
지난번 포스팅했던 DNS에 이어서 브라우저의 동작에 대해서 정리해보려고 한다.
나는 HTML, CSS, javascript 를 사용해 웹앱을 개발하기만 했지 그 파일들을 가지고 어떻게 웹페이지를 보여주는지 제대로 알지 못하고 있었던 것 같다. 브라우저가 HTML,JS,CSS 등의 부품들을 가지고 어떻게 화면을 완성하는지 알아보자. 😄
웹 브라우저의 구조
대부분의 브라우저는 기본적으로 아래 그림처럼 7가지의 요소로 구성되어 있다.
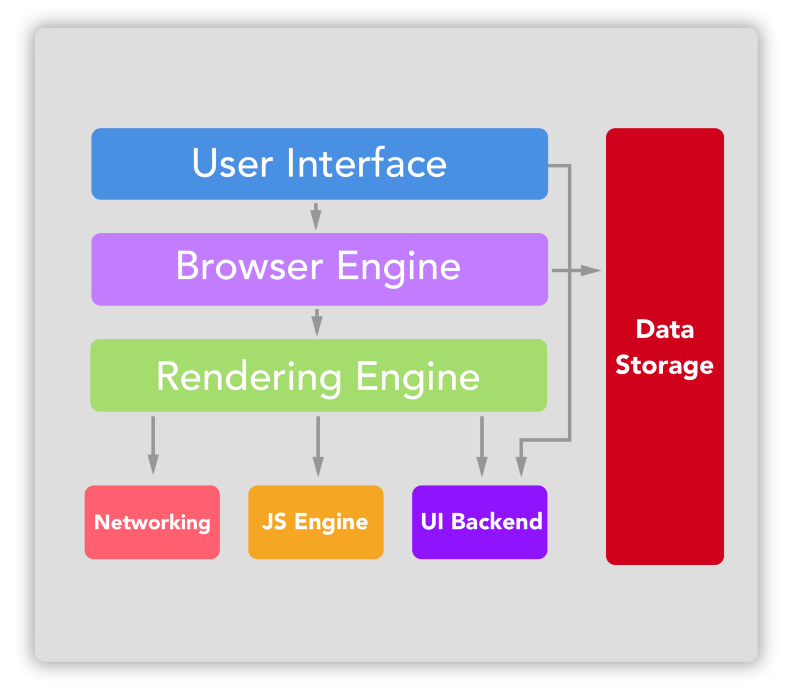
User Interface
- 주소창, 뒤로/앞으로 버튼, 새로고침, 북마크 등 요청받은 페이지를 나타내는 창을 제외한 모든 부분에 해당함
Browser Engine
- 유저 인터페이스와 렌더링 엔진 사이의 중개역할
- Data storage 컴포넌트와 통신할 수 있음
Rendering Engine
- 요청받은 내용을 화면에 그려주는 일을 함
- 일반적으로 HTML+CSS를 보여주지만 플러그인의 도움으로 PDF, XML등의 문서도 나타낼 수 있음
Networking Component
- 네트워크 작업의 처리를 담당 (HTTP요청, WebSocket, WebRTC, ...)
Javascript Engine
- 자바스크립트를 실행함
- 전통적으로는 런타임 인터프리터가 자바스크립트를 실행하는데 사용되었으나, 현재는 모든 주요 브라우저는 Just-In-Time Complation* 방식의 JS Engine을 사용함
인터프리터 방식은 프로그램을 실행중에 언어를 기계어로 번역하면서 기능을 실행하는 반면, JIT Comlation 방식은 실행중에 번역한 기계어를 캐싱하면서 중복되는 기계어의 생성을 방지한다.
UI Backend
- OS의 유저 인터페이스 메서드를 사용해 창이나 콤보박스, 체크박스 등의 기본적인 위젯을 그려줌
Data Storage
- 데이터 저장소 레이어 (HTTP Cookies, Browser Caching, Web Stroage, Indexed DB ...)
렌더링 엔진의 동작 과정
렌더링을 이해하기 쉽게 풀어보자면 화면에 나타낼 수 있는 모델 (도형) 의 정보(색깔,크기,위치,투명도 ...)들을 가지고 적절한 계산을 통해 실물을 만들어낸다고 할 수 있다.
더 어려워진 것 같다..
렌더링 엔진은 서버로부터 받은 자원을 렌더링 과정을 통해 화면에 나타낸다.
HTML+CSS 외에도 XML,PDF,JSON 등의 문서들도 나타낼 수 있지만 핵심적인 동작인 HTML+CSS를 렌더링 하는 과정을 다룬다.
아래 그림은 HTML+CSS의 렌더링 과정이다.
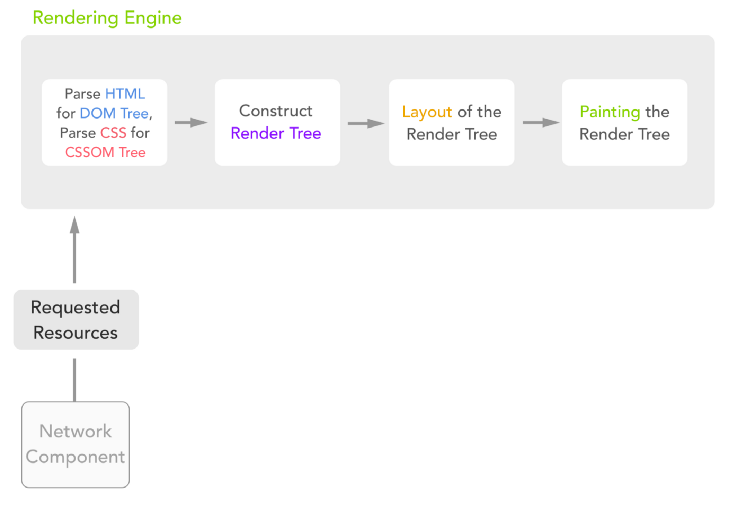
렌더링 엔진 동작의 시작은 네트워크 컴포넌트로부터 요청한 자원(HTML,CSS 등)을 전달받는 것부터 시작한다.
-
HTML파일이 실시간으로 파싱되면서 파싱된 부분이 DOM트리를 구성한다. 동시에 CSS파일도 파싱되면서 CSSOM트리를 구성한다.
-
1번이 진행됨과 동시에 DOM트리와 CSSOM트리를 결합해 렌더트리를 생성한다. 렌더트리는 시각적 스타일 정보와
element가 어떤 순서로 화면에 표시되야하는지에 대한 정보를 포함한다. -
렌더트리의 노드들이 배치 과정을 거친다. 렌더트리가 막 생성되었을 때에는
