스트리밍 데이터란?
- 응용 프로그램에서 생성한 로그 파일
- 웹 애플리케이션 또는 모바일 애플리케이션의 고객 상호 작용 데이터
- 금융 주식 시장 데이터
- IOT 장치 데이터(센서, 성능 모니터 등)
스트리밍 데이터는 많은 데이터 소스에서 연속적으로 생성되는 데이터이다. 이런 데이터는 Amazon Kinesis, Apache Kafka, Apache Spark 및 다양한 프레임워크와 같은 도구로 수집할 수 있다.
이제 간단하고 신속하게 적용할 수 있는 AWS 서비스 중, 대용량 데이터 레코드 스트림을 실시간으로 수집 및 처리하는데 적합한 Kinesis Data Streams를 사용하여 Kinesis Analytics를 통한 분석까지 해보자. 그리고 서비스 활용을 위해 분석 결과를 서버리스 컴퓨팅 서비스인 Lambda 함수를 통해 Redis에 저장까지 해보도록 하겠다.
용어 정리
-
Data Record
데이터 레코드는 데이터 스트림에 저장되는 데이터 단위이다. sequence number, partition key, data blob 등으로 이루어져 있으며 하나에 1MB까지 사용할 수 있다. 한 번 스트림에 들어가면 변경이 불가능하다. -
Retention Period
데이터 레코드의 보존 기간은 기본적으로 24시간이다. 최소 24시간이며 최대 365일까지 증가시킬 수 있으나 요금이 추가된다. -
Producer
스트림에 데이터를 보내준다. -
Consumer
스트림에 있는 데이터를 가져와서 사용한다. -
Shard
샤드는 데이터 스트림의 단위를 말한다. 하나의 스트림은 하나 또는 그 이상의 샤드로 구성될 수 있다. 하나의 샤드는 읽을 때 최대 5개의 트랜잭션을 지원하며 최대 초당 2MB를 읽을 수 있고, 초당 1,000개의 레코드를 쓰고 초당 1MB를 쓸 수 있다. -
Partition Key
파티션 키는 스트림 내에서 샤드별로 데이터를 그룹화하는 데에 사용된다. 데이터 레코드에 파티션 키를 지정할 수 있다. 파티션 키로 데이터 레코드가 속할 샤드를 결정할 수 있으며 결정 시에는 MD5 Hash 함수를 사용한다. -
Sequence Number
각각의 데이터 레코드에는 파티션 키에 고유한 Sequence Number가 있다.
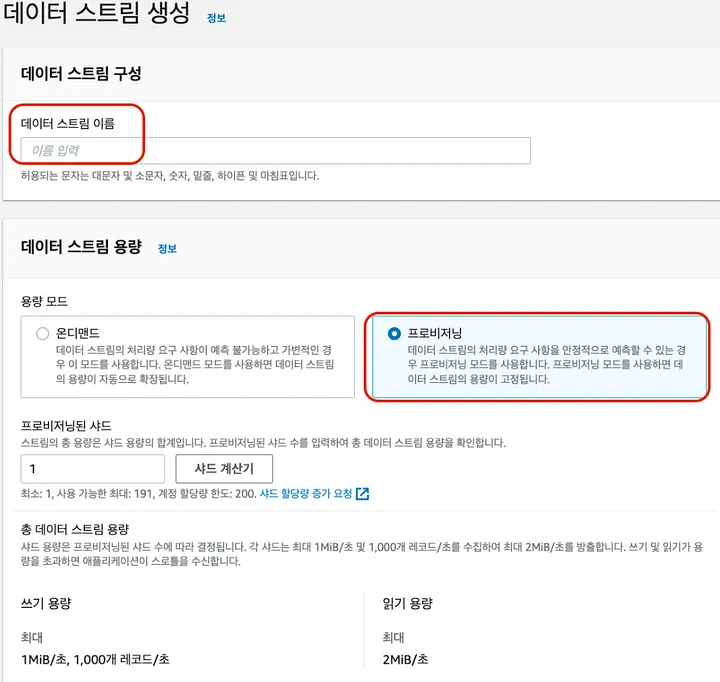
스트림 생성
Kinesis 서비스(데이터스트림)에서 스트림 이름, 용량모드, 샤드 수를 지정하고 생성해보자.
