1. MySQL 온프레미스 아키텍처
1-1. 인프라 구조: Master-Slave
-
Master-Slave 구조
- Master 노드는 데이터베이스의 쓰기 작업을 처리
- Slave 노드는 Master에서 복제된 데이터를 기반으로 읽기 작업을 수행하며, 읽기 부하 분산을 수행
- Master-Slave 복제는 binlog(바이너리 로그)를 통해 이루어진다.
-
데이터 복제
- Master 노드에서 데이터를 변경할 때 binlog를 기록.
- Slave 노드는 Master의 binlog를 읽어와 재생(Replay)하여 데이터를 복제.
-
복제 방식
- Statement-Based Replication (SBR): SQL 문장 단위로 복제.
- Row-Based Replication (RBR): 데이터 변경된 행 단위로 복제.
- Mixed Mode: SBR과 RBR 혼합.
1-2. Binlog의 사용 및 갱신 방식
-
Binlog의 목적
1. 복제: Master에서 발생한 데이터 변경 사항을 Slave로 전송.
2. 데이터 복구: 장애 복구 시 재생하여 데이터 복원.
3. CDC(Change Data Capture): 데이터 변경 사항을 외부 시스템으로 전달. -
Binlog 갱신 방식
- Master 노드에서 트랜잭션 커밋 시 binlog에 기록.
- Slave 노드는 Master의 binlog를 주기적으로 가져와 실행(Apply).
-
문제점
- 복제 지연(Lag): Slave 노드가 Master binlog를 재생하는 데 시간이 걸려 데이터 일관성이 순간적으로 깨질 수 있음.
- 성능 오버헤드: Master가 binlog를 기록하고 Slave로 전송하는 데 리소스 소모.
1-3. 읽기 및 쓰기 쿼리 처리 방식
- 쓰기
- Master 노드에서 처리.
- 쓰기 작업은 binlog에 기록됨.
- 읽기
- Slave 노드에서 처리하여 읽기 부하를 분산.
- 하지만 읽기 작업은 Master 데이터와 약간의 시차가 발생할 수 있음(복제 지연).
2. Amazon Aurora 아키텍처
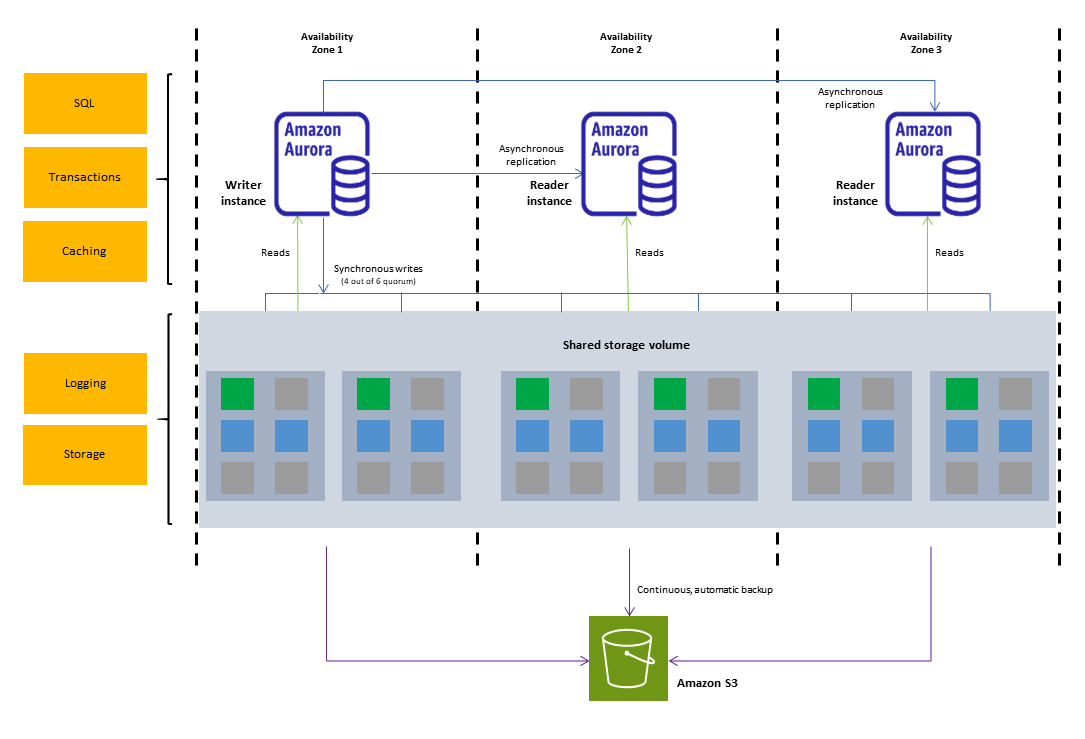
2-1. 인프라 구조: 분산 스토리지
-
Aurora의 분산 스토리지 계층
- 데이터는 다중 AZ(가용 영역)에 걸쳐 자동 복제되며, 최소 6개의 복제본을 유지.
