Gemini for Data Scientists and Analysts : Gemini for Data Scientists
Google Cloud Skills Boost

이번 실습은 Big Query를 생성하고 산점도를 생성하는 부분인데, 큰 오류가 있어서 완료하지 못 했다.
추후 답변이 오면 완성할 예정이다.
1. 환경 및 계정 구성하기
Cloud Shell 접속 후에 환경 및 계정을 구성한다.
# 프로젝트 ID, Region 설정하기
PROJECT_ID=$(gcloud config get-value project)
REGION=Region
echo "PROJECT_ID=${PROJECT_ID}"
echo "REGION=${REGION}"
# Google 계정 접속하기
USER=$(gcloud config get-value account 2> /dev/null)
echo "USER=${USER}"
# Gemini를 위한 Cloud AI Companion API 허용하기
gcloud services enable cloudaicompanion.googleapis.com --project ${PROJECT_ID}
# 필요한 IAM 룰 설정하기
gcloud projects add-iam-policy-binding ${PROJECT_ID} --member user:${USER} --role=roles/cloudaicompanion.user
gcloud projects add-iam-policy-binding ${PROJECT_ID} --member user:${USER} --role=roles/serviceusage.serviceUsageViewer
gcloud projects add-iam-policy-binding ${PROJECT_ID} --member user:${USER} --role=roles/aiplatform.notebookRuntimeUser
gcloud projects add-iam-policy-binding ${PROJECT_ID} --member user:${USER} --role=roles/dataform.codeEditor