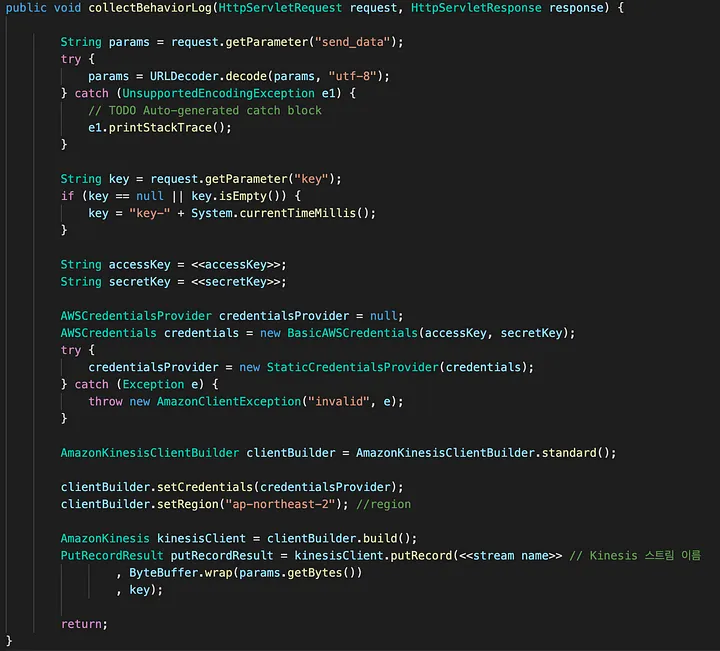
스트림에 데이터 넣기(Producer)
어플리케이션단에서 전달되는 고객 행동로그 데이터를 위에서 만든 스트림으로 보내주면 되는데, 아래는 그 역할을 해주는 생산자를 Spring을 통해 개발한 주요 부분이다.
스트림 데이터 실시간 분석하기(Consumer)
스트림 데이터 분석을 하기 위해 Kinesis Analytics 서비스를 이용해 보자.
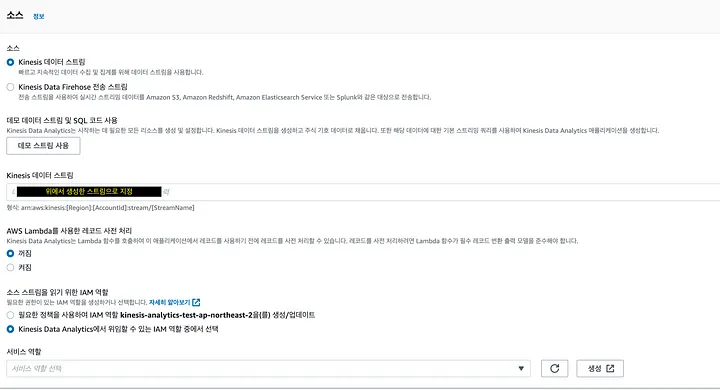
1. 생성 및 구성
Kinesis 서비스(데이터분석)에서 SQL어플리케이션 메뉴에서 생성하고, ‘소스 탭-구성’에서 위에서 만든 스트림을 소스 스트림으로 선택 후 역할 설정을 하자.
2. 스키마 및 데이터 확인
스키마 검색을 하면, 아래와 같이 자동으로 스트림에 유입되는 데이터의 스키마를 잡아줄 것이다. (추가도 되고 제거도 된다)
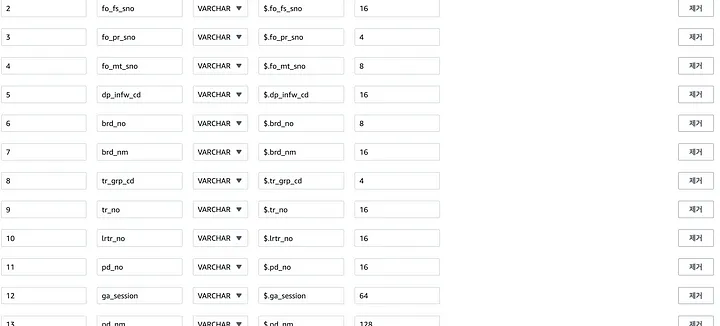
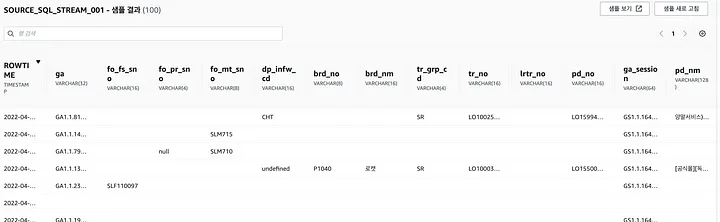
샘플 결과로 스트림 데이터도 익숙한 테이블 형태로 볼 수 있다.
