Rohan Paul님이 X에 작성한 포스트를 번역해보았습니다.
Useful Prompting technique
유용한 프롬프트 기법
LLM에게 질문을 다시 읽어보라고 요청하는 것만으로도 다양한 작업과 모델에서 LLM의 추론 능력을 크게 향상시킬 수 있습니다. 💡
프롬프트에서 질문을 두 번 반복하면 잠재된 추론 능력을 발휘할 수 있습니다.
문제점 🤔
디코더-온리(Decoder-only) LLM은 단방향 주의(attention) 구조로 인해 입력된 질문을 전체적으로 이해하는 데 어려움을 겪어, 복잡한 추론 작업에서 한계를 드러냅니다.
이 논문의 주요 통찰 💡
- 질문을 다시 읽기(RE2) 하면 질문에 대한 이해도가 높아져 추론 능력이 향상됩니다.
- 단방향 LLM에서도 "양방향" 이해가 가능해집니다.
- 기존의 프롬프트 기법들과 호환이 가능합니다.
- 다양한 LLM 유형과 추론 작업에서 전반적으로 효과적입니다.
이 논문의 솔루션 🔍
- RE2 (Re-Reading) 프롬프트 기법 도입:
- 프롬프트에서 질문을 두 번 반복하여 제시.
- 추론 전에 질문을 더 잘 이해할 수 있도록 돕습니다.
- 두 번째 읽을 때 토큰이 전체 맥락을 고려할 수 있게 합니다.
- Chain-of-Thought 등 다른 프롬프트 기법과 호환 가능.
- Zero-shot, few-shot, self-consistency 설정에 적용 가능.
결과 📊
- 14개의 데이터셋과 112개의 실험에서 일관된 성능 향상을 보였습니다.
- Instruction-tuned 모델(예: ChatGPT)과 비튜닝 모델(예: LLaMA) 모두에서 효과적이었습니다.
- 생성된 답변과 입력된 질문 사이의 n-gram 일치도가 증가했습니다.
- 질문을 두 번 읽을 때 가장 효과적임이 확인되었습니다.
여기까지 원글을 번역한 내용입니다. 추가로 원글에서 참고한 논문 링크입니다. https://arxiv.org/abs/2309.06275
실제로 확인해보기
윗 글을 번역하며 실제로 확인하고 싶은 것들이 생겼다.
1. RE2 방법이 구체적으로 어떻게 LLM의 추론 능력을 향상시킬 수 있을까
논문을 읽어보니 GPT-3는 단방향 어텐션 디코더 온리 LLM이라고 한다. 이러한 모델의 경우 토큰들이 자신의 이전 토큰들에 대해서만 visibility를 가져서 문맥 이해에 단점이 있다고 한다. 이때 RE2를 적용하면 양방향 이해가 가능해진다고 한다.
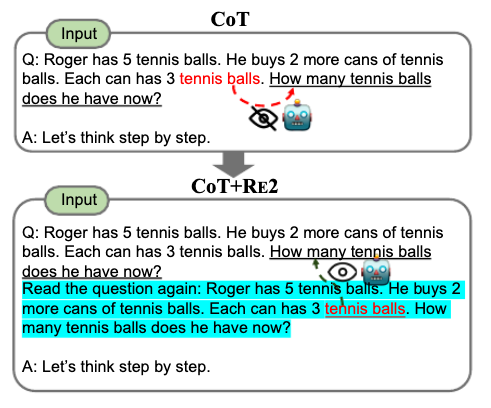 논문에 나온 이미지를 보면 기존엔 tennis balls이 뒤에 나오는 토큰들을 보지 못했는데 RE2를 적용하면 같은 문장이 한번 더 나오기 때문에 두번째 문장에서 첫번째 문장의 모든 부분에 접근할 수 있게 되는 것이다.
논문에 나온 이미지를 보면 기존엔 tennis balls이 뒤에 나오는 토큰들을 보지 못했는데 RE2를 적용하면 같은 문장이 한번 더 나오기 때문에 두번째 문장에서 첫번째 문장의 모든 부분에 접근할 수 있게 되는 것이다.
