IoC
- Inversion Of Control의 약자로 해석하면 '제어의 역전' 입니다.
해석 그대로 제어권이 개발자가 아닌 프레임워크에게 역전되었다고 볼 수 있습니다.
예를 들어, 스프링 프레임워크를 사용하여 개발을 할 때 개발자는 직접 클래스를 new Class()와 같이 생성하지 않습니다. Controller와 Service와 같은 객체들의 동작은 개발자가 직접 구현하지만, 해당 객체들의 호출 시점은 신경 쓰지 않습니다.
바로, 프레임워크가 객체의 생성, 호출, 소멸 등의 생명주기를 관리
하기 때문입니다.
라이브러리와 비교
개발자는 필요한 시점에 외부 라이브러리의 객체를 가져다 씁니다. 이와 유사하게 프레임워크는 애플리케이션 코드에 작성한 객체를 가져다가 프로그램을 구동합니다.
IoC는 스프링 뿐만 아니라 여러 프레임워크에서 범용적으로 사용하는 개념입니다.
그렇다면 왜 사용하는 것일까요?
이렇게 프레임워크가 객체의 생명주기를 관리해 주면 개발자는 비지니스 로직에만 집중할 수 있습니다.
DI
- Dependency Injection의 약자로 해석하면 '의존성 주입' 입니다.
DI는 IoC를 구현하기 위해 사용되는 디자인 패턴 중 하나입니다.
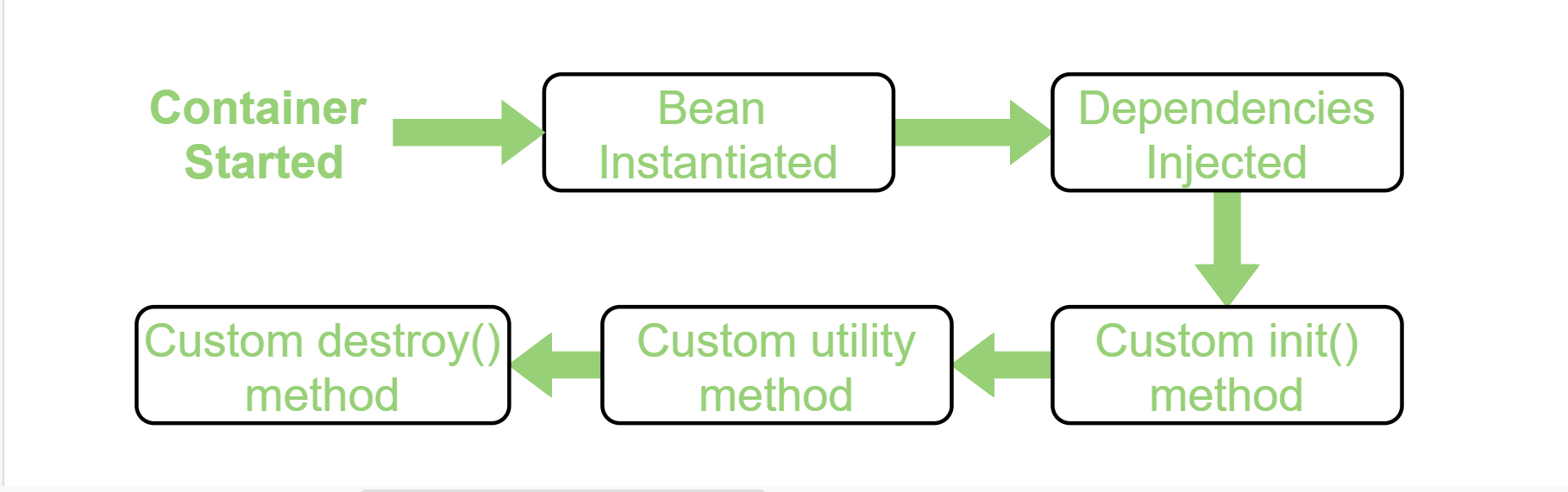
- Bean LifeCycle (생명주기)
