AWS Glue의 실행 모델
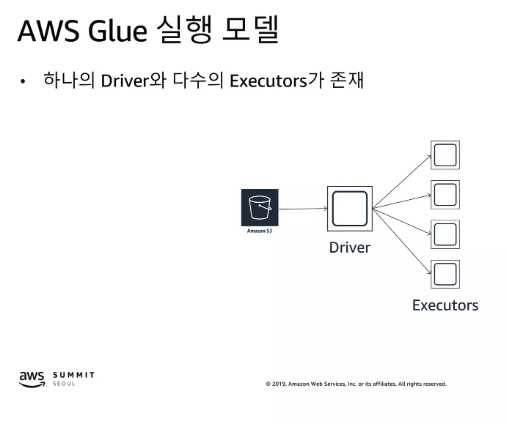
AWS Glue의 실행 모델은 Apache Spark 기반으로, 하나의 Driver와 다수의 Executor로 구성
-
Driver
- 작업을 조정하고, Executor에게 작업을 할당
- 전체 작업의 실행 계획을 관리하고, 작업의 진행 상황을 모니터링
-
Executor
- 실제 데이터 처리 작업을 수행
- Driver로부터 받은 작업을 병렬로 실행하며, 각각은 데이터의 일부분을 처리
Glue 환경

-
Standard Environment
- 기본적인 Glue ETL 작업을 위한 환경으로, 대부분의 일반적인 사용 사례에 적합
- Driver 5G, Executor 5G
-
G.1X Environment
- 더 많은 메모리와 컴퓨팅 리소스를 제공하는 환경입니다. 대용량 데이터 처리나 복잡한 ETL 작업에 적합
- Driver 10G, Executor 10G
-
G.2X Environment
- G.1X보다 더 많은 리소스를 제공하는 환경으로, 매우 큰 데이터셋 또는 매우 복잡한 데이터 처리 작업에 적합
- Driver 20G, Executor 20G

-
Glue Standard Job
- 최소 DPU(Data Processing Unit)는 2개이며, 기본적으로 할당되는 DPU는 10개
-
10 DPU Job 예시
- 10DPU 일때 1개의 마스터 노드와 9개의 코어 노드로 구성된 클러스터에서 실행
- 전체 18개의 Executor(Worker가 9개 이므로 9 X 2 = 18) 중 1개는 Driver 역할을 하고, 나머지 17개는 Executor 역할을 한다.
-
마스터 노드와 코어 노드
- 이들은 클러스터의 물리적 노드를 나타내며, 각각의 노드는 자체 CPU와 메모리 자원을 가지고 있다. AWS Glue에서는 이 용어를 사용하지 않을 수도 있으며, 더 일반적으로 EMR(Elastic MapReduce) 같은 다른 AWS 서비스에서 사용된다.
-
Driver와 Executor
- Spark 실행 모델에서 Driver는 전체 작업의 흐름을 제어하고, Executor는 실제 데이터 처리를 수행한다. AWS Glue 작업은 Spark 기반으로, Glue 작업을 수행할 때 이러한 컴포넌트가 내부적으로 활용된다.
Spark 구조 + Glue

- 기존의 DataFrame이라는 자료구조를 사용하는 spark에, 새로운 자료구조인 DynamicFrame을 Glue에서는 사용한다.
- 이유 : AWS의 다른 서비스와의 통합을 조금 더 수월하게 수행하기 위해 재정의함
자료 구조 비교
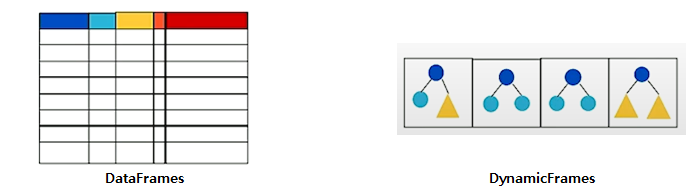
- DataFrames
- '테이블' 형태를 기반으로 한 자료구조
- 즉, 사전에 정의된 스키마가 필요하고, 각 행은 동일한 구조를 가진다.
- DynamicFrames
- JSON, Avro, Apache Logs 등의 semi-structured 데이터를 처리하기 위해 설계됨
- ETL dataframe과 유사하다.
- 따라서, 각각의 행은 제각각의 스키마를 가지는 구조를 가진다.
- 다음과 같은 함수를 활용하면, dataframe과 dynamicframe 간 변환이 가능하다.
- 또한, 아래의 함수를 통해, dataframe과 dynamicframe 간 변환이 가능하고, 때문에 spark의 API 역시 사용 가능하다.

