어, term으로 분리)2단계: 토큰화된 단어에 대해 해당 단어 포함 문서 번호, 문서 상 위치, 출현 빈도 등 정보 확인
- Sharding & Shard
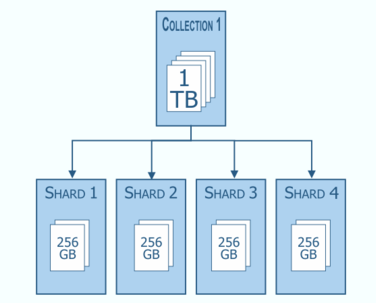
샤딩(Sharding) = 데이터를 다수의 DB에 분산 저장하는 것
샤드(Shard) = 샤딩을 통해 나누어진 블록 구간
- 단일 데이터를 다수의 데이터베이스에 쪼개어 나누는 것
- Scale Out(수평 확장)을 위해 index를 여러 샤드로 쪼개어 저장
- 파티셔닝(Partitioning)이라고도 함
- 대용량 데이터를 안정적으로 보관할 때 샤딩하여 분산 저장
- 데이터가 급격히 증가하거나 트래픽이 특정 DB로 몰리는 상황 대비, 빠르고 유연한 DB 증설 및 분산 시스템 필요
- 분산된 DB에서 필요한 데이터만 빠르게 조회할 수 있기 때문에 쿼리 자체가 가벼움
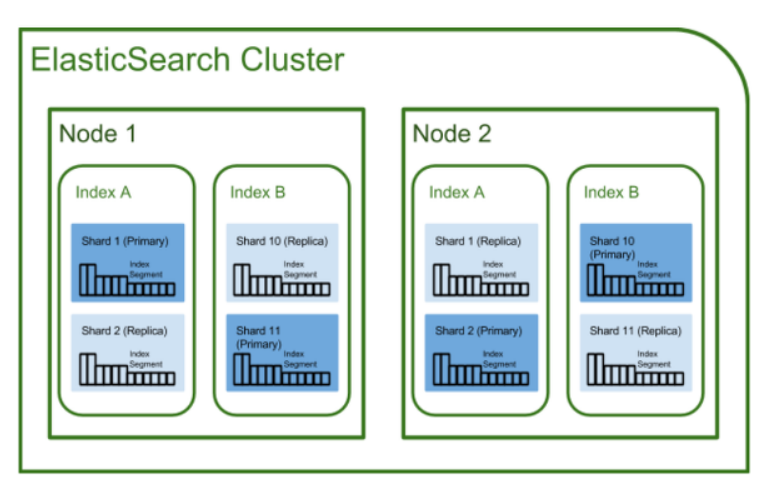
- Replica
Primary Shard - 처음 생성된 shard(원본)
Replica Shard - primary shard를 복제하여 다른 노드에 저장하는 샤드
- index를 쪼개어 나눈 샤드에 대한 한 개 이상의 복사본
- 노드를 손실했을 경우를 대비하여, 데이터 신뢰성을 위해 샤드 복제
- replica는 원본과 다른 노드에 존재할 것 권장
- primary shard가 유실될 경우, replica shard가 primary shard로 승격되고, 복제본(replica shard)가 새로 생성됨
- replica shard는 운영 중 그 수를 변경할 수 있으나 primary shard는 수를 조정할 수 없음
4. Elastic Search의 구조
✨ Master Node
- 클러스터 제어 및 관리
- 인덱스 생성 및 삭제
- 어떤 샤드에 데이터를 할당할지 결정
✨ Data Node
- 실제로 색인된 데이터를 저장하고 있는 노드
- 클러스터에서 마스터 노드와 데이터 노드를 분리하여 설정 가능
예시를 통해 마스터 노드와 데이터 노드를 분리하는 방법을 살펴보자
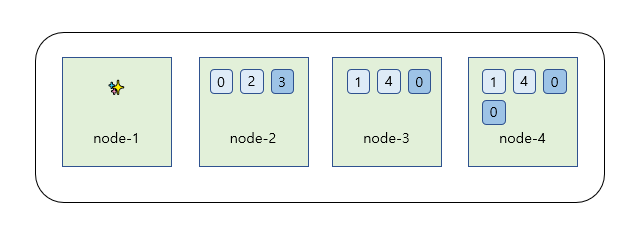
Divide Master and Data node-1
# config/elasticsearch.yml 1 node.master: true 2 node.data: falseDivide Master and Data node-2
# config/elasticsearch.yml 1 node.master: false 2 node.data: trueDivide Master and Data node-3
# config/elasticsearch.yml 1 node.master: false 2 node.data: trueDivide Master and Data node-4
# config/elasticsearch.yml 1 node.master: false 2 node.data: true
- 현재 node는 1번 부터 4번 node까지 생성했다 가정한다
- node-1은 마스터 역할만 수행하는 전용 노드
- node-2,3,4 는 마스터 역할은 하지않고 데이터 저장만 하는 노드로 설정
- 실제 데이터 입력 시 node-1에는 데이터가 들어가지 않고, node-2 ~ 4에만 데이터가 들어간다.