https://media.geeksforgeeks.org/wp-content/uploads/20200428011831/Bean-Life-Cycle-Process-flow3.png
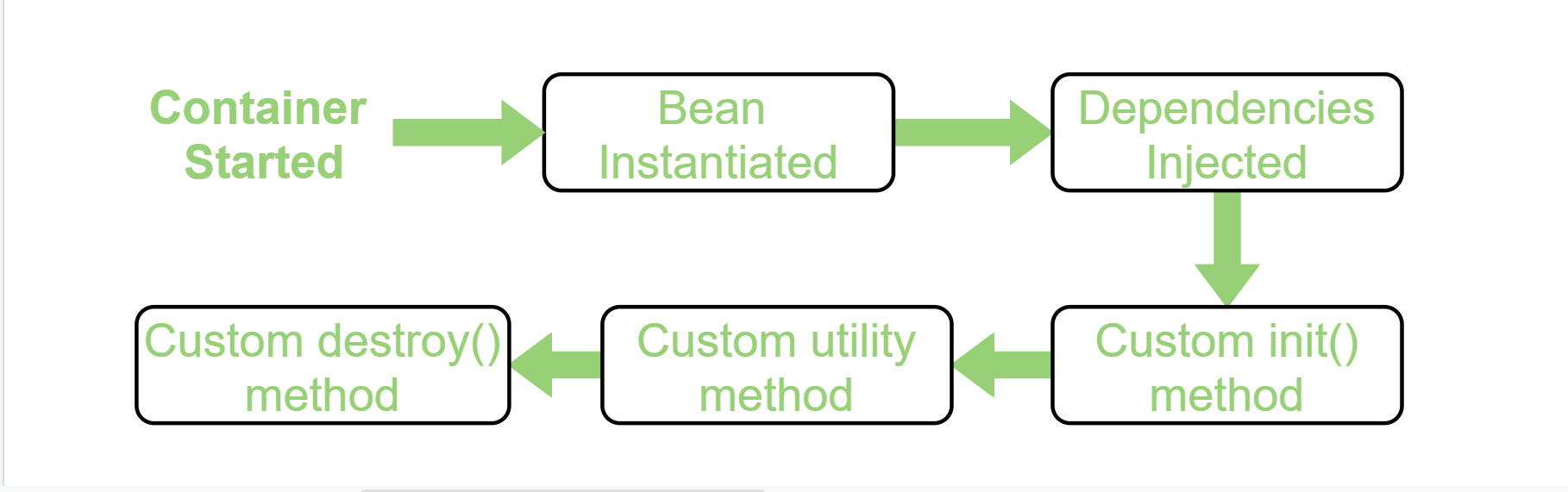
IoC를 설명하면서 프레임워크가 객체의 생명주기를 관리한다고 했는데요, 스프링 프레임워크에서 관리하는 객체를 Bean이라고 합니다.
Bean 생명주기를 보면 Bean생성 이후에 의존 관계를 주입하는 것을 알 수 있습니다.
의존 관계
'A가 B를 사용한다' = 'A가 B를 의존한다'
의존대상인 B가 변하면 A에게 영향을 미치게 되는데요, 이러한 관계를 의존 관계라고 합니다.
의존 관계 추상화
의존 관계를 인터페이스로 추상화함으로서 다양한 의존 관계를 쉽게 변경할 수 있습니다.
- 예시
public class Pay {
private Discount discount;
public Pay() {
discount = new DiscountByCache();
}
}
public interface Discount {
void discountByType();
}
public class DiscountByCache implements Discount {
@Override
public void discountByType() {
// 현금 할인 코드
}
public DiscountByCache() {}
}
위 코드를 보면 Pay는 Discount를 의존하고 있습니다.