성능 비교
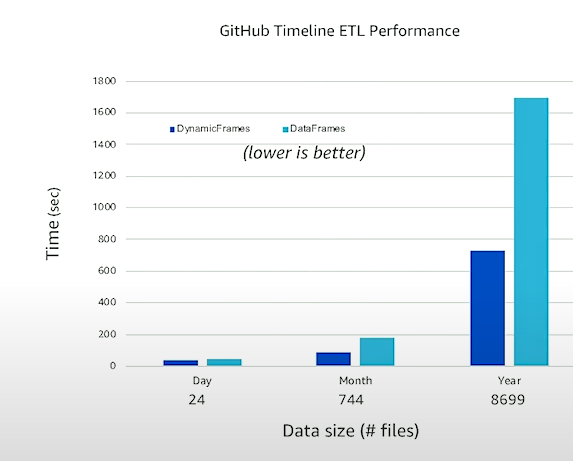
압축에 따른 파일 처리
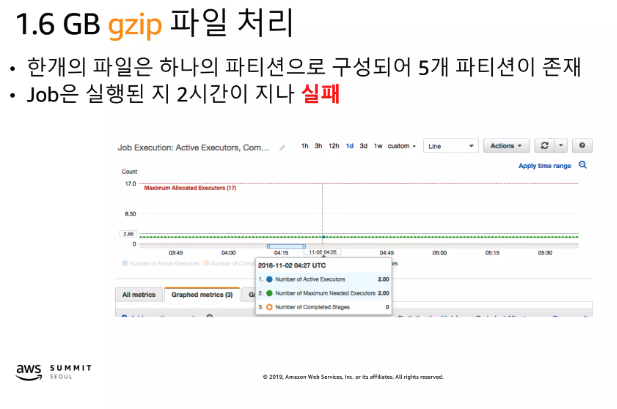
- gzip은 파일이 Split이 되지 않아 파일 하나당 하나의 파티션으로 존재한다. 따라서 Job의 크기가 너무 커서 executor의 자원이 부족하여 Job이 실패
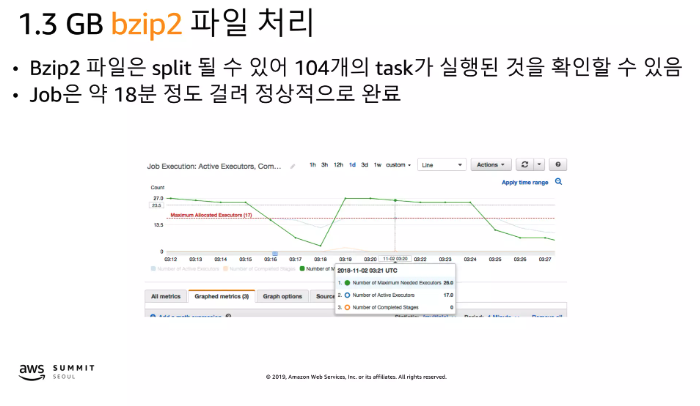
- Bzip2 파일은 Split이 될 수 있어 Job에 메모리가 분산되어 처리
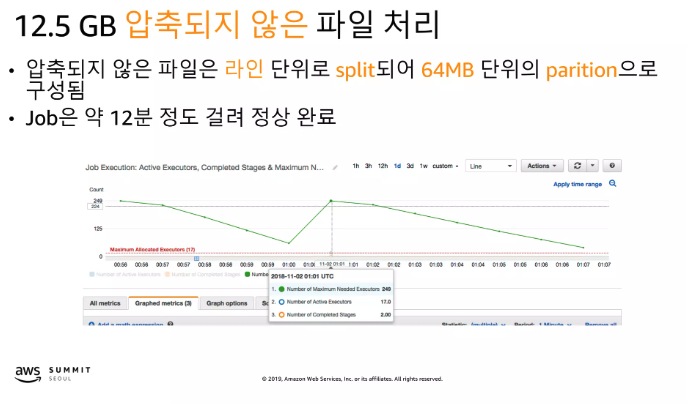
- 기본적으로 Snappy 압축에 Parquet 포맷으로 partition해서 사용하길 권장
- 그 외 압축 형식 중 선택해야 한다면 bzip2
- gzip을 사용한다면 자원을 충붕히 활용할 수 있는 파일 크기로 구성되어 있는 지 확인
- Glue에서는 대역폭이 문제가 되는 경우는 거의 없으므로 압축되지 않은 파일의 경우 상황에 따라 그대로 사용하는 것도 고려할 수 있음
병렬처리 최적화
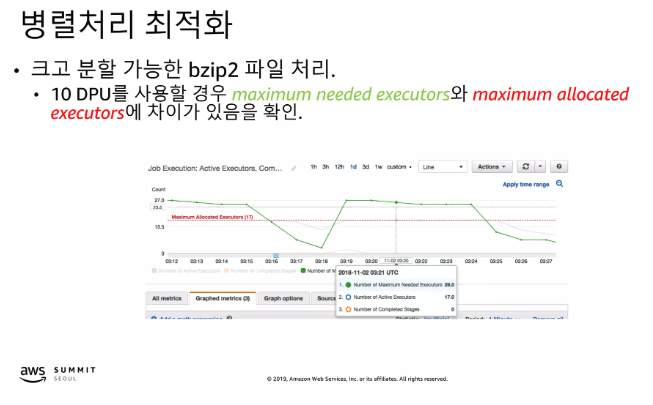
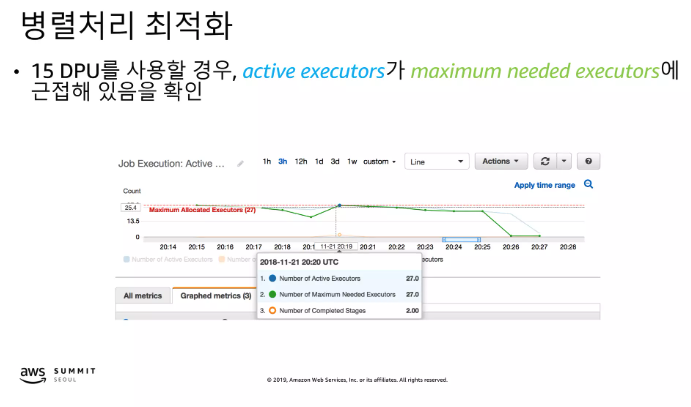

