정렬
- 작은 값부터 큰 값으로 나열하는 알고리즘
- 가장 작은 것을 가장 앞으로 보낸다.
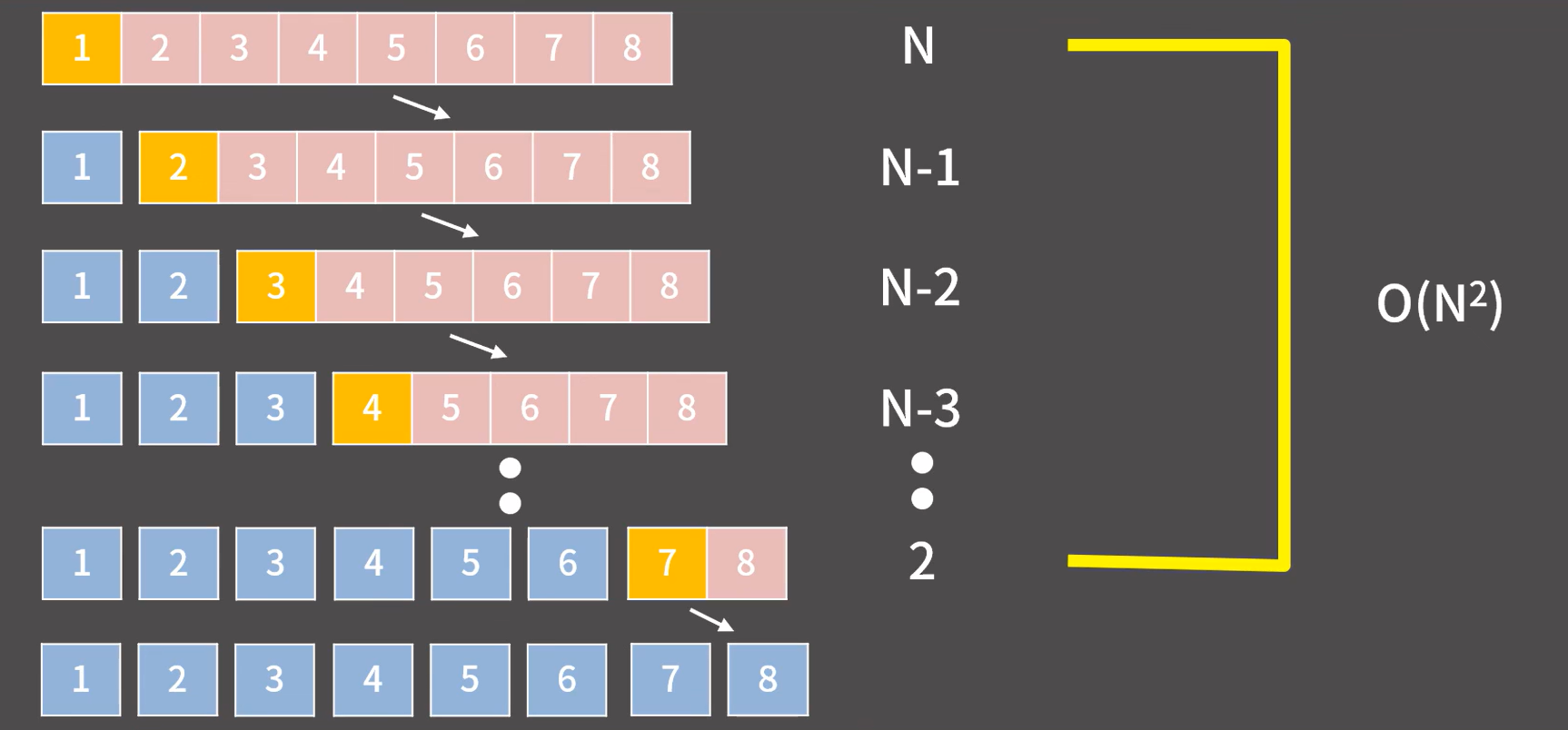
선택 정렬 : Selection sort
기본 선택 정렬 = 오름차순
- 현재 위치 : 배열의 0번째 인덱스부터 시작
- 비교 대상 : 현재 위치의 오른쪽에 있는 값들
- 기준 : 그 중 가장 작은 값을 찾아 현재 위치와 교환
역방향 선택 정렬 = 내림차순
- 현재 위치 : 배열의 마지막 인덱스부터 시작
- 비교 대상 : 현재 위치의 왼쪽에 있는 값들
- 기준 : 그 중 가장 큰 값을 찾아 현재 위치와 교환
시간 복잡도
전체 비교 횟수인 은 등차 수열 합의 공식에 의해 이므로 이다.