# RuntimeUser, Dataform Code Editor 노트북 추가하기
CLOUD_BUILD_SERVICE_ACCOUNT="${PROJECT_ID}@${PROJECT_ID}.iam.gserviceaccount.com"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:$CLOUD_BUILD_SERVICE_ACCOUNT \
--role roles/aiplatform.notebookRuntimeUser
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:$CLOUD_BUILD_SERVICE_ACCOUNT \
--role roles/dataform.codeEditor
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:$CLOUD_BUILD_SERVICE_ACCOUNT \
--role roles/compute.admin2. Project Big Query 생성하기
네비게이션 메뉴 -> BigQuery 선택
Create data set 클릭 후 정보 입력해서 생성

3. Python notebook 생성 및 API 설정
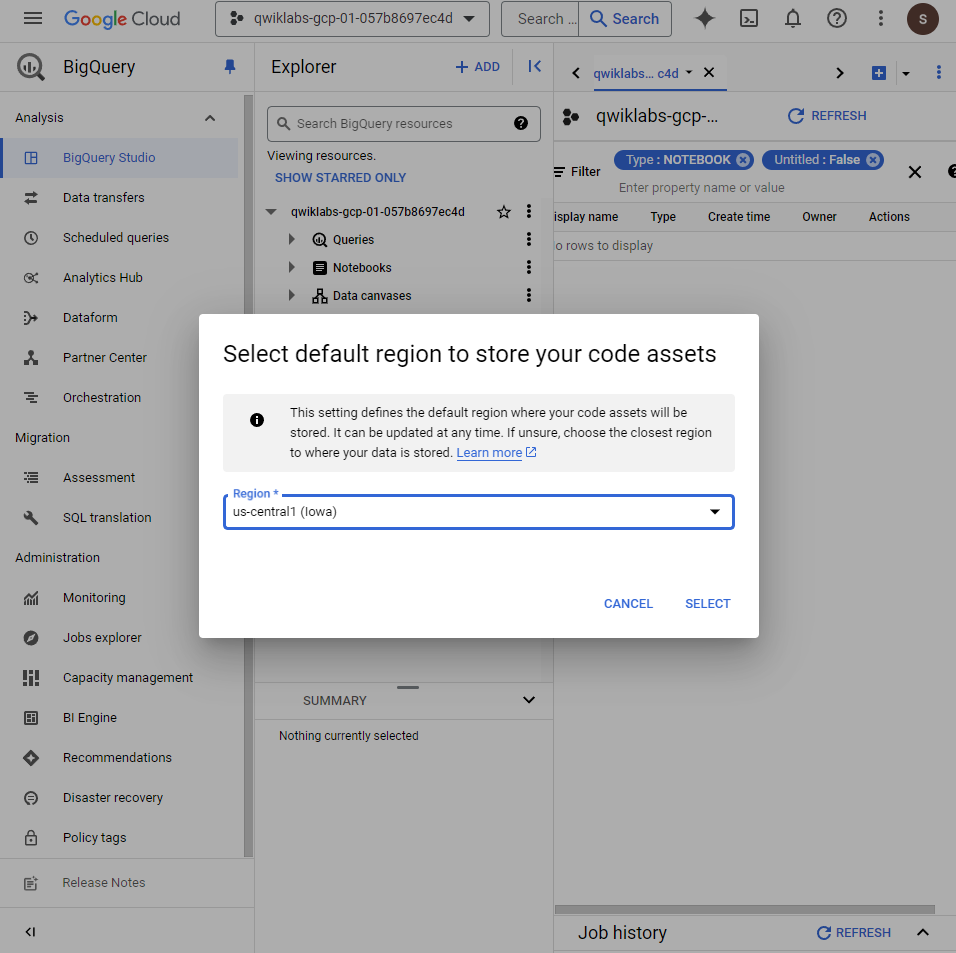
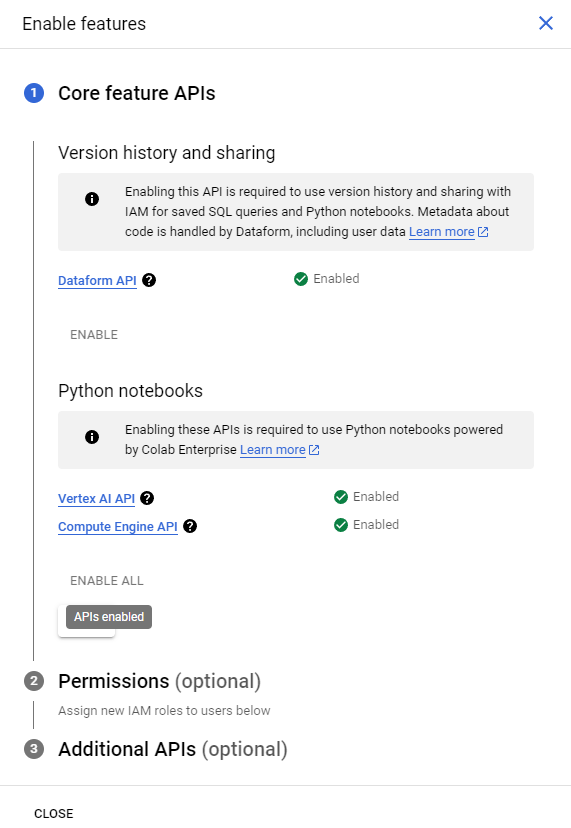
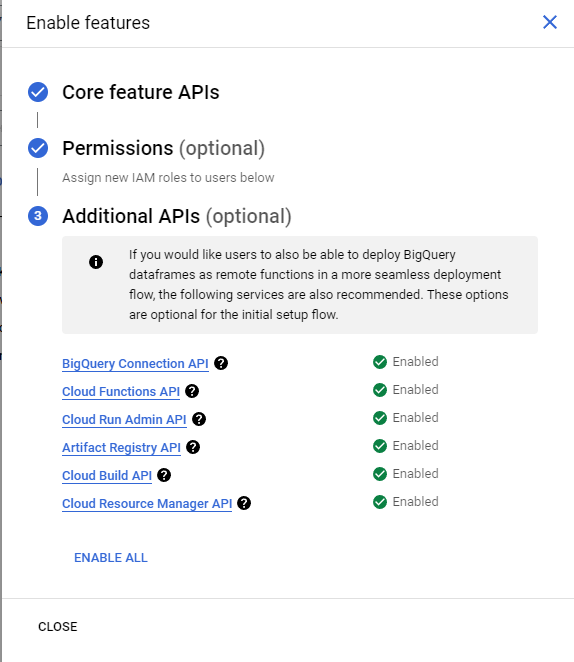
BigQuery -> 플러스 옆 드롭 다운 -> Python Notebook 클릭 후 Region 설정 해주고 모든 API를 ENABLE 설정해준다.
플러스 옆 드롭다운이라해서 좀 헤맸음.
4. Runtime in BigQuery 연결
Notebook에서 연결 ->런타임에 연결을 클릭해준다.
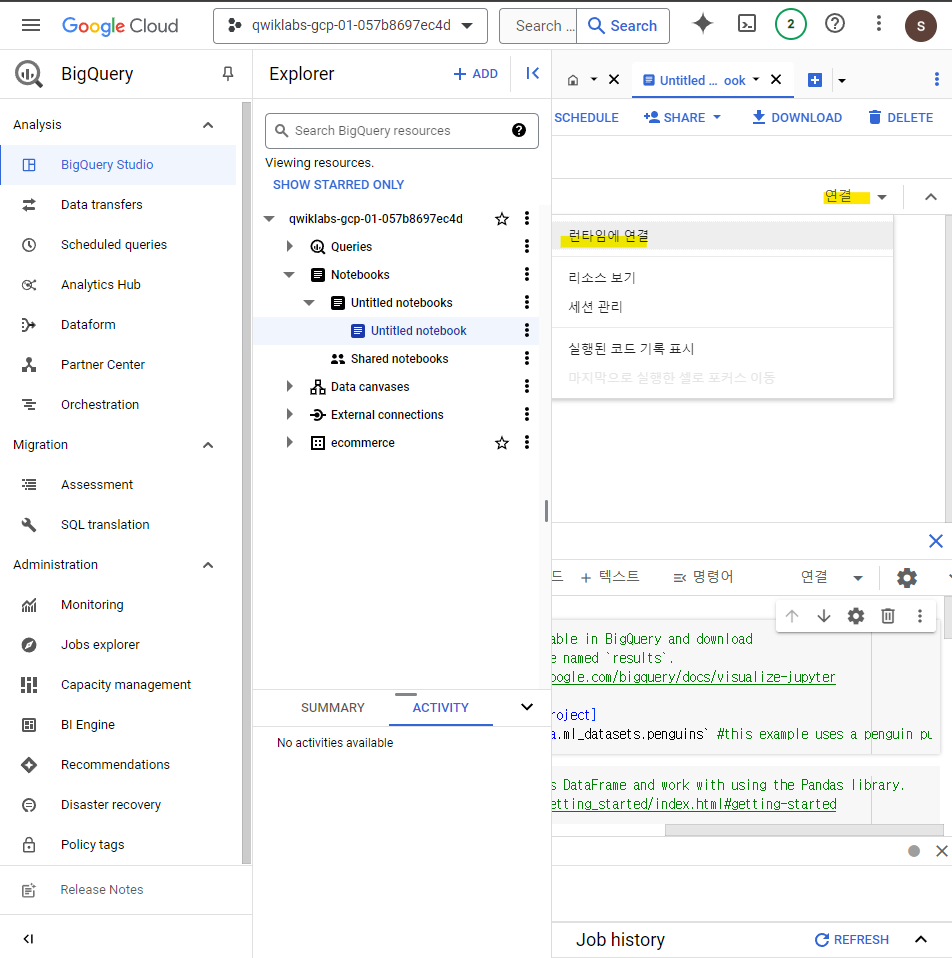
새로운 런타임을 생성해준다.
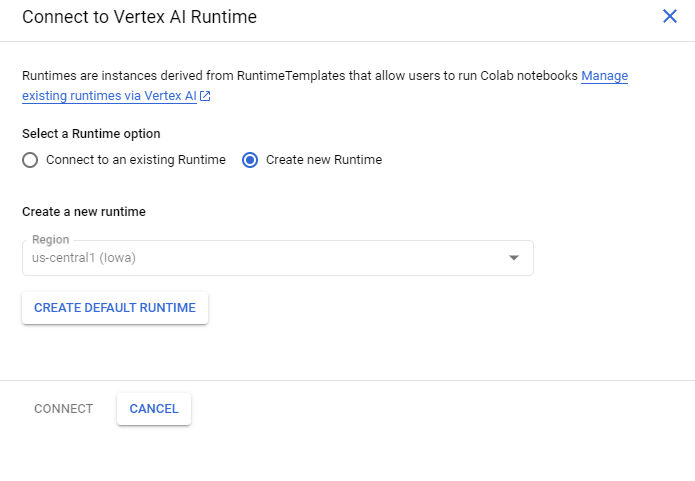
기다리면 런타임이 연결된 걸 확인할 수 있다.