Glue JDBC 파티션
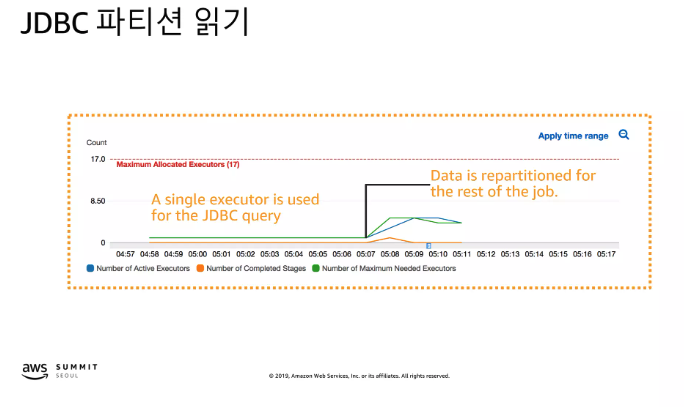
- JDBC를 source로 사용하는 경우 기본 동작은 하나의 테이블은 하나의 파티션으로 읽기 수행
- Glue는 데이터 적재 후 10개 미만의 파티션으로 자동으로 분할
- output partition과는 다른 개념, AWS Glue에서의 "output partition"은 적재되는 데이터가 결과 데이터 저장소(예를 들어 Amazon S3)에 분할되어 저장되는 방식
- 반면에 "10개 미만의 파티션으로 자동 분할"이라는 표현은 일반적으로 입력 데이터를 읽을 때 AWS Glue가 데이터를 읽기 위해 내부적으로 생성하는 파티션을 의미
Database table 병렬 읽기 옵션

