Parquet 정리
1. Parquet (파케이)
- 데이터를 저장하는 방식 중 하나로 하둡생태계에서 많이 사용되는 파일 포맷이다.
- 빅데이터를 처리할 때는 많은 시간과 비용이 들어가기 때문에 빠르게 읽고, 압축률이 좋아야 한다. 이러한 특징을 가진 파일 포맷으로는 Parquet(파케이), ORC, Avro(에이브로)가 있다.
2. 파케이가 압축률이 좋은 이유: 컬럼기반 저장포맷
-
데이터베이스를 예시로 들면, 행 기반으로 저장하는 방식(대표적으로 MySQL)과 열 기반(대표적으로 BigQuery)으로 저장하는 방식이 있다.
-
다음과 같은 데이터베이스가 있다고 했을때
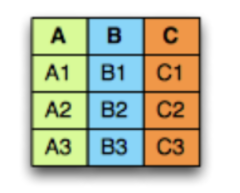
-
행 기반
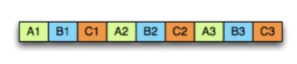
-
열 기반

-
-
열 기반으로 저장되는 것이 압축률이 더 좋은 이유는 다음과 같이 설명할 수 있다.
같은 컬럼에는 종종 유사한 데이터가 나열된다. 특히 같은 문자열의 반복은 매우 작게 압축할 수 있다. 데이터의 종류에 따라 다르지만, 열 지향 데이터베이스는 압축되지 않은 행 지향 데이터 베이스와 비교하면 1/10 이하로 압축 가능하다.
-
데이터 분석에서는 종종 일부 칼럼만이 집계 대상이기 때문에, 이렇게 열 기반으로 압축하면 필요한 칼럼만을 빠르게 읽고 집계할 수 있다.
그렇다면 열 기반으로만 저장하는게 좋은 거 아닌가?
-
위와 같은 궁금증이 들 수 있는데 MySQL 의 경우 대표적인 행 기반 저장 방식의 데이터베이스이다.
-
행 기반 데이터베이스는 매일 발생하는 대량의 트랜잭션을 지연 없이 처리하기 위해 데이터 추가를 효율적으로 할 수 있도록 하는 것이 행 지향 데이터베이스의 특징이다.
-
새로운 레코드를 추가할 경우 끝부분에 추가되기 때문에 고속으로 쓰기가 가능하다.
-
3. Parquet 장점
-
위에서 설명한대로 칼럼단위로 압축하기 압축률이 좋다.
- 이렇게 되면 파일의 크기도 작아지기 때문에 용량을 덜 차지하게 된다.
-
디스크 IO 가 적다. 데이터를 미리 칼럼 단위로 정리해 둠으로써 필요한 칼럼만을 로드하기 때문
4. Parquet 구조
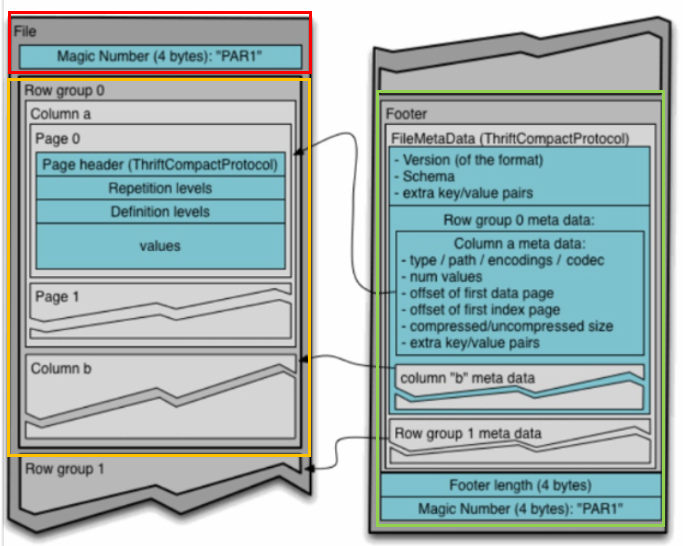
- 파케이 파일은 헤더, 하나 이상의 블록, 꼬리말 순으로 구성
4-1. 헤더
- 파케이 포맷의 파일임을 알려주는 4바이트 매직 숫자인 PAR1 만 포함
4-2. 블록
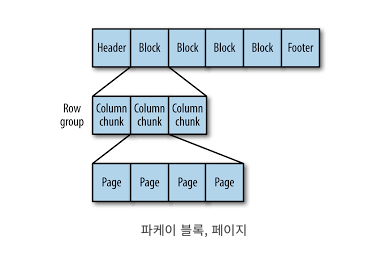
-
각 블록은 row group을 저장
- row group은 동일한 스키마를 가진 레코드의 묶음
- 각 row group은 독립적으로 압축되고 저장
-
row group은, row에 대한 column chunk로 되어 있다.
-
각 column chunk의 데이터는 페이지에 기록된다.
- Parquet에서 Block은 각 컬럼의 데이터를 일정한 크기 단위로 나누어 저장한 구조를 의미한다.
- 이러한 Block은 실제로 페이지(Page)라고 불린다.
-
각 페이지는 동일한 column의 값만 포함하고 있다.
-
따라서 페이지의 있는 값은 비슷한 결향이 있기 때문에 페이지를 압축할 때 유리하다.
row group과 column chunk
예시 테이블
ID Name Age Country 1 Alice 30 USA 2 Bob 25 Canada 3 Charlie 35 UK 4 David 28 Australia 5 Eve 40 Germany
- row group 1:
레코드: (ID=1, Name=Alice, Age=30, Country=USA), (ID=2, Name=Bob, Age=25,Country=Canada), (ID=3, Name=Charlie, Age=35, Country=UK)
row group 1:
Column Chunk 1 (ID 컬럼):
데이터: [1, 2, 3, 4, 5]Column Chunk 2 (Name 컬럼):
데이터: [Alice, Bob, Charlie, David, Eve]Column Chunk 3 (Age 컬럼):
데이터: [30, 25, 35, 28, 40]Column Chunk 4 (Country 컬럼):
데이터: [USA, Canada, UK, Australia, Germany]
4-3. 꼬리말
- 파일의 모든 메타데이터는 꼬리말(Footer) 에 저장
5. 참고자료