5. Python Notebook 빌드하기
- Python library import
- 변수 정의하기
- BigQuery DataFrame으로 기본 테이블 생성하고 public dataset import
- K-means clustering model 생성하고 시각화하기
5-1. 현재 페이지 새로고침
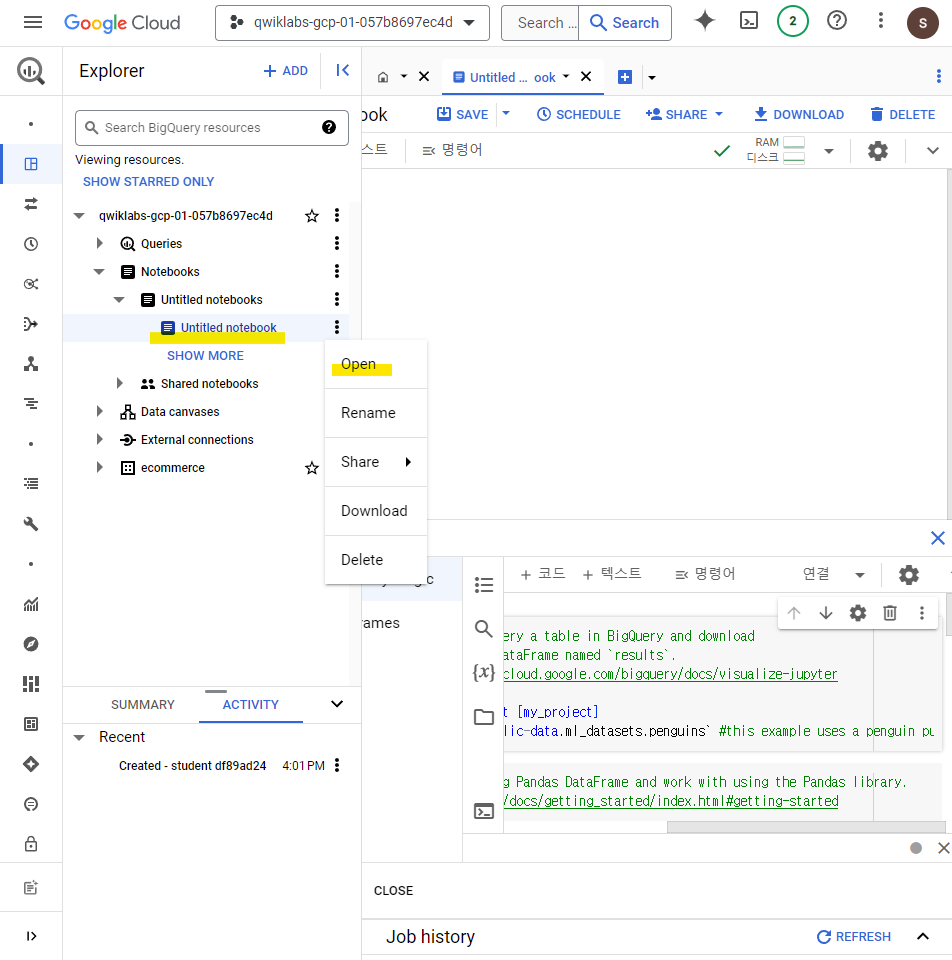
먼저, 해당 페이지를 새로고침 해준다.
해당 프로젝트의 Notebooks -> Untitled notebook -> Open
5-2. Python library import와 변수 정의하기
+코드를 누르고 코드를 추가해서 실행시켜준다.
from google.cloud import bigquery
from google.cloud import aiplatform
import bigframes.pandas as bpd
import pandas as pd
from vertexai.language_models._language_models import TextGenerationModel
from bigframes.ml.cluster import KMeans
from bigframes.ml.model_selection import train_test_split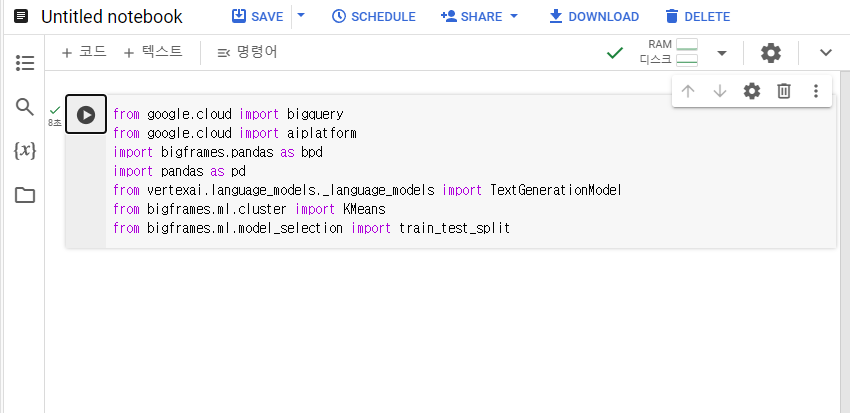
5-3. BigQuery 실행하고 Vertex AI 연결
project_id = 'qwiklabs-gcp-01-057b8697ec4d'
dataset_name = "ecommerce"
model_name = "customer_segmentation_model"
table_name = "customer_stats"
location = "us-central1"