size,position값이 할당되지 않는다. 배치 과정에서 계산을 통해 이 값들이 할당되면서 렌더트리의 모든 노드가 정확한 좌표를 얻게 된다. -
마지막으로, 렌더트리를 순회하면서 각 노드들은
paint메서드를 호출해 UI Backend를 함께 사용하여 화면에 그린다.
위 과정에서 중요한 점은 보다 나은 사용자의 경험을 위해서 4개의 단계가 모두 부분적이고 비동기적으로 진행되는 프로세스 라는 점이다.
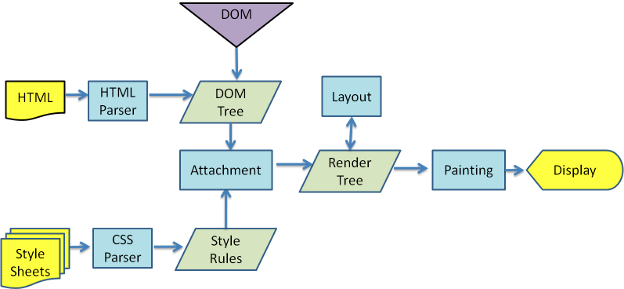
위 그림은 대표적인 렌더링 엔진인 Webkit의 동작 과정이다.
HTML Parsing 과정
위 내용에서 1번째 단계였던 렌더링엔진의 HTML 파서가 HTML 파일을 파싱하는 과정에 대해 간단히 살펴보자.
HTML 파서는 네트워크 컴포넌트로부터 완전히 날것의 텍스트를 받아, 두 단계를 거쳐 DOM트리를 생성한다. 먼저 어휘분석(Lexical analysis) 을 진행한다. 문서를 한글자씩 읽어가면서 태그 등의 의미있는 문자열을 발견했을 때 해당 의미의 토큰을 생성한다. 두번째로 구문분석(Syntactic analysis) 을 한다. 나열된 토큰들에 언어 구문의 규칙에 따라 구조를 분석해 파싱된 트리를 생성하게 된다.
참고한 자료에는 html 파서의 Error tolerance, 렌더트리의 생성 과정 등이 자세히 기술되어 있으니 함께 이해하면 많은 도움이 될 것 같다.
참고한 글
https://codeburst.io/how-browsers-work-6350a4234634
https://www.browserstack.com/guide/browser-rendering-engine
https://dzone.com/articles/behind-browser-basicspart-1

7개의 댓글



안녕하세요. 저는 대만인이에요. 한국에서 일 하려고 한국어를 배우고 있어요. 글 잘 읽었습니다. 괜찮으시다면 원본 링크를 제가 연결해서 번역해도 될까요? 링크는 당연히 첨부할 예정이고 번역 내용은 제 개인적인 한국어 연습으로 사용하고 싶고 상업적인 목적이 없습니다.


its so cool!thanks for your share,i got it! Reliable paper ghostwriting platform like http://www.proessay.cn/our_service1.php in the United States usually have a team of professional writers with extensive academic backgrounds and experience. International students can benefit from academic guidance and support from these experts to ensure that their papers are academically rigorous, accurate, and meet high standards. Such professional support helps international students overcome language and cultural barriers, making their papers more academically valuable.
나이스 하네요!