인접 행렬
그래프의 관계를 이차원 배열로 나타내는 방식
방향이 있는 인접행렬
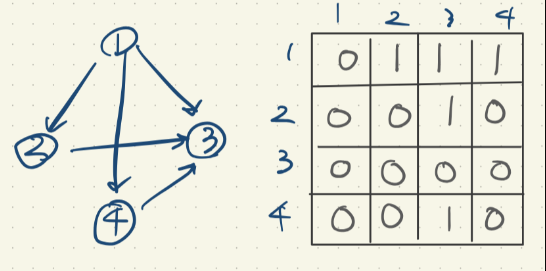
방향이 있는 경우의 그래프의 모습이다.
1번에서 2,3,4 번으로 뻗어나가고 있으니
1번 행이 0,1,1,1 로 표현된다.
그리고 4번 노드는 3번으로만 뻗어나가기 때문에
0,0,1,0으로 표현된다.
여기서는 1로 표현했지만 각 간선의 가중치를 표현할 수도 있다.
예를 들어 1번에서 2번으로 향하는데 6만큼의 비용이 든다고 가정하자
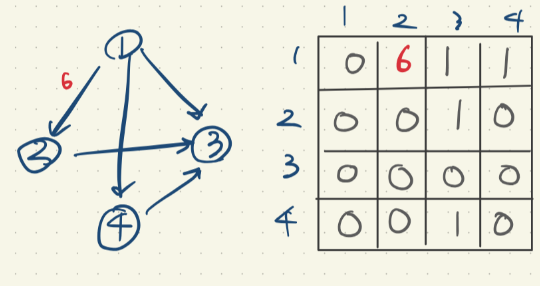
그럼 이런 모습의 인접행렬이 나오게 된다.
해석은 1번에서 2번으로 향하는데 드는 비용이 6
따라서 1번행, 2번열의 값이 1번에서 2번으로 향하는데 드는 비용이다.
방향이 없는 인접 행렬
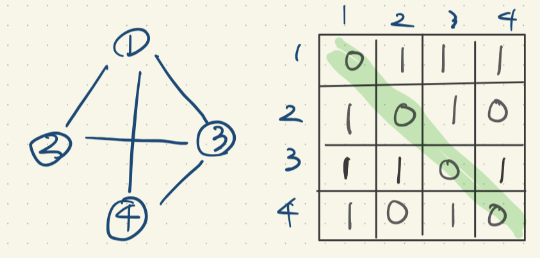
방향이 없는 인접행렬의 특징은 바로 대칭이다.
자기 자신(1,1이나 2,2 혹은 3,3 이런 애들)을 기준으로 대칭을 이루고 있는 형태이다.
삽각형으로 접었을 때 마주보는 값이 일치한다고? 생각하면 된다.
장점
- 구현이 쉽다.
노드i 노드 k의 연결 상태를인접행렬[i][k]의 형태로 O(1)에 알아낼 수 있다.
단점
- 노드와 연결된 갯수 확인에서 시간이 오래걸릴 수 있다.
이 말은 무엇이냐면
만약 저 그림에서 노드의 갯수는 1,2,3,4 총 4개이다.
1번 노드와 연결된 노드 값을 알아내려면 1번 행을 탐색해야한다.
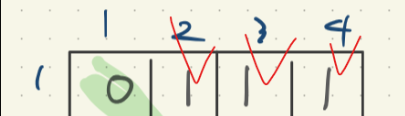
이 그림에서는 1번 노드와 연결된 것이 2,3,4 세 개인 것을 알 수 있다.
우리는 그림으로 보아서 직관적으로 3개임을 알 수 있지만 컴퓨터같은 경우에는 그래프를 읽어야만 알 수 있다.
즉 노드의 갯수가 10개면
1번 행에서 10개의 열을 모두 확인해야한다는 것이다.
그렇다면 노드의 수가 많고 간선의 수가 적을 때 문제가 발생한다.
노드의 수가1000개일때 간선의 수는 2개라고 하자
안타깝게도 인접 행렬에서는 행에 있는 열의 정보를 모두 읽어와야하기 때문에 1000개의 연산이 수행된다. 단 2개의 간선 존재 여부를 위해 비효율적으로 일해야하는 것이다.
- 메모리낭비
위 쪽의 이야기와 살짝 연결이 되는데 1000개의 노드 1개의 간선이어도1000 * 1000형태의 2차원 배열을 사용하기 때문에 낭비가 발생한다.
인접리스트
그래프의 연결 관계를 list로 나타내는 것
이때 C++에서는 vector로 표현하고 자바에서는 주로 ArrayList를 사용한다.
방향이 있는 인접리스트
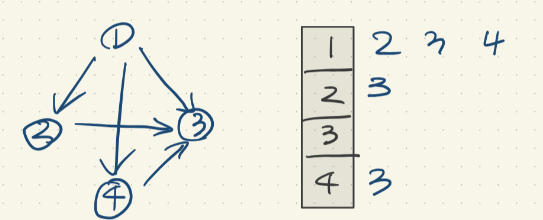
각 행이 어디를 향하느냐에 대한 정보를 담고 있다. 즉 저기서는
1번 노드는 2,3,4,번을 향하고 있고
2번 노드는 3번을 향하고 있다.
간선의 값에 가중치를 주고 싶을때는?
이때 가중치를 주고 싶을때는? 객체를 만들거나 노드, 가중치 쌍을 만들어서 보내면 된다. 예를 들면 Map이라던가 배열의 인덱스를 사용한다던가(0번은 노드 1번은 가중치) 이런식으로 말이다.
