- 이벤트 시간 처리와 상태 기반 처리의 핵심 아이디어는 잡의 전체 생명주기 동안 관련 상태를 유지하는 것
- 이 두 가지 방식을 사용해서 데이터를 싱크로 출력하기 전에 정보를 갱신할 수 있음
이벤트 시간 처리
- 스트림 처리 시스템의 두 가지 이벤트 시간 유형
- 이벤트가 실제로 발생한 시간(이벤트 시간)
- 이벤트가 시스템에 도착한 시간 또는 처리된 시간(처리 시간)
1. 이벤트 시간
- 데이터에 기록되어 있는 시간으로, 대부분 이벤트가 실제로 일어난 시간을 의미
- 이벤트 시간은 다른 이벤트와 비교하는 강력한 방법을 제공하므로 사용해야한다.
- 근데 지연되거나 무작위로 도착하는 이벤트를 해결해야한다는 문제점이 있음
- 컴퓨터 네트워크의 신뢰도는 낮음
- 따라서 스트림 처리 시스템은 반드시 지연되거나 무작위로 도착한 데이터를 제어할 수 있어야함
- ex) 이벤트가 시스템에 늦게 도착하여 원래 속해야 하는 윈도우 처리용 배치가 이미 시작되었다면 다른 윈도우 처리용 배치에서 이벤트가 처리됨
2. 처리 시간
- 스트림 처리 시스템이 데이터를 실제로 수신한 시간
- 처리 시간은 이벤트 시간처럼 외부 시스템에서 제공하는 것이 아니라 스트리밍 시스템이 제공하는 속성이므로 순서가 뒤섞이진 않음
거리에 따른 이벤트 시간 문제 예시
-
데이터센터의 위치: 샌프란시스코
-
상황
- 동시에 콰도르, 버지니아에서 이벤트 발생
- 근데 데이터 센터와 위치가 더 가까운 버지니어에서 발생한 이벤트가 먼저 데이터센터에 도착
-
문제점
- 처리 시간 기반으로 데이터를 분석하면 버지니아 이벤트가 에콰도르 이벤트보다 먼저 발생한 것으로 나타나므로 정상적이지 않음
-
해결방법
- 이벤트 시간 기준으로 데이터를 분석하면 두 이벤트를 같은 시간에 발생한 이벤트로 처리할 수 있음
상태 기반 처리
- 오랜 시간에 걸쳐 중간 처리 정보(상태)를 사용하거나 갱신하는 경우에만 필요
- 스파크는 상태 기반 연산에 필요한 중간 상태 정보를 상태 저장소에 저장함
- 스파크는 인메모리 상태 저장소 제공
- 인메모리 상태 저장소는 중간 상태를 체크포인트 디렉터리에 저장해서 내고장성을 보장함
임의적인 상태 기반 처리
-
상태 기반 처리에서 상태의 유형, 갱신 방법, 제거 시점 등에 따라 세밀한 제어가 필요한 경우에 필요
-
사용자는 스트림 처리에 필요한 모든 정보를 스파크에 저장할 수 있음
- 뛰어난 유연성과 강력함을 얻을 수 있음
-
예시
- 전자 상거래 사이트에서 실시간 추천 서비스를 제공하기 위해 현재 세션에서 사용자가 어떤 페이지를 방문했는지 추적하고 싶은 경우
- 웹 애플리케이션에서 사용자 세션별로 오류가 5번 발생했을때 오류를 보고해야하는 경우
- 카운트 기반 윈도우를 사용하면 처리 가능
- 중복 이벤트를 계속해서 제거해야하는 경우
- 과거의 모든 레코드를 추적해서 중복 데이터를 제거해야함
-
카운트 기반 윈도우
- 시간이 아닌 발생하는 이벤트 수(상태나 이벤트 시간에 무관)를 기반으로 윈도우를 만들고 집계 연산 수행하고 싶은 경우에 사용
- ex) 500개의 이벤트를 수신한 순간에 연산 수행
- 시간이 아닌 발생하는 이벤트 수(상태나 이벤트 시간에 무관)를 기반으로 윈도우를 만들고 집계 연산 수행하고 싶은 경우에 사용
이벤트 시간 처리의 기본
from pyspark.sql import functions as F
from pyspark.sql import types as Tpath = 'FileStore/tables/bin/activity-data'
spark.conf.set('spark.sql.shuffle.partitions',5)static = spark.read.json(path)display(static.limit(5))| Arrival_Time | Creation_Time | Device | Index | Model | User | gt | x | y | z |
|---|---|---|---|---|---|---|---|---|---|
| 1424686735090 | 1424686733090638193 | nexus4_1 | 18 | nexus4 | g | stand | 3.356934E-4 | -5.645752E-4 | -0.018814087 |
| 1424686735292 | 1424688581345918092 | nexus4_2 | 66 | nexus4 | g | stand | -0.005722046 | 0.029083252 | 0.005569458 |
| 1424686735500 | 1424686733498505625 | nexus4_1 | 99 | nexus4 | g | stand | 0.0078125 | -0.017654419 | 0.010025024 |
| 1424686735691 | 1424688581745026978 | nexus4_2 | 145 | nexus4 | g | stand | -3.814697E-4 | 0.0184021 | -0.013656616 |
