우리가 흔히 알고 있는 chrome, safari, opera 같은 브라우저는 어떻게 렌더링이 되는 걸까?라는
의문에서 시작해서 이 글을 쓰게 됐다. 이 글은 크게 아래와 같은 순서로 진행됩니다.
- 브라우저란 뭘까?
- 브라우저의 구조는 어떻게 될까?
- 브라우저마다 렌더링 엔진은 다를까?
- 브라우저가 어떻게 렌더링 되는 걸까?
- 마무리
브라우저란 뭘까?
가끔 이런 경험을 해본 적이 있을 것이다. pdf를 받아서 chrome으로 열기를 누르면 해당 파일이 열린 적이 있을 것이다. 단순히 웹서핑할 때만 브라우저를 이용했던 분은 의아했을 것이다. 하지만 정확히 브라우저의 주요 기능을 알게 되면 왜 브라우저를 통해 pdf 파일을 열수 있는지 이해될 것이다.
브라우저는 사용자가 선택한 자원을 서버에 요청하고 브라우저에 표시하는 것이 주요 기능이다.
자원은 보통 HTML 문서지만 PDF나 이미지 또는 다른 형태일 수 있다. 그렇기 때문에 브라우저를 통해 pdf나 이미지를 열람할 수 있었던 것이다.
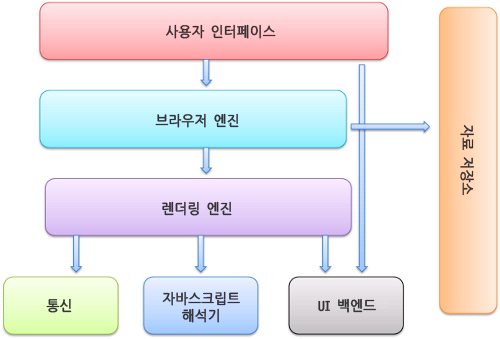
이런 브라우저의 기능을 위해 브라우저의 구조는 어떻게 될까?
- 사용자 인터페이스 - 주소 표시줄, 이전/다음 버튼, 북마크 메뉴 등. 요청한 페이지를 보여주는 창을 제외한 나머지 모든 부분이다.
- 브라우저 엔진 - 사용자 인터페이스와 렌더링 엔진 사이의 동작을 제어.
- 렌더링 엔진 - 요청한 콘텐츠를 표시. 예를 들어 HTML을 요청하면 HTML과 CSS를 파싱하여 화면에 표시함.
- 통신 - HTTP 요청과 같은 네트워크 호출에 사용됨. 이것은 플랫폼 독립적인 인터페이스이고 각 플랫폼 하부에서 실행됨.
- UI 백엔드 - 콤보 박스와 창 같은 기본적인 장치를 그림. 플랫폼에서 명시하지 않은 일반적인 인터페이스로서, OS 사용자 인터페이스 체계를 사용.
- 자바스크립트 해석기 - 자바스크립트 코드를 해석하고 실행.
- 자료 저장소 - 이 부분은 자료를 저장하는 계층이다. 쿠키를 저장하는 것과 같이 모든 종류의 자원을 하드 디스크에 저장할 필요가 있다. HTML5 명세에는 브라우저가 지원하는 '웹 데이터 베이스'가 정의되어 있다.
브라우저마다 렌더링 엔진은 다를까?
맞습니다. 브라우저마다 렌더링 엔진은 다릅니다. 이런 이유 때문에 어떤 브라우저에서는 정상적으로 렌더링이 되는 반면 특정 브라우저에서는 렌더링이 되지 않는 상황이 발생하기도 합니다. 이런 경우 때문에 크로스 브라우징이라는 기법이 나온 것이다. 이런 렌더링 엔진 종류에는 사파리와 크롬에서 사용하는 Webkit 엔진과 파이어폭스에서 사용하는 Gecko 엔진이 있다.