3. 실시간 분석하기 위한 SQL 작성
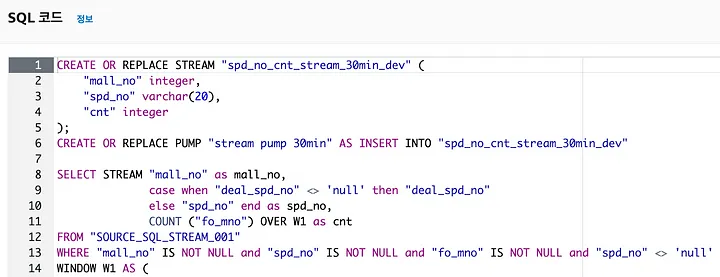
‘실시간 분석 탭-구성’에서 SQL코드를 간단히 작성해 보자. 아래 코드는 몰별_상품별 실시간 클릭 카운팅한 것이다.
아래와 같이 실시간으로 분석하여 샘플 결과를 보여준다.

4. 분석 결과 전송
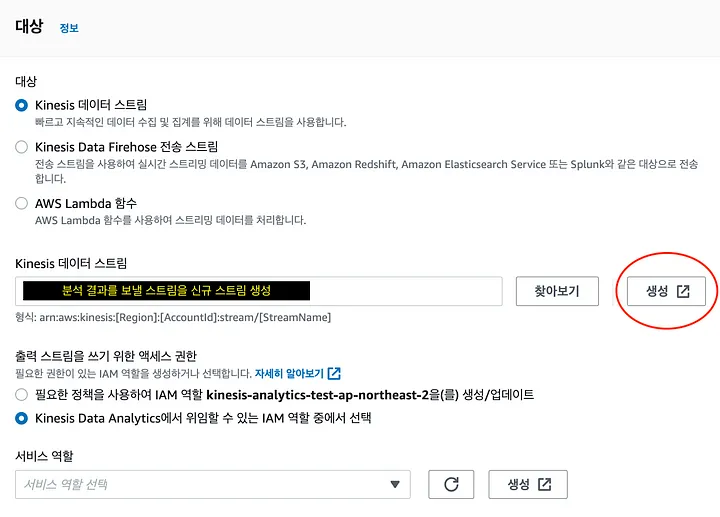
서비스에서 분석 결과를 사용할 수 있도록 신규 스트림으로 보내야 한다. ‘대상 탭-대상추가’에서 생성을 눌러 신규 스트림을 생성해보자. 위에서 만들어봐서 쉽게 만들 수 있을 것이다.
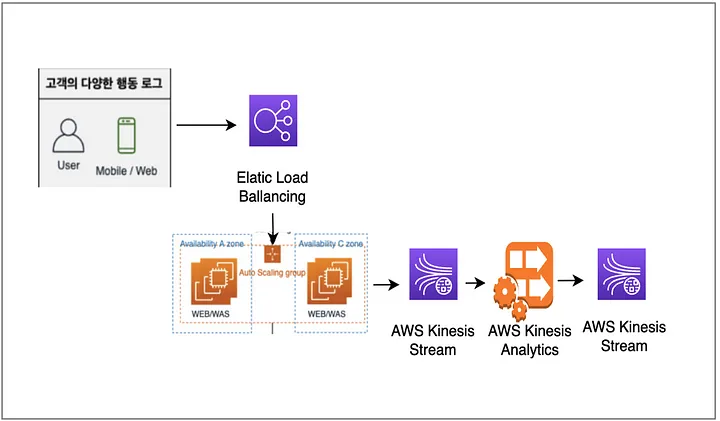
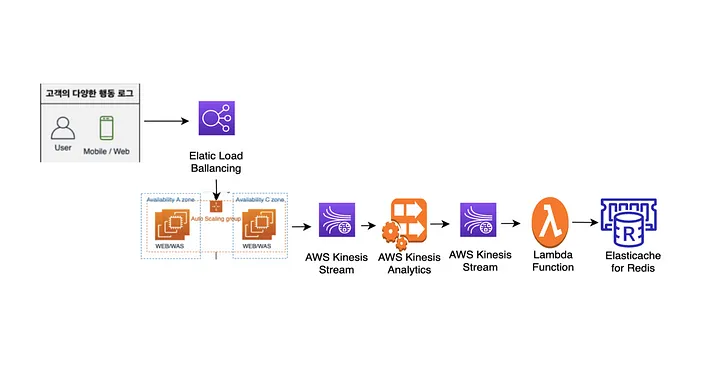
아키텍처
실시간 분석 데이터 저장하기
몰별/상품별로 현재 인기 있는(클릭이 많은) 상품들을 고객에게 더 어필하기 위해 서비스 중인 API가 가져다 쓸 수 있게 준비해 보자. 최종 목표는 Lambda 함수를 통해 분석 결과를 Redis에 저장할 것이다.