구현 방식
1. 배열로 구현
현재 최솟값 vs 현재 내가 탐색하고 있는 값
#include <iostream>
#include <algorithm>
using namespace std;
int main() {
int arr[5] = {3, 2, 7, 116, 62};
int n = 5;
for (int i = 0; i < n - 1; i++) {
int min_idx = i; // 현재 위치 i의 값을 현재 최솟값의 인덱스로 가정
for (int j = i + 1; j < n; j++) {
// 현재 최솟값(arr[min_idx]) vs 지금 탐색 중인 값(arr[j])
if (arr[j] < arr[min_idx]) {
min_idx = j; // 더 작은 값 발견하면 최솟값의 인덱스 갱신
}
}
// i번째 위치에 들어갈 최종 최솟값을 현재 위치 i와 교환
swap(arr[min_idx], arr[i]);
}
return 0;
}2. STL로 구현
max_element(arr, arr+k): arr[0]부터 arr[k-1]까지의 범위 내에서 최댓값인 원소의 주소를 반환하는 함수
int arr[5] = { 3,2,7,116,62 };
int n = 5;
for (int i = n-1; i > 0; i--) {
swap(*max_element(arr, arr+i+1), arr[i]);
}버블 정렬 : Bubble sort
-
인접한 두 원소의 크기를 비교해 자리를 교환하여 정렬하는 방식이다.
-
인접한 처음 두 개의 원소부터 인접한 마지막 원소까지 비교하는 작업과 자리를 교환하는 작업을 반복하면서 결국 가장 큰 원소가 마지막 자리에 정렬된다.
-
위의 과정을 거쳐 원소가 맨 마지막 자리로 이동하는 모습이 물 위로 뽀글뽀글 올라오는 물방울 모양 같다고 해서 버블 정렬이라고 한다.
-
전체 비교 횟수인 와 전체 자리 교환 횟수인 을 합하면 총 실행 횟수는 이므로 시간 복잡도는 이다.