client = bigquery.Client(project=project_id)
aiplatform.init(project=project_id, location=location)5-4. ecommerce.customer_stats table 생성
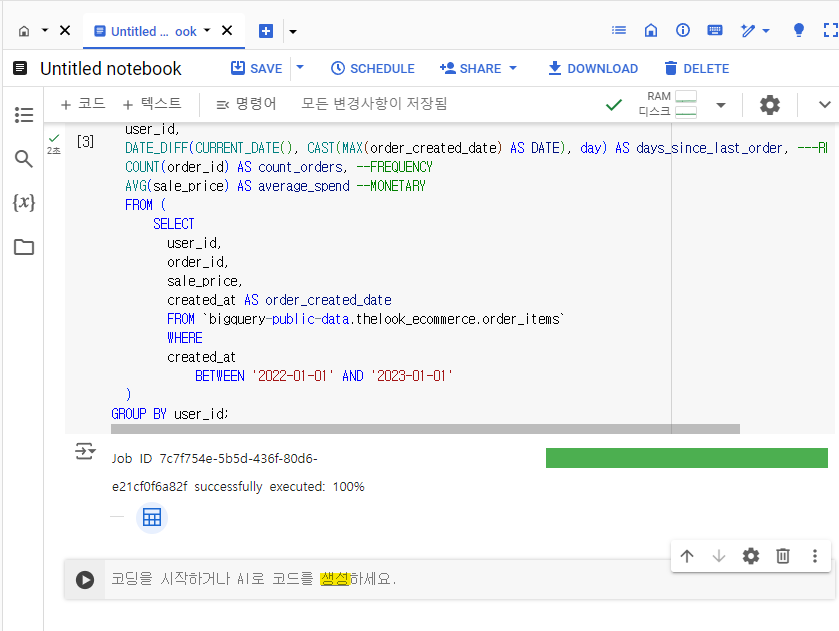
%%bigquery
CREATE OR REPLACE TABLE ecommerce.customer_stats AS
SELECT
user_id,
DATE_DIFF(CURRENT_DATE(), CAST(MAX(order_created_date) AS DATE), day) AS days_since_last_order, ---RECENCY
COUNT(order_id) AS count_orders, --FREQUENCY
AVG(sale_price) AS average_spend --MONETARY
FROM (
SELECT
user_id,
order_id,
sale_price,
created_at AS order_created_date
FROM `bigquery-public-data.thelook_ecommerce.order_items`
WHERE
created_at
BETWEEN '2022-01-01' AND '2023-01-01'
)
GROUP BY user_id;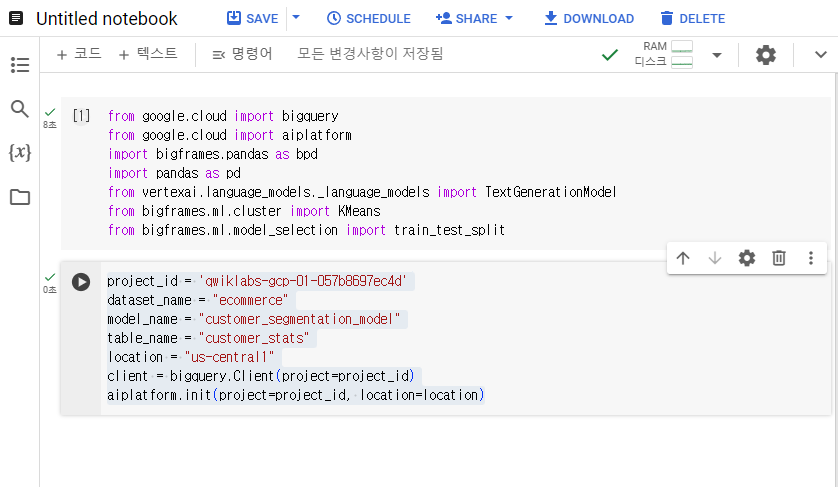
5-5. BigQuery DataFrame 생성하고 Gemini 프롬프트를 이용해서 data 생성하기
5-4. K-means clustering 생성하기
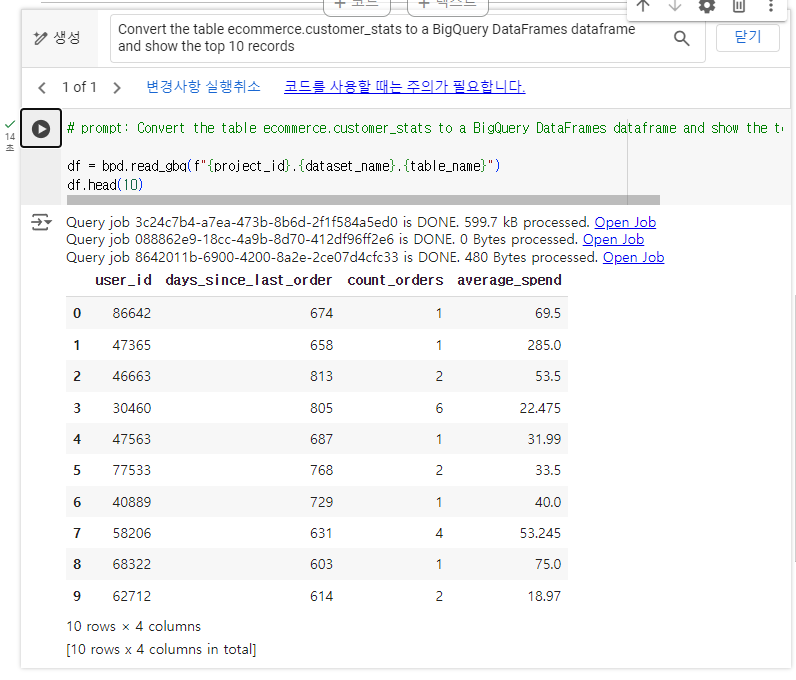
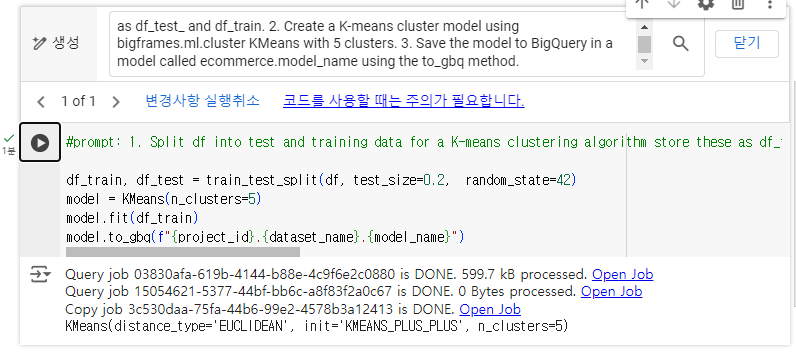
contents refresh 후에 진행한다.