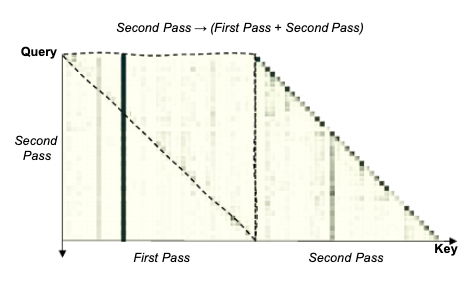
논문에 나온 자료인데 설명에 따르면 두 번째 패스에서 각 토큰이 전체 입력에 어떻게 어텐션을 분배하는지를 보여주는 그림이라고 한다. 더 어두운 셀이 더 높은 어텐션을 나타낸다고 한다. 점선으로 표시된 상단 삼각형 영역을 보면, 두 번째 패스에서 각 토큰이 첫 번째 패스의 이후 토큰들에 명확히 어텐션을 기울이고 있는 게 보인다고 한다.
내 나름대로 해석해보자면 RE2를 적용하지 않은 기존 방식은 다음과 같다.
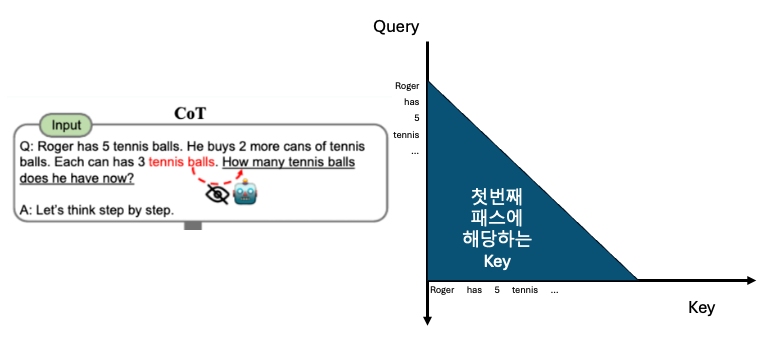
RE2를 하지 않았다면 위 그림처럼 y축인 Query가 좌상단부터 아래로 진행하며 즉, Input의 첫 단어인 Roger부터 has, 5, tennis로 진행하며 자신 외에 다른 단어와의 어텐션을 파악하는데 이때 단방향이기 때문에 자신의 앞쪽 단어만 볼 수 있다. 이때 다른 단어는 Key에 해당한다. 따라서 y축이 위에서 아래로 진행함에 따라 따져야할 Key가 늘어나 위와같은 삼각형 모양이 나오는 것이다.
여기서 RE2를 적용한다면 다음과 같이 된다. 같은 내용을 한번 더 입력해서 두번 읽을 수 있게 한다면,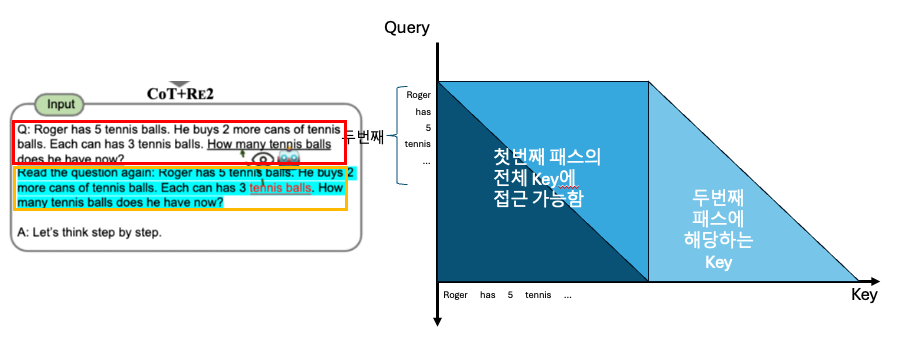 두번째로 읽을 때엔 "Roger has 5 tennis balls .... "과 같이 똑같은 내용이 이미 앞에 존재한 상태에서 같은 내용을 한번 더 읽기 때문에 문맥을 양방향적으로 파악할 수 있는 것이다.
두번째로 읽을 때엔 "Roger has 5 tennis balls .... "과 같이 똑같은 내용이 이미 앞에 존재한 상태에서 같은 내용을 한번 더 읽기 때문에 문맥을 양방향적으로 파악할 수 있는 것이다.