✅ 구현
매 회차의 정렬 종료 후 비교할 원소의 범위가 줄어든다.
- 1회차 정렬 후 : n-1번째 자리의 원소 확정
- 2회차 정렬 후 : n-2번째 자리의 원소 확정
int arr[5] = { -1,2,7,116,62 };
int n = 5; // 배열의 크기
// 전체 배열 정렬
for (int i = 0; i < n; i++) {
// 인접한 두 요소 비교 (이미 정렬된 부분은 제외하고 비교)
// n-1 : 배열의 마지막 인덱스, i : 지금까지 정렬 확정된 원소의 개수
for (int j = 0; j < n-1-i; j++) {
if (arr[j] > arr[j+1]) swap(arr[j], arr[j+1]);
}
}합병 정렬 : Merge sort
재귀적으로 수열을 나눠 정렬한 후 다시 합치는 정렬 방식이다.

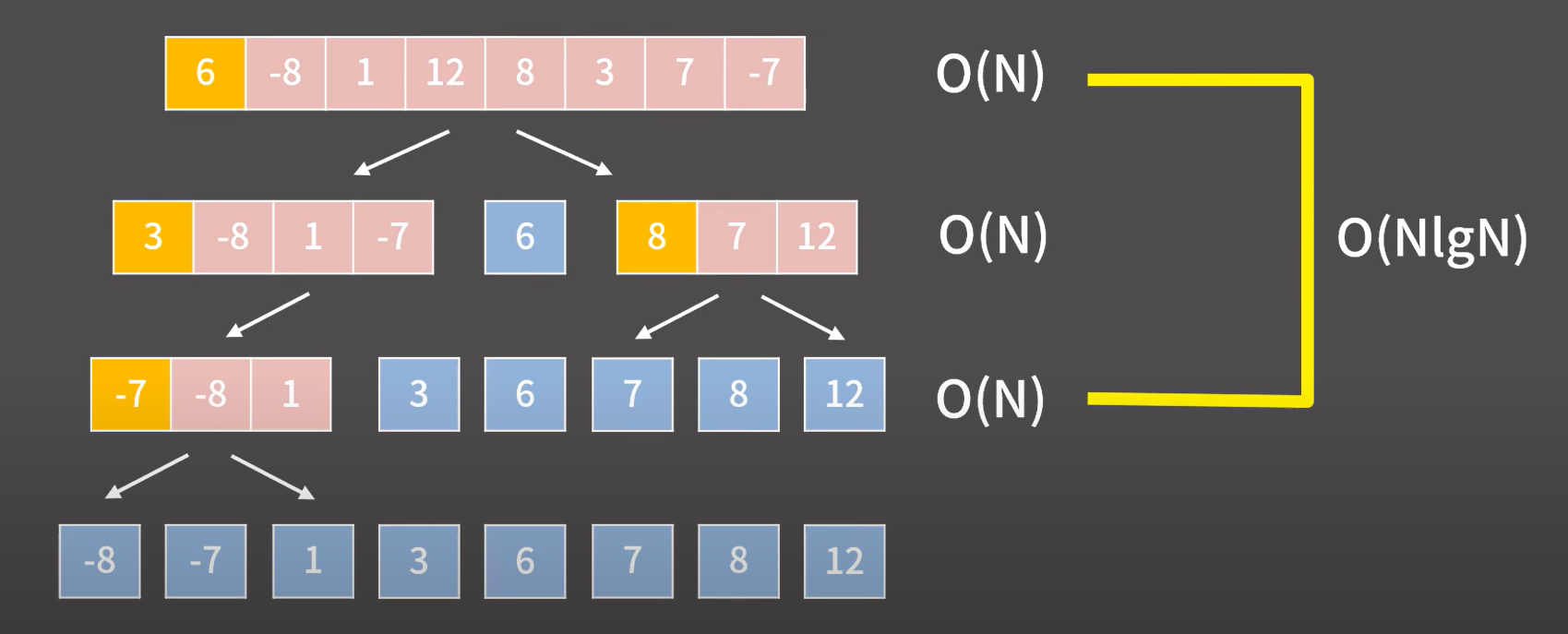
✅ 분할
각 줄에 존재하는 리스트 개수만큼 분할해야 하기 때문에 분할되는 횟수는 번이고 최종적으로 분할된 리스트의 총 개수는 N개이므로 분할 시 시간 복잡도는 이다.
✅ 병합
각 줄에 존재하는 모든 리스트의 원소들을 비교하여 병합하는 과정을 거치기 때문에 한 단계당 총 N개의 원소를 처리한다. 단계별로 각 리스트의 크기가 개로 증가하면서 k단계를 거쳐 최종적으로 병합된 리스트의 길이는 N이므로 병합 시 시간 복잡도는 이다.
이므로 최종적인 시간 복잡도는 이다.
구현 과정
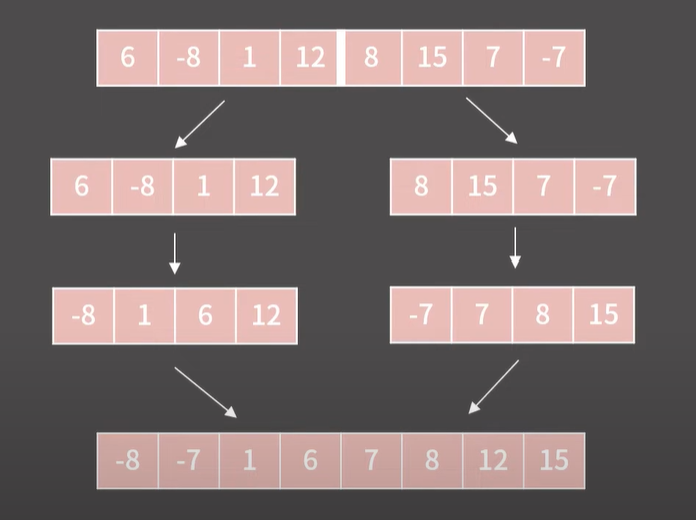
- 주어진 리스트를 2개로 나눈다.
- 나눈 리스트 2개를 각각 정렬한다.
- 정렬된 2개의 리스트를 합친다.
🔎 분할한 리스트를 정렬하는 방법
- 길이가 1인 리스트를 정렬할 수 있다.
- 길이가 N인 두 정렬된 리스트를 합칠 수 있다.
따라서 길이가 N인 리스트를 정렬할 수 있으면 길이가 2N인 리스트를 정렬할 수 있다.
