Glue 개념 정리
1. AWS Glue 가 뭐지?
AWS Glue 는 간단하게 ETL 서비스라고 할 수 있는데 ETL 서비스에 대해서 이해하고 있다면 보다 쉽게 AWS Glue 에 대해 이해할 수 있고Data Warehouse 의 개념이나 구조에 대해서도 어느 정도 이해가 있으면 좋다고 생각한다.
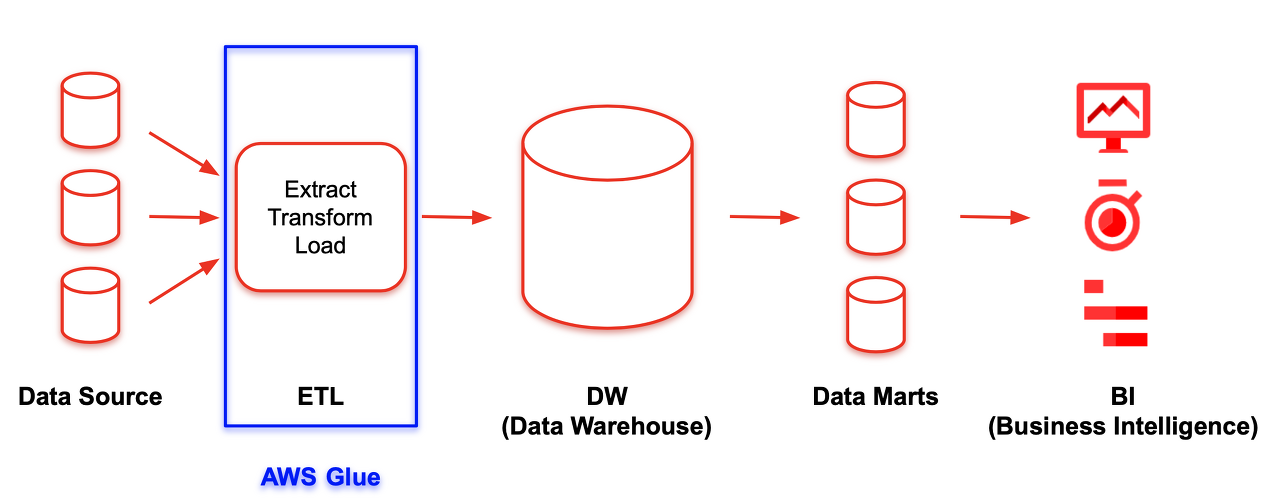
AWS 에서는 다음과 같이 AWS Glue 에 대해서 정의하고 있다.
"완전 관리형 추출(Extract), 변환(Transform), 저장(Load) ETL 서비스"
추출하고 변환해서 다시 저장하는 ETL 서비스를 완전히 AWS Glue 를 통해 관리할 수 있다고 이해할 수 있다.
이러한 서비스를 통해 간단하게 데이터를 정리하고 검증하고 옮길 수 있도록 해준다.
여기서 ETL(Extract, Transform, Load) 에 대해서 이해하고 있다면 보다 쉽게 이해할 수 있다.
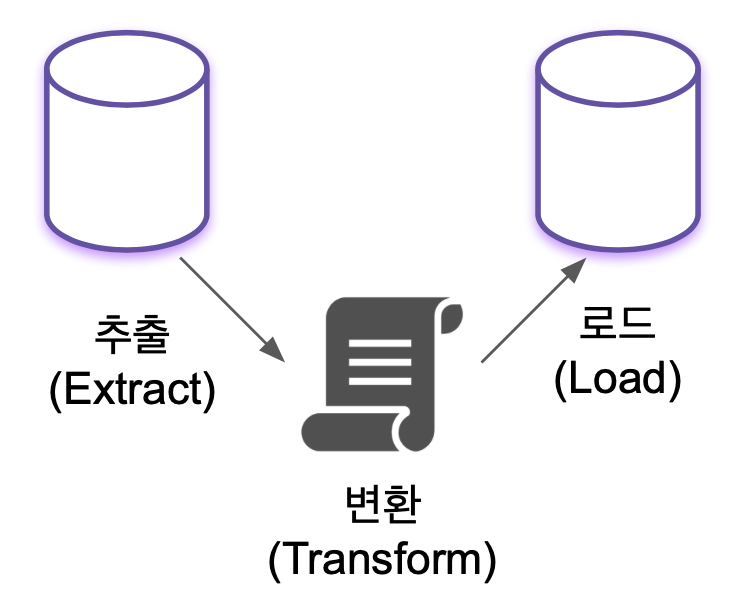
2. AWS Glue 는 어떤 특징을 가지고 있지?
그럼 AWS Glue 는 어떤 특징을 가지고 있는지에 대해서 정리해봤다.