- 데이터 손실 가능성을 줄이고 고가용성을 보장.
-
DB 클러스터
- Writer 인스턴스: 데이터 쓰기와 읽기를 처리.
- Reader 인스턴스: 읽기 전용 인스턴스로 최대 15개까지 확장 가능.
- 모든 인스턴스는 동일한 분산 스토리지 계층을 공유.
2-2. Binlog의 사용 및 갱신 방식
-
Binlog의 목적
- MySQL 온프레미스와 동일하게 복제 및 CDC를 위해 사용.
- Aurora 전용 향상된 binlog는 I/O 오버헤드를 줄이고, 성능 저하를 방지.
-
Binlog 갱신 방식
- 쓰기 작업 시 binlog가 기록되지만, Aurora는 변경 사항을 스토리지 계층에 바로 적용.
- Aurora의 분산 스토리지 시스템은 데이터 복제를 자동으로 처리하므로, binlog를 복제에 활용하지 않아도 됨.
-
최적화
- Aurora는 binlog를 별도의 I/O 캐시에 저장하여 성능을 최적화.
- 복제 지연이 거의 없음.
2-3. 읽기 및 쓰기 쿼리 처리 방식
- 쓰기
- Writer 인스턴스에서 처리.
- Writer 인스턴스의 쓰기 작업은 Aurora의 분산 스토리지 계층에 바로 적용되며, 데이터 복제가 자동으로 이루어짐.
- 읽기
- Reader 인스턴스에서 처리.
- Reader 엔드포인트를 통해 여러 Reader 인스턴스로 부하 분산.
- Aurora는 자동으로 읽기 전용 쿼리를 최적의 Reader 인스턴스로 라우팅.
3. 온프레미스 MySQL과 Aurora의 주요 차이점
| 구분 | MySQL 온프레미스 | Aurora |
|---|---|---|
| 아키텍처 | Master-Slave 구조 | Writer-Reader 구조 + 분산 스토리지 |
| 복제 방식 | Binlog 기반 복제 | 분산 스토리지 계층에 직접 복제 |
| Binlog 사용 | 필수적(복제와 CDC에 필요) | 선택적(복제를 위해 사용되지 않음) |
| Binlog 성능 | I/O 오버헤드 발생 | 향상된 binlog로 I/O 성능 최적화 |
| 쓰기 처리 | Master 노드에서만 처리 | Writer 인스턴스에서 처리 |
| 읽기 처리 | Slave 노드에서만 처리(복제 지연 발생 가능) | Reader 인스턴스에서 처리(복제 지연 없음) |
| 데이터 일관성 | 복제 지연 발생 가능 | Writer와 Reader의 데이터 일관성 보장 |
| 확장성 | Slave 추가로 제한적 확장 | 최대 15개의 Reader 인스턴스 추가 가능 |
4. Aurora에서 binlog를 CDC(Change Data Capture) 용도로 사용하기에 부적합한 이유
4-1. Aurora의 아키텍처와 binlog 처리 지연
-
분산 스토리지 계층
- Aurora는 데이터를 분산 스토리지 계층에 기록하며, 데이터 변경 사항이 스토리지 계층에 즉시 적용된다.