⭐️ 기본 코드
#include <bits/stdc++.h>
using namespace std;
int n = 10; // 리스트의 원소 개수
int arr[1000001] = { 15, 25, 22, 357, 16, 23, -53, 12, 46, 3 };
int tmp[1000001]; // 정렬 결과 임시 저장
// arr[st:mid], arr[mid:en]가 이미 정렬이 되어있는 상태에서 이 둘을 합쳐 arr[st:en]을 다시 정렬하는 함수
void merge(int st, int en) {
int mid = (st + en) / 2; // 분할 지점
int l_idx = st; // arr[st:mid]인 왼쪽 리스트의 인덱스
int r_idx = en; // arr[mid:en]인 오른쪽 리스트의 인덱스
// 다시 정렬하여 tmp 리스트에 저장
for (int i = st; i < en; i++) {
// 오른쪽 리스트 완료 시 남은 왼쪽 리스트 복사
if (r_idx == en) tmp[i] = arr[l_idx++];
// 왼쪽 리스트 완료 시 남은 오른쪽 리스트 복사
else if (l_idx == mid) tmp[i] = arr[r_idx++];
// 두 리스트 비교하여 더 작은 값을 저장
else if (arr[l_idx] <= arr[r_idx]) tmp[i] = arr[l_idx++];
else tmp[i] = arr[r_idx++];
}
for (int j = st; j < en; j++) arr[j] = tmp[j]; // 정렬 후 다시 원래 리스트로 복사
}
// arr[st:en] 구간을 정렬하는 재귀함수
void merge_sort(int st, int en) {
if (en == st + 1) return; // 리스트의 길이가 1이면 종료
int mid = (st + en) / 2;
merge_sort(st, mid); // arr[st:mid]을 정렬
merge_sort(mid, en); // arr[mid:en]을 정렬
merge(st, en); // arr[st:mid]와 arr[mid:en]을 합친다.
}
int main(void) {
ios::sync_with_stdio(0);
cin.tie(0);
merge_sort(0, n);
for (int i = 0; i < n; i++) cout << arr[i] << ' '; // -53 3 12 15 16 22 23 25 46 357
