- 18장에서는 애플리케이션 모니터링 및 디버깅용 도구를 사용해 잡의 신뢰도를 높일 수 있었음
- 이번에는 잡의 실행 속도를 높이기 위한 성능 튜닝 방법을 알아볼 것임
- 주요 튜닝 영역
- 코드 수준의 설계(ex) RDD와 DataFrame 중 하나 선택)
- 보관용 데이터
- 조인
- 집계
- 데이터 전송
- 애플리케이션별 속성
- 익스큐터 프로세스의 JVM
- 워커 노드
- 클러스터와 배포 환경 속성
- 성능 튜닝의 두 가지 유형
- 간접적인 성능 튜닝
- 속성값이나 런타임 환경을 변경해서 성능 튜닝
- 이는 전체 스파크 애플리케이션이나 잡에 영향을 미침
- 직접적인 성능 튜닝
- 개별 스파크 잡, 스테이지, 태스크 성능 튜닝이나 코드 설계를 변경하여 성능 튜닝
- 이는 애플리케이션의 특정 영역에만 영향을 미침
- 간접적인 성능 튜닝
간접적인 성능 향상 기법
- 하드웨어 개선도 포함되지만 여기선 사용자가 제어 가능한 사항만을 다룰 것임
설계 방안
- 좋은 설계 방안으로 애플리케이션을 설계하는 것은 매우 중요
- 외부 환경이 변해도 계속 안정적이고, 일관성 있게 실행할 수 있기 때문
스칼라 vs 자바 vs 파이썬 vs R
- 스파크의 구조적 API는 속도와 안정성 측면에서 여러 언어를 일관성 있게 다룰 수 있으므로 상황에 맞게 잘 고르면됨
- 근데 구조적 API로 만들 수 없는 사용자 정의 트랜스포메이션을 사용해야 하는 경우라면(RDD 트랜스포메이션이나 UDF)
- R이나 파이썬은 사용하지 않는 것이 좋음
- 데이터 타입과 처리 과정을 엄격하게 보장하기 어렵기 때문
- R이나 파이썬은 사용하지 않는 것이 좋음
DataFrame vs SQL vs Dataset vs RDD
-
모든 언어에서 DataFrame, Dataset, SQL의 속도는 동일
-
자바나 스칼라를 사용해 UDF를 정의하는 것이 좋음
- 파이썬이나 R을 사용해 UDF를 정의하면 성능 저하가 발생할 수 있음
- 근데 근본적으로 성능을 개선하고 싶다면 UDF말고 DataFrame이나 SQL을 사용해야 함
-
RDD를 사용하려면 스칼라나 자바를 사용하는 것이 좋음
- 사용자가 직접 RDD 코드를 작성하면 스파크 SQL 엔진에 추가되는 최적화 기법을 사용할 수 없음
- 아니면 RDD의 사용 영역을 최소한으로 제한하자
RDD 객체 직렬화
- Kryo를 이용해 직접 정의한 데이터 타입을 직렬화할 수 있음
- Kryo는 자바 직렬화보다 훨씬 간결하고 효율적
- 하지만 사용할 클래스를 등록해야해서 번거로움
클러스터 설정
- 클러스터 설정으로 잠재적으로 큰 이점을 얻을 수 있음
- 하지만 하드웨어와 사용 환경에 따라 변화하므로 대응하기 더 어려울 수 있음
동적 할당
- 스파크는 워크로드에 따라 애플리케이션이 차지할 자원을 동적으로 조절하는 매커니즘을 제공함
- 즉 사용하지 않는 자원은 클러스터에 반환하고 필요할 때 다시 요청
- 이 기능은 다수의 애플리케이션이 스파크 클러스터의 자원을 공유하는 환경에서 특히 유용
- 근데 기본적으로 비활성화 되어 있음 (링크)
스케줄링
- 16,17장 참고