- binlog는 데이터 변경 사항이 스토리지 계층에 기록된 후 추가적으로 작성된다.
- 이로 인해, binlog가 스토리지 계층의 데이터 변경 사항보다 항상 늦게 기록된다.
-
병렬 처리와 binlog 기록 지연
- Aurora의 분산 시스템은 쓰기 작업을 병렬로 처리하며 데이터 일관성을 보장.
- 반면, binlog는 트랜잭션 단위로 기록되므로 병렬 처리된 작업을 직렬화하여 기록해야 한다.
- 이 과정에서 binlog 기록이 스토리지 계층의 데이터 처리보다 느리게 이루어진다.
4-2. CDC 용도로의 부적합성
-
변경 데이터 수집 지연
- CDC는 실시간 또는 거의 실시간으로 데이터 변경 사항을 외부로 전달해야 한다.
- 그러나 Aurora의 binlog는 스토리지 계층 데이터 적용 후 기록되므로, CDC 용도로 사용할 경우 변경 사항 전달에 시간 지연이 발생하게 된다.
-
쓰기 성능과 binlog의 상충
- Aurora는 쓰기 작업을 빠르게 처리하기 위해 분산 아키텍처와 캐싱 메커니즘을 활용한다.
- 반면, binlog는 CDC를 위해 동기화된 기록을 요구하지만, Aurora의 최적화 방식과 충돌한다. 결과적으로 binlog는 CDC를 위해 설계된 최적화된 시스템이 아니다.
-
스토리지 계층과 binlog의 독립성
- Aurora는 binlog 대신 분산 스토리지 계층 자체에서 변경 사항을 관리하며, binlog는 선택적 기능으로 간주된다.
- 스토리지 계층에서 변경 사항이 즉시 반영되지만, binlog는 추가적인 I/O 작업으로 기록되기 때문에 실시간 CDC에는 부적합하다.
4-3. Aurora에서의 대안
-
Amazon Aurora 데이터 스트리밍(AWS DMS)
- AWS Database Migration Service(DMS)를 사용하면 Aurora에서 변경 사항을 캡처하여 외부 시스템으로 전송할 수 있습니다.
- DMS는 Aurora의 분산 스토리지 계층에서 직접 변경 데이터를 캡처하므로 binlog보다 실시간성이 높습니다.
-
AWS Lambda 트리거
- Aurora는 Lambda와 통합되어 데이터베이스 변경 사항을 실시간으로 처리할 수 있습니다.
-
Aurora 확장된 로그 기능
- Aurora는 binlog 외에 트랜잭션 로그 및 다른 내부 메커니즘을 통해 변경 사항을 관리하며, 이러한 로그를 활용한 CDC 구현이 더 효율적입니다.
| 특징 | Aurora의 binlog | 온프레미스 MySQL의 binlog |
|---|---|---|
| 기록 시점 | 데이터가 스토리지 계층에 적용된 후 기록 | 트랜잭션 커밋 시점에 즉시 기록 |
| CDC 용도로 적합성 | 부적합 (기록 지연) | 적합 (변경 사항을 즉시 반영) |
| 복제 목적 | 분산 스토리지로 대체 가능 | 복제에 필수적으로 사용 |
| 실시간성 | 낮음 | 높음 |
5. Aurora의 스토리지 엔진과 AZ의 개념
5-1. Aurora의 스토리지 계층
-
Aurora는 InnoDB 스토리지 엔진을 사용하지만, 기본 MySQL과는 스토리지 처리 방식이 다름.
-
기본 MySQL(InnoDB)
- MySQL에서 InnoDB는 데이터를 로컬 스토리지(온프레미스나 EC2의 디스크)에 저장.
- Master-Slave 방식에서 데이터 복제는 binlog를 통해 이루어짐.