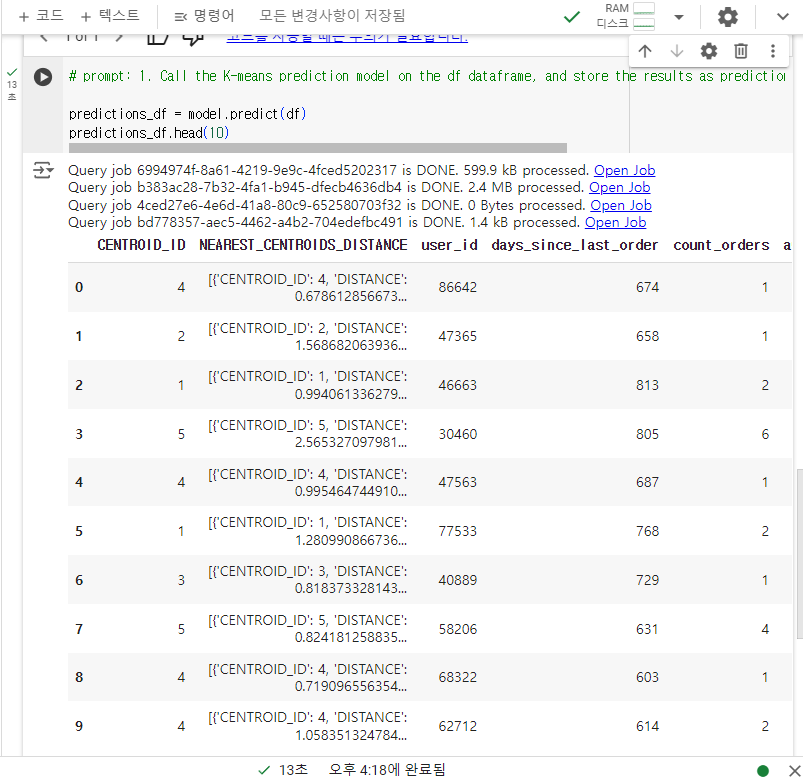
5-6. K-means clustering model 결과 시각화 만들기
여기서 무한 로딩이 뜬다. 30분정도 진행됐는데도 생성이 되지 않았다.
구글 서포트 팀에 문의 결과 다른 유저들도 이 곳에서 같은 문제가 발생했다고 한다.
이메일로 업데이트하고 알려준다는데, 내 스터디 잼 뱃지는 어떻게 될지 모르겠다.
현재 스터디잼 진행팀에 문의 메일을 넣어놓은 상황이다.
주말이 끼어있어서 다시 시도해봤다.
#prompt: 1. Using predictions_df, and matplotlib, generate a scatterplot. 2. On the x-axis of the scatterplot, display days_since_last_order and on the y-axis, display average_spend from predictions_df. 3. Color by cluster. The chart should be titled "Attribute grouped by K-means cluster."
import matplotlib.pyplot as plt
plt.scatter(predictions_df['days_since_last_order'], predictions_df['average_spend'], c=predictions_df['CENTROID_ID'])
plt.xlabel("days_since_last_order")
plt.ylabel("average_spend")
plt.title("Attribute grouped by K-means Cluster")
plt.show()
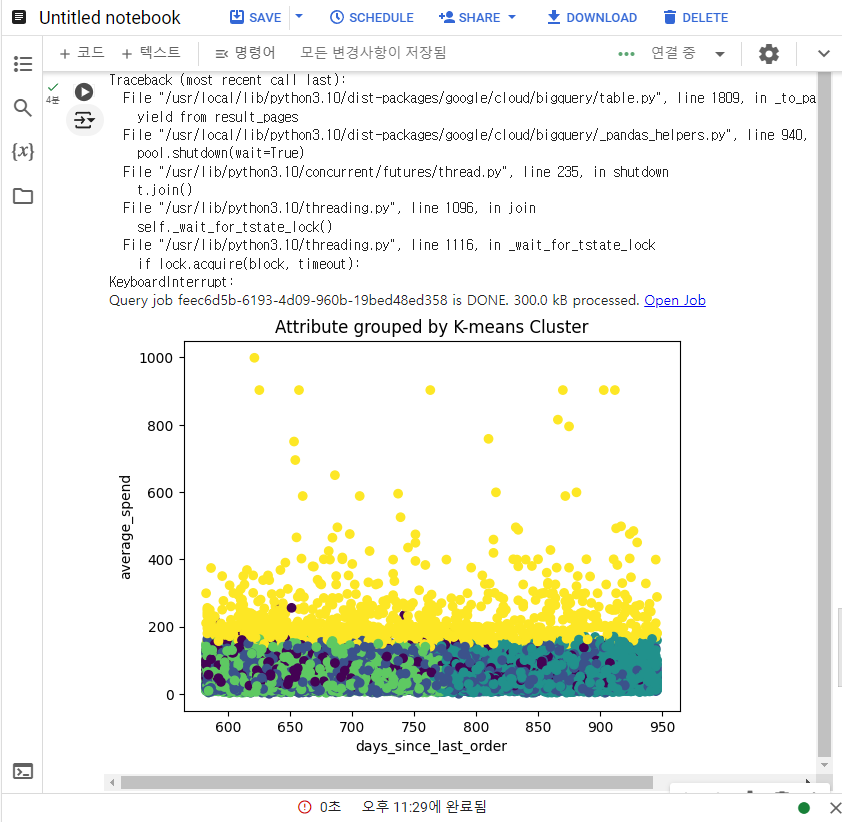
실행 10분 후 중단을 누르니 갑자기 산점도 분포가 나오면서 성공했다고 떴다.
그러나 스터디 진행 사항에서는 인식이 안돼서 다시 시도해봤다.