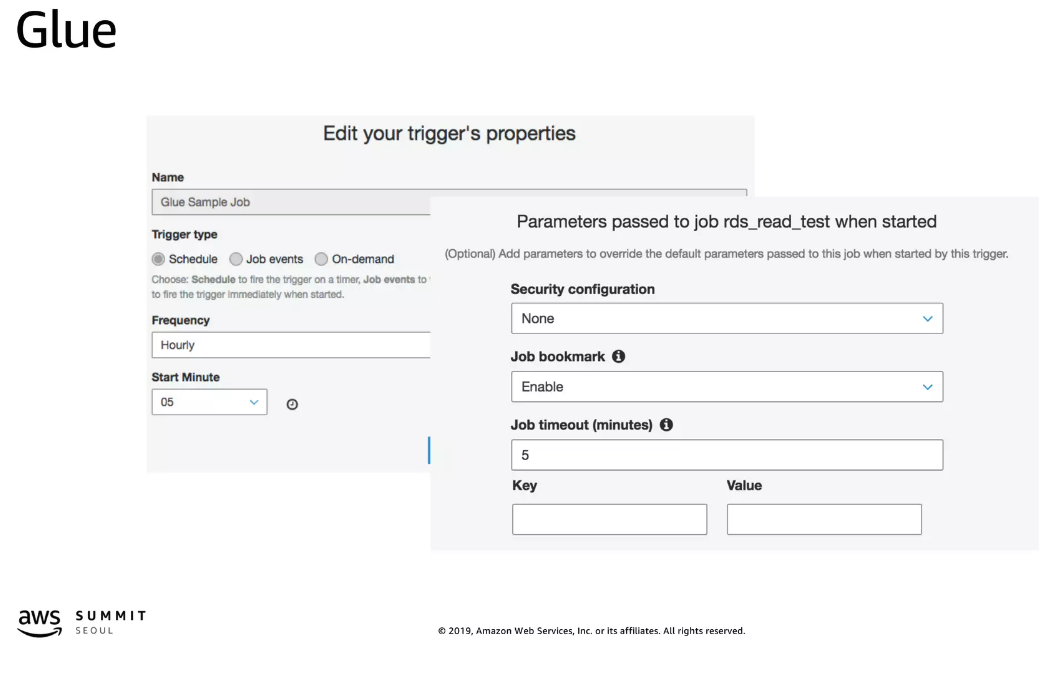
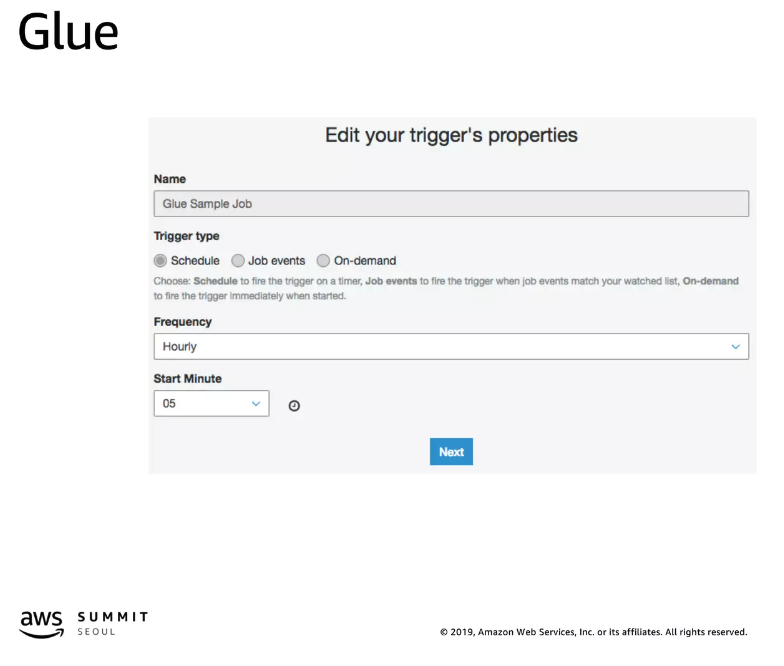
스케줄러
Python shell
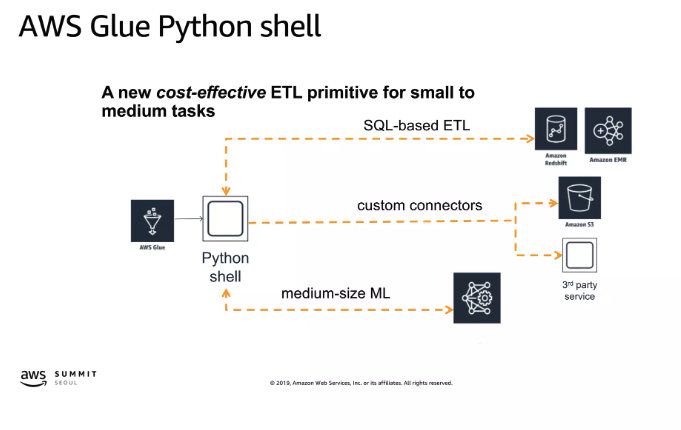
- python 2.7 지원
- cold spin up: < 20sec, VPCs 지원, 실행 시간제한 없음
- size: 1DPU (16GB 사용가능), 또는 1/16DPU (1GB 사용가능)
- pricing: DPU-hour마다 $0.44
- 최소 과금 시간 1분, 이후부터는 초 단위 과금
Glue vs EMP
- On-Premise에서 사용하고 있는 Workload(Hive, Spark Streaming 등)를 AWS로 Migration 해야하는 경우
- AWS glue는 Custom Configuration을 지원하지 않음
- Glue에서 지원하는 것 보다 더 높은 CPU와 Memory를 필요로 하는 Workload의 경우
참고자료

Data Engineer