- 서버리스
- 중앙 메타데이터 리포지토리, AWS Glue Data Catalog
- 자동으로 Python 및 Scala 코드를 생성하는 ETL 엔진
- 종속성 확인, 작업 모니터링 및 재시도를 관리하는 유연한 스케줄러
AWS Glue 는 서버리스로 구성되어 인프라를 관리할 필요가 없다.
AWS Glue Data Catalog 라고 하는 중앙 메타데이터 저장소라고 하는 데이터베이스를 사용한다.
이 말은 즉, 모든 데이터를 한 곳에 모아 ETL 작업을 할 수 있도록 제공한다는 것이다.
ETL 작업을 하기 위한 Python 및 Scala 스크립트를 자동으로 생성해주는 ETL 엔진이 있다.
Python 이나 Scala 언어를 통해 스크립트를 생성하고 생성한 스크립트를 통해 ETL 작업을 하게 되는데
AWS Glue 는 스크립트를 자동으로 생성할 수 있는 이후에 설명할 Built-In Transforms 라는 기능을 제공하고 있다.
또한 작업들을 Cloudwatch 를 통해 모니터링하고 트리거를 통해 실행하고 관리할 수 있는 스케줄러를 가지고 있다.
이후에 Data Catalog 에 메타데이터를 저장하는 방법과 ETL 서비스에 대해서 정리할 예정이다.
3. AWS Glue 를 언제 사용하지?
AWS 에서는 이렇게 설명하고 있다.
"데이터 웨어하우스 또는 데이터 레이크의 스토리지에 데이터를 구성, 정리, 검증 및 포맷할 수 있습니다."
ETL 서비스를 제공하는 다른 플랫폼이나 서비스들도 마찬가지로
데이터를 원하는 형태에 맞게 변환해서 사용하기 쉽게 한 곳에 데이터를 모으기 위해서 사용한다고 생각하면 된다.
AWS Glue 도 마찬가지로 반정형 데이터를 가져와 변환을 통해 원하는 형태로 데이터를 저장할 수 있다.
Glue 아키텍처
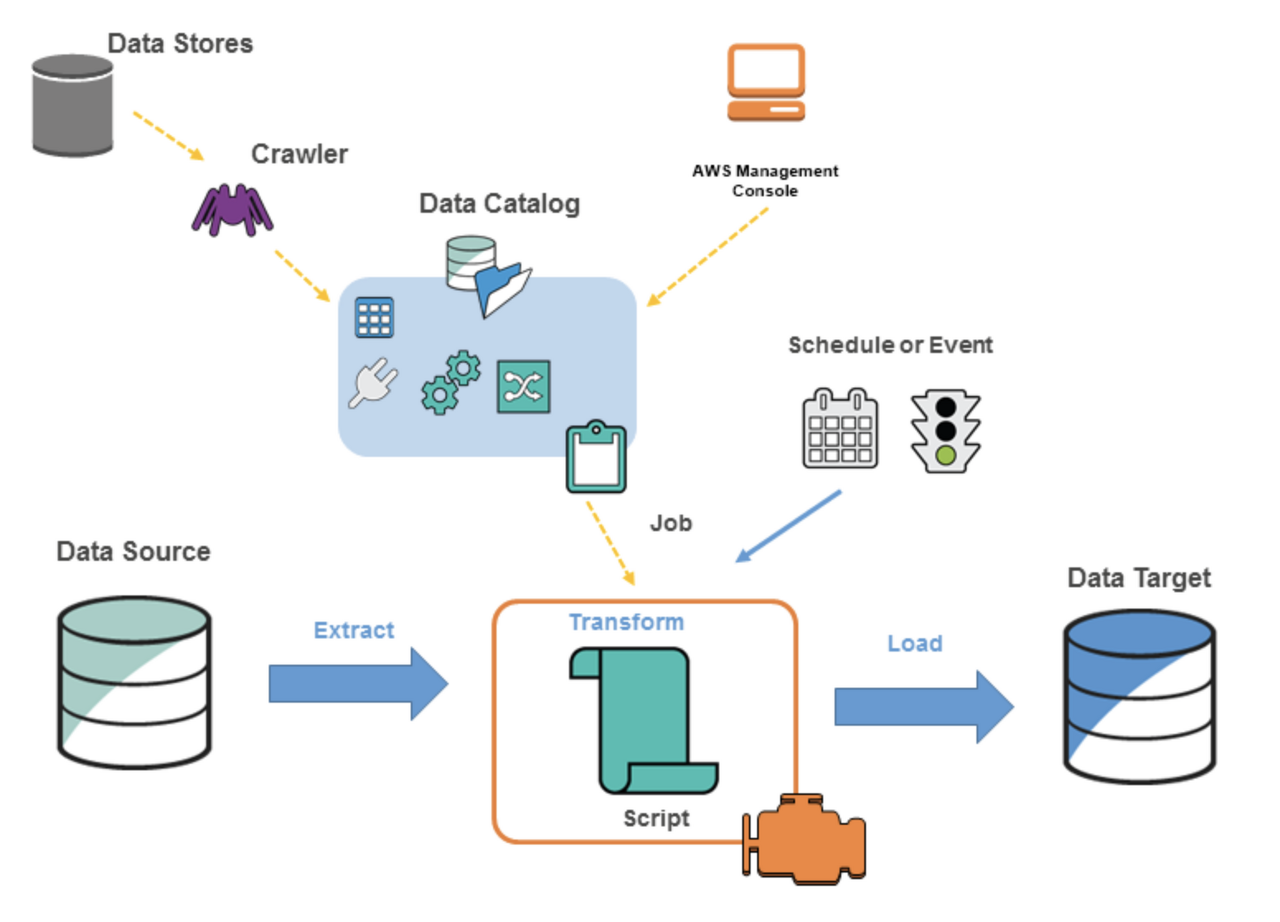
AWS Glue 는 데이터 스토어의 데이터를 크롤러를 통해 메타데이터를 가져와 데이터 카탈로그에 저장한다.