- 여러 사용자가 자원을 더 효율적으로 공유하기 위해 FAIR 스케줄링으로 설정
- 애플리케이션에 필요한 익스큐터 코어 수의 max값을 조절하여 사용자 애플리케이션이 클러스터 자원을 모두 사용하지 못하도록 막을 수 있음
보관용 데이터
- 빅데이터 프로젝트를 성공적으로 수행하려면 데이터를 효율적으로 읽어 들일 수 있도록 저장해야함
- 그러므로 적절한 저장소 시스템과 데이터 포맷을 선택해야함
- 데이터 파티셔닝 가능한 데이터 포맷을 활용해야함
파일 기반 장기 데이터 저장소
-
파일 기반 장기 데이터 저장소에는 다양한 데이터 포맷을 사용할 수 있음
- CSV파일, 바이너리 blob파일, 아파치 파케이 등
-
데이터를 바이너리 형태로 저장하려면 구조적 API를 사용하는 것이 좋음
-
CSV같은 파일은 구조화되어 있는 것처럼 보이지만 파싱 속도가 아주 느리고 예외 상황이 자주 발생함
- 부적절하게 처리된 개행문자는 대량의 파일을 읽을 때 많은 문제를 일으킴
-
가장 효율적으로 사용할 수 있는 파일 포맷은 아파치 파케이
- 데이터를 바이너리 파일에 컬럼 지향 방식으로 저장함
- 또한 쿼리에서 사용하지 않는 데이터를 빠르게 건너뛸 수 있도록 몇 가지 통계를 함께 저장함
- 스파크는 파케이 데이터소스를 내장하고 있으며 파케이 파일과 잘 호환됨
분할 가능한 파일 포맷과 압축
- 파일 포맷을 선택할 때, 분할 가능한 포맷인지 확인해야함
- 여러 태스크가 파일의 서로 다른 부분을 동시에 읽을 수 있기 때문
- 파일을 읽을 때 모든 코어를 활용할 수 있기 때문
- JSON파일은 분할이 불가능해서 병렬성이 급격히 떨어짐
- 압축 포맷은 ZIP, TAR은 분할 X
- gzip,bzip2,lz4를 이용해 압축된 파일이면 분할 O
테이블 파티셔닝
- 9장 참고
- 데이터의 날짜 필드 같은 키를 기준으로 개별 디렉터리에 파일을 저장하는 것이 테이블 파티셔닝
- 따라서 특정 범위의 데이터만 필요할 때 관련 없는 데이터 파일을 건너뛸 수 있음
- 근데 너무 작은 단위로 분할하면 작은 크기의 파일이 대량으로 생성될 수 있으니 조심
- 이는 저장소 시스템에서 전체 파일의 목록을 읽을 때 오버헤드가 발생
버켓팅
- 9장 참고
- 사용자가 조인이나 집계를 수행하는 방식에 따라 데이터를 사전 분할할 수 있음
- 고비용의 셔플을 피할 수 있음
- 버켓팅은 물리적 데이터 분할 방법의 보완재로서 보통 파티셔닝과 함께 적용
파일 수
-
데이터를 파티션이나 버켓으로 구성하려면 파일 수와 저장하려는 파일 크기도 고려해야함
-
작은 파일이 많으면 파일 목록 조회와 파일 읽기 과정에서 부하가 발생함
-
근데 트레이드오프가 있음
- 작은 크기의 파일이 다수
- 스케줄러가 많은 수의 데이터 파일을 모두 찾아 모든 읽기 태스크를 수행해야하므로 네트워크와 잡의 스케줄링 부하가 증가
- 큰 크기의 파일이 소수
- 스케줄러의 부하를 줄일 수 있지만 태스크 수행 시간이 더 길어짐
- 근데 입력 파일 수보다 더 많은 태스크 수를 스파크에 설정해서 병렬성을 높일 순 있음
- 작은 크기의 파일이 다수
-
