포인터
들어가기에 앞서 우리가 앞에서 공부했던 ‘메모리 구조’를 다시 한번 보고 상기시켜 보자.
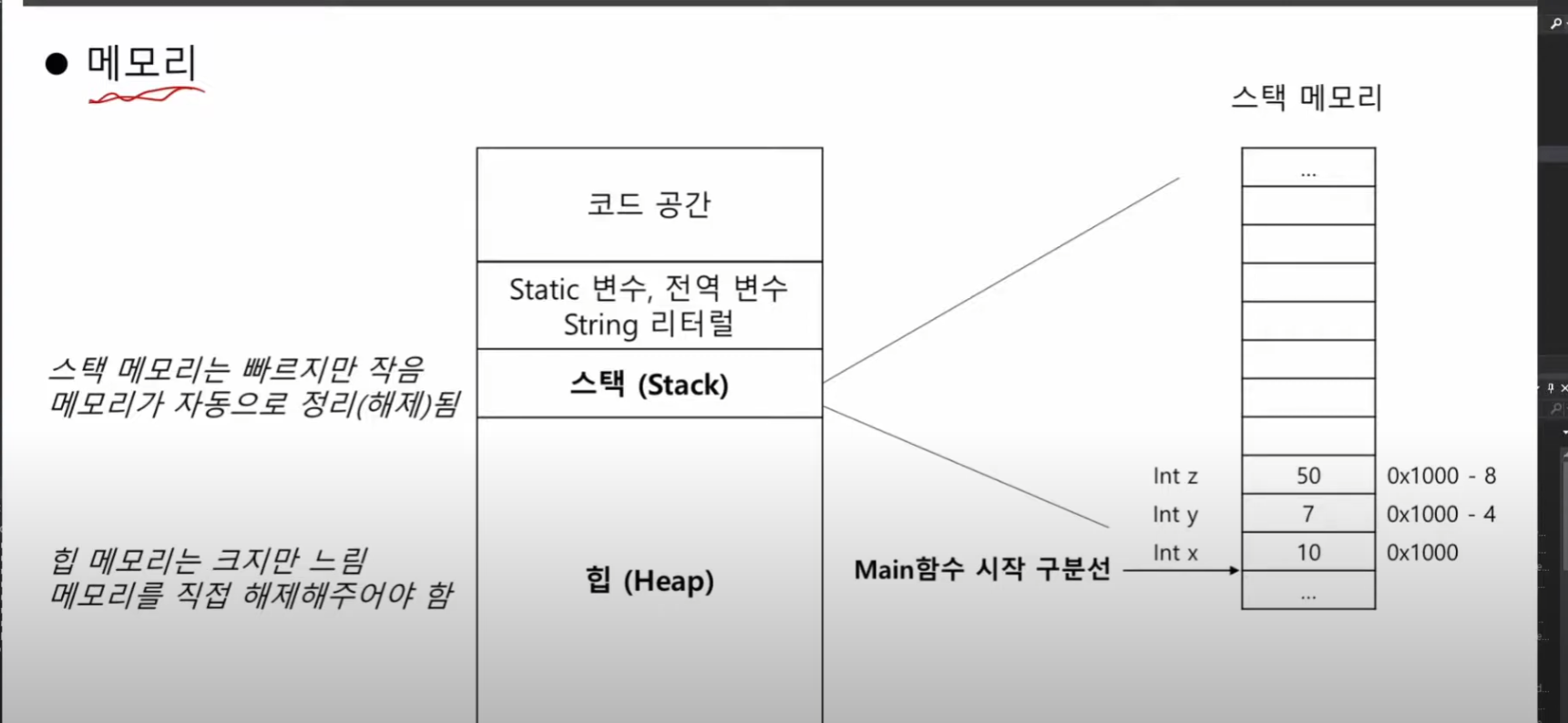
그러기 위해서는 포인터라는 개념을 완벽히 숙지해야 한다.