현재 Discount의 구현체인 현금할인을 사용하고 있는데요,
만약 포인트 할인을 사용하고 싶다면 어떻게 하면 될까요?
public class Pay {
private Discount discount;
public Pay() {
discount = new DiscountByPoint();
}
}
public class DiscountByPoint implements Discount {
@Override
public void discountByType() {
// 포인트 할인 코드
}
public DiscountByPoint(){}
}실제로 Pay 클래스에서는 한 줄만 변경하면 됩니다.
의존성을 주입할 때 구현체만 변경해주면 Pay 클래스에서 나머지 코드들은 변경할 필요가 없습니다.
인터페이스가 아닌 클래스를 사용했다면 의존 객체에 따라 많은 코드를 수정해야 할 수 있습니다.
따라서 인터페이스로 의존관계를 추상화하고 필요한 구현체를 주입받아 의존 대상의 변화에 영향을 덜 받도록 해줍니다.
Spring DI
앞서 살펴본 코드는 개발자가 생성자를 통해 new()로 객체를 생성하여 의존성을 주입하고 있습니다.
따라서 구현체를 변경하고 싶을 때마다 해당 클래스에 직접
수정해 주어야 합니다.
이제 Spring Framework를 사용하여 의존성을 주입받는 방법에 대해 알아보겠습니다.
스프링에서 의존성을 주입하는 방법에는 3가지가 있습니다.
바로 생성자 주입, 메서드 주입, 필드 주입입니다.
Bean
스프링으로부터 생성 주기를 관리받기 위해서는 해당 객체가 Bean으로 등록이 되어있어야 합니다.
Bean 등록 방법은 크게 설정 파일에서 등록하는 방법과 @Component 애너테이션을 사용하는 방법이 있습니다.
다음 예시에서는 간편하게 @Component를 사용하여 Bean으로 등록해주겠습니다.
테스트 기본 설정
테스트하기 위해서 먼저 설정 파일을 생성해 주겠습니다.
@ComponentScan(basePackages = "com.example.chat.dependency")
@Configuration
public class Config {
}위의 설정 파일을 통해 스프링이 Bean으로 등록하기 위해 스캔할 패키지를 명시해 주었습니다.
public static void main(String[] args) {
ApplicationContext applicationContext = new AnnotationConfigApplicationContext(Config.class);
Pay pay = applicationContext.getBean("pay", Pay.class);
System.out.println("=====================");
pay.test();
}좀 전에 작성한 Config.class 정보를 가지고 스프링 컨텍스트를 구성하고,
getBean() 메서드를 사용하여 Pay 인스턴스를 가져오겠습니다.
@Component
public class Pay {
private Discount discount;
public Pay() {
discount = new DiscountByPoint();
}
// 테스트를 위한 메서드 추가
public void test() {
discount.discountByType();
}
}Pay 클래스에 @Component 애너테이션을 추가하여 Bean으로 등록할 수 있도록 하고, 테스트를 위한 test() 메서드를 추가하였습니다.
해당 메서드는 단순히 의존성 주입이 정상적으로 이루어졌는지 알아보기 위해 의존 객체의 discountByType() 메서드를 호출하도록 하였습니다.
@Component
public class DiscountByPoint implements Discount {
@Override
public void discountByType() {
// 포인트 할인 코드
System.out.println("포인트 할인 성공");
}
}각 구현체 또한 @Component 애너테이션을 사용하여 Bean으로 등록하고 discountByType() 메서드에 간단한 메시지를 출력하는 코드를 추가하였습니다.
이제 @Autowired 애너테이션을 사용하여 의존성을 주입받아 보겠습니다.
1. 생성자 주입
@Autowired
public Pay(Discount discount) {
this.discount = discount;
}Pay 생성자에 @Autowired를 붙이게 되면 스프링이 인자에 해당하는 Bean을 찾아서 의존성을 주입해 줍니다.
public Pay() {
discount = new DiscountByPoint();
}기존 코드를 보면 우리가 직접 new로 의존 객체를 생성하여 주입해 주었습니다.