| 1424686735890 | 1424688581945252808 | nexus4_2 | 185 | nexus4 | g | stand | -3.814697E-4 | -0.031799316 | -0.00831604 |
streaming = spark.readStream.schema(static.schema).option('maxFilesPerTrigger', 10).json('/'+path)streaming.printSchema()root
-- Arrival_Time: long (nullable = true)
-- Creation_Time: long (nullable = true)
-- Device: string (nullable = true)
-- Index: long (nullable = true)
-- Model: string (nullable = true)
-- User: string (nullable = true)
-- gt: string (nullable = true)
-- x: double (nullable = true)
-- y: double (nullable = true)
-- z: double (nullable = true)- 이 데이터셋에는 두 개의 시간 컬럼이 있음
- Arrival_Time: 서버에 도착한 시간
- Creation_Time: 이벤트가 생성된 시간
이벤트 시간 윈도우
- 이벤트 시간 분석을 하려면 타임스탬프 컬럼을 적절한 스파크 SQL 타임스탬프 데이터 타입으로 변환해야함
- 현재 컬럼은 나노세컨드 단위의 유닉스 시간타입
display(static.withColumn('event_time', (F.col('Creation_Time')/1000000000).cast(T.TimestampType())).limit(5))| Arrival_Time | Creation_Time | Device | Index | Model | User | gt | x | y | z | event_time |
|---|---|---|---|---|---|---|---|---|---|---|
| 1424686735090 | 1424686733090638193 | nexus4_1 | 18 | nexus4 | g | stand | 3.356934E-4 | -5.645752E-4 | -0.018814087 | 2015-02-23T10:18:53.090+0000 |
| 1424686735292 | 1424688581345918092 | nexus4_2 | 66 | nexus4 | g | stand | -0.005722046 | 0.029083252 | 0.005569458 | 2015-02-23T10:49:41.345+0000 |
| 1424686735500 | 1424686733498505625 | nexus4_1 | 99 | nexus4 | g | stand | 0.0078125 | -0.017654419 | 0.010025024 | 2015-02-23T10:18:53.498+0000 |
| 1424686735691 | 1424688581745026978 | nexus4_2 | 145 | nexus4 | g | stand | -3.814697E-4 | 0.0184021 | -0.013656616 | 2015-02-23T10:49:41.745+0000 |
| 1424686735890 | 1424688581945252808 | nexus4_2 | 185 | nexus4 | g | stand | -3.814697E-4 | -0.031799316 | -0.00831604 | 2015-02-23T10:49:41.945+0000 |
#event_time 컬럼 추가
withEventTime = streaming.selectExpr('*', "cast(cast(Creation_Time as double)/1000000000 as timestamp) as event_time")텀블링 윈도우

- 위 처럼 비중첩 방식으로 각 윈도우를 처리하는 것을 텀블링 윈도우라고 함
예제
- 트리거가 실행될때마다 마지막 트리거 이후에 수신한 데이터를 처리해서 결과 테이블을 갱신
- 이벤트가 겹치지 않도록 10분 길이의 윈도우를 사용(event_time 기준)
- complete 출력 모드를 사용하여 전체 결과 테이블이 출력
withEventTime.groupBy(F.window(F.col('event_time'),"10 minutes")).count()\
.writeStream.queryName('pyevents_per_window').format('memory').outputMode('complete').start()Out[11]: <pyspark.sql.streaming.StreamingQuery at 0x7fc1f07a4780>spark.streams.activeOut[17]: [<pyspark.sql.streaming.StreamingQuery at 0x7fc1f07c8a20>]spark.sql('select * from pyevents_per_window order by window').show()+--------------------+------+
