View
View는 실제 테이블은 아니고 참조를 할 때마다 쿼리를 보내 테이블처럼 보여주는 기능이며 이 기능을 Redshift에서도 사용할 수 있다.
1. View 생성 문법
CREATE [ OR REPLACE ] VIEW name [ ( column_name [, ...] ) ] AS query
[ WITH NO SCHEMA BINDING ]-
OR REPLACE: 같은 이름의 뷰가 이미 있을 경우 쿼리를 교체한다.
-
name: 뷰 이름
-
column_name: 뷰에서 사용할 컬럼명, 입력하지 않으면 쿼리를 보고 자동으로 생성한다.
-
query: 쿼리
-
WITH NO SCHEMA BINDING: 뷰가 데이터베이스 객체에 바인딩 되지 않도록 하여 종속성을 없앤다.
-
Late Binding
- 쿼리될 때까지 데이터베이스 객체를 확인하지 않는다.
- 뷰를 변경하지 않고 기존 테이블을 변경할 수 있다.
-
스키마
- 이 옵션을 사용할 때는 스키마가 반드시 존재해야 한다. 예를 들면 FROM event가 아닌 FROM public.event 와 같은 방식으로 사용해야 한다.
-
2. 생성 예시
기본
CREATE VIEW public.sample_event_view as SELECT eventname FROM event WHERE eventname='click'Late Binding
CREATE VIEW public.sample_event_view AS SELECT * FROM public.event WHERE event_name='click' WITH NO SCHEMA BINDING3. 사용 예시
SELECT * FROM sample_event_view LIMIT 1Materialized View
Amazon Redshift에서는 테이블에서 질의한 보기(View)는 Amazon QuickSight 또는 Tableau 같은 BI(비즈니스 인텔리전스) 도구를 위해 사용할 수 있습니다. 다만, 사용 편의성과 유연성을 제공하지만 데이터 액세스의 속도를 높여 주지 않습니다.
성능이 중요한 경우, 데이터 엔지니어는 CTAS(create table as)를 사용합니다. CTAS는 질의에 의해 정의된 테이블입니다. 질의는 테이블 생성 시점에 실행되며 애플리케이션은 CTAS를 일반 테이블과 같이 사용할 수 있습니다. 단, CTAS 데이터 세트의 단점은 관련 데이터가 업데이트되었을 때 새로 고쳐지지 않는다는 것입니다. 뿐만 아니라, CTAS 정의는 데이터베이스 시스템에 저장되지 않습니다. 테이블이 CTAS에 의해 생성되었는지 여부를 알 수 없기 때문에 어느 CTAS를 새로 고쳐야 하며 어느 것이 최신인지 추적하기가 어렵습니다.
이제 Amazon Redshift를 위한 구체화 보기(Materialized View)를 도입합니다. MV(구체화 보기)는 질의 데이터를 포함하는 데이터베이스 객체입니다. 구체화된 보기는 캐시와 같습니다. 데이터 세트를 런타임 시 구축 및 계산하는 대신, 구체화된 보기는 보기를 생성하는 시점에 데이터를 사전 계산하고, 저장하고, 데이터 액세스를 최적화합니다. 데이터는 일반 테이블 데이터와 똑같이 준비되고 쿼리에 사용할 수 있습니다.
기준 테이블의 데이터가 변경되면 Redshift SQL문 “refresh materialized view“를 사용하여 구체화된 보기를 새로 고쳐야 합니다. 새로 고침 문을 사용한 후에는 구체화된 보기에 일반 보기가 반환하는 것과 동일한 데이터가 포함됩니다. 새로 고침은 증분적 새로 고침 또는 전체 새로 고침(재계산)이 될 수 있습니다. 가능한 경우, Redshift는 구체화된 보기가 마지막으로 새로 고쳐진 후에 기준 테이블에서 변경된 데이터를 증분적으로 새로 고칩니다.
이제 작동 방식을 살펴 보겠습니다. 판매 정보, 즉 각 판매 거래 및 판매가 발생한 매장에 대한 세부 정보를 저장할 샘플 스키마를 생성합니다.