하지만 지금은 생성자와 필요한 의존 객체를 파라미터로 적절히 작성해주면 스프링 프레임워크가 의존성을 주입해 줍니다.
적절히 작성이 무슨 말일까요?
실제로 main() 을 실행시키면 다음과 같은 에러가 발생합니다.
Caused by: org.springframework.beans.factory.NoUniqueBeanDefinitionException: No qualifying bean of type 'com.example.chat.dependency.Discount' available: expected single matching bean but found 2: discountByCache,discountByPoint스프링이 생성자를 통해 의존성을 주입할 때 Discount에 해당하는 의존 객체를 Bean 저장소에서 찾을 때 해당하는 대상이 두 가지 존재합니다.
따라서 두 가지 중 어느 객체를 주입해야 할 지 모르기 때문에 에러가 발생합니다.
@Autowired
public Pay(Discount discountByCache) {
this.discount = discountByCache;
}위와 같이 파라미터명을 원하는 의존 대상이 되는 Bean 이름과 동일 하게 작성하면 해당 Bean을 사용하여 의존성을 주입합니다.
( 기본적으로 따로 이름을 지정하지 않으면 Bean으로 등록하는 클래스(또는 메서드)이름에서 맨 앞자리를 소문자로 변경한 것이 Bean 이름이 됩니다. )
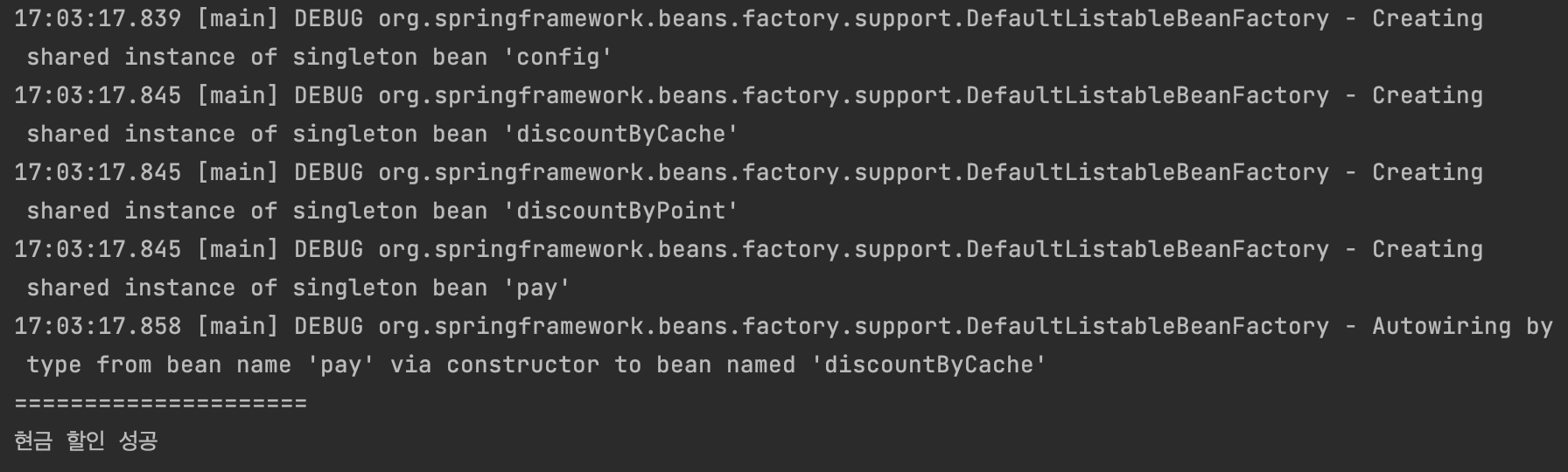
정상적으로 의존성이 주입된 것을 확인할 수 있습니다.