}💡 Stable sort vs Unstable sort
우선 순위가 같은 원소가 여러 개라서 정렬된 결과가 여러 개인 경우
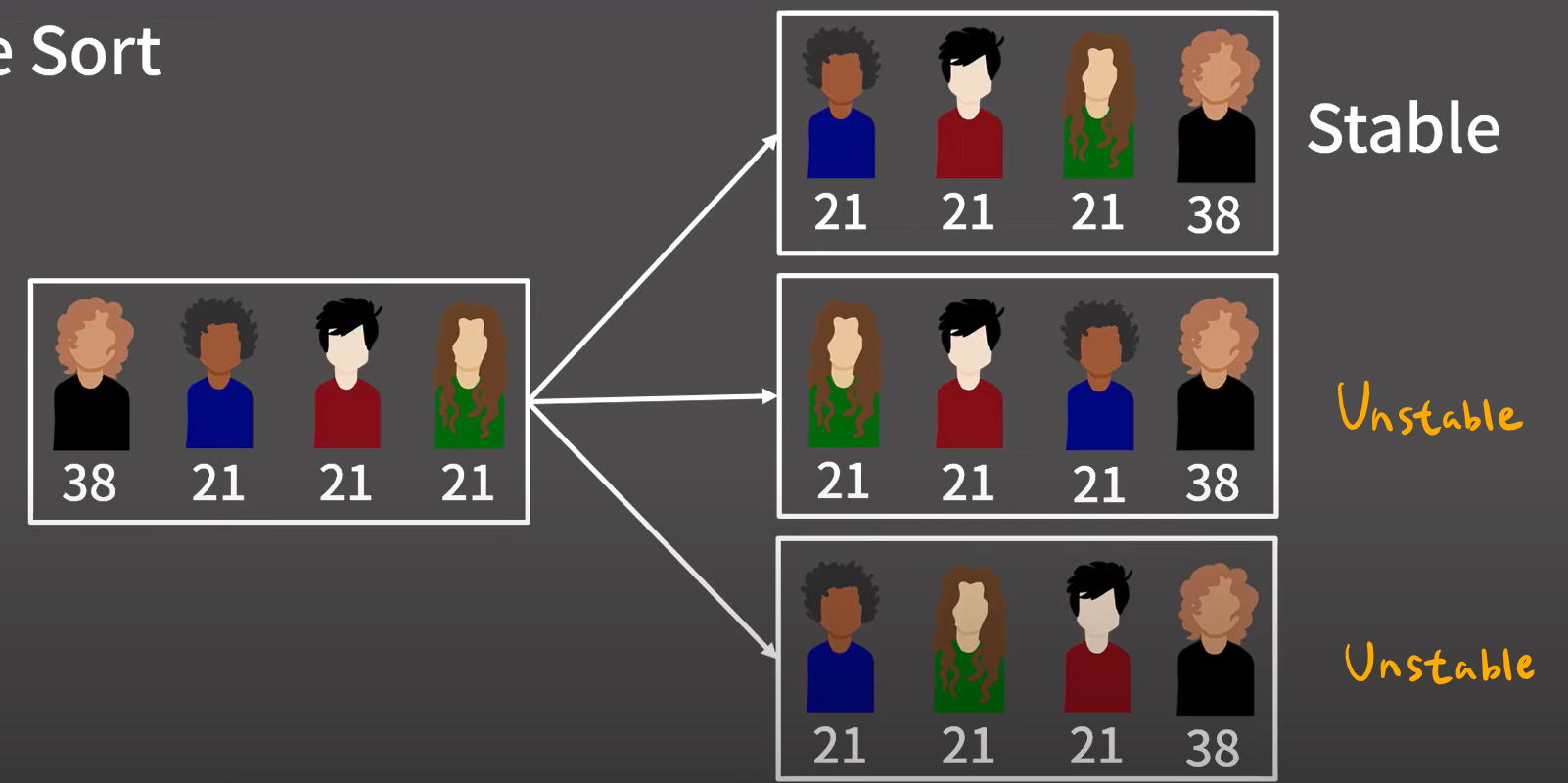
✅ Stable sort
-
우선 순위가 같은 원소들끼리는 원래의 순서를 따라가도록 한다.
-
merge sort, bubble sort, insertion sort
✅ Unstable sort
-
위 그림처럼 첫 번째 정렬 외 다른 순서로도 정렬될 수 있다.
-
quick sort, heap sort, selection sort
퀵 정렬 : Quick sort
-
STL 컨테이너를 사용할 수 없는 경우 정렬 구현 시 무조건 Merge Sort를 사용한다.
-
추가적인 공간 사용 없이 배열 안에서의 자리 바꿈만으로 pivot를 제자리로 보내기 때문에 cache hit rate가 높아 속도가 빠르다
-
이렇게 추가적인 공간을 사용하지 않는 정렬을
In-Place Sort라고 한다.
✅ 구현 과정
- 제일 앞의 원소를 pivot으로 설정한다.
- pivot을 중심으로 왼쪽에는 pivot보다 작은 원소들, 오른쪽에는 pivot보다 큰 원소들이 존재하도록 pivot 원소를 제자리로 보낸다.
- pivot을 중심으로 왼쪽과 오른쪽 리스트를 각각 재귀적으로 정렬한다.
- 위 과정을 반복하여 리스트를 정렬한다.
▶️ pivot 원소를 제자리로 보내는 과정
pivot가 제자리에 있다.
=(pivot보다 작은 원소) (pivot) (pivot보다 큰 원소)
- L 포인터를 pivot보다 큰 값이 나올 때까지 오른쪽으로 이동시킨다.
- R 포인터를 pivot보다 작거나 같은 값이 나올 때까지 왼쪽으로 이동시킨다.
- 각 포인터가 이동을 멈추면 가리키고 있는 원소들의 자리를 바꾼다.
- 위 과정을 반복하다가 두 포인터가 교차되는 순간 pivot과 R 포인터의 원소를 swap하고 종료한다.
✅ 3단계 코드
L 포인터가 가리키는 원소 <= R 포인터가 가리키는 원소
while (1) {
swap(arr[l], arr[r]); // 두 포인터가 가리키는 원소 swap
}✅ 4단계 코드
pivot을 기준으로 왼쪽에는 작은 값들, 오른쪽에는 큰 값들이 존재하도록 정렬 후 두 포인터가 교차되는 순간 pivot과 R 포인터 swap한다.