window| count|
+--------------------+------+
[2015-02-22 00:40...| 35|
[2015-02-23 10:10...| 11515|
[2015-02-23 10:20...| 99178|
[2015-02-23 10:30...|100443|
[2015-02-23 10:40...| 88681|
[2015-02-23 10:50...|160775|
[2015-02-23 11:00...|106232|
[2015-02-23 11:10...| 91382|
[2015-02-23 11:20...| 75181|
[2015-02-23 12:10...| 58984|
[2015-02-23 12:20...|106291|
[2015-02-23 12:30...|100853|
[2015-02-23 12:40...| 97897|
[2015-02-23 12:50...|105160|
[2015-02-23 13:00...|165556|
[2015-02-23 13:10...|162075|
[2015-02-23 13:20...|106075|
[2015-02-23 13:30...| 96480|
[2015-02-23 13:40...|167565|
[2015-02-23 13:50...|193453|
+--------------------+------+
only showing top 20 rowsspark.sql('select * from pyevents_per_window').printSchema()root
-- window: struct (nullable = false)
|-- start: timestamp (nullable = true)
|-- end: timestamp (nullable = true)
-- count: long (nullable = false)- window 컬럼은 struct타입임
- start, end 필드로 특정 윈도우의 시작과 종료 시간을 나타내고 있음
#User 키 추가
withEventTime.groupBy(F.window(F.col('event_time'),'10 minutes'), 'User').count()\
.writeStream.queryName('pyevents_per_window2').format('memory').outputMode('complete').start()Out[33]: <pyspark.sql.streaming.StreamingQuery at 0x7fc1f07b35c0>spark.sql('select * from pyevents_per_window2 order by window,User').show()+--------------------+----+------+
window|User| count|
+--------------------+----+------+
[2015-02-22 00:40...| a| 35|
[2015-02-23 10:10...| g| 11515|
[2015-02-23 10:20...| g| 99178|
[2015-02-23 10:30...| g|100443|
[2015-02-23 10:40...| g| 88681|
[2015-02-23 10:50...| g|160775|
[2015-02-23 11:00...| g|106232|
[2015-02-23 11:10...| g| 91382|
[2015-02-23 11:20...| g| 75181|
[2015-02-23 12:10...| c| 58984|
[2015-02-23 12:20...| c|106291|
[2015-02-23 12:30...| c|100853|
[2015-02-23 12:40...| c| 97897|
[2015-02-23 12:50...| c|105160|
[2015-02-23 13:00...| a| 66049|
[2015-02-23 13:00...| c| 99507|
[2015-02-23 13:10...| a|113530|
[2015-02-23 13:10...| c| 48545|
[2015-02-23 13:20...| a|106075|
[2015-02-23 13:30...| a| 96480|
+--------------------+----+------+
only showing top 20 rows슬라이딩 윈도우
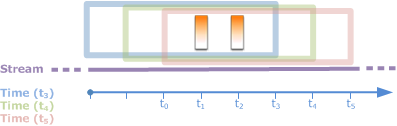
- 지난 시간에 대한 데이터를 유지하면서 연속적으로 값을 갱신함
예제
- 5분마다 시작하는 10분짜리 윈도우 생성
withEventTime.groupBy(F.window(F.col('event_time'),'10 minutes', '5 minutes')).count()\