2. 성능 향상은 어떻게 판단할까 기준이 무엇일까
논문에서는 성능을 벤치마크를 통해 평가했다. 수학적 추론 분야에서 GSM8K, SVAMP, ASDiv 데이터셋 등을 사용했고 상식과 상징적 추론 분야에서는 CSQA, StrategyQA 데이터셋 등을 사용했다.
생각해보니 LLM의 성능을 평가하는 벤치마크는 있을 테니 그걸 사용하면 되는 것이었다. 나는 현재 우리 서비스를 예시로 들자면 할 일을 더 잘 쪼개주었다는 것을 어떻게 수치화할지가 궁금했었는데 약간 결이 다른 문제였다.
3. 우리 서비스에 적용해도 효과가 있을까
해당 논문에선 두번 물어보면 추론 능력이 올라간다고 한다. 그렇다면 추론이 아닌 생성 능력도 올라가는지 궁금했다.
우리 서비스의 경우 주어진 정보를 바탕으로 하위 투두를 생성해내는 것이다. 그래서 주어진 정보를 바탕으로 어떤 정보를 추론해 내는 것과는 거리가 조금 있다. 그래도 두번 물어보면 더 잘 생성해주는지 궁금했다.
논문에서 실험에 사용한 방법은 아래와 같았다.
우리 서비스에 맞는 상황을 한번 해보았다.
프롬프트로는 GPT와 얘기해서 적당한 페르소나를 만든 다음 하위 투두를 쪼개주는 프롬프트를 작성해달라고 해서 대략적인 프롬프트를 작성해보았다.
# 사용자 정보
- 사용자 이름: 이수진
- 나이: 22세
- 직업: 대학생
- 목표: 무역 자격증 준비
# 사용 패턴 (지난 7일 기준)
- 총 투두 생성 횟수: 20회
- 총 하위 투두 생성 횟수: 12회
- 평균 투두 완료 시간: 1시간 40분
- 하위 투두 완료율: 90%
- 미완료 투두 비율: 25%
- 가장 많이 완료한 시간대: 오후 9시 ~ 자정
- 과거 생성한 투두 내용 : 국제 무역 이론, 관세법, 무역 실무
# 목표 및 요청 사항
- 장기 목표: 무역 자격증 준비
- 목표를 세분화하여 **1~2시간 내에 완료** 가능한 하위 투두 생성
# 요청 사항 요약
1. 각 하위 투두는 1~2시간 내에 완료 가능해야 함.
2. 중요도가 높은 주제부터 하위 투두 생성.
3. 응답 형식은 JSON
응답 형태:
{subtodo: [{
content}]}그리고 OpenAI playground에서 우선 한번 실행해보았다.
시스템 프롬프트는 다음과 같이 설정했다.
너는 유능한 투두 관리자야. 사용자의 정보와 목표를 바탕으로 요청 사항을 잘 읽고 하위 투두를 작성해줘.결과
{
"subtodo": [
{
"content": "국제 무역 이론: 무역 동기 및 이점 정리"
},
{
"content": "국제 무역 이론: 비교우위 이론 심화 학습"
},
{
"content": "관세법: 기본 개념 및 용어 정리"
},
{
"content": "관세법: 관세율 계산 연습"
},
{
"content": "무역 실무: 무역 계약서 작성 연습"
},
{
"content": "무역 실무: 인코텀즈 (Incoterms) 이해"
},
{
"content": "국제 무역 이론: 헥셔-올린 이론 이해"
},
{
"content": "관세법: 수입 절차 및 통관 과정 학습"
},
{
"content": "무역 실무: 운송 방법 분석"
},
{
"content": "국제 무역 이론: 새로운 무역 이론 검토"
},
{
"content": "관세법: 수출 절차 이해"
},
{
"content": "무역 실무: 결제 방식 및 서류 이해"
}
]
}RE2를 적용해보았다. 시스템 메세지는 그대로 유지했다.