또는 데이터 카탈로그의 객체인 연결(Connection) 에 데이터 스토어의 연결 정보를 객체로 저장해놓고
크롤러를 통해 데이터 카탈로그에 저장할 수 있다.
이렇게 2가지 방법을 통해 데이터 카탈로그에 메타데이터를 저장할 수 있다.
Data Store → Crawler → Data Catalog(Metadata)
Data Store Connect Info → Connection (Data Catalog Object) → Crawler → Data Catalog
데이터를 저장할 때 데이터 카탈로그에 데이터베이스를 생성하고 데이터베이스 내의 테이블을 생성하게 된다.
데이터 카탈로그의 데이터베이스 내 메타데이터가 저장된 테이블을 통해 ETL 작업(Job)을 수행하게 된다.
물론 Data Catalog 의 테이블 뿐만 아니라 S3, Redshift 등 다른 데이터 스토어를 데이터 소스로 가져올 수 있다.
데이터 타겟도 마찬가지로 Data Catalog 뿐만 아니라 다른 서비스나 플랫폼을 데이터 타겟으로 지정할 수 있다.
Data Source(Data Catalog Table, etc) → Transform (Job) → Data Target(Data Catalog Table, etc)
이렇게 ETL 작업을 거쳐 데이터를 저장하게 된다.
그리고 스케줄러나 이벤트와 같은 트리거를 통해 ETL 작업을 관리할 수 있다.
Glue 용어 정리
1. 데이터 카탈로그 - AWS Glue Data Catalog
AWS Glue의 영구적 메타데이터 스토어입니다.테이블 정의, 작업 정의 및 기타 관리 정보를 포함하여 AWS Glue 환경을 관리합니다.
각 AWS 계정에는 리전당 AWS Glue Data Catalog 하나가 있습니다.
리전당 하나씩 만들게 만든 이유는 아마 한 곳에서 통합해 데이터를 관리하기 위함이라고 생각하면 될 것 같다.
간단하게 AWS Glue 에서 사용하기 위한 메타데이터를 저장하기 위한 저장소라고 생각하면 된다.