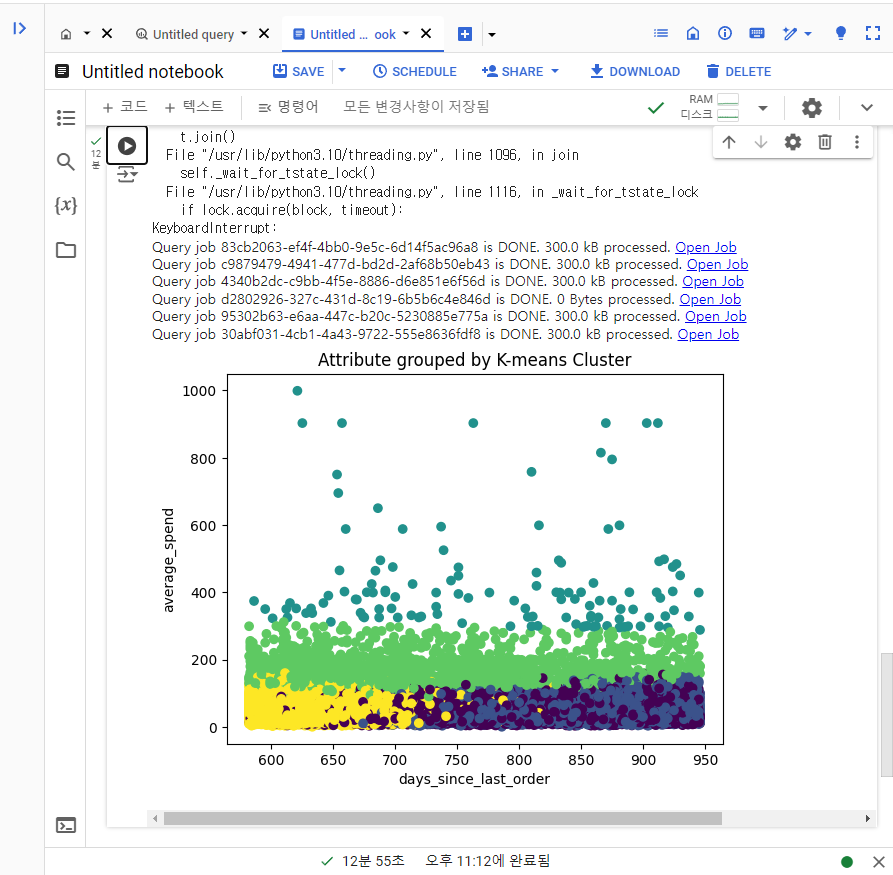
다시 같은 코드를 입력하고 다시 중단하니 오류가 떴다. 이번에는 빈 그래프가 나옴.
산점도가 분포되기 전 중단했던 것 같아서, 다시 돌려봤다.
이번에는 GEMINI 생성을 통해서 코드를 만들어달라고 했다.
그리고 해당 코드를 돌리니 성공했다.
코드 내용은 같았음...
6. 모델 결과로 insight 얻기
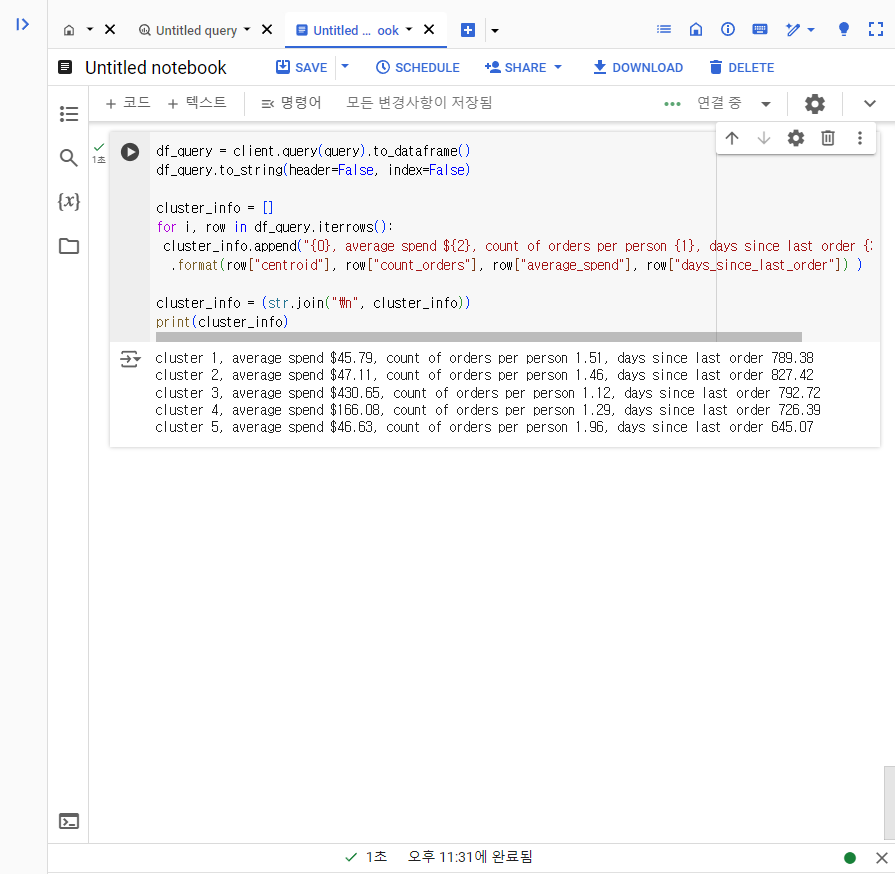
6-1. K-means 모델에서 생성된 각 클러스터를 요약
클러스터 표 요약하기
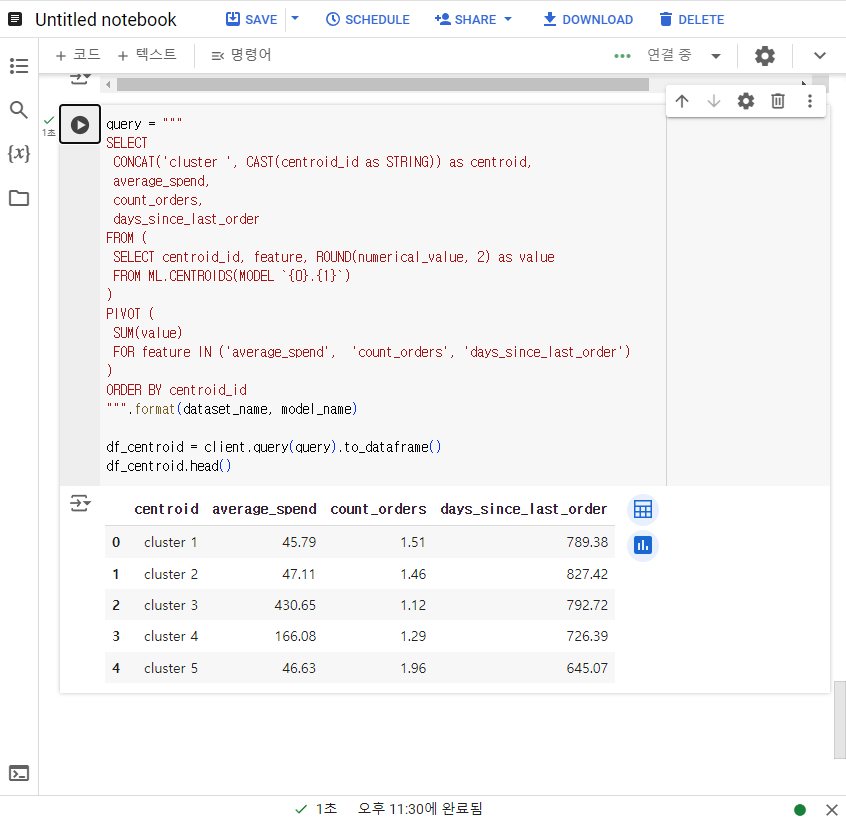
해당 결과를 문자로 출력하기
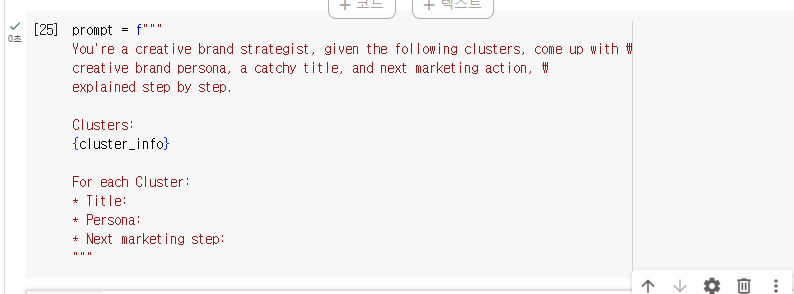
6-2. marketing campaign 프롬프트 정의
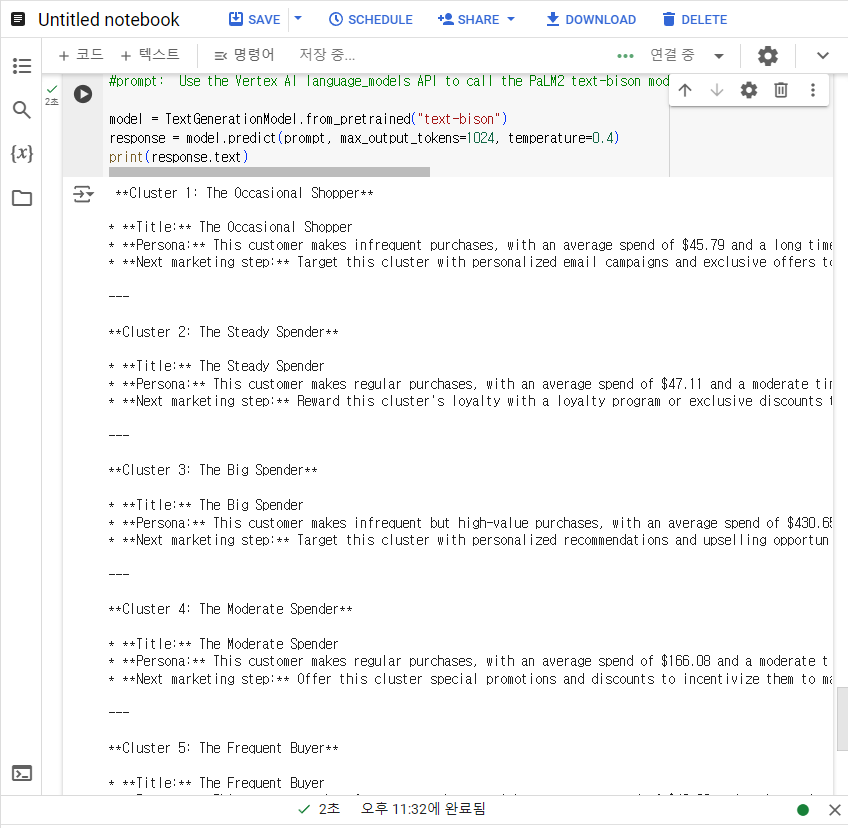