Split Brain
- 마스터 후보 노드가 하나일 경우,해당 노드가 유실되면 클러스터 전체 작동이 정지될 위험이 있음
- 해당 이슈로 인해, 최소한 백업용 노드를 설정해야 한다
- 그러므로 3개 이상의 홀수개로 마스터 노드를 구성하는 것을 권장한다
- 만약 마스터 후보 노드를 2개 혹은 짝수로 운영하는 경우 네트워크 유실로 인해 아래 상황을 겪을 수 있다.
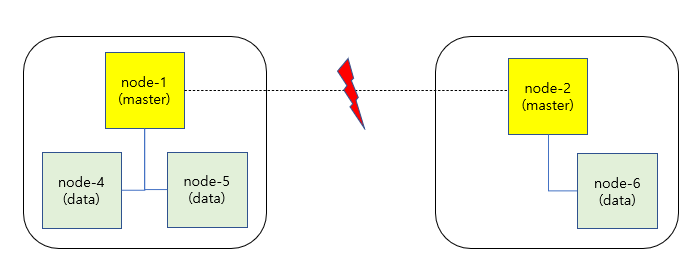
- 위와 같이 네트워크 단절로 마스터 후보 노드인 node-1 과 node-2 가 분리
- 서로 다른 클러스터로 구성되어 계속 동작하는 경우 발생
- 이 상태에서 각자의 클러스터에 데이터 추가 및 변경
- 네트워크가 복구 되고 하나의 클러스터로 합쳐졌을 때 데이터 정합성 및 무결성 문제 발생
- 위 같은 문제를 Split Brain이라 지칭
Split Brain 방지
Split Brain의 방지를 위해서는 마스터 후보 노드를 3개로 두고 클러
스터에 마스터 후보 노드가 최소 2개 이상 존재하고 있을 때에만 클러
스터가 동작하고 그렇지 않은 경우 클러스터는 동작을 멈추도록 해야 한다.
6.x 이전 버전에서 사용하던 방식
# elasticsearch.yml
1 discovery.zen.minimum_master_nodes: 2- minimum_master_nodes 값은 ( 전체 마스터 후보 노드 / 2 ) + 1로 설정
- 마스터 노드가 5개인 경우 3으로 설정
7.0 버전부터 사용하는 방식
# elasticsearch.yml
1 node.master: true- 7.0 부터는 위 구문을 통해 클러스터가 스스로 minimum_master_nodes 노드 값을 변경하도록 패치
# elasticsearch.yml
cluster.initial_master_nodes: [ 'node-1' , 'node-2' ]- 사용자는 위 구문을 통해
최초 마스터 후보 지정만 하면 된다 - 위 설정시 네트워크가 단절 되면 minimum_master_nodes가 2 이상인 클러스만 살아있는다
참고

Data Engineer