2. 데이터베이스 - Database
논리 그룹으로 구성된 일련의 연결된 Data Catalog 테이블 정의입니다.
크롤러를 통해 가져온 메타데이터를 데이터베이스에 테이블을 생성해 저장하게 된다.
3. 테이블 - Table in Database
데이터를 나타내는 메타데이터 정의입니다.
데이터가 Amazon Simple Storage Service(Amazon S3) 파일, Amazon Relational Database Service(Amazon RDS) 테이블 또는 다른 데이터 집합에 있는지에 관계없이 테이블은 데이터의 스키마를 정의합니다.
Data Catalog의 테이블은 열 이름, 데이터 유형 정의, 파티션 정보 및 베이스 데이터 세트에 대한 기타 메타데이터로 구성됩니다.
데이터의 스키마는 AWS Glue 테이블 정의에 나타납니다.
실제 데이터는 파일 혹은 관계형 데이터베이스 테이블 어디에 있든지 기존 데이터 스토어에 남겨집니다.
AWS Glue는 파일과 관계형 데이터베이스 테이블 목록을 AWS Glue Data Catalog에 작성합니다.
ETL 작업을 생성할 경우 소스와 대상로써 사용됩니다.
4. 연결 - Connection
특정 데이터 스토어에 연결하는 데 필요한 속성을 포함하는 Data Catalog 객체입니다.
말 그대로 데이터 스토어를 연결하기 위해 연결 정보를 미리 등록해놓을 수 있다.
등록해놓은 연결 객체를 크롤러를 통해 데이터의 메타데이터를 가져올 수 있다.
5. 크롤러 - Crawler
데이터 스토어(소스 또는 대상)에 연결하는 프로그램은 분류자의 우선 순위 지정 목록을 통해 데이터의 스키마를 결정한 다음
AWS Glue Data Catalog에 메타데이터 테이블을 생성합니다.
크롤러가 데이터 스토어에서 데이터를 직접 가져올 수도 있지만 데이터 카탈로그 객체인 연결(Connection)을 통해서도 가져올 수 있다.
6. 분류자 - Classifier
데이터 스키마를 결정합니다.
AWS Glue는 CSV, JSON, AVRO, XML 등과 같은 일반 파일 형식에 대한 분류자를 제공합니다.
JDBC 연결을 사용한 일반 관계형 데이터베이스 관리 시스템을 위한 분류자를 제공합니다.
a grok 패턴을 사용하거나 XML 문서에 행 태그를 지정하여 자체 분류자를 작성할 수 있습니다.
크롤러를 통해 데이터 스토어의 메타데이터를 가져오는 과정에서 분류자를 통해 구분해 메타데이터를 가져와 스키마를 생성한다.
기본적으로 JSON, CSV 등의 파일 형식에 대해서 분류를 하기도 하지만 로우 데이터의 형태가 달라 구분하기 위한 분류자가 필요할 때
분류자를 커스텀해서 메타데이터를 가져와 데이터 카탈로그에 저장할 수 있다.
7. 데이터 스토어, 데이터 원본, 데이터 대상
데이터 스토어는 데이터를 영구적으로 저장하기 위한 리포지토리입니다.예를 들면 Amazon S3 버킷과 관계형 데이터베이스가 있습니다.데이터 원본은 프로세스 또는 변환의 입력값으로 사용되는 데이터 스토어입니다.데이터 대상은 프로세스 또는 변환에서 쓰기를 수행하는 대상 데이터 스토어입니다.
8. AWS Glue Studio Job
작업은 ETL 작업을 수행하는 데 필요한 비즈니스 로직입니다.변환 스크립트, 데이터 원본 및 데이터 대상으로 구성됩니다.작업은 트리거에 의해 시작되고, 트리거는 예약되거나 이벤트 기반으로 작동할 수 있습니다.
9. ETL Script
소스에서 데이터를 추출하고 데이터를 변환한 다음 대상으로 로드하는 코드입니다.AWS Glue는 PySpark 또는 Scala 스크립트를 생성합니다.
10. Transform
다른 포맷으로 데이터를 바꾸는 코드 로직.
11. Trigger
ETL 작업 시작. 트리거는 정해진 시간 혹은 이벤트 기반으로 정의할 수 있습니다.
참고