while (1) {
if (l > r) break; // 두 포인터가 교차되는 순간
}
swap(arr[st], arr[r]); // arr[st]가 pivot기본 코드
#include <bits/stdc++.h>
using namespace std;
int n = 10;
int arr[1000001] = { 15, 25, 22, 357, 16, 23, -53, 12, 46, 3 };
// arr[st:en] 정렬 함수
void quick_sort(int st, int en) {
if (en <= st + 1) return; // 리스트 길이가 1 이하이면 종료
int pivot = arr[st]; // 맨 앞 원소를 pivot이라 설정
int l = st + 1; // 제일 왼쪽 원소를 가리키는 포인터 = 인덱스 번호 저장
int r = en - 1; // 제일 오른쪽 원소를 가리키는 포인터 = 인덱스 번호 저장
while (1) {
while (l <= r && arr[l] <= pivot) l++; // L 포인터 이동
while (l <= r && arr[r] >= pivot) r--; // R 포인터 이동
if (l > r) break;
swap(arr[l], arr[r]);
}
swap(arr[st], arr[r]);
quick_sort(st, r); // pivot의 왼쪽 리스트 퀵 정렬 실행
quick_sort(r + 1, en); // pivot의 오른쪽 리스트 퀵 정렬 실행
}
int main() {
ios_base::sync_with_stdio(0);
cin.tie(0);
quick_sort(0, n);
for (int i = 0; i < n; i++) cout << arr[i] << ' ';
}🤨 시간 복잡도 : 평균
-
L,R 포인터가 각 리스트의 모든 원소를 한 번씩 검사 후 pivot을 제자리로 보낸다. =
-
pivot이 제자리로 갈 때마다 항상 리스트의 정중앙에 위치하여 각 리스트를 균등하게 씩 쪼갠다. =
😡 시간 복잡도 : 최악
-
L,R 포인터가 각 리스트의 모든 원소를 한 번씩 검사 후 pivot을 제자리로 보낸다. =
-
pivot이 제자리로 갈 때마다 항상 리스트의 제일 왼쪽에 위치하여 정렬해야 할 리스트의 크기가 N부터 1씩 감소한다. =
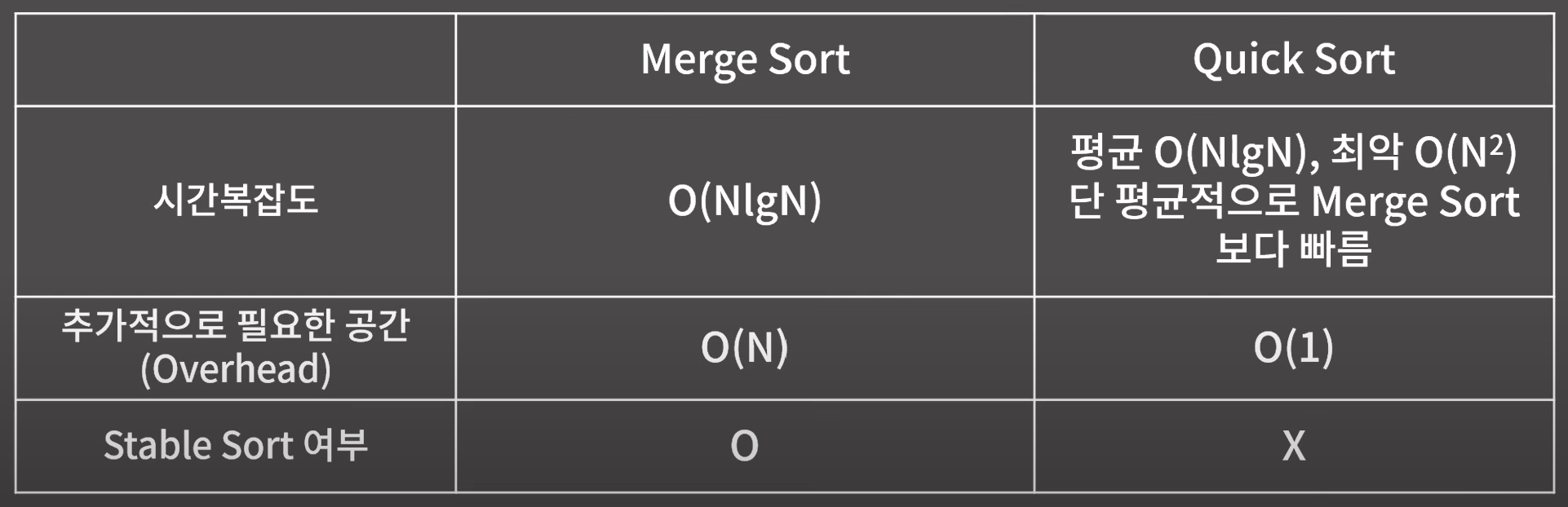
Merge Sort vs Quick Sort