2. 메서드 주입
메서드 주입은 주로 setter를 말합니다.
아래와 같이 setter를 사용하여 의존성을 주입합니다.
@Autowired
public void setDiscount(Discount discountByCache) {
this.discount = discountByCache;
}
3. 필드 주입
말그대로 필드에 @Autowired 애너테이션을 사용하여 의존성을 주입합니다.
@Autowired
private Discount discountByCache;
필드 주입은 제일 간단한 방법이지만 권장되지 않는 방법입니다.
필드 주입을 사용하면 사용자가 직접 객체를 생성해서 주입할 방법이 없습니다. 이렇게 되면 테스트 시 DI 컨테이너가 없다면 정상적으로 동작하지 않습니다. 즉 테스트가 DI컨테이너에 대해 의존하게 됩니다.
class PayTest {
private Pay pay;
class DiscountImpl implements Discount {
@Override
public void discountByType() {
System.out.println("테스트 할인");
}
}
@Test
void test1() {
pay = new Pay(new DiscountImpl());
pay.test();
}
}생성자 주입을 사용하면 이처럼 DI 컨테이너를 사용하지 않고 사용자가 직접 의존 객체를 주입하여 테스트를 진행할 수 있습니다.
단위 테스트는 의존 대상에 의존하지 않고 테스트하는 메서드가 본인 역할을 제대로 수행하는지 확인해야 합니다.
위와 같이 구현체를 임의로 생성하여 의존성을 주입해줄 수도 있습니다.
class PayTest {
private Pay pay;
@Test
void test1() {
pay = new Pay();
pay.test();
}
}필드 주입을 사용한다면 사용자가 직접 의존 객체를 주입할 수 없어 NullPointerException이 발생합니다.

순환참조와 생성자 주입
BeanA와 BeanB가 서로 의존하고 있다고 가정하겠습니다.
// BeanA.class
@Component
public class BeanA {
private BeanB beanB;
@Autowired
public BeanA(BeanB beanB) {
this.beanB = beanB;
}
public void test() {
System.out.println(beanB);
}
}
// BeanB.class
@Component
public class BeanB {
private BeanA beanA;
@Autowired
public BeanB(BeanA beanA) {
this.beanA = beanA;
}
}
// main
public static void main(String[] args) {
ApplicationContext applicationContext = new AnnotationConfigApplicationContext(Config.class);
BeanA beanA = applicationContext.getBean("beanA", BeanA.class);
beanA.test();
}생성자 주입을 사용하면 빈을 생성할 때 순환 참조 문제가 발생하여 에러가 발생합니다.
애플리케이션을 구동하고 스프링 컨텍스트를 구성할 때 Bean을 생성하는데요, 이때 생성자 주입의 경우 생성할 때 의존성을 주입하게 됩니다. 즉 BeanA를 생성하기 위해서는 BeanB가 필요하고 BeanB를 생성하기 위해서는 BeanA가 필요하게 됩니다. 이때 순환 참조 문제가 발생하여 에러가 발생하는 것입니다.

// BeanA.class
@Component
public class BeanA {
@Autowired
private BeanB beanB;
public void test() {
System.out.println(beanB);
}
}
// BeanB.class
@Component
public class BeanB {
@Autowired
private BeanA beanA;
}
위와 같이 필드(또는 메서드) 주입으로 변경하면 main에서의 beanA.test()가 정상적으로 실행됩니다.
왜냐하면 필드 주입에서는 객체 생성 시에 의존성이 주입되지 않습니다. 메서드 주입도 동일합니다.
실제로 의존 객체가 필요할 때 의존성을 주입하기때문에 BeanA를 생성하고 BeanB를 생성하고 의존성이 필요할때 BeanA에서 BeanB를 주입받습니다. 따라서 위의 코드에서 순환 참조 에러가 발생하지 않습니다.