variable_type* pointer_name = nullptr;
-
초기화를 하지 않으면 쓰레기 값이 들어있는 상태이므로 방지가 필요
- 임의의 값이 컴퓨터의 중요한 메모리에 접근 할 수도 있음
-
nullptr은 아무것도 가리키지 않는 상태를 의미
-
포인터 변수는 변수의 타입 중 하나
- 포인터 변수의 값은 메모리의 주소
- 지금까지 사용한 변수와 포인터 변수의 차이 : 값을 저장하는지 ,주소를 저장하는지
- 포인터는 가리키는 주소에 저장된 데이터의 타입을 알아야함
- 포인터 변수의 값은 메모리의 주소
-
포인터의 타입
- 컴파일러는 포인터가 가리키는 타입이 맞는지 확인함
- int 는 int가 저장된 주소만, double 는 double이 저장된 주소만 가리킬 수 있음
- 컴파일러는 포인터가 가리키는 타입이 맞는지 확인함
-
포인터를 쓰는 이유
- 동적 할당을 통해 힙 영역의 메모리를 사용
- 변수의 범위 문제로 접근할 수 없는 곳의 데이터를 사용 (참조자와 유사한 목적)
- 배열의 효율적인 사용
- 다형성은 포인터를 기반으로 구현됨
- 시스템 응용 프로그램 / 임베디드 프로그래밍에서는 메모리에 직접 접근이 필요함.
변수의 주소값을 얻어오기
- 포인터 변수는 주소값을 저장하므로, 주소값을 얻어올 수 있어야 함
- 이를 위해 주소 연산자( “&” )를 사용
- 연산자가 적용되는 피연산자의 주소값이 반환됨
- 피연산자는 주소값을 얻을 수 있는 종류여야 함 ( L - value)
ex)
int a = 10;
int* ptr = null;
ptr = &a;
cout << sizeof(ptr); // 4byte이때 ptr의 크기가 왜 4바이트냐? 가리키는 변수가 int라서 그런가?
- 아니다! 그 이유는 우리가 (대부분) 32비트 운영체제를 사용하기 때문이다, 32 비트 운영체제는 메모리를 32비트 주소로 나타내기 때문에 포인터는 4 byte의 크기를 가질 수 밖에 없는 것이다
- 만약 OS가 64 bit로 메모리를 나타낸다면 포인터의 크기는 8 byte의 크기를 가질 수 밖에 없다.
포인터의 역참조
- 포인터의 주소에 저장된 데이터에 접근
- 연산자를 이용 ( 에스터리스크)
#include <iostream>
int main()
{
int score = 10;
int* ptr = &score;
std::cout << *ptr << std::endl;
*ptr = 20;
std::cout << *ptr << std::endl;
std::cout << score << std::endl;
return 0;
}위와 같이 *ptr을 단독적으로 사용한다면 “ptr이라는 포인터 변수가 가리키고 있는 변수에 int형 변수에 접근하여 그 안에 저장된 값에 접근한다!” 라고 생각하면 좋다!
즉 , 포인터가 가리키고 있는 변수의 값을 조작하고 싶으면 역참조를 사용하면 된다.
동적 메모리 할당
-
런타임에 힙 메모리를 할당
- 프로그램의 실행 도중 얼마나 많은 메모리가 필요한지 미리 알 수 없는 경우 사용
- 사용자의 입력에 따라 크기가 바뀌는 경우
- 파일을 선택하여 내용을 읽어오는 경우
- 큰 데이터를 저장해야 할 경우 ( stack은 크기가 작다, 몇MB 정도 밖에..)
- 객체의 생애주기 (언제 메모리가 할당되고 해제되어야 할지)를 직접 제어하는 경우
- 프로그램의 실행 도중 얼마나 많은 메모리가 필요한지 미리 알 수 없는 경우 사용
-
힙 메모리는 스택과 달리 스스로 해제되지 않음!
-
사용이 끝나고 해제하지 않으면 메모리 누수 발생!
ex)
int n;
std::cout << "Enter the number of elements: ";
std::cin >> n;//사용자의 입력의 크기에 따라서 달라진다.
// 동적 메모리 할당
int* arr = new int[n];동적 메모리 할당 사용
- new 연산자 사용
- 해제시 delete를 사용하여 주소 공간 반환
- 메모리 누수가 날 수 있다
new의 역할 ( C 의 malloc) Heap 메모리 공간에 int 하나를 담을 수 있는 메모리 주소를 찾고 주소 값을 반환
#include <iostream>
using namespace std;
int main()
{
int* ptr = nullptr;
ptr = new int; // heap에 int만큼의 메모리 할당
cout << ptr << endl; //주소 값
cout << *ptr << endl; // 쓰레기 값
*ptr = 100;
cout << *ptr << endl;
delete ptr;// 해제해주고 ptr은 nulltptr이 된다.
ptr = nullptr;//컴파일러 마다 null처리를 해주는 것이 있고 안해주는 것이 있어서 초기화 해주는게 좋다.
return 0;
}헷갈리는 Point
int* ptr = nullptr; //이는 스택에 존재
ptr = new int; // ptr이 가리키는 변수를 heap에 할당하고 해당 주소값을 저장한다.- ptr은 stack에 존재 ptr이 가리키는 변수는 heap 영역에 존재한다.