데이터를 효율적으로 저장하려면 입력 데이터 파일이 최소 수십 메가바이트의 데이터를 갖도록 파일의 크기를 조정하는 것이 좋음
데이터 지역성
- 데이터 지역성: 네트워크를 통해 데이터 블록을 교환하지 않고 특정 데이터를 가진 노드에서 동작할 수 있도록 지정하는 것
- 저장소 시스템이 스파크와 동일한 노드에 있고 해당 시스템이 데이터 지역성을 제공한다면
- 스파크는 입력 데이터 블록과 최대한 가까운 노드에 태스크를 할당하려 함
- 참고
통계 수집
- 스파크의 구조적 API를 사용하면 비용 기반 쿼리 옵티마이저가 내부적으로 동작함
- 쿼리 옵티마이저: 입력 데이터의 속성을 기반으로 쿼리 실행 계획을 만듦
- 근데 여기서 비용 기반으로 옵티마이저가 작동하려면 정보가 필요함
- 즉, 사용 가능한 테이블과 관련된 통계를 수집해야함
- 통계
- 이름이 지정된 테이블에서만 사용 가능(임의의 DataFrame이나 RDD에서는 사용 X)
- 테이블 수준과 컬럼 수준 두 가지 종류가 있음
- 통계는 조인, 집계, 필터링 등 여러 잠재적인 상황에서 도움됨
- 참고
셔플 설정
- 외부 셔플 서비스
- 머신에서 실행되는 익스큐터가 바쁜 상황에서도 원격 머신에서 셔플 데이터를 읽을 수 있으므로 성능을 높일 수 있음
- 하지만 코드가 복잡해짐
- 자바 직렬화 대신 Kryo 직렬화
- 직렬화 포맷은 RDD 기반 스파크 잡의 셔플 성능에 큰 영향을 미침
- 파티션 수
- 셔플 수행 시 결과 파티션당 최소 수십 메가바이트의 데이터가 포함되도록 하자
- 파티션 수가 너무 적으면 소수의 노드만 작업을 수행하므로 데이터 치우침 현상이 발생
- 파티션 수가 너무 많으면 파티션을 처리하기 위한 태스크를 많이 실행해야 하므로 부하 발생
메모리 부족과 가비지 컬렉션(GC)
-
메모리 부족의 원인 3가지
- 애플리케이션 실행 중에 메모리를 너무 많이 사용한 경우
- GC가 자주 수행되는 경우
- JVM 내에서 객체가 너무 많이 생성되어 더 이상 사용하지 않는 객체를 GC가 정리하면서 실행 속도가 저하
-
3번 문제는 구조적 API로 해결 가능
-
JVM객체를 생성하지 않으므로
JVM 메모리 관리에 대하여
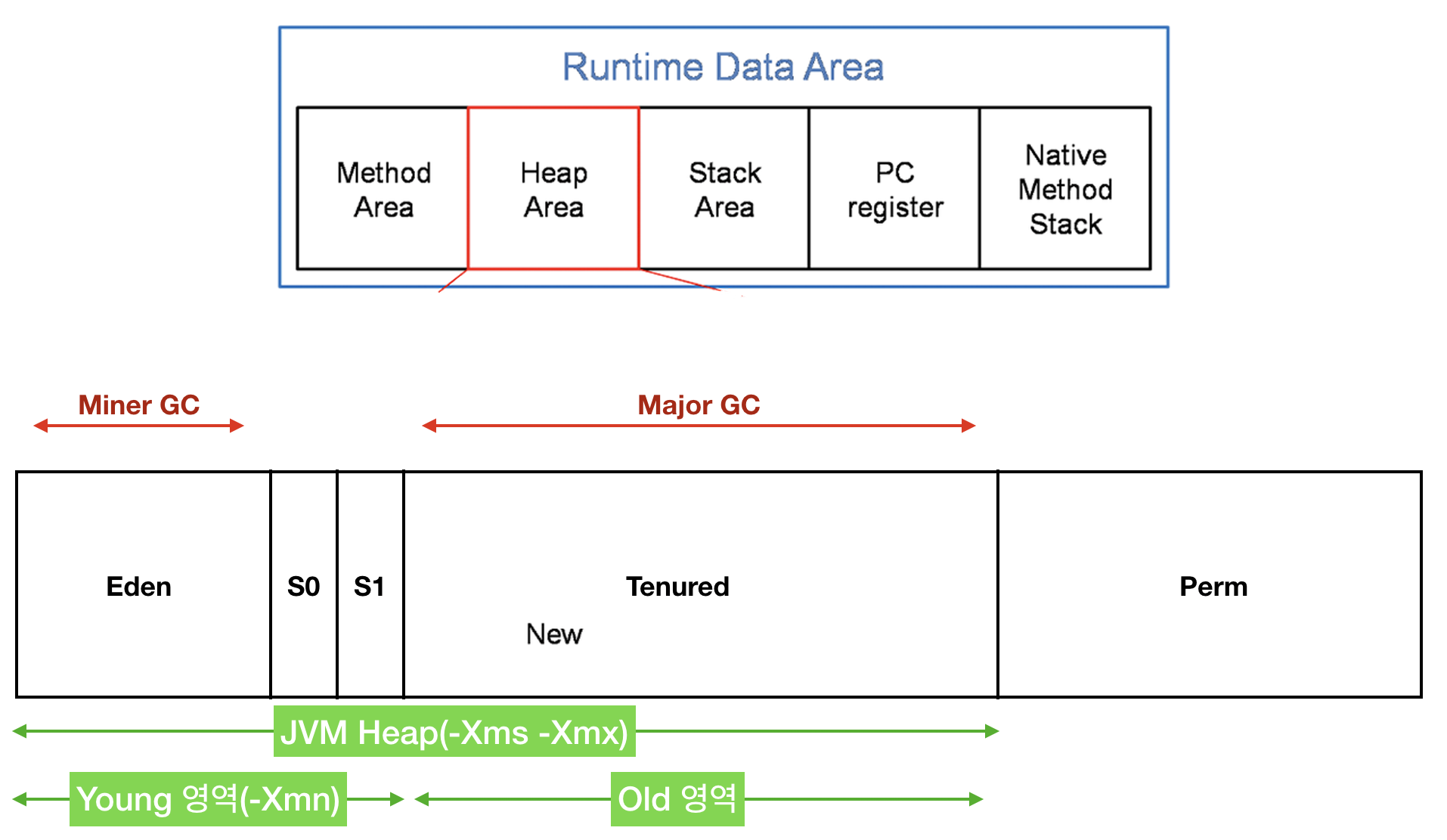
- JVM 메모리 구조
- Young 영역: 수명이 짧은 객체를 유지
- Old 영역: 오래 살아 있는 객체를 유지
- Young 영역은 다시 Eden, Survivor1(S1),2(S2) 세 영역으로 나뉨
- 가비지 컬렌션 수행 절차
- Eden 영역이 가득 차면 Eden 영역에 대한 minor GC가 실행됨
- Eden 영역에서 살아남은 객체와 S1 영역의 객체는 S2 영역으로 복제됨
- S1,2 영역을 교체함
- 객체가 아주 오래되었거나 S2 영역이 가득 차면 객체는 Old 영역으로 옮겨짐
- Old 영역이 거의 가득 차면 full GC가 실행됨
- full GC는 minor GC + major GC로, 가장 느린 GC
- 힙 공간의 모든 객체를 추적해서 참조 정보가 없는 객체를 제거함
- 그리고나서 남은 객체들을 빈 곳으로 옮김