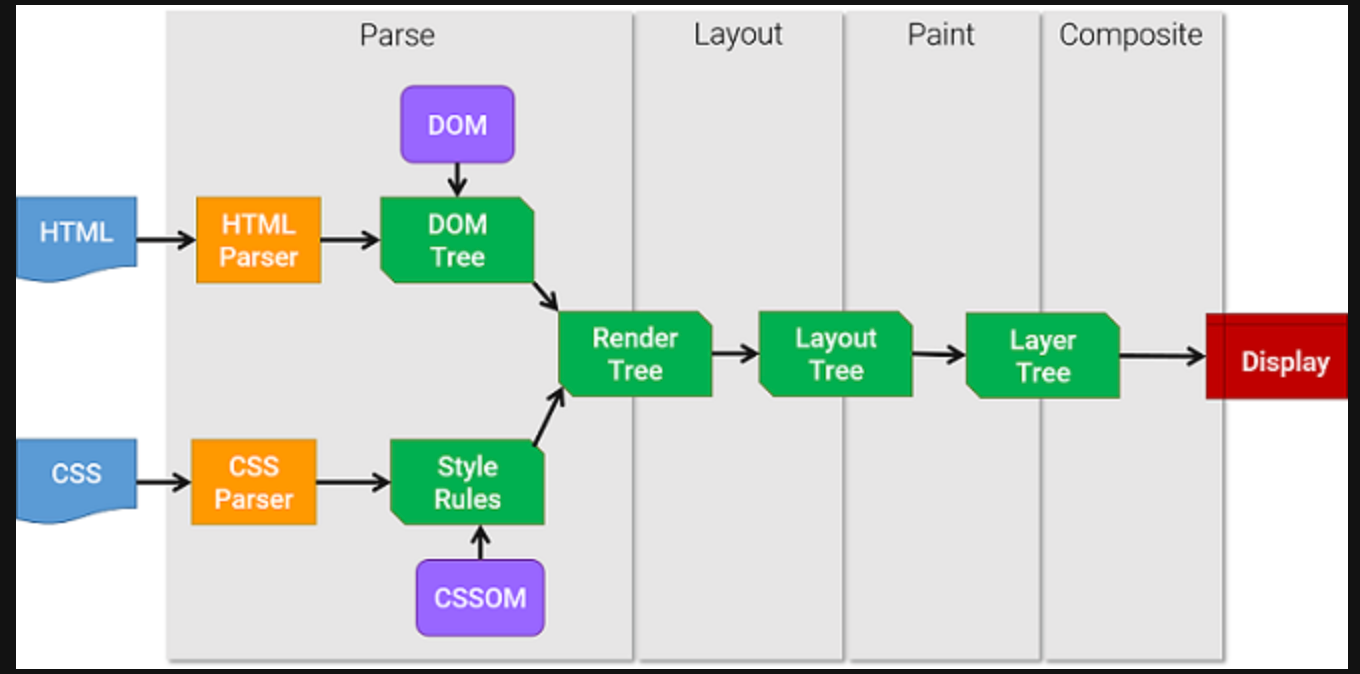
브라우저 렌더링 과정은 어떻게 될까?
렌더링의 기본적인 동작 과정은 다음과 같다.
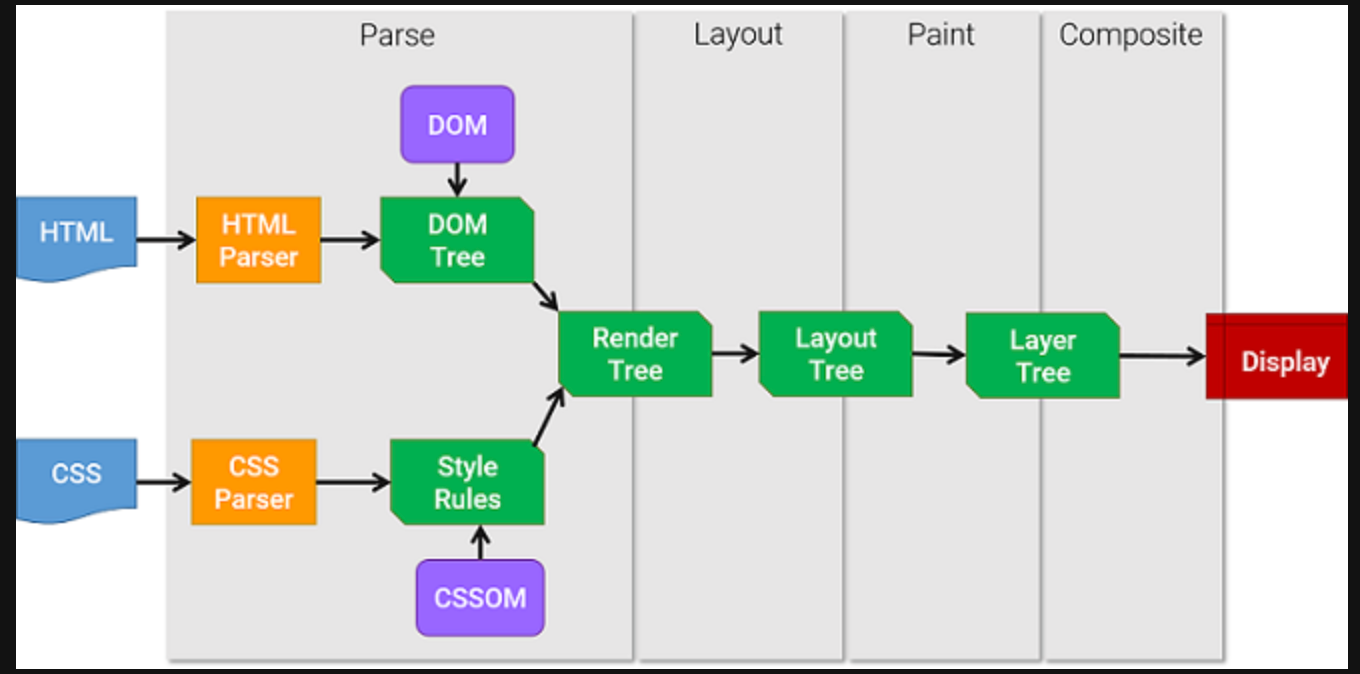
- HTML 파일과 CSS 파일을 파싱해서 각각 Tree를 만든다. (Parsing)
- 두 Tree를 결합하여 Rendering Tree를 만든다. (Style)
- Rendering Tree에서 각 노드의 위치와 크기를 계산한다. (Layout)
- 계산된 값을 이용해 각 노드를 화면상의 실제 픽셀로 변환하고, 레이어를 만든다. (Paint)
- 레이어를 합성하여 실제 화면에 나타낸다. (Composite)
각 단계별로 자세히 살펴보겠다.