-
Aurora
- InnoDB의 데이터 저장 방식을 클라우드 환경에 맞춰 확장
- 데이터를 10GB 단위의 세그먼트로 나누고, Amazon의 다중 가용 영역(AZ)에 걸쳐 자동 복제.
- Aurora의 “스토리지 계층”은 이러한 분산 저장 및 복제 기능을 담당.
5-2. AZ(Amazon Availability Zone)란?
-
AZ(Amazon 가용 영역)
- AWS의 데이터 센터를 물리적으로 격리된 여러 그룹으로 나눈 것
- 하나의 리전에 여러 AZ가 있으며, AZ 간은 저지연 네트워크로 연결되어 있다.
- Aurora는 데이터를 최소 3개의 AZ에 분산 저장하여 고가용성을 보장.
-
예를 들어:
- Aurora는 데이터의 6개의 복사본(복제본)을 3개의 AZ에 분산 저장.
- 각 AZ에는 2개의 복제본이 저장된다.
- 특정 AZ에 장애가 발생하더라도 다른 AZ의 복제본으로 데이터 일관성을 유지하고 복구 가능.
| 특징 | Aurora 스토리지 계층 | InnoDB (기본 MySQL) |
|---|---|---|
| 데이터 저장 위치 | 분산 스토리지 계층 (다중 AZ) | 로컬 스토리지 (디스크 또는 SSD) |
| 복제 방식 | 분산 스토리지 계층에서 자동 복제 | Master-Slave binlog 기반 복제 |
| 데이터 손실 가능성 | 6개의 복제본 중 3개 이상이 손실되지 않는 한 없음 | Master 또는 Slave 손실 시 |
| 확장성 | 자동 확장 (최대 128TB) | 디스크 크기에 따라 수동 확장 필요 |
| 읽기/쓰기 분리 | Writer-Reader 구조에서 분리 처리 | Master에서만 쓰기 처리, Slave는 읽기 전용 |
| 고가용성 | 자동 장애 복구 | 수동 장애 복구 (Replication 구성 필요) |
6. 데이터 저장 방식 비교
6-1. Aurora: 분산 스토리지 계층
-
데이터는 Reader 노드나 Writer 노드에 저장되지 않음.
- Aurora의 데이터는 분산 스토리지 계층에만 저장됩니다.
- Writer와 Reader 노드는 단지 분산 스토리지 계층에 저장된 데이터에 액세스하는 역할을 합니다.
-
저장 경로
- Writer 노드: 쓰기 작업 요청을 받아 데이터를 Aurora 분산 스토리지 계층에 기록.
- Reader 노드: 분산 스토리지 계층에서 데이터를 읽음. 데이터를 직접 저장하거나 변경하지 않음.
-
분산 스토리지 계층의 특징
- 데이터는 6개의 복제본(3개의 가용 영역에 각각 2개씩)에 저장됩니다.
- Writer와 Reader 모두 동일한 스토리지 계층을 참조하기 때문에, 데이터 일관성이 유지됩니다.
6-2. 온프레미스 MySQL: 로컬 스토리지
-
데이터는 Reader 노드(Master-Slave 아키텍처의 Slave 노드) 자체에 저장됩니다.
- Master는 데이터를 로컬 디스크(InnoDB 데이터 파일)에 저장하며, binlog를 통해 Slave로 데이터를 복제합니다.
- Slave는 이 복제 데이터를 로컬 디스크에 저장하여 읽기 요청을 처리합니다.
-
저장 경로
- Master 노드: 쓰기 작업 요청을 받아 데이터를 로컬 디스크에 저장.
- Slave 노드: Master의 binlog를 복제하여 데이터를 로컬 디스크에 저장. 읽기 요청을 처리할 때 로컬 데이터를 참조.
-
복제 지연
- Slave 노드는 Master에서 데이터를 복제받아야 하기 때문에, 데이터 저장 시점에서 지연(Lag)이 발생할 수 있음.
참고 문헌

Data Engineer