.writeStream.queryName('events_per_window3').format('memory').outputMode('complete').start()Out[36]: <pyspark.sql.streaming.StreamingQuery at 0x7fc2145bf358>spark.sql('select * from events_per_window3 order by window').show()+--------------------+------+
window| count|
+--------------------+------+
[2015-02-22 00:35...| 35|
[2015-02-22 00:40...| 35|
[2015-02-23 10:10...| 11515|
[2015-02-23 10:15...| 55686|
[2015-02-23 10:20...| 99178|
[2015-02-23 10:25...|101286|
[2015-02-23 10:30...|100443|
[2015-02-23 10:35...| 98969|
[2015-02-23 10:40...| 88681|
[2015-02-23 10:45...|132708|
[2015-02-23 10:50...|160775|
[2015-02-23 10:55...|120218|
[2015-02-23 11:00...|106232|
[2015-02-23 11:05...|101780|
[2015-02-23 11:10...| 91382|
[2015-02-23 11:15...| 92946|
[2015-02-23 11:20...| 75181|
[2015-02-23 11:25...| 29794|
[2015-02-23 12:05...| 14805|
[2015-02-23 12:10...| 58984|
+--------------------+------+
only showing top 20 rowsspark.streams.activeOut[42]: [<pyspark.sql.streaming.StreamingQuery at 0x7fc1f07a4e10>,
<pyspark.sql.streaming.StreamingQuery at 0x7fc1f07a4be0>,
<pyspark.sql.streaming.StreamingQuery at 0x7fc1f07a4f60>]워터마크로 지연 데이터 제어하기
- 위 예제에선 데이터가 필요 없어지는 시간을 지정하지 않았기 때문에 스파크는 중간 결과 데이터를 영원히 저장함
- 따라서 스트림에서 오래된 데이터를 제거하는 데 필요한 워터마크를 반드시 지정해야함
- 이 설정으로 시스템이 긴 시간 동안 부하에 노출되는 현상 방지 가능
- 워터마크
- 특정 시간 이후에 처리에서 제외할 이벤트나 이벤트 집합에 대한 시간 기준
예제
- 각 윈도우의 결과를 만들기 위해 10분 단위 rolling 윈도우의 마지막 타임스탬프 이후 30분까지 대기
withEventTime.withWatermark('event_time','30 minutes')\
.groupBy(F.window(F.col('event_time'), '10 minutes', '5 minutes'))\
.count().writeStream.queryName('pyevents_per_window4').format('memory').outputMode('complete').start()Out[44]: <pyspark.sql.streaming.StreamingQuery at 0x7fc1f0730630>#중간 결과
spark.sql('select * from pyevents_per_window4 order by window').show()+--------------------+------+
window| count|
+--------------------+------+
[2015-02-22 00:35...| 30|
[2015-02-22 00:40...| 30|
[2015-02-23 10:10...| 10082|
[2015-02-23 10:15...| 48775|
[2015-02-23 10:20...| 86822|
[2015-02-23 10:25...| 88541|
[2015-02-23 10:30...| 87831|
[2015-02-23 10:35...| 86645|
[2015-02-23 10:40...| 77644|
[2015-02-23 10:45...|116113|
[2015-02-23 10:50...|140591|
[2015-02-23 10:55...|105186|
[2015-02-23 11:00...| 92997|
[2015-02-23 11:05...| 89074|
[2015-02-23 11:10...| 79909|
[2015-02-23 11:15...| 81313|
[2015-02-23 11:20...| 65837|
[2015-02-23 11:25...| 26066|