1. Parsing
렌더링 하고자 하는 HTML 파일을 해석하는 작업이 선행되어야 한다.
HTML 파일을 해석하면서 DOM(Document Object Model) Tree를 구성하는 단계이다.
이 과정에서 HTML에 CSS가 포함되어 있다면 CSSOM(CSS Object Model) Tree 구성 작업도 함께 진행된다. 그래서 Parsing 과정을 거치면 Dom Tree 와 CSSOM Tree가 생긴다.
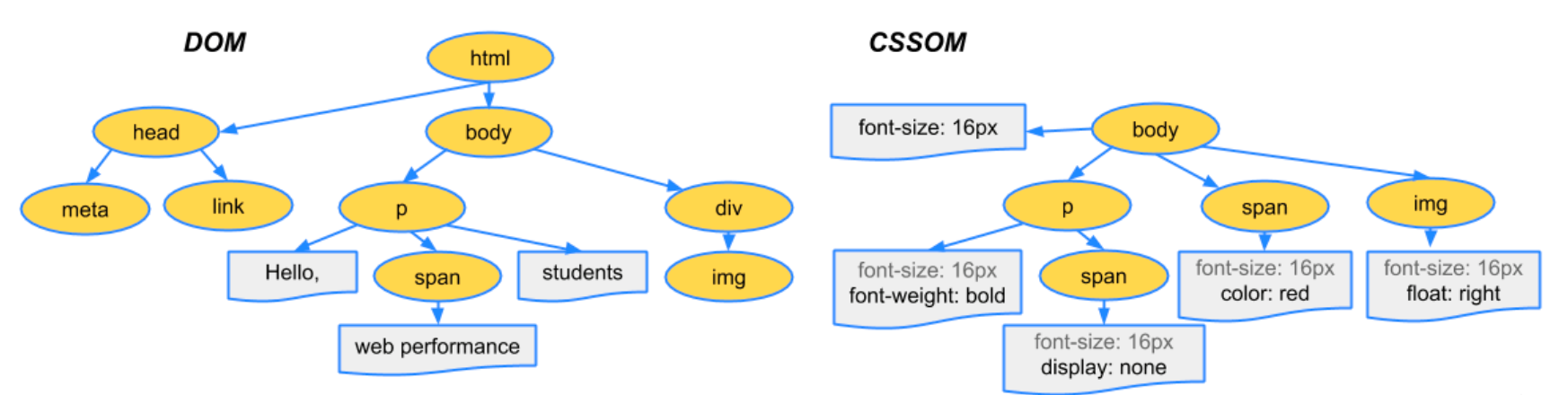
Style
Style 단계에서는 Parsing 단계에서 생성된 DOM Tree와 CSSOM Tree를 매칭시켜서 Render Tree를 구성한다. Render Tree는 실제로 화면에 그려질 Tree이다.