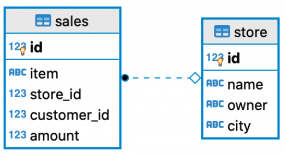
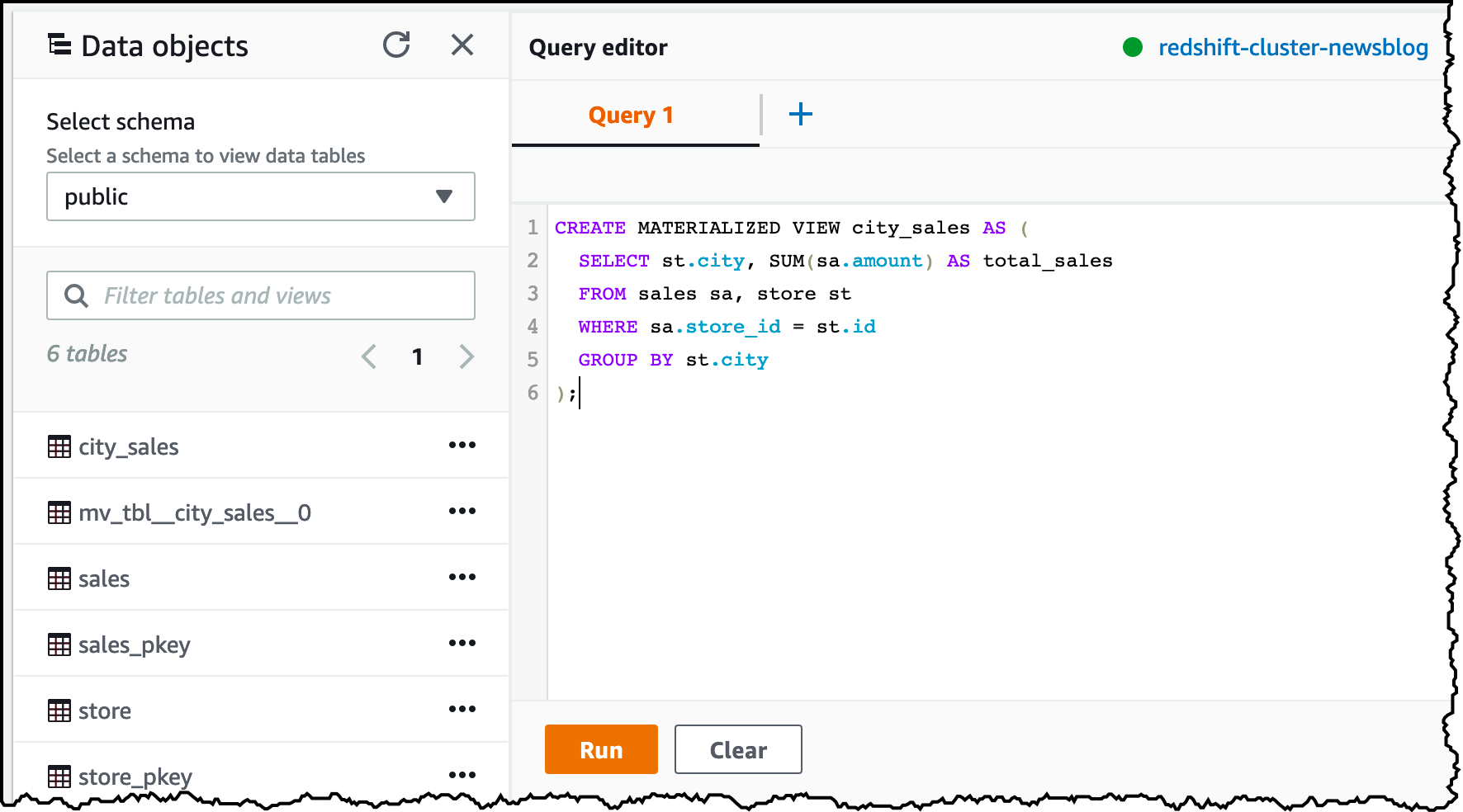
도시별 총 판매량을 보기 위해 create materialized view SQL문으로 구체화된 보기를 생성합니다. Redshift 콘솔에 연결하고, 쿼리 Editor를 선택하고 다음 문을 입력하여 두 개의 테이블에 있는 레코드를 조인하고 도시별(group by city) 판매 금액(sum(sales.amount))을 집계하는 구체화된 보기(city_sales)를 생성합니다.
CREATE MATERIALIZED VIEW city_sales AS (
SELECT st.city, SUM(sa.amount) as total_sales
FROM sales sa, store st
WHERE sa.store_id = st.id
GROUP BY st.city
);
그 결과 다음과 같은 스키마가 만들어집니다.
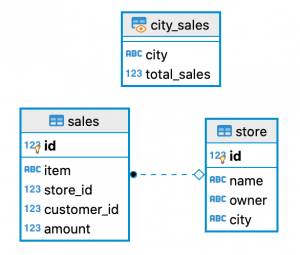
이제 일반 보기 또는 테이블과 똑같이 구체화된 보기를 쿼리할 수 있으며 “SELECT city, total_sales FROM city_sales”와 같은 문을 통해 아래의 결과를 얻을 수 있습니다. 두 테이블의 조인 및 집계(sum and group by)는 이미 계산되어 있으므로 검색할 데이터가 상당히 줄어듭니다.