[2015-02-23 12:05...| 12899|
[2015-02-23 12:10...| 51598|
+--------------------+------+
only showing top 20 rowsspark.sql('select * from pyevents_per_window4 order by window').show()+--------------------+------+
window| count|
+--------------------+------+
[2015-02-22 00:35...| 35|
[2015-02-22 00:40...| 35|
[2015-02-23 10:10...| 11515|
[2015-02-23 10:15...| 55686|
[2015-02-23 10:20...| 99178|
[2015-02-23 10:25...|101286|
[2015-02-23 10:30...|100443|
[2015-02-23 10:35...| 98969|
[2015-02-23 10:40...| 88681|
[2015-02-23 10:45...|132708|
[2015-02-23 10:50...|160775|
[2015-02-23 10:55...|120218|
[2015-02-23 11:00...|106232|
[2015-02-23 11:05...|101780|
[2015-02-23 11:10...| 91382|
[2015-02-23 11:15...| 92946|
[2015-02-23 11:20...| 75181|
[2015-02-23 11:25...| 29794|
[2015-02-23 12:05...| 14805|
[2015-02-23 12:10...| 58984|
+--------------------+------+
only showing top 20 rows- 이때 append모드를 하면 윈도우 종료 전까지 결과를 확인할 수 없으니 complete모드를 사용해서 중간 결과를 확인하자
스트림에서 중복 데이터 제거하기
- 스트림에서 중복을 제거하는 것은 레코드 단위 처리 시스템에서 가장 처리하기 어려운 연산 중 하나
- 중복을 찾기 위해 여러 레코드를 반드시 한 번에 처리해야함
- 한 번에 많은 레코드를 처리해야 하므로 중복 제거는 처리 시스템에 큰 부하를 발생시킴
- 구조적 스트리밍은 최소 한 번(at least-once) 처리하는 방식을 제공하는 메시지 시스템을 쉽게 사용 가능
- 처리시에 키를 기준으로 중복을 제거해서 정확히 한 번 처리(?)
- 중복 제거를 위해 사용자가 지정한 키를 유지하면서 중복 여부를 확인함(?)
- 주의: 워터마크를 명시해서 상태 정보가 무한히 커지지 않도록 해야함
예제
- 목적: 사용자(User)별 이벤트 수 줄이기
- 중복을 제거해야 하는 컬럼과 함께 이벤트 시간 컬럼을 중복 컬럼으로 명시해야함
- ['User', 'event_time']
withEventTime.withWatermark('event_time', '5 seconds')\
.dropDuplicates(['User', 'event_time'])\
.groupBy('User').count().writeStream\
.queryName('pydeduplicated')\
.format("memory")\
.outputMode("complete")\
.start()Out[7]: <pyspark.sql.streaming.StreamingQuery at 0x7f2233c86358>spark.sql("select * from pydeduplicated").collect()Out[10]: [Row(User='a', count=80854),
Row(User='b', count=91239),
Row(User='c', count=77155),
Row(User='g', count=91673),
Row(User='h', count=77326),
Row(User='e', count=96022),
Row(User='f', count=92056),
Row(User='d', count=81245),
Row(User='i', count=92553)]spark.sql("select * from pydeduplicated").collect()Out[17]: [Row(User='a', count=80854),
Row(User='b', count=91239),
Row(User='c', count=77155),
Row(User='g', count=91673),
Row(User='h', count=77326),
Row(User='e', count=96286),
Row(User='f', count=92056),
Row(User='d', count=81245),
Row(User='i', count=92553)]임의적인 상태 기반 처리

- 2.2버전에는 스칼라로만 상태 기반 처리 가능(지금도 없는 것 같음)
- 임의적인 상태 기반 처리를 사용하면 어떤 처리를 할 수 있나?