예를 들면 Render Tree를 구성할때 visibility: hidden은 요소가 공간을 차지하고, 보이지만 않기 때문에 Render Tree에 포함이 되지만, display: none 의 경우 Render Tree에서 제외된다.
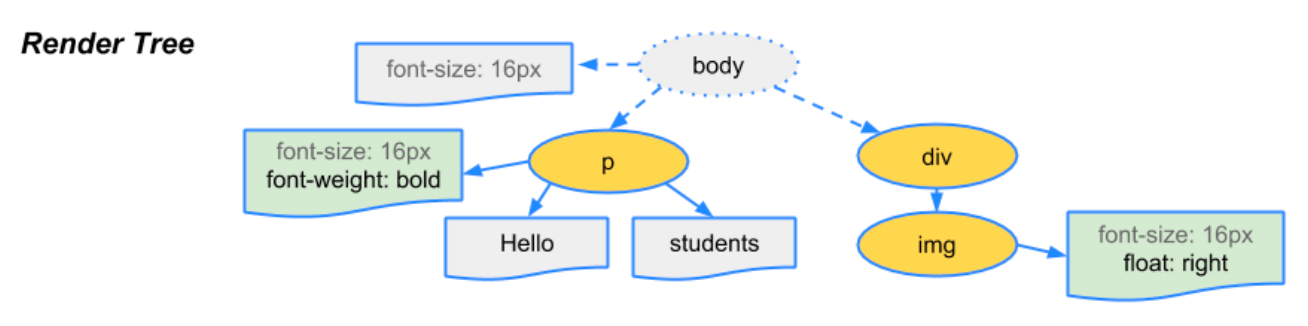
Layout
Layout 단계에서는 Render Tree를 화면에 어떻게 배치해야 할 것인지 노드의 정확한 위치와 크기를 계산한다.
루트부터 노드를 순회하면서 노드의 정확한 크기와 위치를 계산하고 Render Tree에 반영한다. 만약 크기 값을 %로 지정하였다면, Layout 단계에서 % 값을 계산해서 픽셀 단위로 변환한다.
Paint
Paint 단계에서는 Layout 단계에서 계산된 값을 이용해 Render Tree의 각 노드를 화면상의 실제 픽셀로 변환한다. 이때 픽셀로 변환된 결과는 하나의 레이어가 아니라 여러 개의 레이어로 관리된다.
당연한 말이지만 스타일이 복잡할수록 Paint 시간도 늘어난다. 예를 들어, 단색 배경의 경우 시간과 작업이 적게 필요하지만, 그림자 효과는 시간과 작업이 더 많이 필요하다.
Composite
Composite 단계에서는 Paint 단계에서 생성된 레이어를 합성하여 실제 화면에 나타낸다. 우리는 화면에서 웹 페이지를 볼 수 있다.
위와 같은 과정을 통해서 우리는 브라우저에서 HTML 파일을 볼 수 있는 것이다. 위 과정들을 조금 축약해서 그림으로 표현하자면 다음과 같다.

- HTML에 있는 코드 읽기
- 읽은 코드들을 하나의 트리로 만들기
- 트리 만든것을 실제 브라우저에 어떻게 배치할지 정하기
- 어떻게 배치 할지 정했다면 브라우저에 그리기
위와 같이 간단히 정리 할 수 있을것이다.
마무리
브라우저의 렌더링 과정들을 정리하면서 많은 도움이 되었다. 공부하면서 렌더링 과정을 어떻게 최적화 시킬 수 있을까에 대한 의문이 들었다. 해당 내용은 다음 글에서 설명해봐야겠다.
참고자료