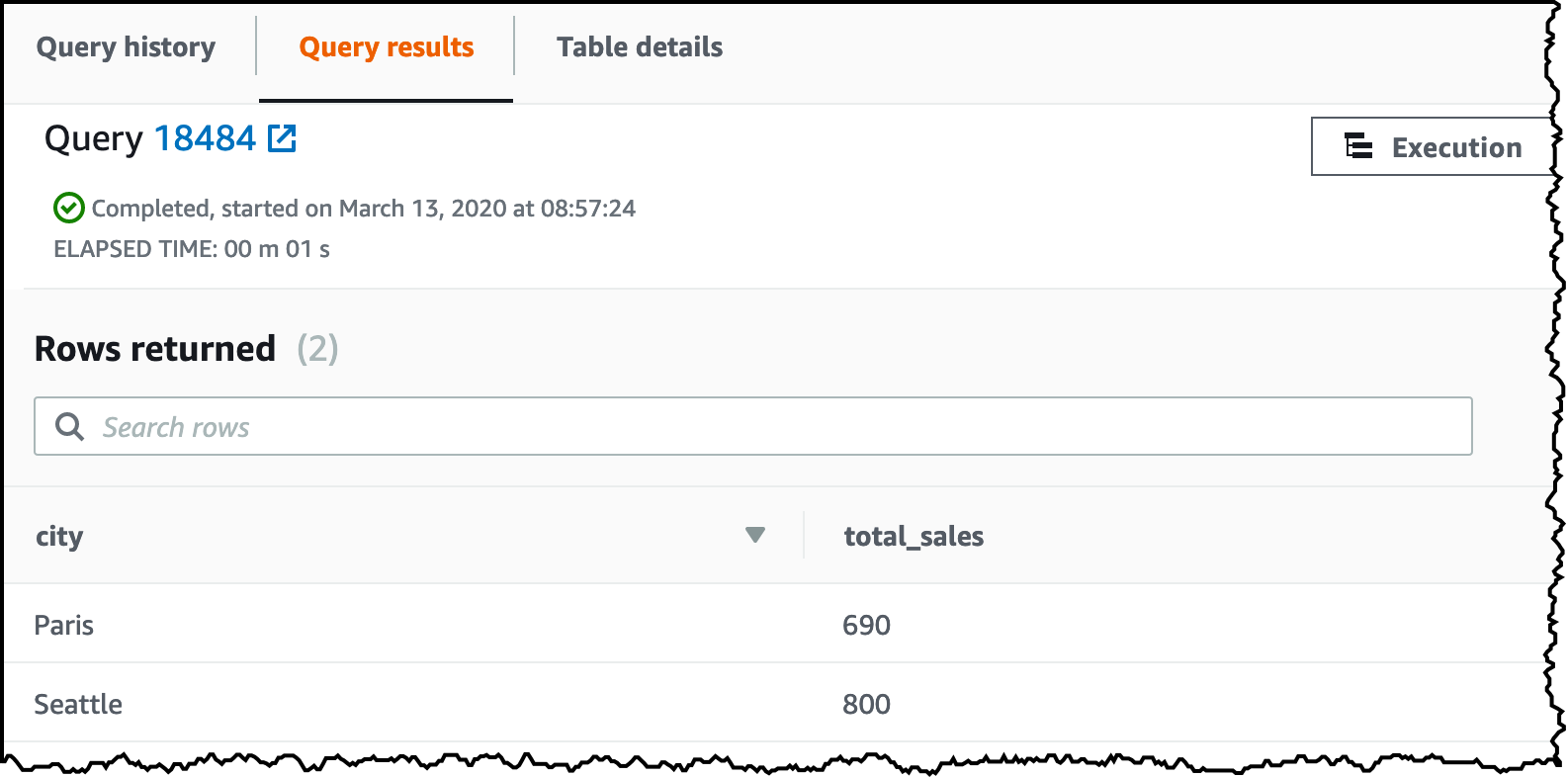
기준 테이블의 데이터가 변경되면 구체화된 보기에는 이러한 변경 사항이 자동으로 반영되지 않습니다. 구체화된 보기에 저장된 데이터는 온디맨드 방식으로 SQL refresh materialized view 명령을 사용하여 기준 테이블의 최신 변경 사항으로 새로 고칠 수 있습니다. 실제 예를 살펴보겠습니다.
!-- let's add a row in the sales base table
INSERT INTO sales (id, item, store_id, customer_id, amount)
VALUES(8, 'Gaming PC Super ProXXL', 1, 1, 3000);
SELECT city, total_sales FROM city_sales WHERE city = 'Paris'
city |total_sales|
-----|-----------|
Paris| 690|
!-- the new sale is not taken into account !
!-- let's refresh the materialized view
REFRESH MATERIALIZED VIEW city_sales;
SELECT city, total_sales FROM city_sales WHERE city = 'Paris'
city |total_sales|
-----|-----------|
Paris| 3690|
!-- now the view has the latest sales data간단한 이 데모의 전체 코드는 gist 형태로 제공됩니다. 구체화된 보기는 지금 모든 AWS 리전에서 사용할 수 있습니다. 기존 클러스터의 어떤 부분도 변경하지 않고 구체화된 보기를 사용할 수 있으며, 추가 비용 없이 지금 바로 생성할 수 있습니다.
참고
