1. 개념
1.1. 개요
언어 모델(Language Model)은 문장이 얼마나 자연스러운지 확률적으로 계산함으로써 문장 내 특정 위치에 출현하기 적합한 단어를 확률적으로 예측하는 모델입니다. 더욱 쉽게 설명하자면, 언어 모델은 문장 내 앞서 등장한 단어를 기반으로 뒤에 어떤 단어가 등장해야 문장이 자연스러운지 판단하는 도구입니다.
언어 모델은 크게 통계학적 언어 모델과 인공신경망 기반의 언어 모델이 있습니다. 최근에는 BERT, GPT-3와 같은 인공신경망 기반의 언어 모델의 성능이 뛰어나 대부분의 자연어처리 문제에서는 인공신경망 기반의 언어 모델을 사용합니다. 본 포스팅에서는 통계학 기반의 언어 모델에 대해 다루고, 향후에 인공신경망 기반의 언어 모델에 대해 다룹니다.
1.2. 예시
예시를 통해 언어 모델의 개념에 대해 더욱 쉽게 알아봅니다.
"비행기를 타기 위해 공항을 가는데 차가 너무 막혀서 결국 비행기를 ???"
사람은 이 문장에서 '비행기를' 단어 뒤에 이어질 물음표(???)에 들어갈 단어로 '놓쳤다'를 쉽게 예측할 수 있습니다. 왜냐하면 우리는 수많은 단어와 문장을 듣고 쓰고 말하며 언어능력을 학습해왔기 때문에, 확률적으로 '놓쳤다'라는 단어가 가장 적합하다고 판단할 수 있는 것이죠.
마찬가지로, 해당 문장을 기계(=언어 모델)에게 보여주고 물음표에 올 적합한 단어를 예측하라고 하면 어떻게 될까요? 기계 역시 사람과 같은 프로세스로 동작합니다. 먼저, 언어 모델은 텍스트 기반의 수많은 문장을 통해 어떤 단어가 어떤 어순으로 쓰인 것이 가장 자연스러운 문장인지 학습합니다. 이를 통해 언어 모델은 문장이 주어졌을 때 앞뒤에 주어진(=어순) 단어 조합을 기반으로 가장 높은 확률로 등장할 만한 단어를 출력해 주는 것이죠.
2. 확률적 표현
확률적 표현을 통해 언어 모델의 개념에 대해 더욱 자세히 알아봅니다. 먼저, 단어 여러 개가 주어졌을 때 뒤이어 등장할 단어를 확률적으로 표현하는 방법을 다루고, 이어서 문장 자체를 확률적으로 표현하는 방법을 알아봅니다.
2.1. 단어 예측의 확률적 표현
총 n개의 단어로 구성된 문장에서, (n-1)개의 단어가 주어졌을 때, n번째 위치에 출현할 단어의 예측을 확률적으로 표현하면 다음과 같습니다.
여기서 P는 확률(Probability)을, |는 조건부 확률(Conditional Probability)을, w는 하나의 단어(Word)를 의미합니다.
2.2. 문장 자체의 확률적 표현
수학에서 시퀀스(Sequence)는 순서를 고려하여 나열된 여러 객체들의 묵음을 의미한다는 점에서, 문장은 어순을 고려하여 여러 단어로 이루어진 단어 시퀀스(Word Sequence)라고도 부릅니다. n개의 단어로 구성된 단어 시퀀스(W)를 확률적으로 표현하면 다음과 같습니다.
단어 시퀀스 자체의 확률은 모든 단어 (w_1, w_2, w_3, ...., w_n)의 예측이 완료되었을 때, 즉 문장이 완성되었을 때 알 수 있습니다. 즉, 첫 번째 단어가 주어졌을 때 2번째 단어가 등장할 확률, 2번쨰 단어까지 주어졌을 때 3번째 등장할 단어의 확률, ..., (n-1)번째 단어까지 주어졌을 때 n번째 단어가 등장할 확률을 모두 곱한 것이 단어 시퀀스 자체의 확률입니다. 따라서 단어 시퀀스를 확률적으로 표현하면 다음과 같습니다.