참고로 들어가는 값에 순서는 의미가 없다.
방향이 없는 인접리스트
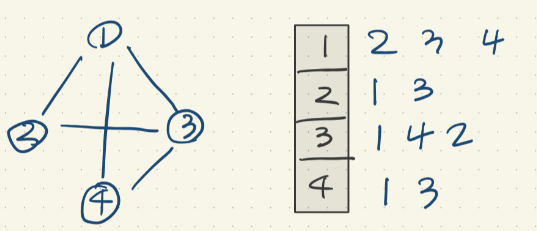
마찬가지로 방향이 없는 그래프는 위처럼 표현될 수 있다.
장점
실제로 연결된 노드의 정보만 저장하기 떄문에 메모리를 인접행렬보다 아낄 수 있다.
단점
노드 i,k가 연결되어 있는지 확인하려면
list[i]행의 노드들을 탐색해야한다. 즉
1번 노드와 연결된 노드를 알려면 인접행렬과 달리 list의 1번 행에 저장된 값을 읽어야 노드를 확인할 수 있다는 의미이다.
문제
백준 dfs와 bfs
dfs, bfs를 통해서 노드를 탐색하는 방법을 알려주는 기본 문제이다.
- 나는 두 가지 방법을 활용해서 문제를 풀어보았다.
인접행렬 활용
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.sql.SQLOutput;
import java.util.*;
class Main {
static int [] vis;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
int node = Integer.parseInt(st.nextToken());
int v = Integer.parseInt(st.nextToken());
int start = Integer.parseInt(st.nextToken());
vis = new int[node+1];
int [][] arr = new int[node+1][node+1];
for(int i=0; i<v; i++){
st = new StringTokenizer(br.readLine());
int x = Integer.parseInt(st.nextToken());
int y = Integer.parseInt(st.nextToken());
arr[x][y] =1;
arr[y][x] =1;
}
//dfs수행
dfs(start, arr);
System.out.println();
for(int i=0; i<arr.length; i++){
vis[i] =0;
}
bfs(start, arr);
}
private static void dfs(int start ,int[][] arr){
vis[start]=1;
System.out.print(start+ " ");
for(int i=1; i<arr.length; i++){
if(arr[start][i] == 1 && vis[i] ==0){
vis[start]=1;
dfs(i,arr);
}
}
}
private static void bfs(int start, int[][] arr){
Queue<Integer> q = new LinkedList<>();
q.add(start);
vis[start]=1;
System.out.print(start + " ");
while(!q.isEmpty()){
int cur = q.poll();
for(int i=1; i<arr.length; i++){
if( arr[cur][i]==1 &&vis[i]==0){//연결된 노드인데 방문을 안했다?
vis[i] =1;
q.add(i);
System.out.print(i + " ");
}
}
}
}
}
인접 리스트활용!
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.sql.SQLOutput;
import java.util.*;
class Main {
static int[] vis;
public static void main(String args[]) throws IOException{
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
int node = Integer.parseInt(st.nextToken());
int line = Integer.parseInt(st.nextToken());
int start = Integer.parseInt(st.nextToken());
vis = new int[node+1];
ArrayList<ArrayList<Integer>> templist = new ArrayList<>();
for(int i=0; i< node+1; i++){
ArrayList<Integer> arr = new ArrayList<>();
templist.add(arr);
}
//값 받기
for(int i=0; i<line; i++){
st = new StringTokenizer(br.readLine());
int x = Integer.parseInt(st.nextToken());
int y = Integer.parseInt(st.nextToken());
templist.get(x).add(y);
templist.get(y).add(x);
}
//정렬하기
ArrayList<ArrayList<Integer>> list = new ArrayList<>();
for(int i=0; i<templist.size(); i++){
ArrayList<Integer>arr = new ArrayList<>();
arr = templist.get(i);
Collections.sort(arr);
list.add(arr);
}
//dfs를 통해서 돌리기
ArrayList<Integer> answer = new ArrayList<>();
dfs(start, list, answer);
for(int x : answer){
System.out.print(x + " ");
}
System.out.println();
for(int i=0; i<node +1; i++){
vis[i] =0;
}
answer = new ArrayList<>();
bfs(start,list, answer );
for(int x : answer){
System.out.print(x + " ");
}
System.out.println();
}
private static ArrayList<Integer> dfs(int start, ArrayList<ArrayList<Integer>> list, ArrayList<Integer> answer){
vis[start] =1;
answer.add(start);
for(int x: list.get(start)){
if(vis[x]==0){
dfs(x,list,answer);
}
}
return answer;
}
private static ArrayList<Integer> bfs(int start, ArrayList<ArrayList<Integer>> list, ArrayList<Integer> answer){
vis[start]=1;
Queue<Integer> q = new LinkedList<>();
q.add(start);
answer.add(start);
while(!q.isEmpty()){
int cur = q.poll();//list.get(cur) 해서 노드들 다 탐색할꺼임
vis[cur] =1;
for(int x : list.get(cur)){
if(vis[x] ==0){
q.add(x);
vis[x] =1;
answer.add(x);
}
}
}
return answer;
}
}
인접 행렬과 인접 리스트는 모두 간선의 연결 상태를 확인할 수 있는 지표이다. 둘의 장점 단점을 파악하고 필요한 상황에 적절하게 배치해보자!
Reference