- 참고
가비지 컬렉션 영향도 측정
- 발생 빈도와 소요 시간에 대한 통계를 모아 영향도 확인
- 태스크가 완료되기 전에 full GC가 자주 발생하는 것이 확인되면, 캐싱에 사용되는 메모리양을 줄여야함
가비지 컬렉션 튜닝
- full GC를 피하는 방법
- 수명이 긴 캐시 데이터셋을 Old 영역에 저장
- Young영역에서 수명이 짧은모든 객체를 보관 할 수 있도록 충분한 공간 유지
- minor GC는 매우 많이 발생하지만 major GC는 자주 발생하지 않는다면, Eden 영역에 메모리를 더 할당
직접적인 성능 향상 기법
- 지금부터 다룰 내용은 특정 스테이지나 스파크 잡이 가진 문제점에 대한 일종의 '임시방편'용 해결책
- 스테이지나 잡을 개별적으로 검사하는 최적화 방법도 포함
병렬화
- 특정 스테이지의 처리 속도를 높이려면 가장 먼저 병렬성을 높이는 작업부터 시작해야함
- spark.sql.shuffle.partitions 값을 클러스터 코어 수에 따라 설정
- 스테이지에 처리해야 할 데이터양이 매우 많다면 클러스터의 CPU 코어당 최소 2~3개 태스크 할당
향상된 필터링
- 필터링을 가장 먼저 수행하여 최종 결과와 무관한 데이터를 배제하고 작업 진행하여 성능 향상
- 파티셔닝과 버켓팅 기법을 활용하는 것 또한 성능 향상을 도움
파티션 재분배와 병합
- 파티션 재분배 과정은 셔플을 수반하지만 클러스터 전체에 데이터가 균등하게 분배되므로 잡의 전체 실행단계를 최적화함
- 병렬성을 높일 수 있음
- 다만 셔플을 할 때 가능한 적은 양의 데이터를 셔플하는 것이 좋음
- coalesce 메서드로 전체 파티션 수를 먼저 줄이자
사용자 정의 파티셔닝
- 잡이 여전히 느리고 불안정하다면 RDD를 이용한 사용자 정의 파티셔닝 기법을 적용하여 성능 향상
- DataFrame보다 더 정밀한 수준으로 클러스터 전반의 데이터 체계 제어 가능
사용자 정의 함수(UDF)
- UDF 최대한 피하여 성능 향상
- 데이터를 JVM 객체로 변환하고 쿼리에서 레코드당 여러 번 수행되므로 많은 자원을 소모함
임시 데이터 저장소(캐싱)
- 애플리케이션에서 같은 데이터셋을 계속해서 재사용한다면 캐싱을 사용해 성능 향상
- 근데 캐싱이 항상 유용한 것은 아님
- 데이터를 캐싱할 때 직렬화, 역직렬화 그리고 저장소 자원을 소모하기 때문
- 따라서 데이터셋을 한 번만 처리하는데 굳이 캐싱을 한다면 성능 저하
조인
- 조인 순서를 변경으로 성능 향상
- inner 조인 먼저
- 브로드캐스트 조인 힌트 사용으로 성능 향상
- 조인 전에 테이블 통계 수집으로 성능 향상
- 스파크가 조인 타입을 결정하는 데 유용하게 사용함
- 버켓팅으로 성능 향상
- 조인 수행 시 거대한 양의 셔플이 발생하지 않도록 방지
집계
- 집계 전 충분히 많은 수의 파티션을 가질 수 있도록 데이터 필터링
브로드캐스트 변수
- 다수의 UDF에서 큰 데이터 조각을 사용한다면, 해당 데이터 조각을 개별 노드에 전송하여 읽기 전용 복사본으로 저장하여 재전송 과정을 건너뛰도록 함

Data Engineer