1. Lambda 함수 개발
참고로 Lambda 함수 생성 시 런타임은 Java 8 on Amazon Linux 2를 사용하였다. 아래는 Lambda 함수가 redis에 데이터를 넣는 주요 소스 부분이다.
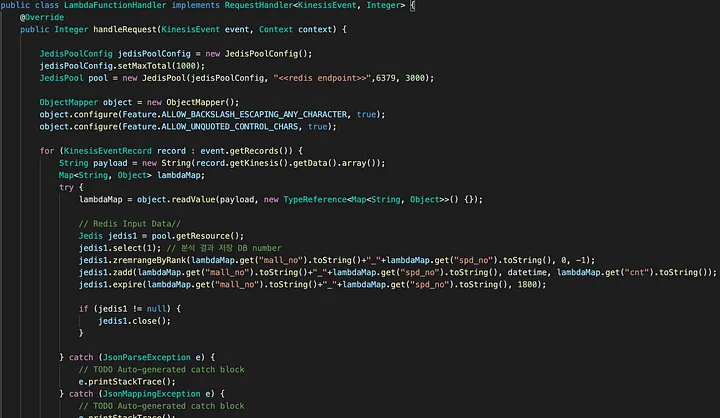
2. Lambda 함수 배포
maven을 사용하여 배포 패키지를 빌드했고 생성된 .jar는 Lambda API를 사용하여 최종 배포하였다.

참고: https://docs.aws.amazon.com/ko_kr/lambda/latest/dg/java-package.html
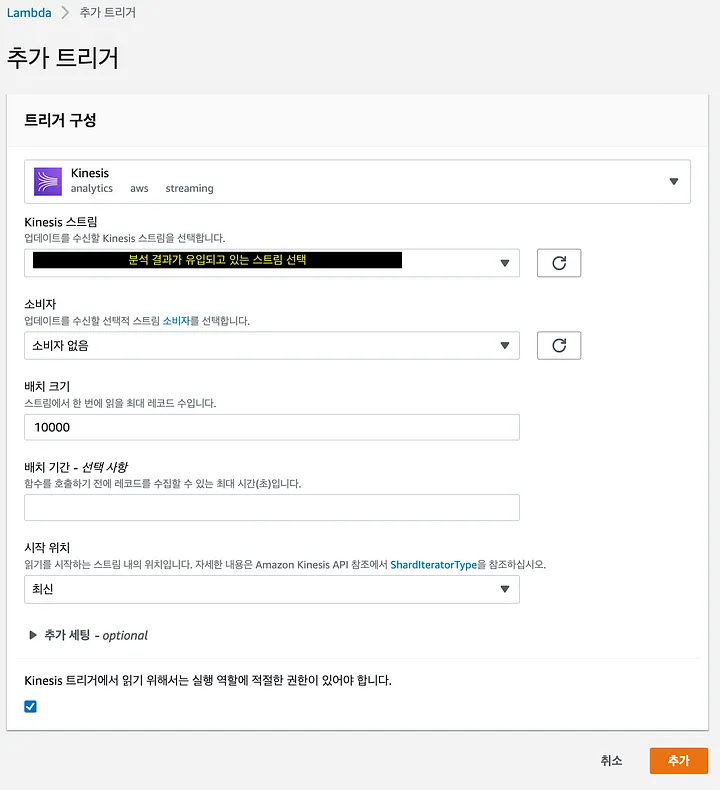
3. Lambda Trigger 추가
마지막으로 실시간으로 분석되어 kinesis stream에 유입되는 결과들이 Lambda를 통해 Redis에 즉시 저장되려면 해당 스트림을 트리거로 추가해 주어야 한다.
최종 아키텍처
참고