// BeanA.class
@Component
public class BeanA {
@Autowired
private BeanB beanB;
public void test() {
System.out.println(beanB);
}
// 추가
public void testA() {
beanB.testB();
}
}
// BeanB.class
@Component
public class BeanB {
@Autowired
private BeanA beanA;
public void testB() {
beanA.testA();
}
}
// main
public static void main(String[] args) {
ApplicationContext applicationContext = new AnnotationConfigApplicationContext(Config.class);
BeanA beanA = applicationContext.getBean("beanA", BeanA.class);
beanA.test(); // 성공
beanA.testA(); // 실패
}위와 같이 몇 가지의 코드를 추가하였습니다. BeanA의 testA() 메서드 에서는 BeanB의 testB()를 호출하고, BeanB의 testB()는 BeanA의 testA()를 호출하고 있습니다.
이를 실행하면 beanA.test()는 정상적으로 수행되지만 beanA.testA()는 아래와 같은 에러가 발생합니다.
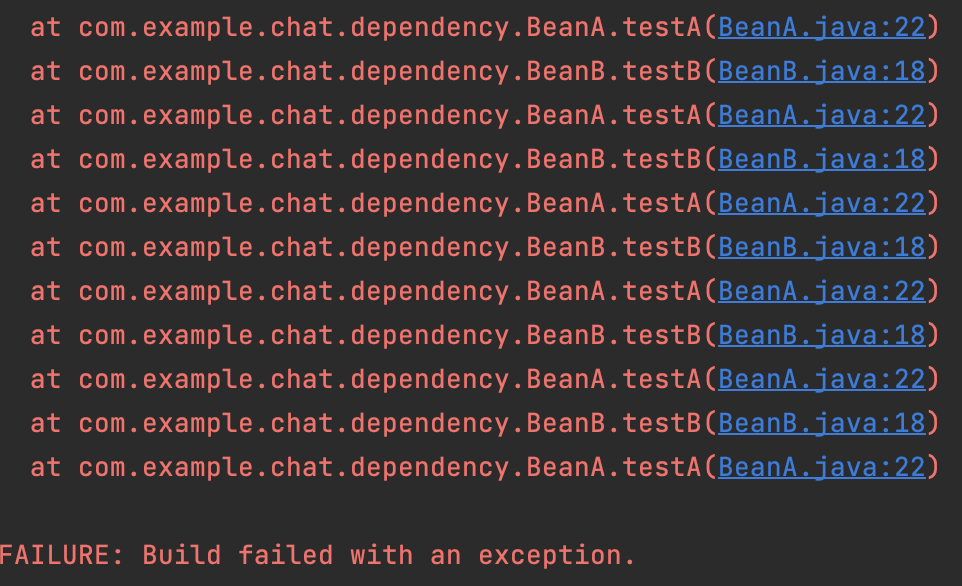
필드주입 또는 메서드 주입에서는 의존객체가 필요할 때 의존성을 주입하기 때문에 Bean 생성시에는 순환참조가 발생하지 않습니다. testA() -> testB() -> testA() 와 같이 순환참조 메서드가 발생할 실제로 호출될 때 에러가 발생하게 됩니다.
정리하자면, 메서드 주입과 필드 주입은 생성자 주입에 비해 여러 단점이 존재하므로 주로 생성자 주입을 사용하여 의존성을 주입하고 있습니다.
또한 Lombok의 @RequiredArgsConstructor 애너테이션을 사용하면 생성자를 직접 구현하지 않아도 final 필드와 @NonNull 필드를 인자로 가지는 생성자를 자동으로 만들어 줌으로써 간편하게 사용할 수 있습니다.
참고문헌
https://yaboong.github.io/spring/2019/08/29/why-field-injection-is-bad/
https://marrrang.tistory.com/58
https://yaboong.github.io/spring/2019/08/29/why-field-injection-is-bad/

{kind=link}