위 식을 곱연산(product operator)을 활용해 표현하면 다음과 같습니다.
3. 활용분야
언어 모델의 활용 분야는 무궁무진합니다. 예를 들어, 기계 번역(Machine Translation), 오타 교정(Spell Correction), 음성인식(Speech Recognition), 검색어 추천(Keyword Search Recommendation) 등에 활용되고 있습니다. 간단한 사례와 함께 몇 가지 활용 예시를 알아봅니다.
3.1. 기계 번역(Machine Translation)
아래와 같이 번역기를 돌린 2가지 문장이 있다고 가정했을 때, 좌측 문장이 우측 문장보다는 자연스러운 문장이죠. 즉, 언어 모델은 좌측 문장이 우측 문장보다 높은 확률을 갖는다고 판단합니다.
P("나는 지하철을 탔다") > P("나는 지하철을 태웠다")
3.2. 오타 교정(Spell Correction)
키보드 자판의 위치로 인해 아래와 같이 '알아갔다'를 '랄아갔다'로 오타가 발생할 수 있죠. 문장을 보면 오타가 발생한 우측 문장보다는 좌측 문장이 자연스러운 문장임을 알 수 있죠. 즉, 언어 모델은 좌측 문장의 확률이 우측 문장보다 높다고 판단합니다.
P("자연어처리 방법론을 알아갔다") > P("자연어처리 방법론을 랄아갔다")
3.3. 음성 인식(Speech Recognition)
"신라"는 소리 내어 발음하면 "실라"입니다. 언어 모델은 이처럼 실제 텍스트와 발음 간의 차이를 교정해 주는 데 활용할 수 있습니다.
P("신라의 달밤") > P("실라의 달밤")
3.4. 검색어 추천(Keyword Search Recommendation)
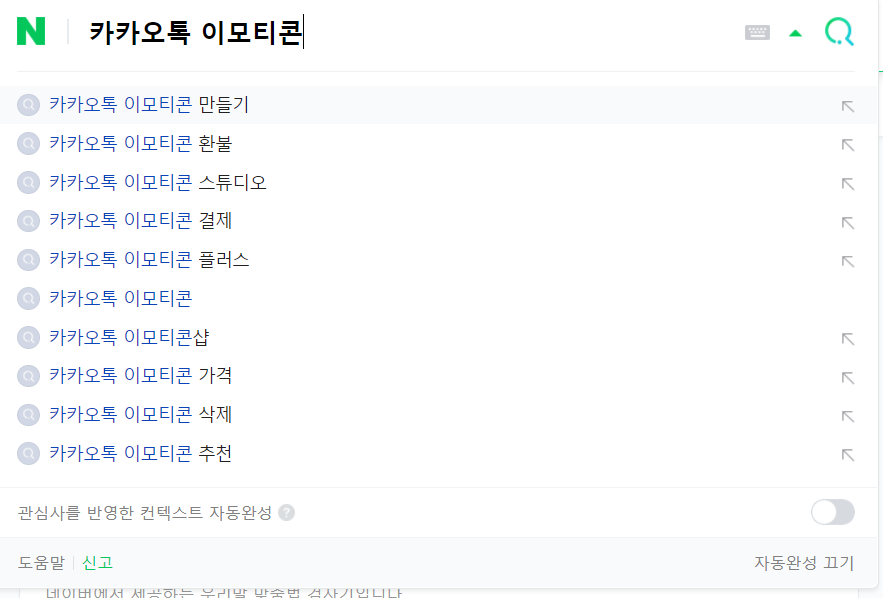
검색어 추천 예시(네이버)
네이버나 구글 검색 시 위와 같이 자동완성 기능을 한 번쯤은 꼭 보셨을 겁니다. 이 역시 언어 모델을 통해 사용자가 입력한 단어를 기반으로 뒤이어 입력할 만한 단어를 추천해 줄 수 있습니다.
참고