- 특정 키의 개수를 기반으로 윈도우 생성
- 특정 시간 범위 안에 일정 개수 이상의 이벤트가 있는 경우 알림 발생
- 결정되지 않은 시간 동안 사용자 세션을 유지하고 향후 분석을 위해 세션 저장
- 임의적인 상태 기반 처리를 수행하면 결과적으로 두 가지 처리 유형을 만남
- 데이터의 각 그룹에 맵 연산을 수행하고 각 그룹에서 최대 한 개의 로우를 만듦 -> mapGroupsWithState API 이용
- 데이터의 각 그룹에 맵 연산을 수행하고 각 그룹에서 하나 이상의 로우를 만듦 -> flatMapGroupsWithState API 이용
- doc
- 데이터의 각 그룹에 연산을 수행하면 각 그룹을 임의로 갱신 가능
- 즉, 이전의 윈도우와 다른 임의의 윈도우 유형을 정의할 수 있다는 의미
- 타임아웃 설정도 가능
- 임의적인 상태 기반 처리는 사용자가 상태를 일일이 다 관리해야함
- ex) 윈도우 시작 시간이 워터마크보다 작아질 때 윈도우를 제거해야하는 것 명시
타임아웃
- 타임아웃은 중간 상태를 제거하기 전에 기다려야하는 시간 정의함
- 각 키별로 그룹이 존재한다면, 타임아웃은 전체 그룹에 대한 전역 파라미터로 동작함
- 처리 시간 기반의 타임아웃은 시스템 시간의 변화에 영향을 받으니 시간대 변경과 시간 지연을 잘 고려해야함
출력모드
- 사용자 정의 상태 기반 처리에서는 모든 출력 모드를 지원하지 않음
- 3.1 버전 기준으로
- mapGroupsWithState: update
- flatMapGroupsWithState: append, update
mapGroupsWithState
- 갱신된 데이터셋을 입력으로 받고 값을 특정 키로 분배하는 사용자 정의 집계 함수와 유사
- 정의해야하는 것
- 입력 클래스 / 상태 클래스 / 출력 클래스(선택)
case class InputRow(user:String, timestamp:java.sql.Timestamp, activity:String) case class UserState(user:String, var activity:String, var start:java.sql.Timestamp, var end:java.sql.Timestamp)
- 키, 이벤트 이터레이터, 이전 상태를 기반으로 상태를 갱신하는 함수
//업뎃 함수 정의 def updateUserStateWithEvent(state:UserState, input:InputRow):UserState = { // no timestamp, just ignore it if (Option(input.timestamp).isEmpty) { return state } //does the activity match for the input row if (state.activity == input.activity) { if (input.timestamp.after(state.end)) { state.end = input.timestamp } if (input.timestamp.before(state.start)) { state.start = input.timestamp } } else { //some other activity if (input.timestamp.after(state.end)) { state.start = input.timestamp state.end = input.timestamp state.activity = input.activity } } //return the updated state state } - 타임아웃 파라미터
import org.apache.spark.sql.streaming.GroupStateTimeout withEventTime .selectExpr("User as user", "cast(Creation_Time/1000000000 as timestamp) as timestamp", "gt as activity") .as[InputRow] // group the state by user key .groupByKey(_.user) .mapGroupsWithState(GroupStateTimeout.NoTimeout)(updateAcrossEvents) .writeStream .queryName("events_per_window") .format("memory") .outputMode("update") .start()
- 입력 클래스 / 상태 클래스 / 출력 클래스(선택)
flatMapGroupsWithState
- 단일 키의 출력 결과가 여러 개 만들어짐
- mapGroupsWithState에 적용된 기본 구조를 가지며 더 나은 유연성 제공
- 정의해야하는 것
- 입력 클래스 / 상태 클래스 / 출력 클래스(선택)
- 키, 이벤트 이터레이터, 이전 상태를 기반으로 상태를 갱신하는 함수
- 타임아웃 파라미터

Data Engineer