동적 할당을 이용한 배열 선언
#include <iostream>
using namespace std;
int main()
{
int* arrayPtr = nullptr;
int size = 0;
cout << "size of array?";
cin >> size;
arrayPtr = new int[size];
arrayPtr[0] = 10;
arrayPtr[1] = 20;
arrayPtr[2] = 30;
delete[] arrayPtr;
return 0;
}- 별로 다를 것은 없다
- 선언 : new int [size]
- 해제 : delete [] ptr;
- [ ]을 사용하여 배열을 해제할 것이라는 걸 알려주고 ptr을 해제한다.
배열과 포인터
- 배열의 이름은 배열의 첫 요소의 주소를 가리킨다
- 포인터 변수의 값은 주소값이다
- 포인터 변수와 배열이 같은 주소를 가리킨다면, 포인터 변수와 배열은 (거의) 동일하게 사용 가능하다.
-
차이점 : 배열은 주소 값을 정의 이후 변경 불가 , sizeof() 반환 값이 다름
-
직접 봐보자!
#include <iostream> using namespace std; int main() { int scores[] = { 100,95,90 }; cout << sizeof(scores) << endl; int* scoresPtr = scores; cout << sizeof(scoresPtr) << endl; scores = #/* *********중요******* 불가능하다. 배열의 이름음 항상 처음 선언했던 배열의 첫 번째 요소만 가리킨다. */ return 0; }
-
- 이 때 socres = 12 byte , scoresPtr = 4 byte가 나온다
- why ?
- sizeof()의 문법에 처리가 달라서 그렇다, sizeof(배열 이름)은 전체 배열의 크기를 나타내고 sizeofPtr(포인터)는 포인터의 크기를 나타낸다.
- why ?
#include <iostream>
using namespace std;
int main()
{
//정적 할당
int scores[] = { 100,95,90 };
cout << scores << endl; //0x...
cout << *scores << endl; // 100
int* scoresPtr = scores;
cout << scores << endl;//0x...
cout << *scores << endl; //100
return 0;
}- 위의 코드에서 scores라는 배열의 이름은 배열의 첫 요소를 가리키기 때문에 scoresPtr 변수에 할당이 가능하다
- 즉, 우리는 배열의 이름을 포인터 변수에 할당하여 해당 배열에 접근 가능하다.
우리는 배열의 이름이 항상 배열의 첫 번째 요소를 가리키는 포인터인 것을 알게 되었다.
자 그럼 이제 아래의 코드를 한번 봐보자.
#include <iostream>
using namespace std;
int main()
{
//정적 할당
int scores[] = { 100, 95 , 90 };
int* scoresPtr = scores;
cout << scoresPtr << endl; //0x1234
cout << (scoresPtr + 1) << endl; //0x123404
cout << (scoresPtr + 2) << endl; //0x123408
cout << *scoresPtr << endl; // 100
cout << *(scoresPtr + 1) << endl; // 95
cout << *(scoresPtr + 2) << endl; // 90
return 0;
}- C언어에서 배운 사람들은 알 것이다.
int arr[3];
int* ptr = arr;
cout << arr + 1 << endl;
cout << arr + 2 << endl;arr + 1 의 의미는 arr이 가리키는 변수(요소)의 주소 값 + 1 * (data size of int)
-
우리는 여기서 포인터 변수를 선언 할 때 data type을 넣는 이유를 알게 되었다.
- 메모리에서 포인터로 데이터를 접근 할 때 얼마나 건너뛰어야 다음 data가 나오는지 알기 위해
-
arr [1] 과 *(arr + 1)의 차이점?
- 없다. 우리는 좌측이 익숙하지만 컴파일러는 우측의 방식으로 변환해서 컴퓨터가 알아 볼 수 있게 한다.
- 우리는 우측의 방식으로 사용해야 하지만 arr [ ] 방식을 사용하게 해서 사용자들의 편의를 높여준 것이다.
- 즉, 위의 과정들을 통해서 우리는 ‘배열은 포인터다’ 라는 말을 이해 할 수 있게 되었다.