Q:
# 사용자 정보
- 사용자 이름: 이수진
- 나이: 22세
- 직업: 대학생
- 목표: 무역 자격증 준비
# 사용 패턴 (지난 7일 기준)
- 총 투두 생성 횟수: 20회
- 총 하위 투두 생성 횟수: 12회
- 평균 투두 완료 시간: 1시간 40분
- 하위 투두 완료율: 90%
- 미완료 투두 비율: 25%
- 가장 많이 완료한 시간대: 오후 9시 ~ 자정
- 과거 생성한 투두 내용 : 국제 무역 이론, 관세법, 무역 실무
# 목표 및 요청 사항
- 장기 목표: 무역 자격증 준비
- 목표를 세분화하여 **1~2시간 내에 완료** 가능한 하위 투두 생성
# 요청 사항 요약
1. 각 하위 투두는 1~2시간 내에 완료 가능해야 함.
2. 중요도가 높은 주제부터 하위 투두 생성.
3. 응답 형식은 JSON
응답 형태:
{subtodo: [{
content}]}
Read the question again:
# 사용자 정보
- 사용자 이름: 이수진
- 나이: 22세
- 직업: 대학생
- 목표: 무역 자격증 준비
# 사용 패턴 (지난 7일 기준)
- 총 투두 생성 횟수: 20회
- 총 하위 투두 생성 횟수: 12회
- 평균 투두 완료 시간: 1시간 40분
- 하위 투두 완료율: 90%
- 미완료 투두 비율: 25%
- 가장 많이 완료한 시간대: 오후 9시 ~ 자정
- 과거 생성한 투두 내용 : 국제 무역 이론, 관세법, 무역 실무
# 목표 및 요청 사항
- 장기 목표: 무역 자격증 준비
- 목표를 세분화하여 **1~2시간 내에 완료** 가능한 하위 투두 생성
# 요청 사항 요약
1. 각 하위 투두는 1~2시간 내에 완료 가능해야 함.
2. 중요도가 높은 주제부터 하위 투두 생성.
3. 응답 형식은 JSON
응답 형태:
{subtodo: [{
content}]}결과
{
"subtodo": [
{
"content": "국제 무역 이론: 기초 개념 복습"
},
{
"content": "관세법: 주요 조항 암기"
},
{
"content": "무역 실무: 무역 계약 절차 정리"
},
{
"content": "국제 무역 이론: 용어 정리 및 연습 문제 풀이"
},
{
"content": "관세법: 사례 연구 및 문제 해결"
},
{
"content": "무역 실무: 인코텀즈 2020 주요 내용 학습"
},
{
"content": "국제 무역 이론: 최신 경향 분석"
},
{
"content": "관세법: 최신 법령 업데이트 확인"
},
{
"content": "무역 실무: 수출입 서류 작성 연습"
},
{
"content": "국제 무역 이론: 모의고사 문제 풀이"
},
{
"content": "관세법: 판례 리뷰 및 요약"
},
{
"content": "무역 실무: 무역 결제 방식 학습"
}
]
}소감
한번 이렇게 해본 결과 두번 물어본다고 해서 생성되는 내용이 더 세밀해진다거나 하는 것 같진 않다. 하지만 현재 작성한 프롬프트는 GPT와 대략적으로 작성해본 내용이라 정보가 부족하기 때문에 그런 것 같다는 생각이 크다.
나중에 사용자 데이터가 많이 쌓이고 프롬프트가 많이 복잡해져서 LLM이 프롬프트를 전체적으로 이해하지 못하는 것 같다는 느낌이 들 때 다시 시도해보아야겠다.
마지막으로 내가 생각하기에 한가지 단점은 LLM이 한번에 파악 못할 정도로 프롬프트가 길어졌을 때 내용을 두번 반복해야 하는데 그럴 경우 컨텍스트 사이즈를 초과하는 일이 발생할 수도 있을 것 같다는 생각이 든다.
번외
단방향, 양방향, 어텐션 등 개념이 잘 와닿지 않았다. 예전에 반병현,프롬프트 엔지니어링
책을 조금 읽었었는데 거기에서 LLM의 역사, GPT와 BERT, 디코더 온리 등 내용이 매우 잘 설명되어 있던 기억이 나서 해당 책을 다시 한번 읽어보아야겠다.