6-3. text-bison model을 이용한 marketing campaign 생성
- Title
- Persona
- Next marketing step
항목으로 생성
7. 프로젝트 리소스 정리
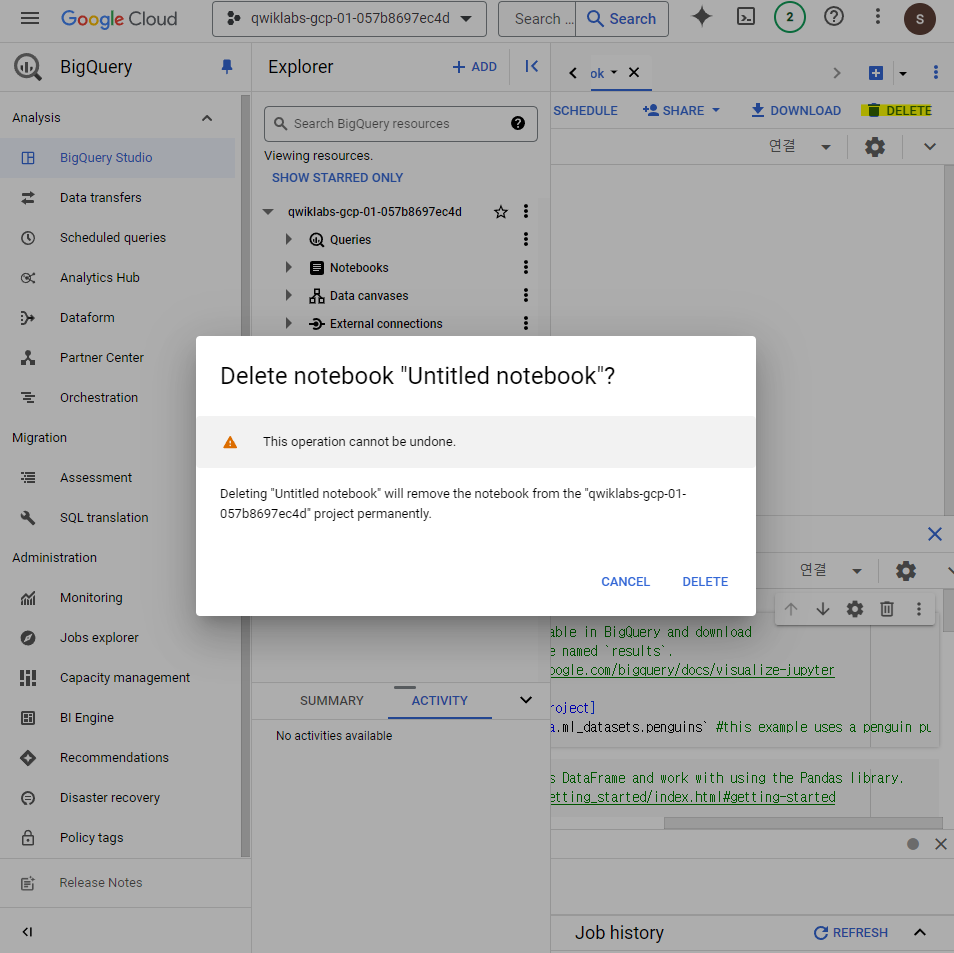
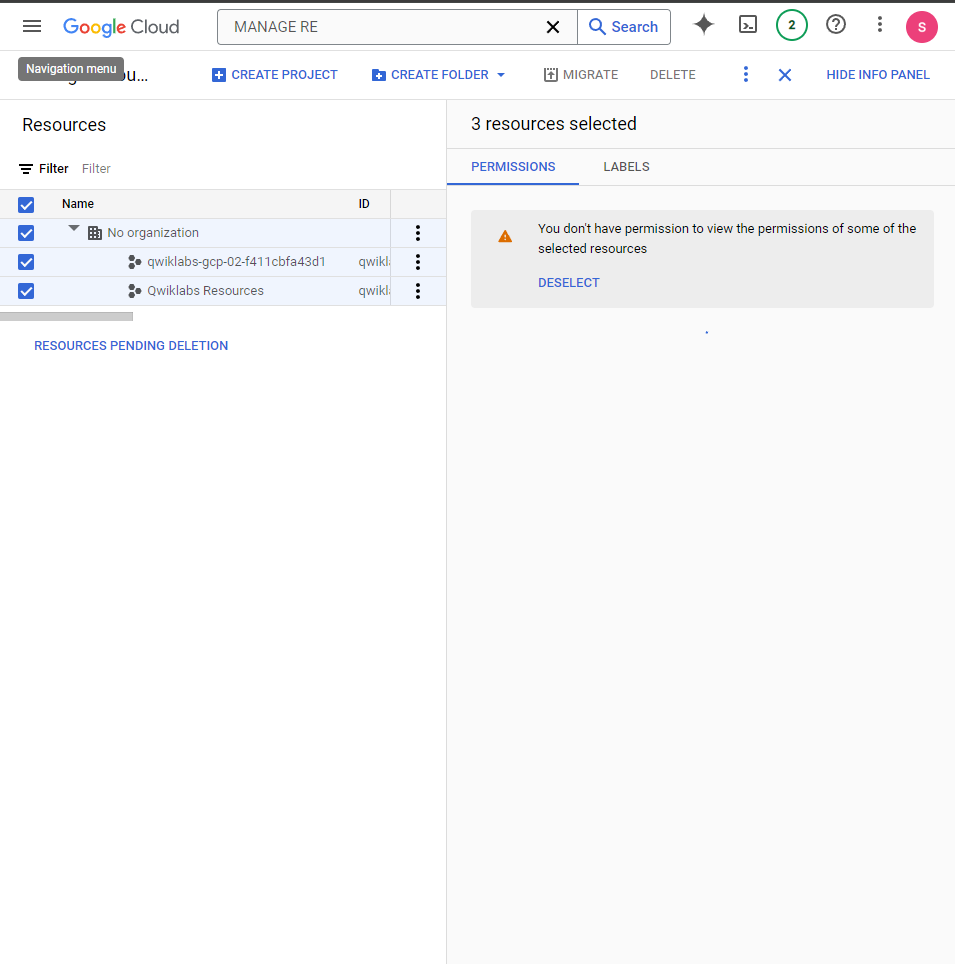
7-1. 프로젝트 삭제
Google Cloud 콘솔 내에서 Manage Resources에서 해당 프로젝트 선택 후 DELETE
7-2. 개별 리소스를 삭제
# Delete customer_stats table
client.delete_table(f"{project_id}.{dataset_name}.{table_name}", not_found_ok=True)
print(f"Deleted table: {project_id}.{dataset_name}.{table_name}")
# Delete K-means model
client.delete_model(f"{project_id}.{dataset_name}.{model_name}", not_found_ok=True)
print(f"Deleted model: {project_id}.{dataset_name}.{model_name}")
삭제된 걸 확인할 수 있다.
8. 정리


말도 많고 탈도 많던 Data Scientist 실습이었다.
BigQuery 스튜디오에서 DataFrame을 이용해서 Dataset을 만들고 산점도 모델을 만들어 도표화하고 마케팅 캠페인이 맞춰서 문자 출력까지 해봤다.
확실히 데이터양이 많으니까 시간이 오래걸리고 오류도 많은 듯 하다.
지난 번에는 30분 이상 소요돼도 안 됐는데 중간에 중단했다가 재시도 하니까 10분만에 됐다.
인프라는 원래 이런거라고는 하지만, 설정이 바뀐 게 없었는데...
이래서 서버 돌릴 때 기도하는 듯
